Alexa Skills Kitでしりとりスキルを作ってみる②:Lambda関数の設定~テスト

はじめに
こんにちは。データサイエンスチームのmotchieです。
この記事では、Alexa Skills Kitでしりとりスキルを作成していきます。
Alexa Skills Kit for Node.js (以下、Alexa SDK)を使い、アレクサとしりとりが出来るようにLambda関数を設定し、テストシミュレーターを使ってスキルをテストしてみます。
Alexa SDKに関して、ステートハンドラによるインテント制御、セッションアトリビュートによる情報の保持、ElicitSlotディレクトリによる単一スロットのみの発話の認識、スロット値の取得、などの方法を見ていきます。
また、形態素解析器kuromoji.jsによる品詞判定や読み仮名取得の方法や、Lambdaで実行する際の注意点も見ていきたいと思います。
この記事は、NHN テコラス DATAHOTEL:確率統計・機械学習・ビッグデータを語る Advent Calendar 2017 23日目の記事です。
0. 前提
この記事は②になります。アカウント作成~対話モデルの設定まで手順はこちらの記事をご覧ください。
Alexa Skills Kitでしりとりスキルを作ってみる①:アカウント作成~対話モデル設定
1. Node.jsデプロイパッケージの作成
node.jsのプロジェクト用にディレクトリを作り、必要なファイルを作成していきます。
最終的な関数パッケージの中身は以下のようになります。
lambda-package.zip ├── alexaVocab.json ├── index.js ├── node_modules │ ├── alexa-sdk │ ├── async │ ├── aws-sdk │ ├── base64-js │ ├── buffer │ ├── crypto-browserify │ ├── doublearray │ ├── events │ ├── i18next │ ├── i18next-sprintf-postprocessor │ ├── ieee754 │ ├── isarray │ ├── jmespath │ ├── kuromoji │ ├── lodash │ ├── punycode │ ├── querystring │ ├── sax │ ├── url │ ├── uuid │ ├── xml2js │ ├── xmlbuilder │ └── zlibjs └── package.json
それではさっそく作っていきましょう!
1.1 npmによるパッケージの取得
まず、必要なnode.jsのパッケージのインストールしていきます。
node.jsをこれからインストールする場合は、node.jsのバージョン管理が容易なnvmでインストールするのがオススメです。
GitHub – creationix/nvm: Node Version Manager – Simple bash script to manage multiple active node.js versions
パッケージのインストールにはnpmを用います。
Alexa SDKとkuromoji.jsのパッケージを取得します。
npm init # パッケージ定義の作成。デフォルトでOK npm install --save alexa-sdk kuromoji # パッケージのインストール
作成されたpackage.jsonは以下のような内容になっているかと思います。
{
"name": "alexa-siritori",
"version": "1.0.0",
"description": "Alexa custom skill to play siritori game.",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "motchie",
"license": "ISC",
"dependencies": {
"alexa-sdk": "^1.0.24",
"kuromoji": "^0.1.1"
}
}
1.2 エンドポイントの作成
アプリのメイン部分になるエントリポイントを作成していきます。
index.jsを作成し、以下の内容を貼り付けます。
"use strict";
const Alexa = require("alexa-sdk");
const _ = require("lodash");
const kuromoji = require("kuromoji");
const alexaVocab = require("alexaVocab.json")
const APP_ID = undefined;
const GAME_NAME = "しりとりスキル";
const START_MESSAGE = "しりとりスキルへようこそ。" +
"ゲームを始めるには、まず、「しりとり」と言ってみてください。";
const UNHANDLED = "聞き取れませんでした。もう一度言ってください。";
const HELP_MESSAGE = "しりとりを続けますか?" +
"続ける場合は「はい」、やめる場合は「いいえ」、と言ってください。";
const CANCEL_MESSAGE = "しりとりを終了します。";
const SURRENDER_MESSAGE = "返せる言葉がありません。あなたの勝ちです。";
const KUROMOJI_DICT_PATH = "node_modules/kuromoji/dict/";
// ステートによるスキルの状態管理
const GAME_STATES = {
START: "_STARTMODE",
SIRITORI: "_SIRITORIMODE",
HELP: "_HELPMODE",
};
// スキル起動時のステートハンドラ
const newSessionHandlers = {
"LaunchRequest": function () {
// ゲームスタート時のステートをセット
this.handler.state = GAME_STATES.START;
this.emitWithState("NewGame");
},
"AMAZON.StartOverIntent": function () {
this.handler.state = GAME_STATES.START;
this.emitWithState("NewGame");
},
"AMAZON.HelpIntent": function () {
this.handler.state = GAME_STATES.HELP;
this.emitWithState("helpTheUser");
},
"Unhandled": function () {
const speechOutput = UNHANDLED;
this.emit(":ask", speechOutput);
}
};
// しりとりスタート時のステートハンドラ
const startStateHandlers = Alexa.CreateStateHandler(GAME_STATES.START,{
"NewGame": function () {
// ゲーム中のステートをセット
this.handler.state = GAME_STATES.SIRITORI;
const speechOutput = START_MESSAGE;
this.emit(":ask", speechOutput);
},
"Unhandled": function () {
const speechOutput = UNHANDLED;
this.emit(":ask", speechOutput);
},
});
// しりとりゲーム中のステートハンドラ
const siritoriStateHandlers = Alexa.CreateStateHandler(GAME_STATES.SIRITORI,{
"SiritoriIntent" : function () {
// 既出単語の配列をセッションアトリビュートから参照する
let previousWords = this.attributes["previousWords"];
// 初回の処理(入力は「しりとり」)
if (previousWords == null) {
// 「リ」から始まる単語を辞書から取得する
const answer = alexaVocab.words["リ"][0]
// 既出単語の配列に代入する
this.attributes["previousWords"] = [ answer ];
this.emit(":elicitSlot", "SiritoriWord", answer);
}
// GAME_STATES.HELPステートから復帰時の処理
if (this.attributes["break"]) {
this.attributes["break"] = false;
const speechOutput = "しりとりを再開します。前の単語は、" +
previousWords[previousWords.length-1] + "です。" +
"次の単語を入力してください。";
this.emit(":elicitSlot", "SiritoriWord", speechOutput);
}
// SiritoriWordのスロット値を取得する
const inputWord = this.event.request.intent.slots.SiritoriWord.value;
