GuardDutyを軸としたセキュリティ対応の自動化について考えてみた ~ リスクに応じた対応方針の策定 ~

はじめに
こんにちは、元営業マンryoです。
今回はセキュリティ対策を一部自動化する話をしたいと思います。
セキュリティ対応のように迅速性が求められるタスクを、リスクを最小限に抑えながら効率化することはできないか、と思ったのが本記事を書こうと思った背景です。
セキュリティ対応は「誰がやるか」の設計が9割
セキュリティインシデントが発生したとき、最初の数分間の対応が被害の大小を左右します。
しかし、「速く対応する」ことと「正しく対応する」ことは簡単には両立しません。
全自動にすれば速い。でも誤検知で本番を止めるリスクがある。
全手動にすれば正確。でも夜間に誰も対応できなければ被害が広がる。
結局のところ、セキュリティ対応で最も重要な設計判断は「何を機械に任せ、何を人間が判断するか」の境界線をどこに引くかです。
本記事では、Amazon GuardDuty の検知をトリガーにしたインシデント自動対応基盤を、人間と自動化の役割分担をどう設計したかを紹介します。
自動化の範囲
| 対象作業 | 自動化/人間が対応 |
|---|---|
| GuardDuty 検知 → 重大度判定 → 対応アクション実行(EC2隔離・ネットワークACL(NACL)遮断・WAF IPブロック・IAMキー無効化・セキュリティグループ(SG)是正)→ 通知・記録 | 自動化 |
| High レベルにおける承認フロー(Slack 承認ボタン + 15分タイムアウトによるフォールバック) | 自動化 |
| 復旧作業(隔離解除・キー再有効化など) | 人間が対応 |
| フォレンジック調査・根本原因分析 | 人間が対応 |
| 対応方針の見直し・閾値のチューニング | 人間が対応 |
システム構成概要
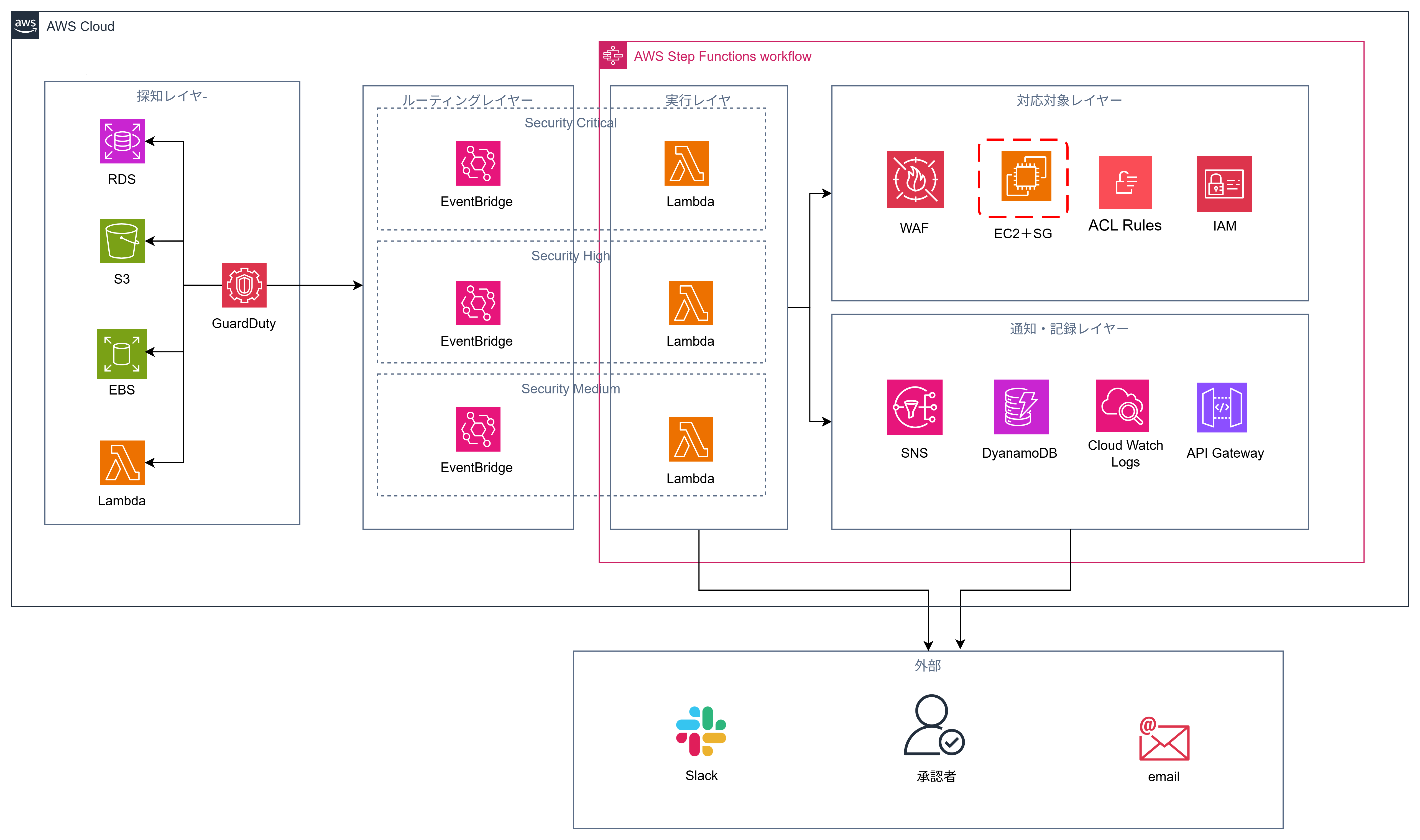
| レイヤー | 役割 | 主要サービス |
|---|---|---|
| 検知 | 脅威の検出 | GuardDuty(S3/EBS/RDS/Lambda保護) |
| ルーティング | 重大度別の振り分け | EventBridge(3ルール) |
| オーケストレーション | ワークフロー制御 | Step Functions(3ワークフロー) |
| 実行 | 具体的な対応アクション | Lambda(8関数) |
| 通知・記録 | 通知と証跡管理 | Slack / SNS / DynamoDB / CloudWatch |
なぜ「全自動」でも「全手動」でもダメなのか
全手動の限界
従来のセキュリティ対応は、検知→通知→確認→判断→対応のサイクルを人間が担っていました。
- 初動の遅れ:確認→判断に時間がかかり、攻撃者に猶予を与える
- 夜間・休日の空白:オペレーター不在時は翌営業日まで放置される
- 対応の属人化:担当者ごとに判断基準が異なり品質にばらつきが出る
人間だけに依存する体制では「24時間365日の対応」が構造的に不可能です。
