Zabbix6.0のネイティブHA機能を試してみた

はじめに
エンジニアリング本部 マイグレーションチームに所属しています、tkgです。
卵かけご飯には醤油と生姜と出汁を入れるタイプです。よろしくお願いします。
さて、2/15に個人的に楽しみにしていたZabbix 6.0 LTSがリリースされました。
5.2以降追加された実運用に利用できそうな機能が多い中、一番気になった6.0新機能のHA機能を試してみました。
HA機能でできること
zabbix_serverプロセスのHA Cluster構成が構築可能です。
各nodeにconfigを記載の上プロセスを起動させると、自動的にprimary/standby構成としてプロセスが動作します。
しかし、zabbix_server以外のDBやVIP等のHA機能は無く、別途検討する必要がありそうです。
実際に作ってみる
環境・前提
今回はAWSを利用し、下記環境を作成しました。
– EC2(Alma Linux 8.5) 2台
– RDS(MySQL 8.0.27)

RHEL7系以前は zabbix-serverのパッケージが提供されていないようなので、パッケージでインストールしたい方は8系以降のOSを利用する必要がありそうです。
前提事項
- SELinuxの停止とMySQLクライアントのインストールを実施しています。
- インスタンス間の通信はセキュリティグループにて許可されているものとします。
- 各node上でZabbixのセットアップが完了している必要があります。
初期セットアップは公式サイトを参照してください。
MySQLのユーザを作成する
MySQLのユーザ作成時に複数のnodeから接続できるようにしてあげる必要があります。
今回は 10.64.101.0/24のサブネット上に環境を構築したため、下記のとおりMySQLユーザを作成しました。
mysql> create user zabbix@10.64.101.0/255.255.255.0 identified by '[password]'; mysql> grant all privileges on zabbix.* to 'zabbix'@'10.64.101.0/255.255.255.0';
configの変更
zabbix_server.confについても、DBの設定はRDS宛に変更します。
また、HA機能用の設定として、HANodeのヘルスチェック・識別用の設定がありますのでそちらも設定します。
DBHost=RDSのエンドポイント名 DBPassword=[password] HANodeName=[任意の一意なホスト名] NodeAddress=[ホストのIP:Zabbix-serverのポート]
なお、インストール時点初期値コメントアウトされているconfigですが、
/etc/zabbix/web/zabbix.conf.php 等に配置されるphpの下記項目を
コメントアウトしておく必要もあるようです。
// $ZBX_SERVER = ''; // $ZBX_SERVER_PORT = '';
起動してHAの状況を確認する
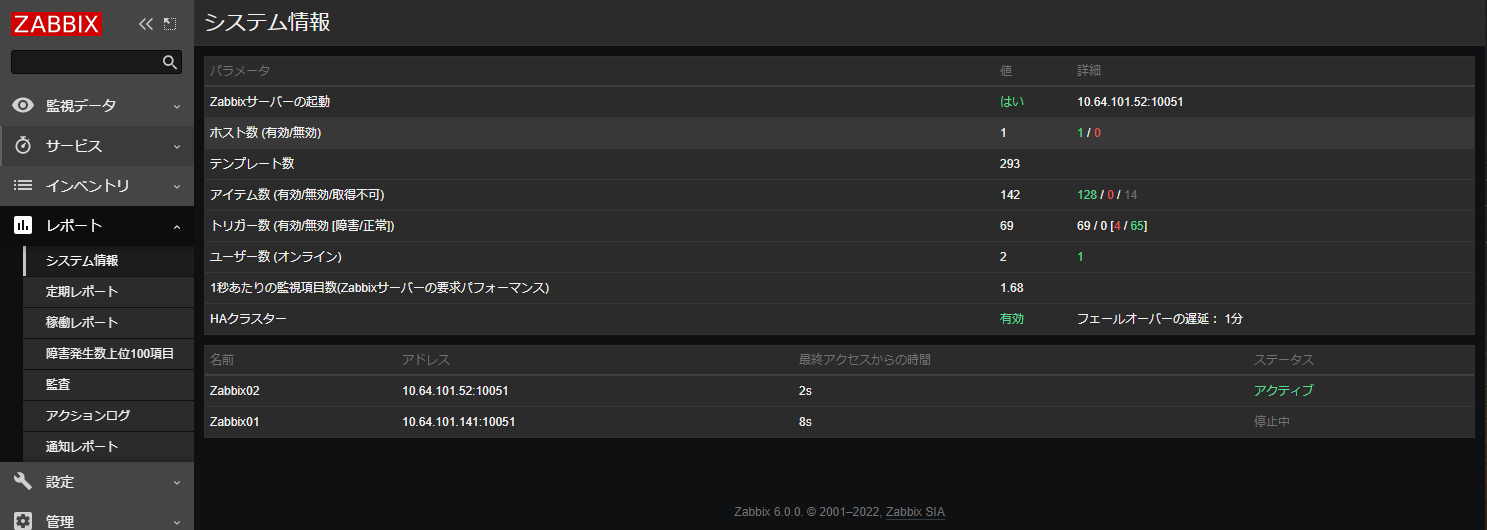
レポート → システム情報を確認すると、HANodeの状況が表示されるようになりました。

