Amazon Redshiftって何ができるの?AWSのデータウェアハウスサービスを解説
こんにちは。データサイエンスチーム tmtkです。
この記事では、Amazon Redshiftを紹介します。
Amazon Redshiftとは
Amazon Redshiftとは、AWSが提供するデータウェアハウスサービスです。
データウェアハウス(DWH)というのは、さまざまなデータ源からデータを収集・統合・蓄積し、分析のため保管しておくシステムです。伝統的なRDBMSとは違って、継続的な書き込みや更新には向いておらず、一括でデータを書き込み分析のため大容量データを読み出すという処理に最適化されています。その結果として、たとえばRDB設計における正規化はデータウェアハウスでは重視されず、読み出しの高速化のためにあえて正規化しないでデータを格納することもあります。
Amazon Redshiftでは、並列コンピューティングをサポートしており、大量のデータを短時間で読み出し・分析することが可能です。
インターフェイスとしては、BIツールやPostgreSQLクライアントから操作することができます。
AWSの活用事例集!

NHNテコラスのC-Chorusから提供するAWS活用支援サービスをご利用いただいたお客様の事例を1冊にまとめました。AWSの導入・移行、運用の最適化やAI・データ分析などへの活用事例をご紹介しています。
Amazon Redshiftを使ってみる
それでは、早速Amazon Redshiftを使ってみます。
準備
Redshiftの設定に入る前に、いくつかの準備をしておきます。
読み込むデータの設置
Redshiftで読み込むサンプルデータとして、Amazon S3に以下の内容のファイル「score.csv」をアップロードします。
Name,English,Mathematics Ichiro,10,10 Jiro,20,40 Saburo,30,90