全自動の落とし穴
では全自動化すればよいかというと、別のリスクがあります。
- 誤検知による業務影響:本番稼働中の EC2 を誤って隔離してしまう
- 過剰対応:問題ないケースでも機械的に IAM アクセスキーを無効化してしまう
- 文脈の欠落:「このIPは社内VPN」「このAPIコールはリリース作業」といった人間にしかわからない文脈を無視する
機械は速いが「判断の文脈」を持たない。人間は文脈を理解できるが遅い。どちらか一方では不十分です。
必要なのは「自動化するか/しないか」の二者択一ではなく、「何を機械に任せ、何を人間が担うか」を明確に設計することです。
役割分担の設計:重大度で境界線を引く
本システムでは、GuardDuty の severity スコア(1.0〜10.0)を基準に役割分担を設計しました。
※本記事独自に、3つの重大度レベルに分けました。
参考: GuardDuty の重大度レベル – AWS公式ドキュメント
| 重大度 | スコア | 機械の役割 | 人間の役割 |
|---|---|---|---|
| Critical | 8.0 以上 | 即時自動対応(隔離・遮断・ブロック) | 事後確認・復旧判断 |
| High | 5.0 〜 7.9 | 通知 + 15分後の自動フォールバック | 15分以内の承認/拒否判断 |
| Medium | 2.0 〜 4.9 | 記録 + 是正提案の提示 | 提案に基づく対応判断・実行 |
根底にある考え方は、「リスクの大小で主導権を渡す相手を変える」ということです。
Critical(8+): 機械が主導、人間は事後確認
Severity 8 以上は「攻撃の進行が確認された」レベルです。
なぜ人間を待たないのか:
人間の判断を待つ損失の方が、万が一の誤検知による業務影響より圧倒的に大きい。
15分の間に攻撃者はラテラルムーブメントを進め、被害範囲が一気に広がります。
機械がやること: EC2隔離、NACL遮断、WAF IPブロック、IAMキー無効化(検知から数十秒以内)
人間がやること: 対応内容の確認、誤検知時の復旧判断、根本原因の調査
「止める」は機械、「判断する・直す」は人間。
High(5-7.9): 人間が主導、機械がバックアップ
ここが本システムで最も工夫したポイントです。
High レベルは「攻撃の兆候はあるが、文脈次第で正常な活動の可能性もある」状態です。全自動では業務影響が出るリスクがあり、全手動では夜間に放置される。
採用した方式 ── 15分のタイムリミット付き承認フロー:
- 検知と同時に Slack へ承認ボタン付き通知を送信する
- オペレーターが15分以内に「承認」または「拒否」を判断する
- 15分間応答がなければ機械が自動でフォールバック対応を実行する
機械がやること: 通知送信、15分のタイマー管理、タイムアウト時の自動対応、結果の記録
人間がやること: 状況の判断(正常な活動か攻撃か)、承認/拒否の意思決定
この設計により実現できること:
- 営業時間中 → 人間が文脈を踏まえて判断する(機械は待機)