// スロット値が空の場合
if (inputWord == null) {
const speechOutput = "単語が取得できませんでした。" +
"違う単語を試してみてください。";
this.emit(":elicitSlot", "SiritoriWord", speechOutput);
}
// 同期処理を設定し、形態素変換が終わってから以後のしりとり処理が行われるようにする
new Promise((resolve, reject) => {
// kuromojiによる形態素変換
kuromoji.builder({dicPath: KUROMOJI_DICT_PATH }).build(
function (err, tokenizer) {
if(err) {
throw err;
}
resolve(tokenizer.tokenize(String(inputWord)));
}
)
}).then((tok) => {
// 形態素変換を繰り返すとメモリリークが起こるため、
// 強制的にガベージコレクションを開始する
gc();
// 入力単語が名詞一単語ではない場合
if (tok.length > 1 || tok[0].pos != "名詞") {
this.emit(":elicitSlot", "SiritoriWord",
inputWord + "、は使えない言葉です。名詞一単語で答えてください。");
}
// 読み仮名が取得できない単語の場合
if (!tok[0].hasOwnProperty("reading")) {
const speechOutput = "単語の読みがなが取得できません。" +
"違う単語を試してみてください。";
this.emit(":elicitSlot", "SiritoriWord", speechOutput);
}
// 読み仮名(カタカナ)の取得
const inputWordReading = tok[0].reading;
// 入力単語・前回単語の頭の文字・末尾の文字を取得する
const inputHeadChar = inputWordReading.slice(0, 1);
// 単語末尾の伸ばし棒は削除する
const inputLastChar = inputWordReading
.replace(new RegExp("ー$"), "").slice(-1);
const previousLastChar = previousWords[previousWords.length-1]
.replace(new RegExp("ー$"), "").slice(-1);
// 入力単語の先頭文字が間違っている場合
if (previousLastChar != inputHeadChar) {
const speechOutput = inputWordReading + "は先頭の文字が" +
previousLastChar + "ではありません。" +
previousLastChar + "から始まる単語を入力してください";
this.emit(":elicitSlot", "SiritoriWord", speechOutput);
}
// 入力単語が既出である場合
if (previousWords.indexOf(inputWordReading) != -1) {
const speechOutput = inputWordReading +
"は既に使われた単語です。他の単語を入力してください";
this.emit(":elicitSlot", "SiritoriWord", speechOutput);
}
// 入力単語が「ん」で終わる場合。アレクサの勝利とし、スキルを終了する
if (inputLastChar == "ン") {
const speechOutput = inputWordReading +
"は、「ん」で終わる単語ですね。" +
"しりとりは私の勝ちです。またの挑戦を待っています。";
this.emit(":tell", speechOutput);
}
// 次に返せる単語を辞書から探す
const answers = _.difference(
alexaVocab.words[inputLastChar],
previousWords
);
// 返せる単語がある場合
if (answers.length > 0) {
const answer = answers[0];
// ユーザーの入力単語・アレクサの返答単語の順で、
// 既出単語の配列に追加していく
previousWords.push(inputWordReading);
previousWords.push(answer);
// セッションアトリビュートに代入し、既出単語の配列を更新する
this.attributes["previousWords"] = previousWords;
this.emit(":elicitSlot", "SiritoriWord", answer);
}
// 返せる単語がない場合。ユーザーの勝利とし、スキルを終了する
this.emit(":tell", SURRENDER_MESSAGE);
})
},
"AMAZON.HelpIntent": function () {
this.handler.state = GAME_STATES.HELP;
this.emitWithState("helpTheUser", false);
},
"AMAZON.StopIntent": function () {
this.handler.state = GAME_STATES.HELP;
this.emitWithState("helpTheUser", false);
},
"AMAZON.CancelIntent": function () {
const speechOutput = CANCEL_MESSAGE;
this.emit(":tell", speechOutput);
},
"Unhandled": function () {
const speechOutput = UNHANDLED;
this.emit(":ask", speechOutput);
}
});
// ヘルプが呼び出された際のステートハンドラ
const helpStateHandlers = Alexa.CreateStateHandler(GAME_STATES.HELP,{
"helpTheUser": function () {
const speechOutput = HELP_MESSAGE;
this.emit(":ask", speechOutput);
},
"AMAZON.StartOverIntent": function () {
this.handler.state = GAME_STATES.START;
this.emitWithState("NewGame");
},
"AMAZON.HelpIntent": function () {
this.emitWithState("helpTheUser");
},
// しりとりを続ける場合
"AMAZON.YesIntent": function () {
// 復帰時の処理のため
this.attributes["break"] = true;
this.handler.state = GAME_STATES.SIRITORI;
this.emitWithState("SiritoriIntent");
},
"AMAZON.NoIntent": function () {
const speechOutput = CANCEL_MESSAGE;
this.emit(":tell", speechOutput);
},
"AMAZON.StopIntent": function () {
const speechOutput = HELP_MESSAGE;
this.emit(":tell", speechOutput);
},
"AMAZON.CancelIntent": function () {
const speechOutput = CANCEL_MESSAGE;
this.emit(":tell", speechOutput);
},
"Unhandled": function () {
const speechOutput = UNHANDLED;
this.emit(":ask", speechOutput);
},
});
exports.handler = function (event, context) {
const alexa = Alexa.handler(event, context);
alexa.APP_ID = APP_ID;
alexa.registerHandlers(newSessionHandlers, startStateHandlers,
siritoriStateHandlers, helpStateHandlers);
alexa.execute();
};
Alexa SDKの使い方については、こちらの記事を参考にさせていただきました。
Alexaスキル開発トレーニングシリーズ 第3回 音声ユーザーインターフェースの設計
ここで、コードの中身とAlexa SDKの使い方について見ていきたいと思います。
1.2.1 ステートハンドラによるインテントの制御
アレクサとユーザーとの会話が複数回にわたるスキルでは、会話の段階によって呼び出せるインテントを制御する仕組みが必要になります。