アップロードした先のURIを「s3://your-bucket/score.csv」とします。
IAM ロールの作成
S3に設置したファイルをRedshiftクラスターから読み込めるよう、Redshiftクラスターに付与するためのIAM ロールを作成します。
まず、AWS マネジメントコンソールからIAM Management Consoleに移動します。画面左側のメニューから「ロール」を選び、「ロールの作成」をクリックします。
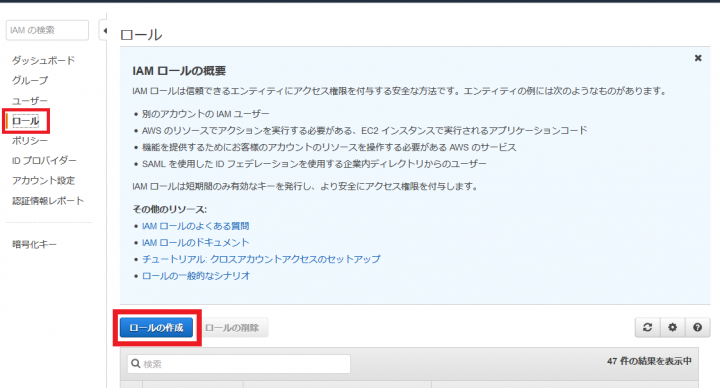
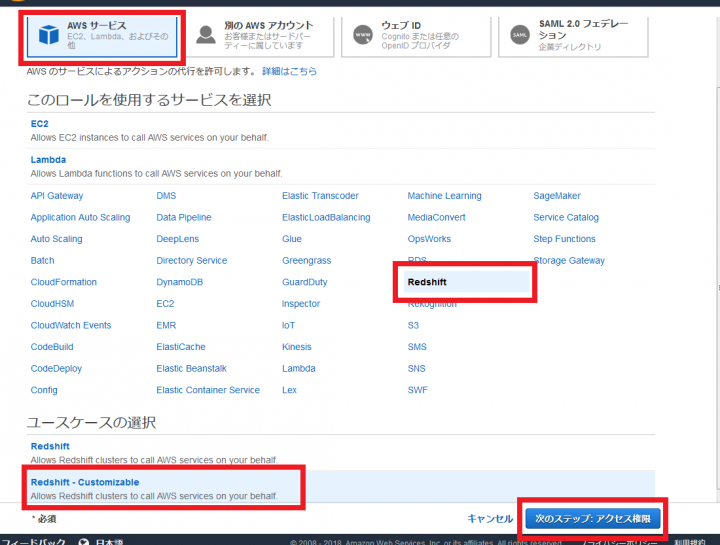
次に、画面のように「AWSサービス」「Redshift」「Redshift – Customizable」をそれぞれ選択し、「次のステップ: アクセス権限」をクリックします。
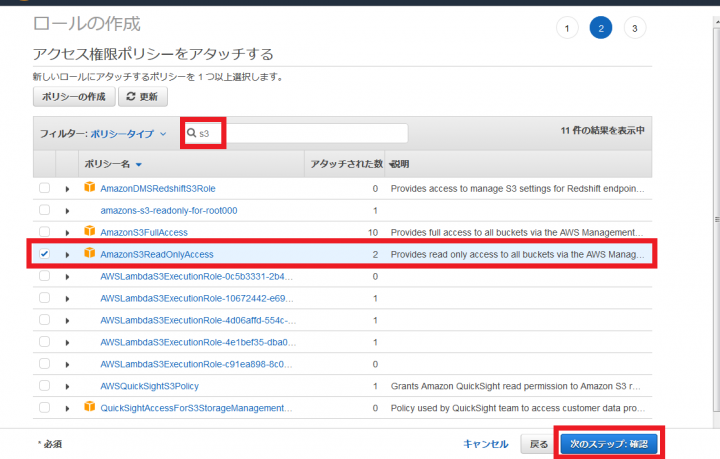
検索欄に「S3」などと入力し、「AmazonS3ReadOnlyAccess」のチェックボックスにチェックをつけ、「次のステップ: 確認」をクリックします。
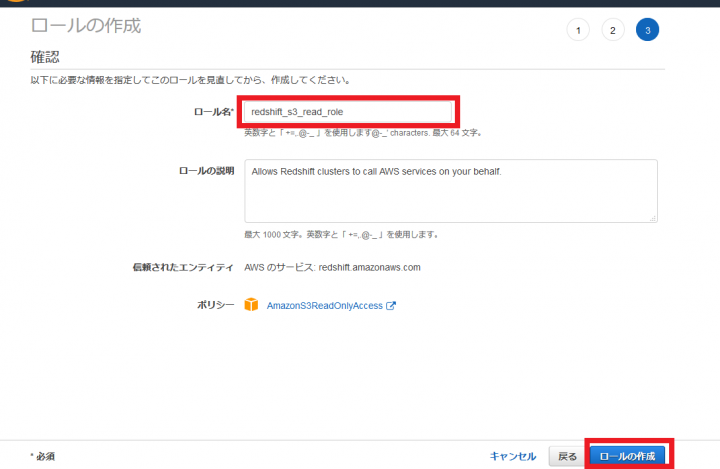
「ロール名」に「redshift_s3_read_role」など適当なロール名を入力し、「ロールの作成」をクリックします。
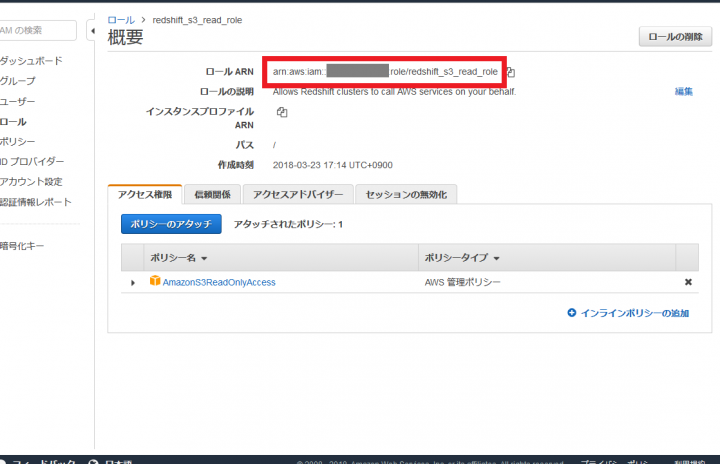
いま作成したロールを選択し、「ロール ARN」に表示されている文字列をメモします。この文字列は後で使います。
PostgreSQLクライアントのインストール
Amazon RedshiftクラスターにはPostgreSQLのクライアントpsqlを使って接続することもできます。この記事ではpsqlでRedshift クラスターに接続するため、psqlをインストールしておきます。
