Cloud Spanner の構成を徹底解説!
2024.12.24

この記事は NHN テコラス Advent Calendar 2024の24日目の記事です。
はじめに
こんにちは、Koo です。
今回は、Google Cloud のデータベースサービスである Cloud Spanner の構成について解説します。
Cloud Spanner は、世界中にデータを分散させながらも、一貫性を保つことができる強力なデータベースです。
Cloud Spanner がなぜ大規模サービスを支えることができるのか、構成を見ながらその秘密を一緒に見ていきましょう!
Cloud Spanner とは
Cloud Spanner が何か分からない方は、こちらの記事をご覧ください!

Cloud Spanner の基本構成
まずは、Cloud Spanner の基本的な構成要素を理解しましょう!
(1)Cloud Spanner の仕組み
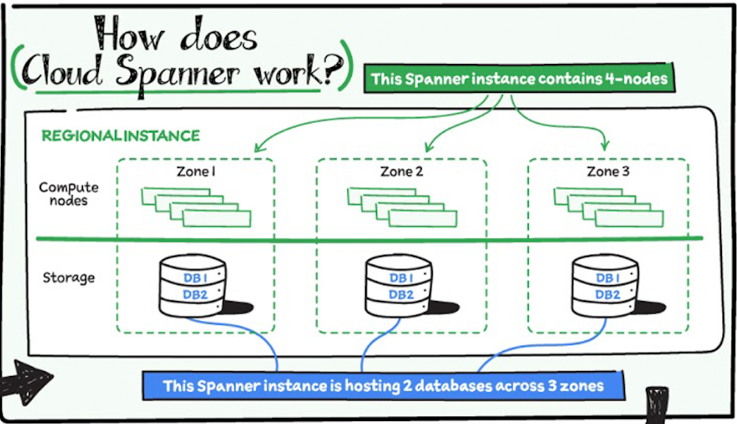
この図では、4つのノードが3つのゾーンに分散されています。ノードはデータを処理する場所、ゾーンはデータを保管する場所だと考えてください。
Cloud Spanner は、データ処理を行うコンピューティング層と、データを保管するストレージ層の2つの層に分かれています。
この2つの層が分離していることで、Cloud Spanner は柔軟性と高い可用性を実現しています。
(2)用語解説
■ ノード
ノードは Spanner のコンピューティング単位です。
読み書きの処理や、データベースへの変更処理などを行います。
例えば、コンピューティング階層は図書館の司書のように、ユーザーが要求したデータを探して整理する役割を果たします。
1ノード = 1,000PU(processing unit)に相当し、処理能力を柔軟に調整できます。
「1,000PU未満は100単位、1,000PU以上なら1,000単位で調整可能」
ノードはデータベースの読み取り、書き込み、およびトランザクションの Commit を処理します。
1ノードの単純な1つのレコードを読み書き処理の QPS を表に示します。
| インスタンス構成タイプ | ピーク時の読み取り(QPS) | ピーク時の書き込み(QPS) |
|---|---|---|
| シングルリージョン | 22,500 | 3,500 |
| デュアルリージョンとマルチリージョン | 15,000 | 2,700 |
参考 : パフォーマンスとストレージの改善
■ ストレージ (Colossus)
データは、Colossus という Google の分散ストレージシステムに保管されます。
Colossus は、大量のデータを安全に、かつ効率的に保管することができます。
例えば、図書館の本棚のようにデータを保存し、安全に保管する役割を果たします。
データが個々のノードに縛られていないため、負荷を再分散する際に大いに役立ちます。
■ Split
構成の図には2つのデータベースが表示されていますが、実際にはこれらのデータベースの内部は「Split」と呼ばれる小さな単位に分割されています。
データベースのデータ量が増えてくると、Cloud Spanner は自動的にデータを分割し、負荷を分散します。
これにより、大量のデータでも高速に処理することができます。
この Split は、それぞれリーダーを選出します。
■ TrueTime API