しりとりスキルでも、スキル開始時はしりとりゲーム中のインテントSiritoriIntentは呼び出せないようにし、ヘルプが呼び出された時はAmazon.YesIntentでしりとりを終了する、などといったインテント制御を行っています。
会話の段階によって、呼び出すインテントを制御するためには、Alexa SDKではステートという仕組みを用います。
ステートごとにステートハンドラを定義し、会話が特定の段階(ステート)の場合に呼び出せるインテントを、ステートハンドラごとに定義します。
ステートハンドラの実装については、こちらを参考にさせていただきました。
GitHub – alexa/skill-sample-nodejs-trivia
// ステートによるスキルの状態管理
const GAME_STATES = {
START: "_STARTMODE",
SIRITORI: "_SIRITORIMODE",
HELP: "_HELPMODE",
};
しりとりスキルではステートとして、しりとりスタート時のSTARTMODE、しりとりゲーム中のSIRITORIMODE、ヘルプが呼び出された際のHELPMODEを定義しました。
// スキル起動時のステートハンドラ
const newSessionHandlers = {
"LaunchRequest": function () {
// ゲームスタート時のステートをセット
this.handler.state = GAME_STATES.START;
this.emitWithState("NewGame");
},
(中略)
// しりとりスタート時のステートハンドラ
const startStateHandlers = Alexa.CreateStateHandler(GAME_STATES.START,{
"NewGame": function () {
起動時は何もステートを持たないため、newSessionHandlersのハンドラのインテントが呼ばれます。
this.handler.stateにステートの値を代入することで、そのステートに紐付くステートハンドラのインテントが呼び出されるようになります。
ステートハンドラは、Alexa.CreateStateHandlerメソッドでステートとハンドラを設定して作成します。
exports.handler = function (event, context) {
(中略)
alexa.registerHandlers(newSessionHandlers, startStateHandlers,
siritoriStateHandlers, helpStateHandlers);
また、ステートハンドラは、通常のハンドラと同じように、alexa.registerHandlersメソッドで登録します。
1.2.2 セッションアトリビュートによる情報の保持
アレクサとユーザーとの会話が複数回にわたるスキルでは、ユーザーから入力された情報を保存しておき、後で参照できる仕組みが必要です。
Alexa SDKではセッションアトリビュートによって、会話(セッション)をまたいで情報を保持することが出来ます。
// 既出単語の配列をセッションアトリビュートから参照する let previousWords = this.attributes["previousWords"]; (中略) // ユーザーの入力単語・アレクサの返答単語の順で、既出単語の配列に追加していく previousWords.push(inputWordReading); previousWords.push(answer); // セッションアトリビュートに代入し、既出単語の配列を更新する this.attributes["previousWords"] = previousWords;
しりとりスキルでは、セッションアトリビュートの値として既出単語の配列を保持しています。
しりとり処理ごとに、this.attributesの要素から参照、配列に新しい単語を加えて更新し、this.attributesの要素に代入し直しています。
1.2.3 レスポンスアクションによる複数回のやりとり
アレクサがレスポンスを返した後、セッションを維持してユーザーから次の返答を待つか、返答を待たずにスキルを終了するか、2種類のアクションが考えられます。
これらのアクションは、emitメソッドの引数で指定します。
this.emit(":tell", SURRENDER_MESSAGE);
:tellを指定し、単発のレスポンスを返します。発話が終わるとセッションが終了し、スキルが終わります。
const speechOutput = START_MESSAGE;
this.emit(":ask", speechOutput);
:askを指定すると、レスポンスを返した後、ユーザーからの応答を待ち、セッションを維持します。複数回の会話を行う際には、基本的にこの:askを指定します。
this.emit(":elicitSlot", "SiritoriWord", answer);
:elicitSlotを指定することで、レスポンスを返した後、セッションを維持して、特定のスロット値に関するユーザーの返答を待つことができます。
通常は、単一スロット値のみの発話は認識できません。しかし、ElicitSlotディレクティブを使うことで、単一のスロット値のみの発話を認識してインテントを呼び出す事が出来ます。
しりとりスキルでは、しりとり単語(SiritoriWordスロット)のみの発話を認識するため、:elicitSlotを多用しています。:elicitSlotでは、emitメソッドの引数として、引き出すスロット名SiritoriWordを指定します。
1.2.4 スロットによるしりとり単語の取得
// SiritoriWordのスロット値を取得する const inputWord = this.event.request.intent.slots.SiritoriWord.value;
スロット名SiritoriWordを指定して、ユーザーが入力した言葉を取得します。対話モデルでのインテント・スロットの設定については、前回の記事をご覧ください。
スロットの値として取得される単語は、SiritoriWordのスロットタイプSiritoriWordType作成時に追加した単語に偏重されますが、それ以外の単語でも認識されます。
1.2.5 kuromoji.jsによる単語の品詞判定と読み仮名取得
スロットから取得した言葉は、既に漢字変換などの処理が行われているため、しりとり処理で使うためには読み仮名へと変換する必要があります。
また、入力された言葉がちゃんと名詞一単語であるか、チェックする必要があります。
今回は、JavaScriptの形態素解析器kuromoji.jsを使い、入力された単語の読み仮名の取得と、入力が1つの名詞からなる単語かどうかの判定を行います。
takuyaa/kuromoji.js – GitHub
[ { word_id: 190420,
word_type: "KNOWN",
word_position: 1,
surface_form: "西瓜",
pos: "名詞",
pos_detail_1: "一般",
pos_detail_2: "*",
pos_detail_3: "*",
conjugated_type: "*",
conjugated_form: "*",
basic_form: "西瓜",
reading: "スイカ",
pronunciation: "スイカ" } ]
例えば、「西瓜」をkuromoji.jsで形態素変換した結果は上のようになります。
結果は配列で得られるため、品詞はtok[0].pos, 読み仮名はtok[0].readingといった形で取得できます。
// 同期処理を設定し、形態素変換が終わってから以後のしりとり処理が行われるようにする
new Promise((resolve, reject) => {
// kuromojiによる形態素変換
kuromoji.builder({dicPath: KUROMOJI_DICT_PATH }).build(
function (err, tokenizer) {
if(err) {
throw err;
}
resolve(tokenizer.tokenize(String(inputWord)));
}
)
}).then((tok) => {
今回、Promiseを用いて同期処理を設定することで、形態素変換が終わるのを待ってから、以降のしりとり処理が行われるようにしました。
tokenizer.tokenize(String(inputWord))で形態素変換した結果をresolveの引数で渡し、then節の中でのしりとり処理で使っています。
また、スロットから取得した単語をそのまま形態素変換しようとするとTypeError: Cannot read property "search" of undefinedというエラーが出るため、Stringにキャストする必要があります。(原因調査中です…)
// 形態素変換を繰り返すことでメモリリークが起こるため、 // 強制的にガベージコレクションを開始する gc();
複数回のやりとりをしていくうちに、Lambdaのメモリ使用量が増えていってエラーになる問題に直面しました。
形態素変換で確保したメモリが開放されずに残っているのかもしれないと思い、強制的にガベージコレクションを実行することで、エラーを回避しています。
Lambdaにおけるnode.jsのメモリリークに関しては、こちらの記事に記述がありました。
AWS Developer Forums: Lambda leaking memory with dire consequences.