スタンバイノード上では、ha manager のみがzabbix_serverプロセス配下で起動しており、昇格時にpoller等のプロセスが起動する挙動となるようです。
- スタンバイ機のプロセスの状態
$ ps auxwwf | grep zabbix_serve[r] zabbix 1384 0.0 0.2 172244 10124 ? S 03:27 0:02 /usr/sbin/zabbix_server -c /etc/zabbix/zabbix_server.conf zabbix 1395 0.0 0.1 172244 4356 ? S 03:30 0:03 \_ /usr/sbin/zabbix_server: ha manager
HA構成時のデータの流れ
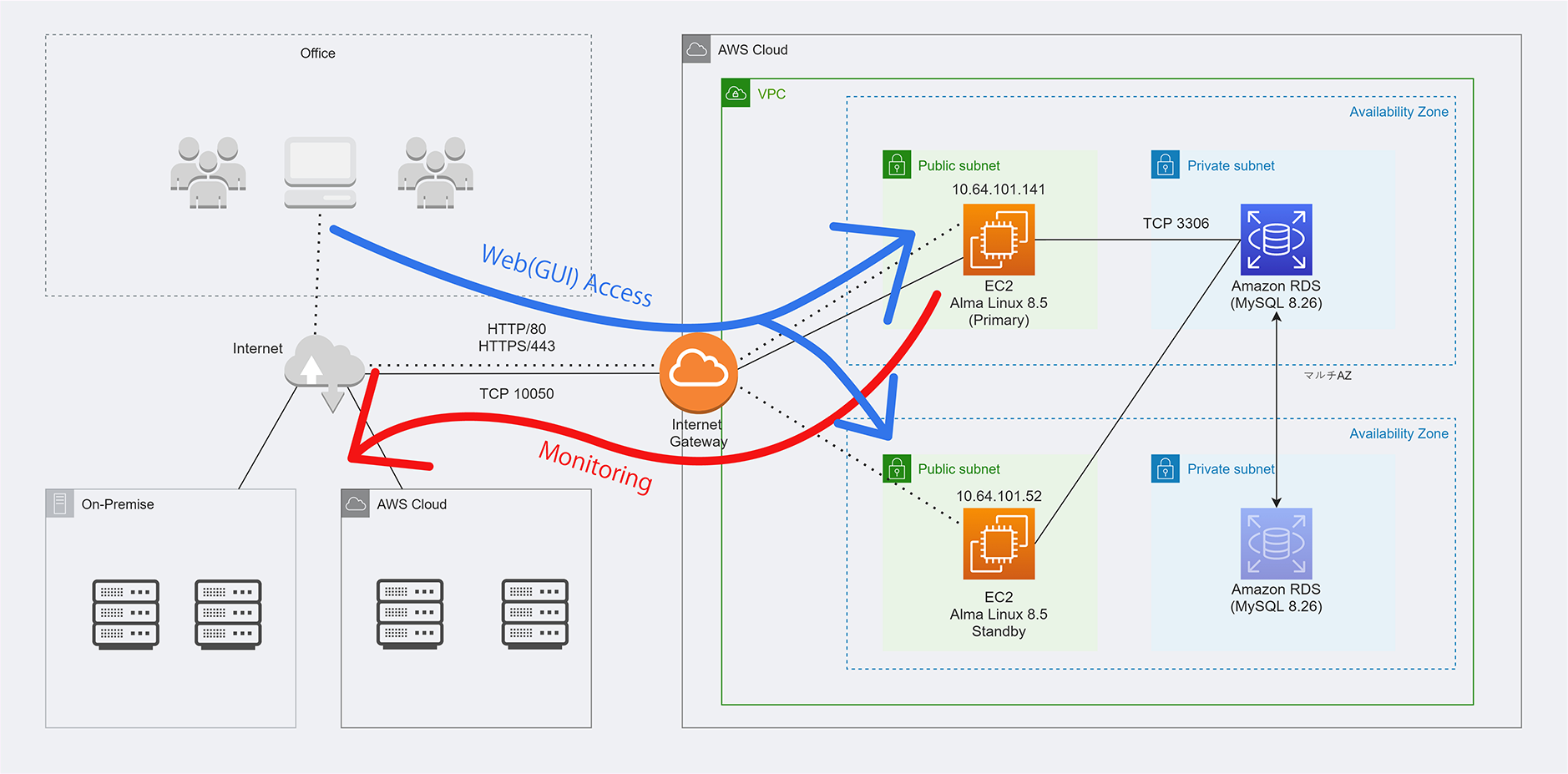
通信の流れとしてこのようになります。
GUI閲覧については、DBが共通のためどちらのサーバでも同一のデータを閲覧することが可能です。
実際にフェイルオーバーさせてみる
アクティブで動作しているzabbix_serverを停止してみたところ、
stanby nodeだったサーバにて、poller等のzabbix_serverプロセスが稼働を始めました。
また、GUI上も下記の通り更新されました。
5秒ごとに各nodeがDBに対してハートビートを送信しており、その疎通状況によってフェイルオーバーするようです。
デフォルトではフェイルオーバーの閾値が1分のようですが、ランタイムコマンドにてカスタマイズ可能なようでした。
片系障害時のデータの流れ

