【Google Cloud Next Tokyo ’24】 Gemini で実現するマルチモーダル生成 AI – ユースケースとアーキテクチャの理解を深める(D2-AIML-06)
2024.8.14

はじめに
こんにちは、ヒョンスクです!
2024年8月1日から2日までにパシフィコ横浜ノースで開催されたGoogle Cloud Next Tokyo ’24に行ってまいりました。
新製品の発表、技術デモ、顧客事例発表など、さまざまなセッションが行われまして参加するのが忙しかったです。そして、Googleのクラウド技術を活用したソリューションを直接体験し、学ぶ機会を得ることができて楽しめました。
最も記憶に残る「Gemini で実現するマルチモーダル生成 AI – ユースケースとアーキテクチャの理解を深める」というセッションについて関連する情報とともにレポートします!
セッション概要
セッションタイトル
Gemini で実現するマルチモーダル生成 AI – ユースケースとアーキテクチャの理解を深める
セッション レベル:中級者
登壇者
Google Cloud 遠山 雄二
カスタマー エンジニアリング
カスタマー エンジニア
概要
本セッションでは、Gemini の最大の特徴である「マルチモーダル」と、「ロングコンテキスト ウィンドウ」にフォーカスをあて、その可能性をご紹介します。マルチモーダル / ロングコンテキスト ウィンドウ の概念を理解をした上で、それがどのようなビジネス ユースケースにつながるのか。またそのユースケースをどのように実現するのか、マルチモーダル生成 AI を利用した代表的なアーキテクチャ パターンである、マルチモーダル RAG を例に、実践のポイントをお伝えします。ユースケースを検討中のビジネスサイドの皆様から、具体的な実装イメージを知りたいエンジニアの皆様まで、即実践できるアイデアを得られるセッションです。
セッションレポート
今回のセッションでは、Geminiを活用して非構造化データ(画像や動画)をどのように生成し、変換し、そして抽出するかに関する具体的な活用事例が紹介され、それに対応するアーキテクチャを理解するポイントとなりました。データエンジニアとして、データ処理の過程が非常に有益であり、ビジネスの観点からも深く考える機会となりました。それでは、セッションについて簡単にご紹介いたします。
1.生成AIのトレンド – 高速なレスポンスの実現

Google Cloud の基盤モデルである Gemini 1.5 Flash が紹介されました。レイテンシー(遅延時間)とコストが重要な作業において優れた性能を発揮するように設計されたそうです。ユースケース例として、カスタマーサポート、マルチモーダルチャットアプリケーション(チュータリングやビデオQ&A)、精密な画像およびビデオキャプション生成、長いドキュメントや表からのデータ抽出、オンデマンドコンテンツ生成(ゲーム、ストーリーなど)、そして教育製品での活用が可能です。
- Gemini 1.5 Pro : ロングコンテキスト
- Gemini 1.5 Flash : 高速なレスポンスと高いコスト効率
2.生成 AI を利用したビジネス ユースケース

生成AIのユースケースにより創出される価値の約75%は、「顧客対応」「マーケテング&セールス」「ソフトウェアエンジニアリング」「研究開発(R&D)」の4つの領域に集中
出典 : 生成 AI がもたらす潜在的な経済効果、McKinsey & Company、2023年6月
弊社で新たにビジネスを創出できる可能性がある取り組みについて考えてみました。既に存在しているかもしれませんが、例えば、新入社員向けの教育プログラム、社内規定のチャットボットシステム、そして会社のポータルサイトにおけるチャットボットシステム(24時間対応の問い合わせチャットボット)などが挙げられると思います。
3.マルチモーダル生成AIのユースケース