// 読み仮名が取得できない単語の場合
if (!tok[0].hasOwnProperty("reading")) {
const speechOutput = "単語の読みがなが取得できません。" +
"違う単語を試してみてください。";
this.emit(":elicitSlot", "SiritoriWord", speechOutput);
}
また、形態素変換の結果、読み仮名(reading)要素を持たない形態素が得られることもあるため、上のように処理を分けています。
1.3 アレクサ用の単語辞書を作成
アレクサがしりとりで使える単語の連想配列を作成します。
プロジェクトのディレクトリにalexaVocab.jsonを作成し、以下の内容を貼り付けます。
{
"words":{
"イ": ["イチゴ"],
"カ": ["カラス", "カメ"],
"ゴ": ["ゴリラ"],
"リ": ["リス"],
"パ": ["パンツ"],
"レ": ["レモネード"]
}
}
keyにしりとり単語の頭の文字, valueにしりとり単語の配列をそれぞれカタカナで入力します。
上記の単語配列の要素を増やしていくことで、アレクサが使える単語を増やしていくことが出来ます。
今回はまたしても力尽きたので極めて少ないボキャブラリーしか設定していませんが、最強のしりとりスキルを目指して、アレクサに使わせてみたい単語をぜひ色々追加してみてください。
カスタムスロットタイプや単語の追加に関しては、次回の記事で詳しく扱う予定です。
1.3 zipファイルの作成
├── alexaVocab.json ├── index.js ├── node_modules │ ├── alexa-sdk │ ├── async │ ├── aws-sdk │ ├── base64-js │ ├── buffer │ ├── crypto-browserify │ ├── doublearray │ ├── events │ ├── i18next │ ├── i18next-sprintf-postprocessor │ ├── ieee754 │ ├── isarray │ ├── jmespath │ ├── kuromoji │ ├── lodash │ ├── punycode │ ├── querystring │ ├── sax │ ├── url │ ├── uuid │ ├── xml2js │ ├── xmlbuilder │ └── zlibjs └── package.json
ここまでの手順が完了すると、ディレクトリ内は上のようになっているかと思います。
zip lambda-package.zip * -r
プロジェクトのディレクトに移り、これらのファイルをzipに圧縮します。
ここまでがLambda関数パッケージの作成でした。次はこのパッケージをAWS上にアップロードしていきます。
2. Lambda関数の作成
AWSマネジメントコンソール
AWSにログインし、Lambda関数を作成していきます。画面左上からサービス一覧を開き、「Lambda」をクリックします。
2.1 関数の作成

左側のタブで「関数」を選択し、「関数の作成」をクリックします。リージョンは東京で作成します。
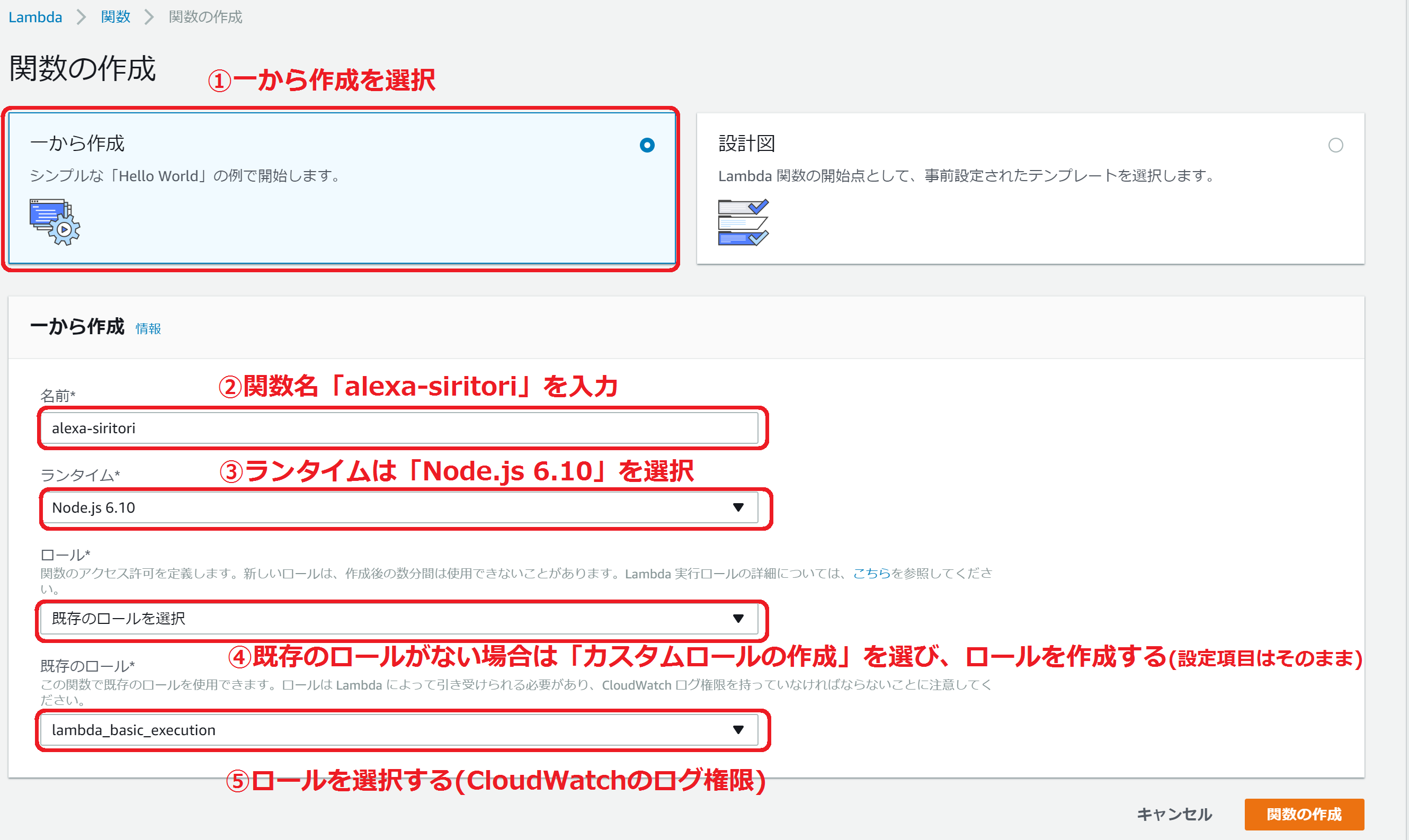
「一から作成」を選択します。今回、関数の名前は「alexa-siritori」としました。CloudWatchログ権限を持つロールを選択します。既存のロールがない場合は、「カスタムロールの作成」を選択し、設定項目はそのままで「許可」ボタンをクリックしてロールを作成します。

「関数の作成」をクリックします。
2.2 トリガーの追加
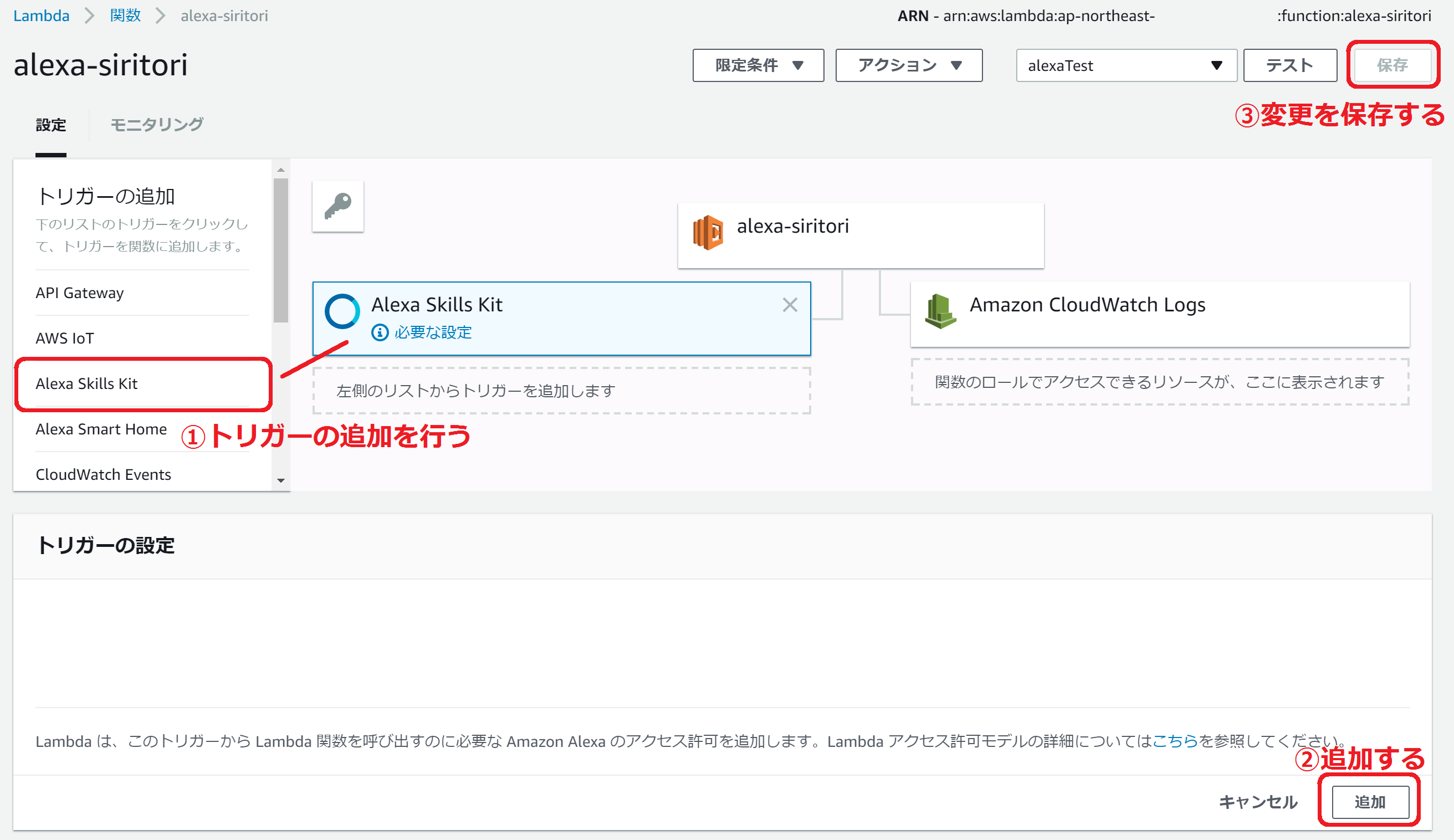