出典 : TrueTime
TrueTime API は、すべての Google サーバーのアプリケーションに提供される、可用性の高い分散型時計システムです。
Google が世界中に持つ原子時計と GPS アンテナを使って、高精度の時刻同期を実現しています。
これにより、世界中に分散したデータであっても、正確な時間順序を保証し、データの整合性を保つことができます。
Cloud Spanner は、この TrueTime API を使って、世界中に分散したデータでも一貫性を保つことができます。
■ Jupiter Network
Jupiter Network は、Google データセンター内部でデータを非常に高速かつ安定的にやり取りできる超高速ネットワークです。
コンピューティング層とストレージ層の間を高速でデータがやり取りできるようにします。
これにより、データを処理する部分とデータを保管する部分が遠く離れていても、遅延なく高速に通信ができます。
参考 : 25 years of Google data-center networking evolution
なぜ Cloud Spanner が選ばれるのか?
Cloud Spanner は、これらの要素を組み合わせることで、以下のような優れた特性を持っています。
これらの特性は、特に大規模サービスやグローバルサービスを運用する上で非常に重要です。
(1)高い可用性
上の構成図を思い出してください!
Cloud Spanner は、データを複数のゾーンに分散し、自動的に複製します。
この複製は、単なるコピーではありません。
Colossus と呼ばれる分散ストレージシステム上で、データの整合性を保ちながら行われます。
さらに、Split という単位で細かく分割されたデータは、それぞれリーダーが選出され、ゾーン障害時には自動でリーダーが切り替わるため、ダウンタイムを最小限に抑えられます。
他の DB のゾーン分散とは異なり、Colossus 上の分散ストレージと Split の組み合わせで、極めて高い可用性と堅牢性を実現しています。
(2)柔軟な拡張性
Cloud Spanner の最大の特長の一つが、コンピューティング層(ノード)とストレージ層(Colossus)が完全に分離している点です。
これにより、個別のリソースを独立してスケールさせることができます。
例えば、読み書き処理の増加にはノード数を増やし、データ量の増加にはストレージ容量を増やすというように、ニーズに合わせて柔軟にリソースを調整できます。
さらに、Split と呼ばれる単位でデータを分割することで、ノードをスケールアウトさせるときにデータ分割単位で処理を分散できます。
他のデータベースのように、単一サーバーの性能を上げるスケールアップではなく、スケールアウトによる水平分散で性能を向上させることができます。
この柔軟性があることで、コストを最適化できるだけでなく、予測不可能なトラフィック変動にも対応できます。
(3)グローバルな一貫性
Cloud Spanner が、世界中に分散したデータに対するトランザクション処理でも一貫性を保てるのは、TrueTime API という独自の仕組みがあるからです。
原子時計と GPS アンテナを組み合わせることで、ほぼ同時刻に世界中のサーバーで正確な時刻を共有できます。
これにより、世界中のどの場所でデータが更新されても、その変更が全世界のノードで一貫した順序で適用されます。
他のデータベースでは、分散環境におけるデータの一貫性維持のために複雑な処理が必要になります。
Cloud Spanner は TrueTime API によって、この問題を自動的に解決してくれるため、開発者はビジネスロジックに集中できます。
Cloud Spanner の導入事例
最後に、Cloud Spanner がどのように活用されているのか、具体的な事例をいくつか紹介します!
(1)Sprocket 株式会社
Sprocket 株式会社は、顧客行動データの分析基盤に Cloud Spanner を導入しました。以前は、大量の顧客行動データを処理する際に、コストとパフォーマンスの両面で課題を抱えていました。しかし、Cloud Spanner の柔軟なスケーラビリティと高い読み書き性能を活用することで、データ処理コストを大幅に削減し、分析処理を高速化することに成功しました。さらに、一時的なトラフィック増加にも柔軟に対応できるため、ビジネスチャンスを逃すことなく、サービスの拡充を推進しています。
参考 : 株式会社 Sprocket: 顧客行動データの保管先を Spanner に移行、運用コスト削減とサービスの拡充を推進
(2)Glance
Glance は、従来のドキュメントデータベースで、読み書き性能に課題を感じていました。そこで、Cloud Spanner の高い読み書き性能とグローバルな一貫性に着目し、ドキュメントデータベースを Cloud Spanner に移行しました。
その結果、読み書き性能が大幅に向上し、データベース運用にかかるコストと手間を削減することに成功しました。また、グローバルに展開するサービスにおいても、データの一貫性を保ちながら安定的な運用が可能になりました。
参考 : Spanner によりデータベース運用を改善した Glance の事例
(3)バンダイナムコエンターテインメント / バンダイナムコスタジオ
バンダイナムコエンターテインメント / バンダイナムコスタジオでは、ゲームの特性上、ユーザー数が時間帯やイベントによって大きく変動するため、既存のデータベースでは拡張性と可用性に課題がありました。
Cloud Spanner を導入した結果、高い拡張性と可用性を実現し、ユーザー数の急増にも柔軟に対応できるようになりました。さらに、ダウンタイムなしでゲームサービスを安定的に提供できるようになったことで、ユーザー体験を向上させるとともに、運用コストを削減することにも成功しました。
参考 : 『ドラゴンボール レジェンズ』の舞台裏を支える Google Cloud
さいごに
今回紹介いたしました構成は、Cloud Spanner の基本構成です。
本日の内容で Cloud Spanner がどうやって構成しているのか理解できましたら嬉しいです。
次回は、トランザクション、シャーディング構成など解説する予定です。
クリスマスイブに Cloud Spanner を学んでいただき、ありがとうございます!
最後までご覧いただきありがとうございました!

料理と音楽が好きなデータベースエンジニアです。 MySQL と Google Cloud、特に Cloud Spanner への関心が高いです。


Recommends
こちらもおすすめ
-

【イベント参加】Oracle HeatWave Meet in Tokyo
2025.12.4
-
Cloud Spanner のリージョンを徹底解説!
2024.10.25
-

Cloud Spanner の Data Boost を試してみた!
2024.11.29


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16