atop コマンドを用いて Amazon EC2 の障害原因を切り分けよう!

はじめに
「メトリクス監視にてアラートが発報されたので原因を調べて欲しい」
「EC2 で処理が止まったのでメトリクスを見てみたら CPU が 100 % になっていたけど何で?」
そのような経緯で EC2 の障害の原因調査をしたことはありませんか?
一般的な調査手法として、とりあえずログを見てエラー内容を確認しろと言われています。
しかし、コスト削減などの目的から 1 つのインスタンスに複数のアプリを導入していると、
「どのログを見れば良いのか分からない」「全部のログを見るのは面倒」といったお悩みがあるかと思います。
そんな方のために、今回は EC2 の障害調査にて原因の切り分けに利用できる atop コマンドをご紹介します!
atop コマンドとは?
Atop is an ASCII full-screen performance monitor for Linux that is capable of reporting the activity of all processes (even if processes have finished during the interval), daily logging of system and process activity for long-term analysis, highlighting overloaded system resources by using colors, etc.
Atoptool.nl
atop とは、一言で表すとサーバーのパフォーマンス監視ツールです。
特徴としては、以下の 2 点があります。
- プロセスごとにメトリクスを表示可能
- 過去の値を参照可能
デフォルトの設定では /var/log/atop/ 以下に日次でログファイルを生成し、30 日間保管します。
ファイル内には 10 分間隔で取得された各プロセスの CPU、メモリ、ディスクなどのメトリクスが記録されており、用途に応じて柔軟に参照できます。
他のツールとどう違うの?
パフォーマンス監視用ツールには top コマンドなど他のコマンドもありますし、AWS のサービスとして CloudWatch メトリクスもあります。
しかし、これらのツールは上記の特徴を兼ね備えておらず、障害原因を切り分ける際には活用できません。
そのため、冒頭の「どのログを見れば良いのか分からない」「全部のログを見るのは面倒」といったお悩みに対応するためには atop コマンドが必要になります。
| ツール | プロセスごとに表示 | 過去の値を参照 |
|---|---|---|
| atop コマンド | 〇 | 〇 |
| top コマンド | △※1 | △※2 |
| CloudWatch メトリクス | × | 〇 |
※1: top コマンドでは CPU 使用率、メモリ使用率をプロセスごとに表示することはできますが、ディスク I/O をプロセスごとに表示することはできません。
※2: top コマンドの過去の出力を参照するには別途ロギングの設定が必要になります。
導入方法
なお、atop コマンドを利用するためには atop 及び sysstat をインストールする必要があります。
以下のドキュメントを参考に事前にインストールしてください。
EC2 Linux インスタンスのモニタリングツールを設定する | AWS re:Post
また、以下の設定については適宜変更することができます。
特に、メトリクスの取得はデフォルトで 10 分間隔と広くなっているため 1 分程度に変更することを推奨します。
- メトリクスの取得間隔
- ログの保管期間
- ログの保管場所
よく使うオプション
- コマンド実行時のオプション
| オプション | 説明 |
|---|---|
| r | 参照するログファイルを指定 (ファイル名の形式は atop_yyyymmdd) |
| b | 参照する時間帯の開始時刻 (形式は hhmm) |
| s | 参照する時間帯の終了時刻 (形式は hhmm) |
例.) 2024/5/20 14:00 ~ 15:00 のメトリクスを参照したい場合 → atop -r /var/log/atop/atop_20240520 -b 1400 -e 1500
- 出力画面上でのオプション
| オプション | 説明 |
|---|---|
| t | 前の記録へ移動 |
| T | 次の記録へ移動 |
| g | 汎用情報の表示 (デフォルトの表示形式) |
| m | メモリ情報の表示 |
| d | ディスク情報の表示 |
| C | CPU 使用率に応じてプロセスを降順に表示 |
| M | メモリ使用率に応じてプロセスを降順に表示 |
| D | ディスク使用率に応じてプロセスを降順に表示 |
| P | プロセス名で絞り込み |
| I | プロセス ID で絞り込み |
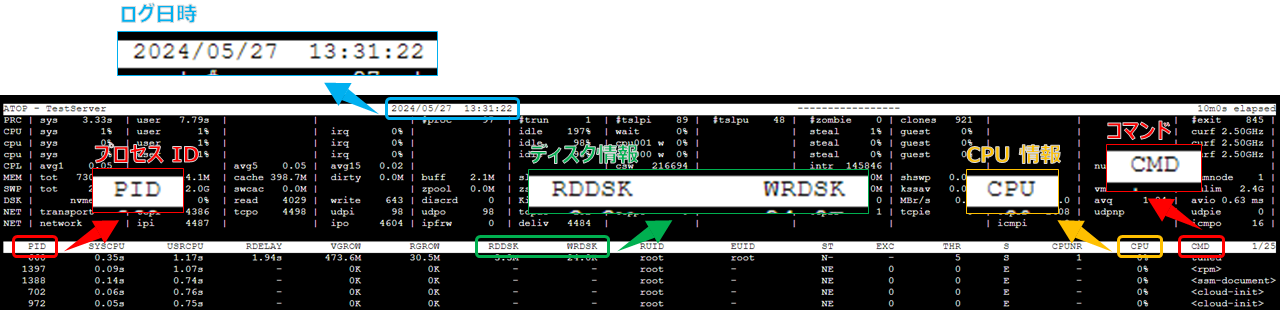
▲ 汎用情報を表示