アレクサからLambda関数を呼び出せるように、アクセス許可を追加します。
トリガーの追加タブで「Alexa Skills Kit」を選んで「追加」をクリックします。右上のボタンで変更を保存します。
2.3 関数のアップロード・設定
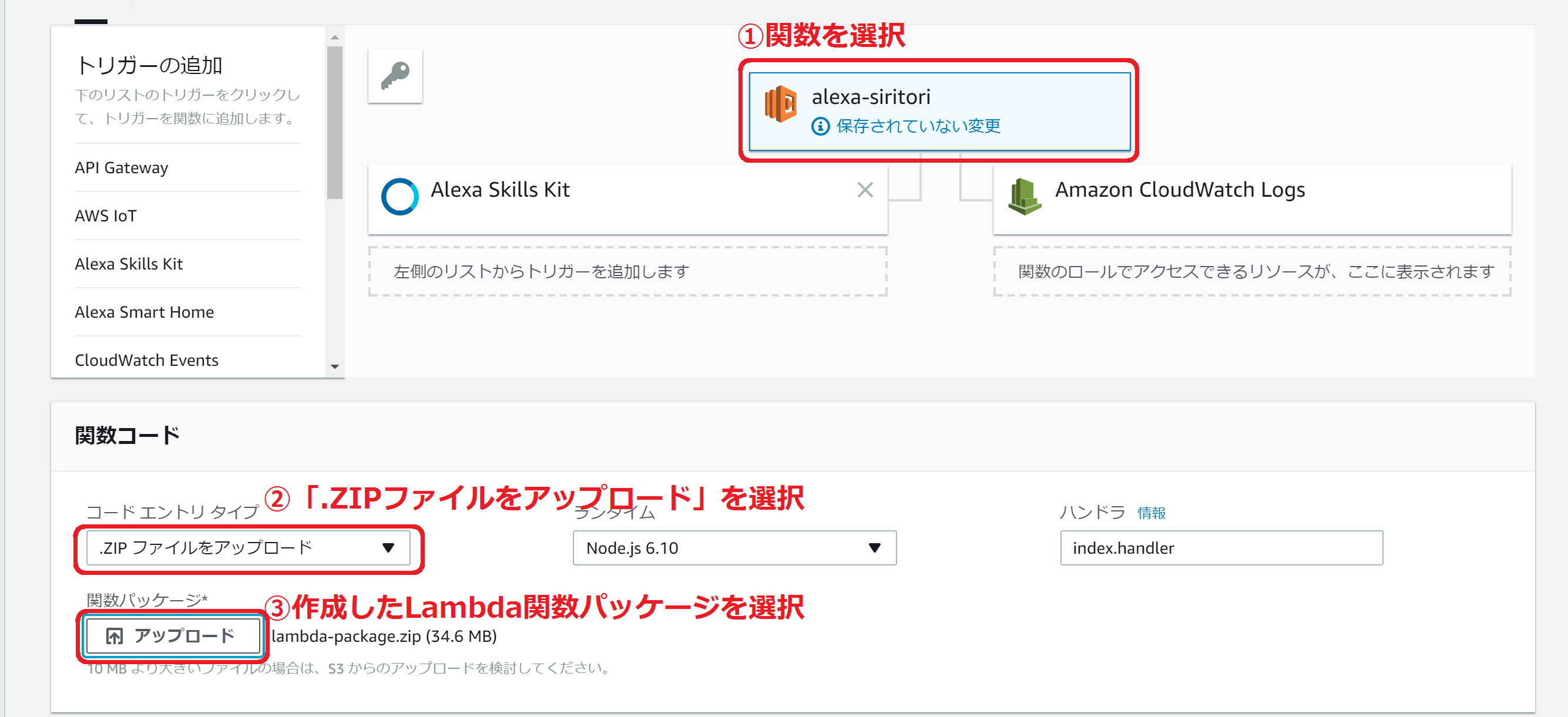
手順1で作成したLambda関数パッケージをアップロードします。
alexa-siritoriの関数を選択します。コードエントリタイプとして「.ZIPファイルをアップロード」を選択し、「アップロード」のボタンをクリックして関数パッケージをアップロードします。

形態素変換の処理にメモリと時間が必要になるため、メモリとタイムアウトの設定を変更します。
ページを下にスクロールしていくと基本設定の項目があります。
今回は、メモリを768MB、タイムアウトを10秒に設定してみます。
もしメモリ不足でエラーになる場合は、こちらの設定を増やしてみてください。

ページ右上のボタンをクリックし、ここまでの変更を保存します。
また、手順3で必要なので、ARNの値をコピーしておきます。
以上まででLambda関数の設定は終了です。次はAmazon開発者コンソールに戻り、スキルとLambdaの接続設定を行います。
3. スキルとLambdaの接続
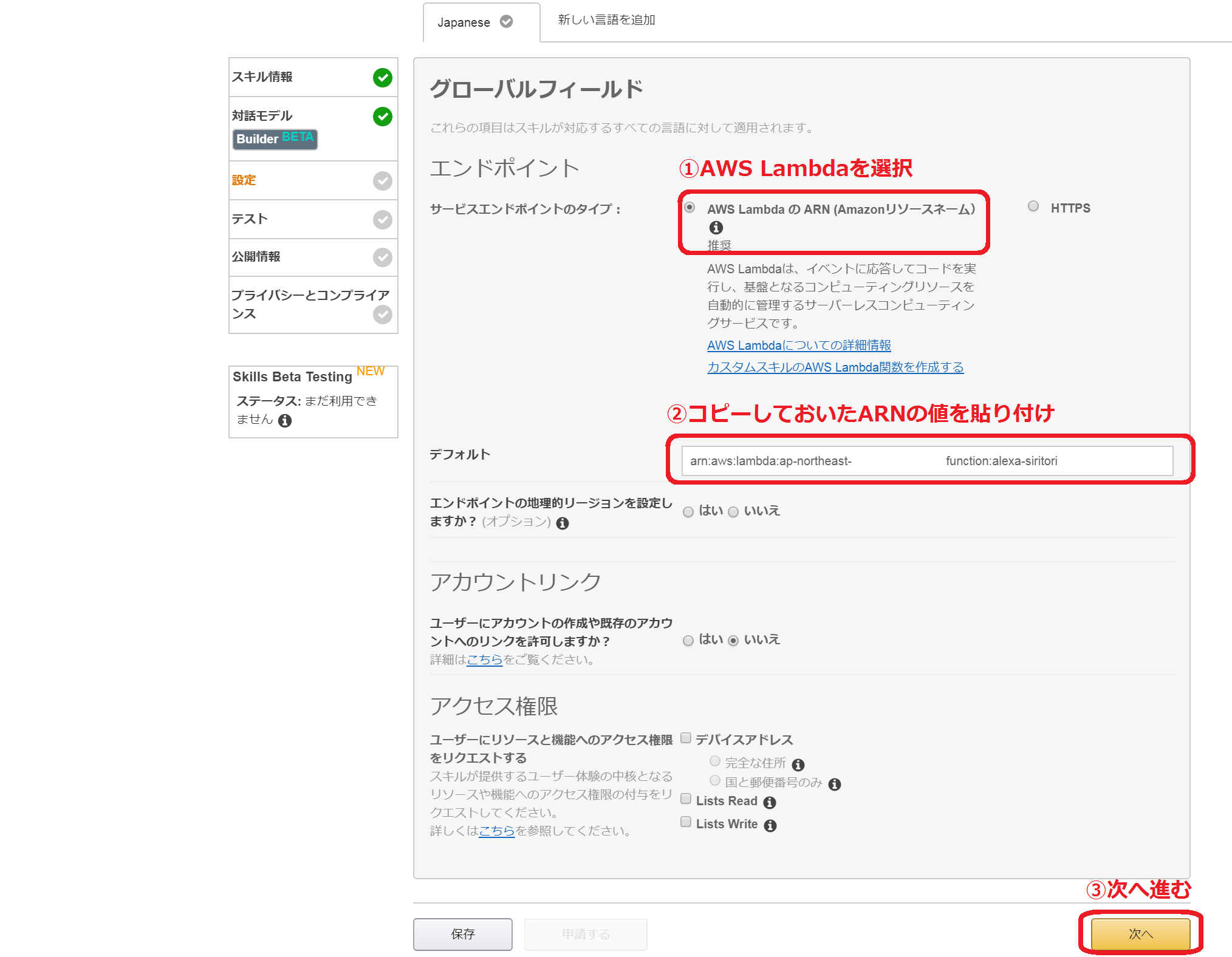
Amazon開発者コンソールのスキル開発に戻ります。左側のタブの上から三つ目の「設定」をクリックします。
エンドポイントのタイプは「AWS LambdaのARN」を選びます。デフォルトの枠に先ほどでコピーしたLambdaのARNの値を貼り付けます。他の設定は既定値のまま「保存」をクリックし、「次へ」をクリックします。
4. スキルのテスト