マルチモーダル生成AIのさまざまなユースケースについて取り上げました。LLMが画像/動画データを活用してどのように情報を生成、加工、抽出できるかを説明しました。例えば、画像生成ではエンターテインメントやビジネス用途のクリエイティブコンテンツを作成できて、画像の言語化プロセスを通じて検索サービスの改善も可能です。また、動画データにおいては、メタデータを追加したりビジネス状況を分析するなど、多岐にわたる活用方法が提示されました。
このセッションを通じて、AIが多様な形式のデータをどれほど柔軟に処理し、ビジネスにどのように価値を付加できるかについて深い理解を得ることができました。データエンジニアとして、これらの技術が実際にどのように実装され、ビジネスに応用できるかを考える時間となりました。
(1) ユースケース例 – 1 : 非構造データを構造データへの変換

プロンプトを入力し、ファイルを添付して希望する形式でデータを出力してくださいと依頼すると、その形式に応じたデータが正確に出力されることを確認しました。非構造化データであっても、Geminiを経由すると構造化データとして出力される点に感心しました。
(2) ユースケース例 – 2 : 面像/動画の加工、ビジネスへの利用

面像や動画のデータまで読み込み、メタデータ、レコメンデーション理由、ビジネス状況の可視化までデータ化することができます。
(3) ユースケース例 – 3 : マルチモーダルデータに対するナレッジ検索

ユーザーからテキスト形式のクエリが入力され、そのクエリに対してマルチモーダルデータ(テキスト+画像)を基にしたチャットエージェントが適切な回答を提供するプロセスで、企業の財務報告書(Form 10-K)などのテキストデータだけでなく、関連するグラフや表といったビジュアルデータを組み合わせて、より充実した情報をユーザーに提供することになりました。かなり素晴らしい機能で感心しました。
より詳しい情報は、弊社ブログでフクナガさんが執筆したマルチモーダルに関する詳細な説明をご参照ください。
参考: What is Multimodal Search: “LLMs with vision” change businesses
4.組織での生成AI利用における課題と対策
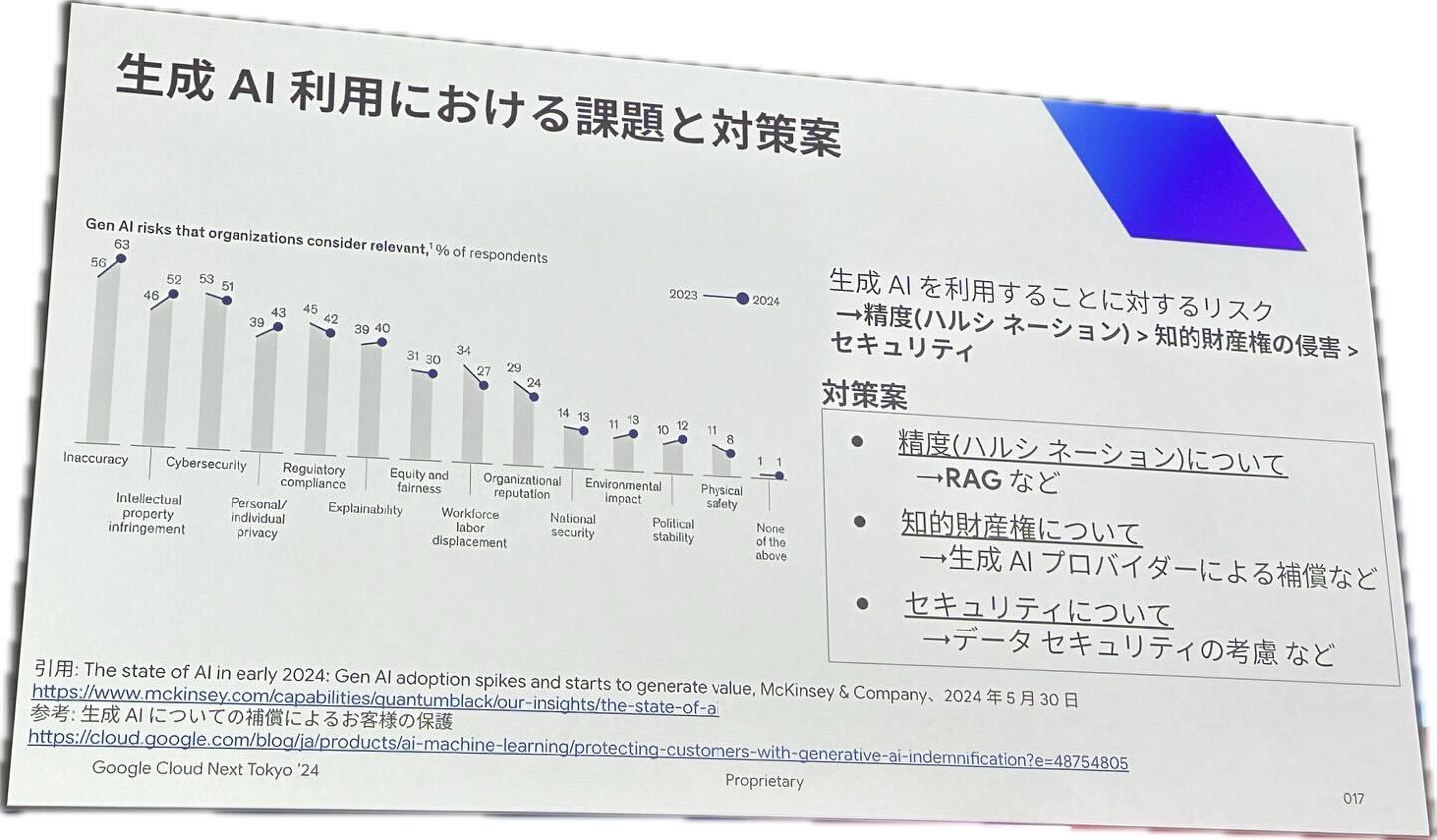
生成AIの導入がもたらすさまざまなリスクと、それらを管理するための解決策について深く理解することができました。特に、精度(ハルシネーション)、セキュリティ、知的財産権侵害など、実際のリスクに対する具体的な対応策を学ぶことができました。
出典: The state of AI in early 2024
参考: 生成AIについての補償によりお顧客保護
5.マルチモーダルRAGのアーキテクチャについて
(1) マルチモーダル RAG – 実現方式