実際に運用する想定での構成案
今回は設定していませんが、この構成の場合両方のWEBを利用可能ですので、route53でフェイルオーバールーティングポリシーやELBを利用したいと思いました。
片方が障害時のことを考えるとヘルスチェックのある振り分けを行うと同一URLでの接続が可能となり、運用上も都合が良さそうです。
最後に
confにすこし追記するだけ、という簡単な設定でHAを組めるのはとても楽だなと感じました。
今回はDBにRDSを使用したため、ZabbixのネイティブHA機能を活かし、高い可用性を実現できました。
しかし、DBをセルフマネージドする必要がある場合や、VIPを使う必要がある環境などを利用する場合、DBやVIP等の管理に別のクラスタソフトウェアを利用する必要が出てくるため、合わせてそちらでZabbixも管理したほうが良いかもしれません。
(弊社で利用しているZabbixも冗長化しているものはPacemakerで一括管理しているものが多いです)
その他気になる新機能もありますので、検証を進めていきたいと思います。
参考資料
https://www.zabbix.com/documentation/6.0/en/manual
https://blog.zabbix.com/build-zabbix-server-ha-cluster-in-10-minutes-by-kaspars-mednis-zabbix-summit-online-2021/18155/

2016年入社のインフラエンジニアです。 写真が趣味。防湿庫からはレンズが生え、押入れには機材が生えます。 2D/3DCG方面に触れていた時期もありました。
Recommends
こちらもおすすめ
-

第5回JAWS-UG初心者支部勉強会に参加してきました
2016.4.20
-

Zabbixで名前解決ができているのか監視する
2023.12.15


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15