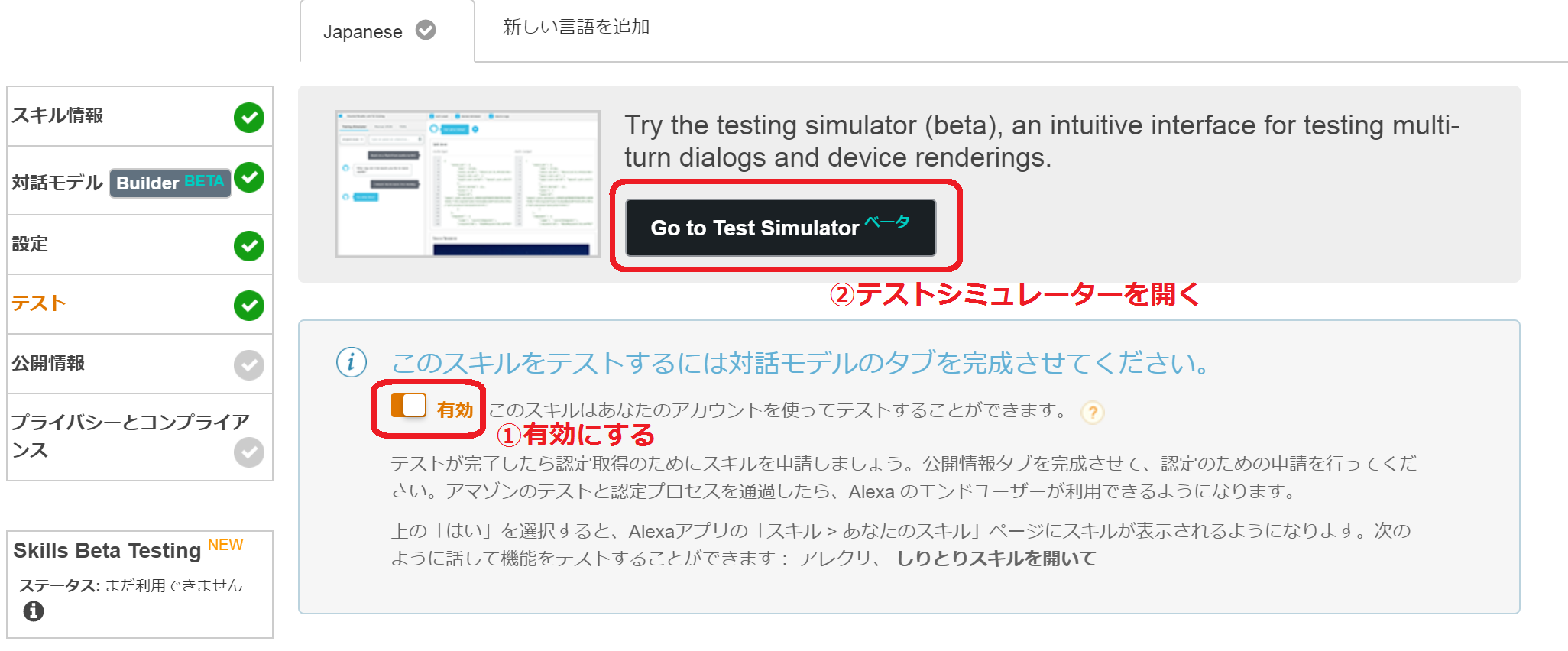
テストを「有効」にし、しりとりスキルをテストできるようにします。
これで、お持ちのアレクサデバイスでしりとりスキルがテストできるようになりました。もしアレクサアプリにスキルが表示されない場合は、開発者コンソールにログインしているAmazonアカウントとアレクサアプリに設定したAmazonアカウントが同じであるか確認してみてください。Amazon.co.jpのアカウントとAmazon.comのアカウントは別物なので注意してください。
また、アレクサデバイスがなくても、テストシミュレーターを使ってスキルのテストを行うことが出来ます。
「Go to Test Simulator」をクリックし、テストシミュレーターを開きます。
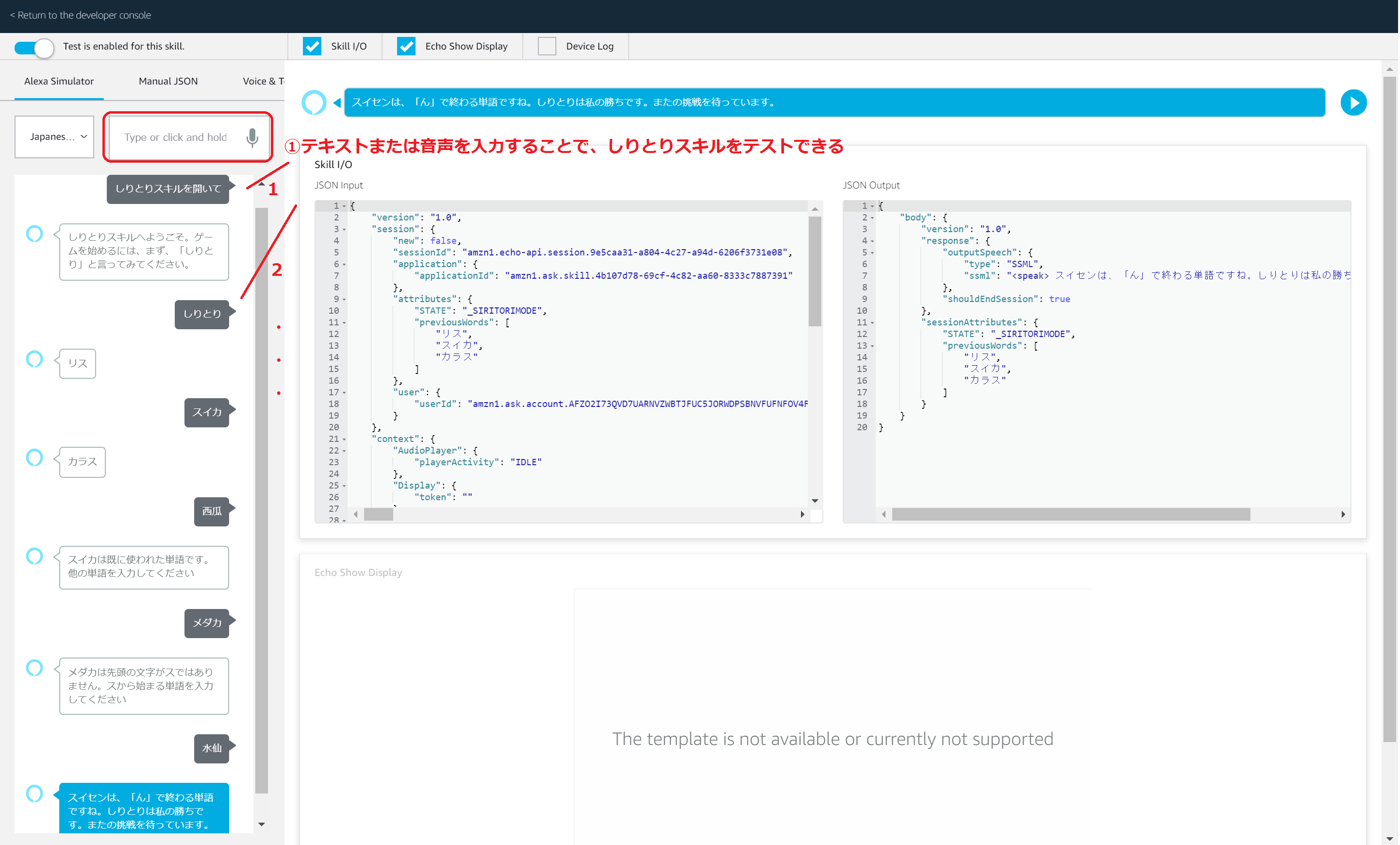
テキストまたは音声を入力して、スキルのテストが行えます。
「しりとりスキルを開いて」と入力してスキルを起動し、しりとりをテストしてみましょう。
注意点ですが、執筆時点(12/22)では、Amazon.co.jpに紐づく開発者アカウントではスキルの起動に失敗します。本記事では、Amazon.comに紐づくアカウントで実行確認を行いました。
テストシミュレーターに関しては、こちらの記事を参考にさせていただきました。
[Alexa] 本日公開された Test Simulator(Beta)を使ってみました
以上がAlexa Skills Kitでしりとりスキルを作ってみた手順になります。
みなさんもぜひ好きな単語を追加して、オリジナルのしりとりスキルを作ってみてください。
まとめ
- この記事では、Alexa Skills Kitによるスキル作成のうち、Node.jsデプロイパッケージの作成、Lambda関数の作成、スキルとLambda関数の接続、スキルのテストまでを行いました。