Ubuntuの場合は、postgresql-clientパッケージをインストールすれば、psqlが使えるようになります。
sudo apt install postgresql-client
Redshiftクラスターの作成
いよいよRedshiftクラスターを作成します。
AWS マネジメントコンソールからAmazon Redshiftを選択し、移動します。
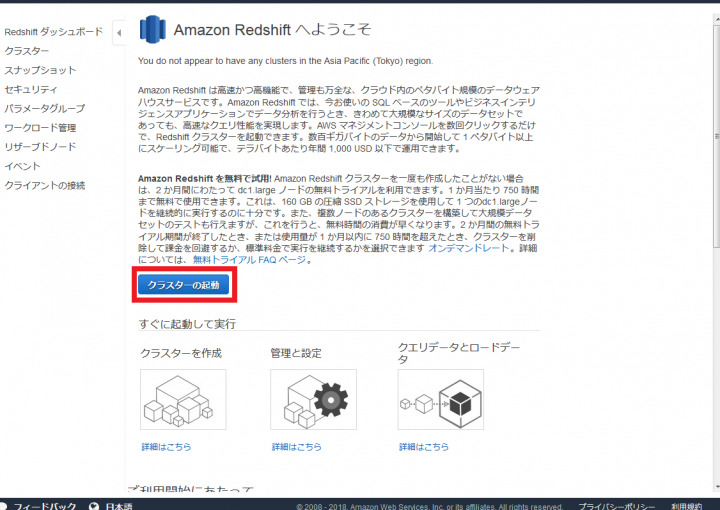
移動した先で、「クラスターの起動」をクリックします。
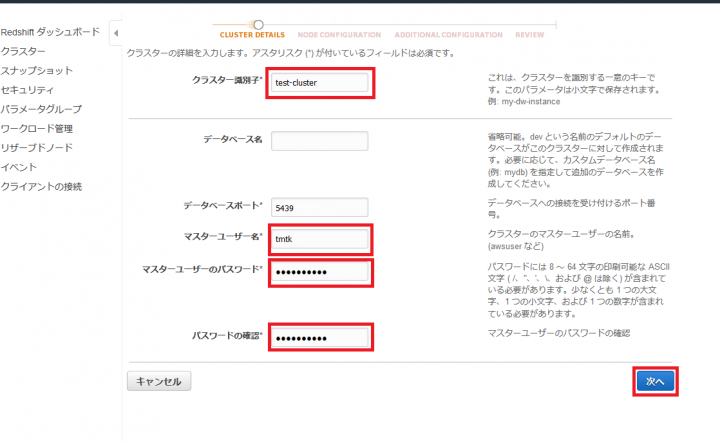
「クラスター識別子」「マスターユーザー名」「マスターユーザーのパスワード」にそれぞれ好きな文字列を入力し、「次へ」をクリックします。私の場合は、「クラスター識別子」に「test-cluster」、「マスターユーザー名」に「tmtk」と入力しました。
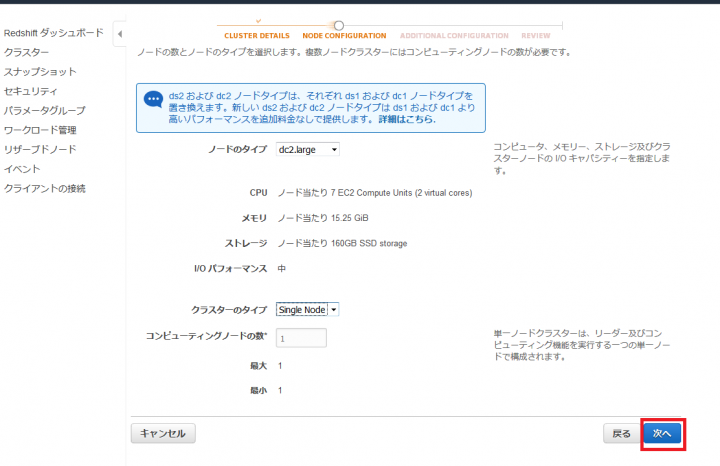
次の画面では特に何もいじる必要がないので、そのまま「次へ」をクリックします。
「VPCセキュリティグループ」はdefaultを選択し、「使用可能なロール」に先ほど作った「redshift_s3_read_role」を追加し、「次へ」をクリックします。
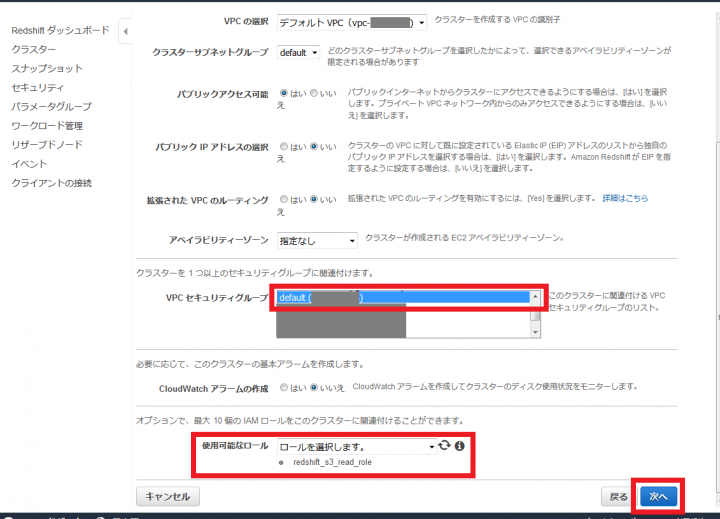
次の画面で「クラスターの起動」をクリックし、クラスターを起動します。
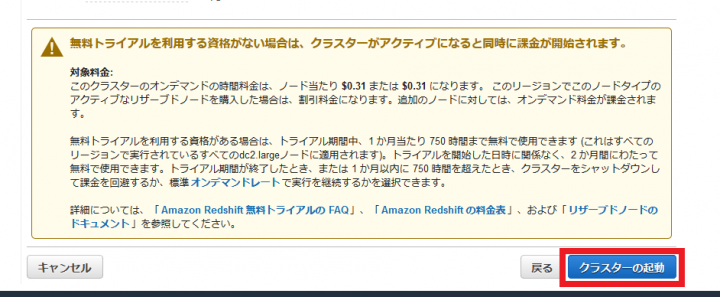
起動したクラスターを選択し、エンドポイントをメモしておきます。「:5439」以前の文字列です。この文字列は後で使います。
以上でクラスターの作成は完了です。
Redshiftクラスターへ接続
いよいよ作成したRedshiftクラスターに接続します。
まず、Linuxのターミナル上で、psqlコマンドによってRedshiftクラスターに接続します。