- 夜間・休日 → 人間が不在でも15分後に機械が対応する(放置されない)
「基本は人間が判断するが、不在時は機械がカバーする」という設計です。
なお、15分という値は「Slack通知に気づいて状況を確認し判断するまでの現実的な時間」として選定しました。
5分では確認が困難、30分では侵害進行のリスクが高まります。
Medium(2-4.9): 人間が主導、機械は情報提供
Medium は侵害の確証がないレベルです。自動で止めると正常な業務を止めるリスクの方が高い。
機械がやること: 検知事実の記録、是正提案の Slack 通知
人間がやること: 是正の要否判断、必要に応じた対応実施
役割分担を成立させるための設計判断
「人間にしかできないこと」を明確にする
役割分担の境界線を引くにあたり、「そもそも人間にしかできないことは何か」を整理しました。
- 文脈の理解:「このIPは社内VPNだ」「このAPIコールはリリース作業だ」
- ビジネス判断:「このサービスを止めると売上に影響する」
- 例外処理:想定外のパターンへの対応
- 改善:検知ルールや閾値のチューニング
逆に言えば、これら以外は機械に任せられます。
この整理が境界線の設計根拠です。
「止め遅れ」と「止めすぎ」のリスク比較
Critical を承認制にすべきかとも考えましたが、最終的にリスクの比較で判断しました。
- severity 8+ → 止め遅れの被害 > 誤検知の業務影響 → 機械が即時対応
- severity 5-7.9 → 文脈による判断が有効 → 人間に委ねるが不在時は機械がカバー
- severity 2-4.9 → 侵害の確証なし → 人間に任せる
まとめ:役割分担の設計指針
本記事で得た知見を整理します。
- 「速度が必要な作業」は機械に任せる
人間の判断を待つコスト > 誤動作のコスト なら自動化する - 「文脈が必要な判断」は人間に任せる
ただし、人間が不在の場合のフォールバックは必ず機械で用意する - 「境界線の根拠」を定量的に示す
severity スコアのように数値基準で分けることで、チーム内の合意形成と説明責任を果たせる
「重大度で境界線を引き、人間と機械の得意分野で分担する」という考え方は、セキュリティに限らずあらゆる運用自動化に応用できるはずです。
今回ご紹介できなかった対象システムをTerraformで構築した話やオーケストレーションレイヤーの実装等については別記事でまとめたいと思います。
なお、EventBridge × 障害自動検知・対応の別のアプローチや、Terraform × AWS 運用自動化については以下も参考にしてください。

営業・インフラエンジニアを経てクラウドへ転向。VMware関連の知識も強みのひとつです。セキュリティ・IaCにも高い関心を持っています。休日はサウナかご飯食べてます。


Recommends
こちらもおすすめ






Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16