- Alexa SDKに関して、ステートハンドラによるインテント制御、セッションアトリビュートによる情報の保持、ElicitSlotディレクトリによる単一スロットの発話の認識・スロット値の取得、などの方法を見ていきました。
- kuromoji.jsの使い方、Lambdaで使う際の注意点を見ていきました。
- テストシミュレーターを使ってスキルのテストを行いました。
参考
Alexaスキル開発トレーニングシリーズ 第3回 音声ユーザーインターフェースの設計
Dialogインターフェースのリファレンス | Custom Skills – Amazon Developer
[Alexa] 本日公開された Test Simulator(Beta)を使ってみました
GitHub – alexa/skill-sample-nodejs-trivia
takuyaa/kuromoji.js – GitHub
GitHub – creationix/nvm: Node Version Manager – Simple bash script to manage multiple active node.js versions
AWS Developer Forums: Lambda leaking memory with dire consequences.

2017年4月、NHNテコラスに新卒入社。データサイエンスチームに所属し、AWSを活用したデータ分析サービスの設計開発を担当。


Recommends
こちらもおすすめ
-

Roomba(ルンバ) のお掃除状況を飼い猫に鳴いてもらう
2016.4.18
-

「Hey Siri 掃除をして」で、Roomba(ルンバ)に掃除をしてもらう
2016.4.22




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16