psql -h (メモしたエンドポイント) \
-U (Redshiftクラスタを起動するとき入力したマスターユーザー名) \
-d dev \
-p 5439
すると、パスワードの入力を求められるので、マスターユーザーのパスワードを入力します。これで、Redshiftクラスターに接続できました。
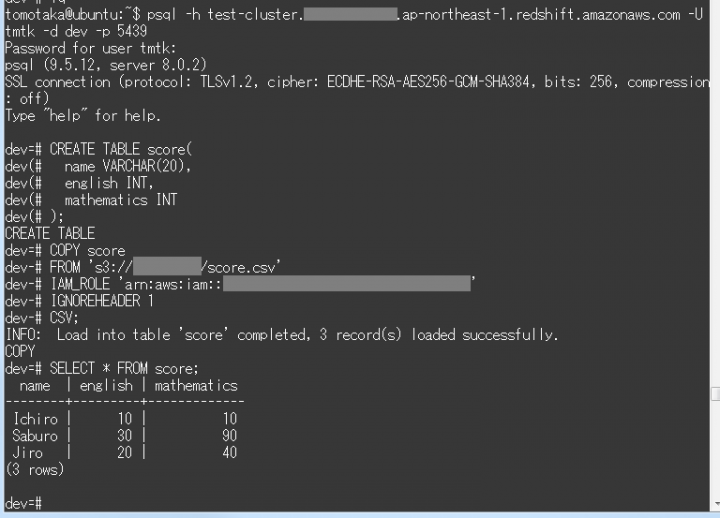
S3上のデータをRedshiftクラスターに読み込んでみましょう。まずは、SQLでテーブルを作成します。
CREATE TABLE score( name VARCHAR(20), english INT, mathematics INT );
COPYコマンドで、先ほど作成したテーブルにAmazon S3からデータを読み込みます。
COPY score FROM 's3://your-bucket/score.csv' IAM_ROLE '(作成したIAM ロールのロール ARN)' IGNOREHEADER 1 CSV;
これで、準備でアップロードしたscore.csvファイルの内容がRedshiftクラスターに読み込まれます。
最後に、読み込んだデータにSQLのクエリを投げてみましょう。
SELECT * FROM score;
すると、以下のような結果が返ってきます。データがちゃんと読み込まれたことがわかります。
name | english | mathematics --------+---------+------------- Ichiro | 10 | 10 Saburo | 30 | 90 Jiro | 20 | 40
Redshiftクラスターの削除
最後に、作成したRedshiftクラスターを削除します。
AWS マネジメントコンソールから、作成したRedshiftクラスターのページに移動し、「クラスター」「削除」とクリックします。