検索拡張生成(RAG)とは
検索拡張生成(RAG)は、従来の情報検索システム(データベースなど)の強みと、生成大規模言語モデル(LLM)の機能を組み合わせた AI フレームワークです。この追加の知識と AI 独自の言語スキルを組み合わせることで、AI は、より正確で最新の、特定のニーズに関連するテキストを作成できます。
出典:検索拡張生成(RAG)
RAGを実装するための2つのアプローチについて紹介されました。
1) マネージドサービスを利用して実装
Vertex AI Agent Builder (Vertex AI Search) を利用する方法です。このアプローチでは、生成AIを活用した検索および対話型アプリケーションを構築するための機能が提供され、UIが含まれているため、迅速な開発が可能です。まずこの方法を使用して要件を満たせるかどうかを確認するのが推奨されます。このアプローチの利点は、設定や管理が簡単で、複雑なコーディングを必要とせずに迅速に開始できることです。
2) スクラッチで実装
PythonとGeminiを活用して、直接コードを記述し、さまざまな機能を組み合わせてカスタマイズする方法です。このアプローチは、データの入力および出力形式に対する柔軟性が高く、特定の要件に合わせたカスタムソリューションを開発するのに適しています。
(2) マルチモーダルRAG – アーキテクチャ
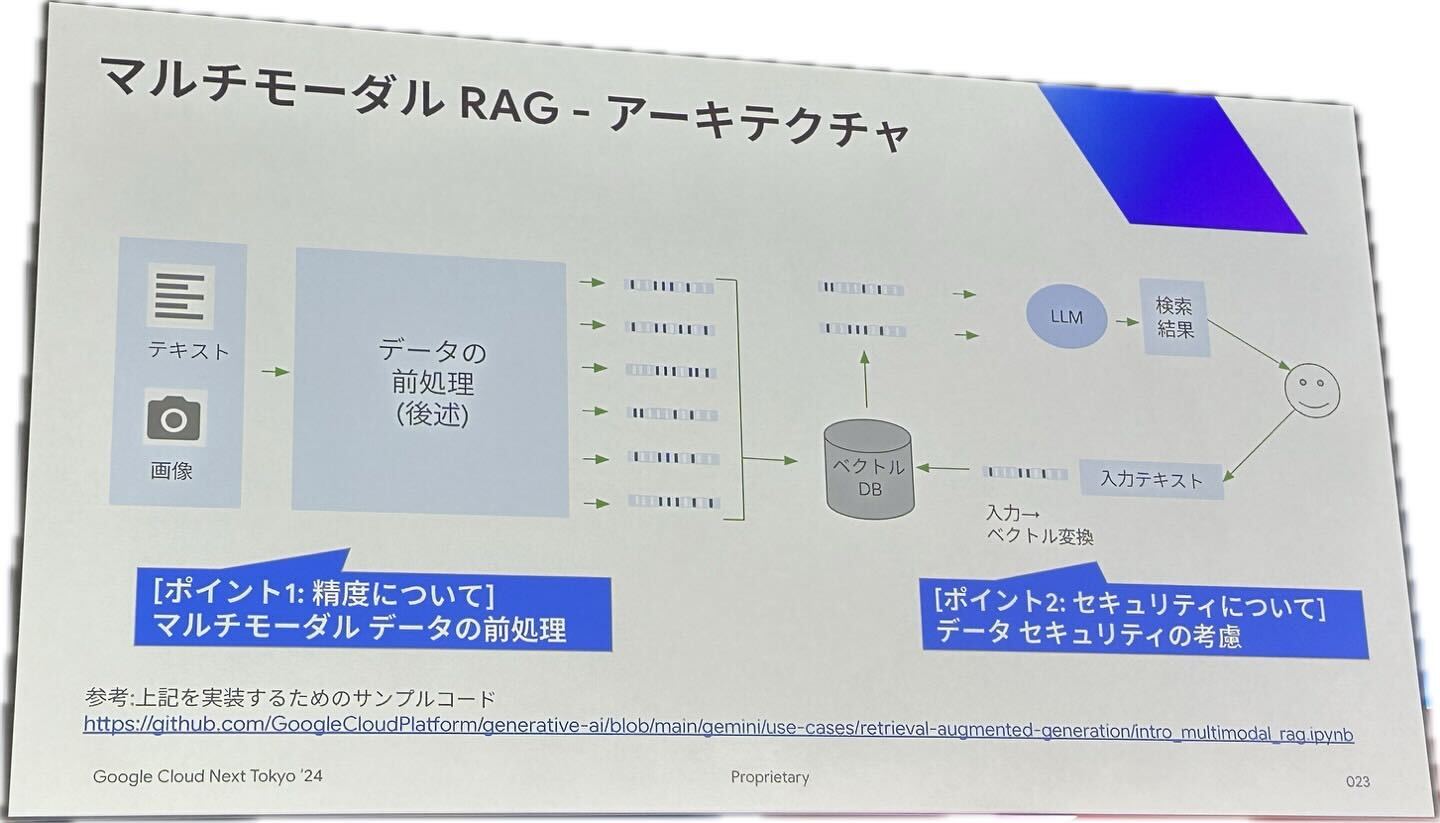
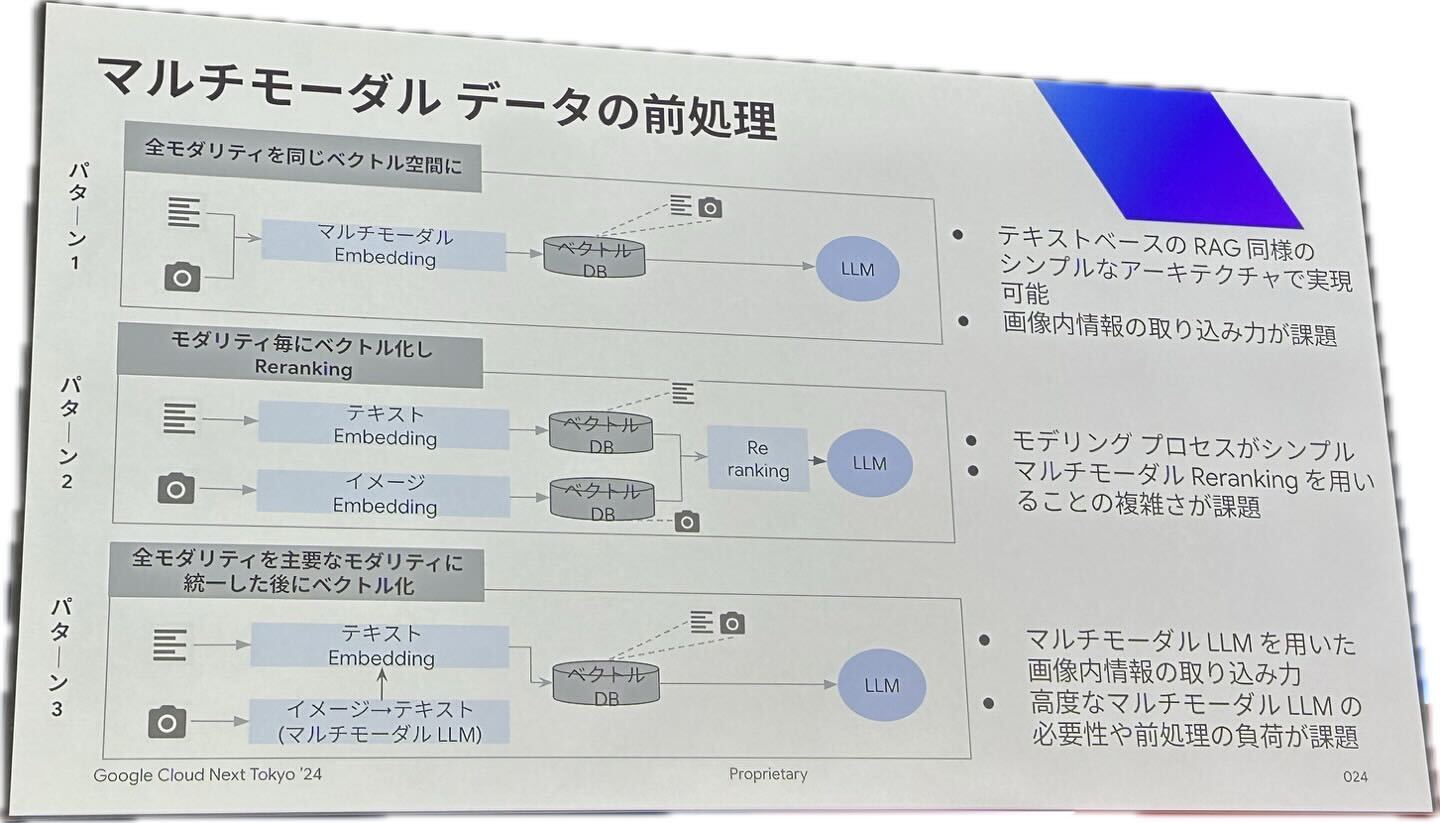
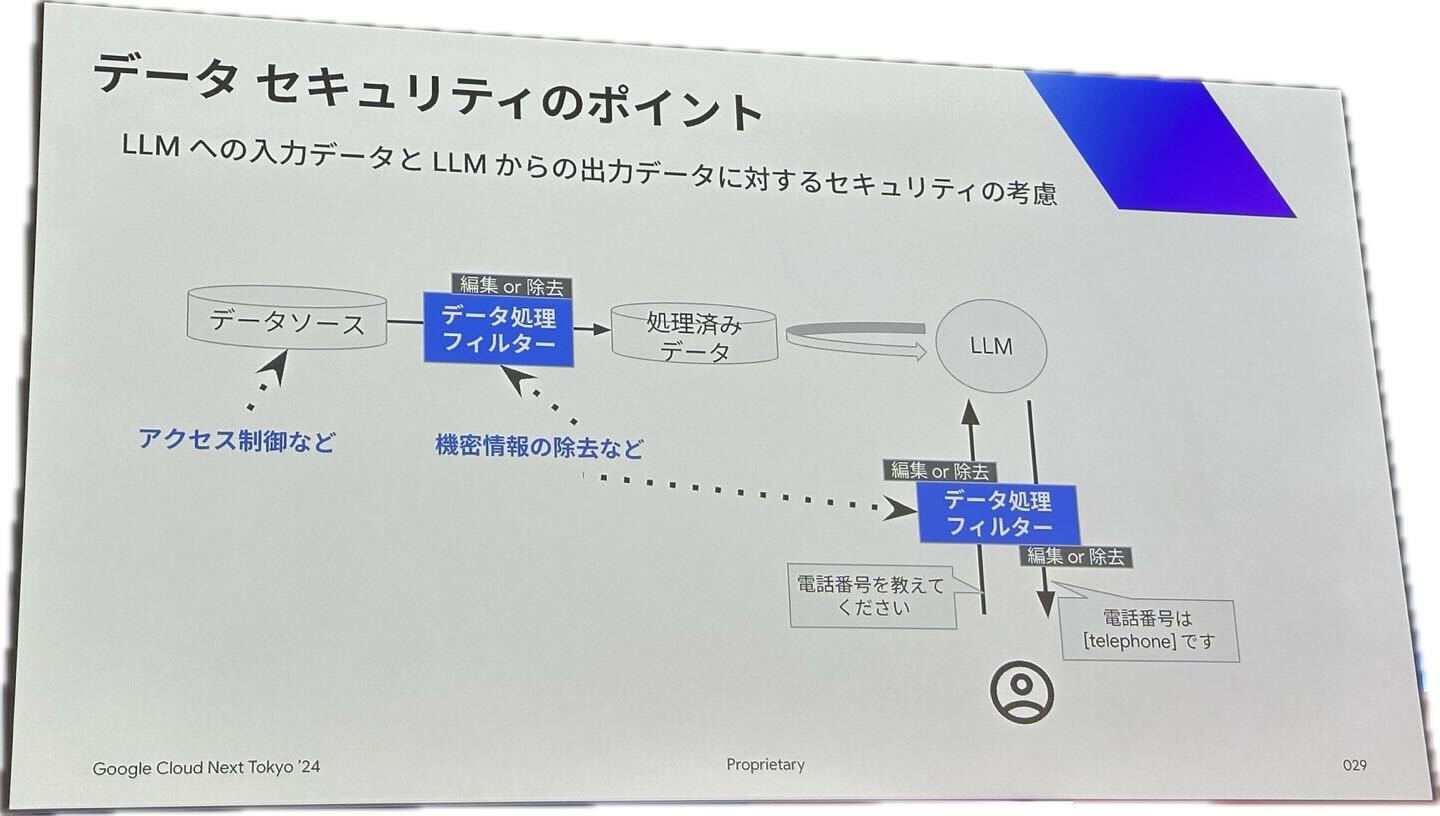

日本のビールが大好き、韓国出身です。
現、データエンジニアとして活躍してます。
クラウドエンジニアになるために頑張っているところです!
Google Cloud11冠


Recommends
こちらもおすすめ





Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16