▲ メモリ情報を表示

▲ ディスク情報を表示
atop コマンドを使ってみた
では、実際に atop コマンドを利用して障害調査を行ってみたいと思います。
調査手順は以下の通りです。
- CloudWatch メトリクスを確認
- atop コマンドを用いてプロセスごとのメトリクスを確認
まずは CloudWatch メトリクスからボトルネックとなったメトリクスを特定し、
その後、atop コマンドからどのプロセスがリソースを消費していたのか特定します。
実際の障害調査ではさらにログファイルの調査がありますが、今回は省略します。
1. CloudWatch メトリクスを確認
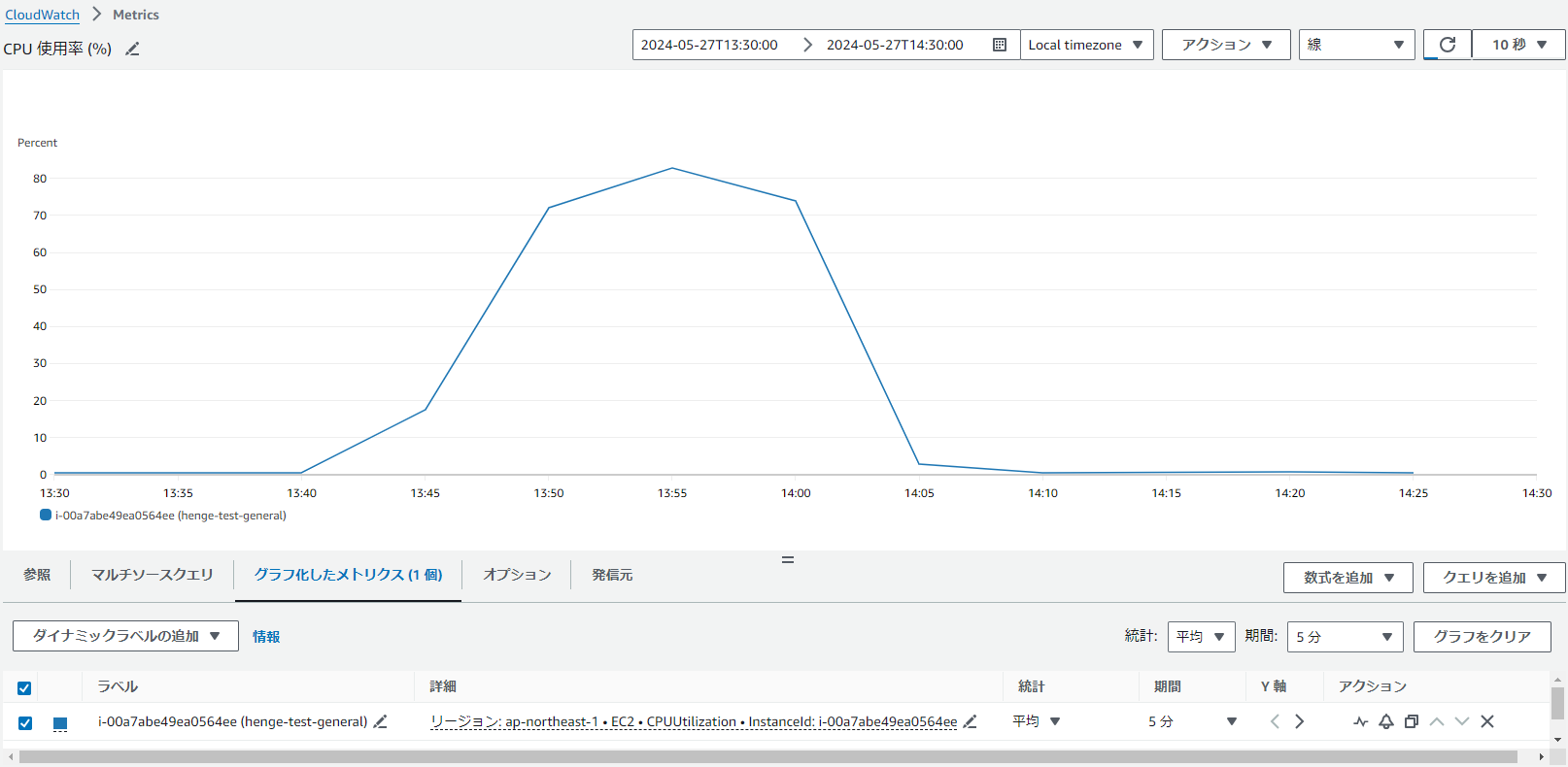
まずは CloudWatch メトリクスを確認し、どのメトリクスがボトルネックになっているのか確認します。
今回は 2024 年 5 月 27 日 13:55 付近にて CPU 使用率の値が高くなっていることが分かりました。
なお、実際の環境では CloudWatch アラームを設定してメトリクスを監視することを推奨します。
その場合、どのメトリクスの値が高いのかは通知内容から分かるため、本手順を省略することが可能です。
2. atop コマンドを用いてプロセスごとのメトリクスを確認
インスタンスにアクセスして atop コマンドを実行し、どのプロセスが CPU 使用率を消費しているのか確認します。
以下のコマンドを実行して障害時刻周辺のメトリクスを表示します。
atop -r /var/log/atop/atop_20240527 -b 1340 -s 1410
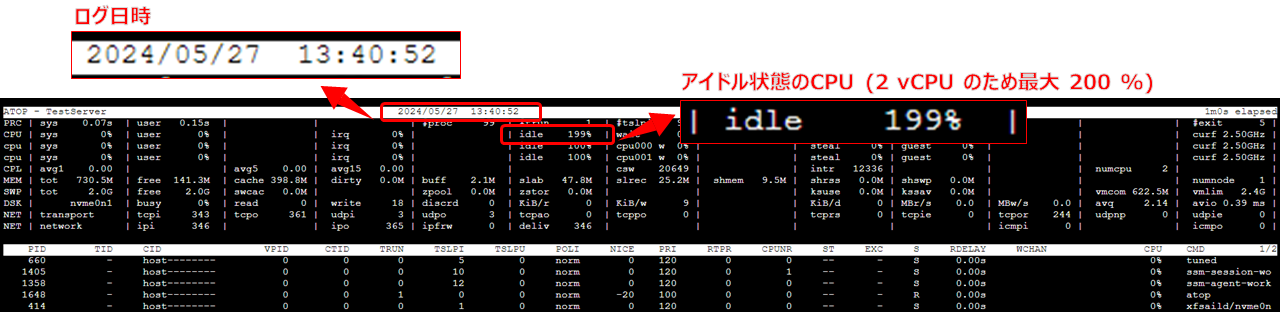