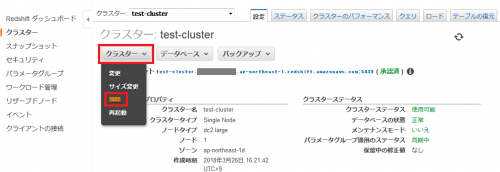
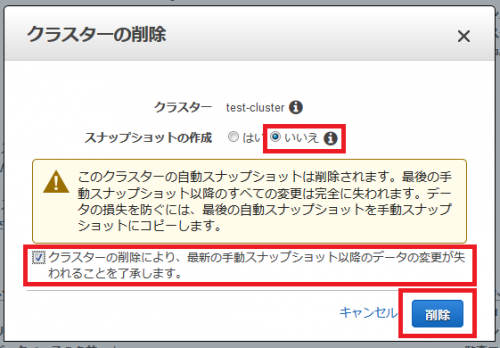
次のようなポップアップが表示されるので、「スナップショットの作成」で「いいえ」を選択し、「クラスターの削除により、最新の手動スナップショット以降のデータの変更が失われることを了承します。」をチェックし、「削除」をクリックします。すると、Redshiftクラスターが削除されます。
まとめ
この記事では、Redshiftクラスターを作成し、S3上のデータを読み込み、クエリを実行しました。
今回は小さいテストデータを使ってAmazon Redshiftの使い方を説明しましたが、Amazon Redshiftは並列コンピューティングもサポートしており、もっと膨大なデータを大量のコンピューティングリソースでさばくことができます。
Amazon Redshiftを使えば、いろいろなデータソースからデータを集約し、ビジネス上の洞察を得るためにSQLを使ったデータ分析をすることが可能になります。
AWSのビッグデータ活用・機械学習導入支援サービス
▼ エンジニアの運用負担を軽減!最適なシステム構成もご提案する運用代行サービス!

参考

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

AWS GlueとAmazon Machine Learningでの予測モデル
2017.12.17
-

純粋数学専攻がデータサイエンティストに転身してからの半年間を振り返る
2017.12.19
-

TensorFlowとKerasで画像認識する方法
2017.12.6
-

画像分類の機械学習モデルを作成する(1)ゼロからCNN
2018.4.17


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16