すると、13:40 時点のメトリクスが表示されますが、画面上部の CPU 列の idle の値が高いので、現時点ではまだ問題なさそうです。
では、t オプションで時間を進めます。
なお、デフォルトのメトリクス取得間隔は 10 分となっていますが、今回の検証では 1 分ごとに取得するように設定を変更しています。
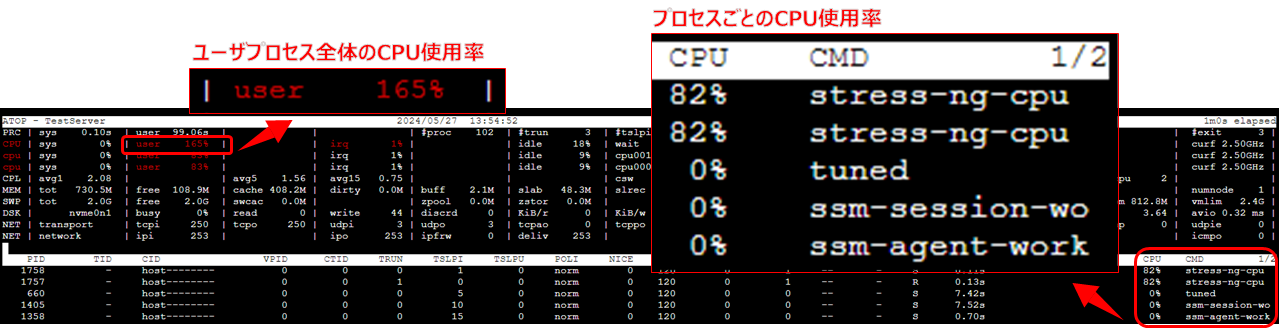
13:54 まで時間を進めると CPU 使用率が上昇してきました。
値が異常なものは赤字で強調表示されています。
そこで、画像右下の部分を見るとプロセスごとの CPU 使用率とそのコマンドが表示されています。
今回は stress-ng-cpu というコマンドが原因だと分かります。
実は AWS FIS というサービスでこのインスタンスの CPU に負荷を与えていたのですが、このコマンドが実行されていたようです。
まとめ
今回は atop コマンドを利用した EC2 の障害調査方法についてご紹介しました。
個人的には障害調査で EC2 のどこが原因なのか分からなくて調査が進まないという経験が多いので、atop コマンドの存在はありがたい限りです。
皆さんも atop コマンドを導入して良き障害調査ライフをお過ごしください!
Appendix

第二SAチームのhengeです。 ゲームとゴルフが好きなエンジニアです。 よろしくお願いします。


Recommends
こちらもおすすめ
-

AWS無料セミナー開催レポート | 大人気のAWS入門セミナー
2018.11.17
-

【ハンズオン】AWSで実用的なWordPressを構築してみる!
2022.8.31



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16