AWS DevOps Agent を用いて障害対応を更に自動化しよう!

はじめに
今回は AWS re:Invent 2025 で発表された新サービス AWS DevOps Agent を用いたユースケースについてご紹介します。
早いもので AWS re:Invent 2025 が開催されてから 3 ヶ月が経過しました。
その間に DevOps Agent がどのようなサービスなのか?どのようなことを実現できるのか?などといった DevOps の紹介記事については多く世に出たかと思います。
そこで本記事では、基本的なサービス仕様の紹介にとどまらず、実際のトラブル対応フローへの組み込み方という具体的なユースケースに焦点を当ててご紹介します。
DevOps Agent とは?
まずはユースケースをご理解いただくにあたって DevOps Agent がどのようなサービスなのか基本をおさらいしましょう。
AWS DevOps エージェントは、インシデントを解決、予防し、信頼性とパフォーマンスを継続的に向上させるフロンティアエージェントです。
出典:フロンティアエージェント – AWS DevOps エージェント – AWSフロンティアエージェントは、目標を達成するために独立して動作し、同時実行タスクに対応するために大規模にスケールして、介入なしで数時間または数日間にわたって持続的に動作する自律システムです。
出典:大規模にスケーラブルな自律型 AI エージェント – フロンティアエージェント – AWS
DevOps Agent は名前の通り、運用上のトラブルを調査し、解決策を提示してくれる AI Agent です。
具体的には、トラブルが起きた際に発生時刻・発生個所・ログメッセージといった情報を与えることで、自動的に根本原因の調査や解決策の提案をしてくれます。
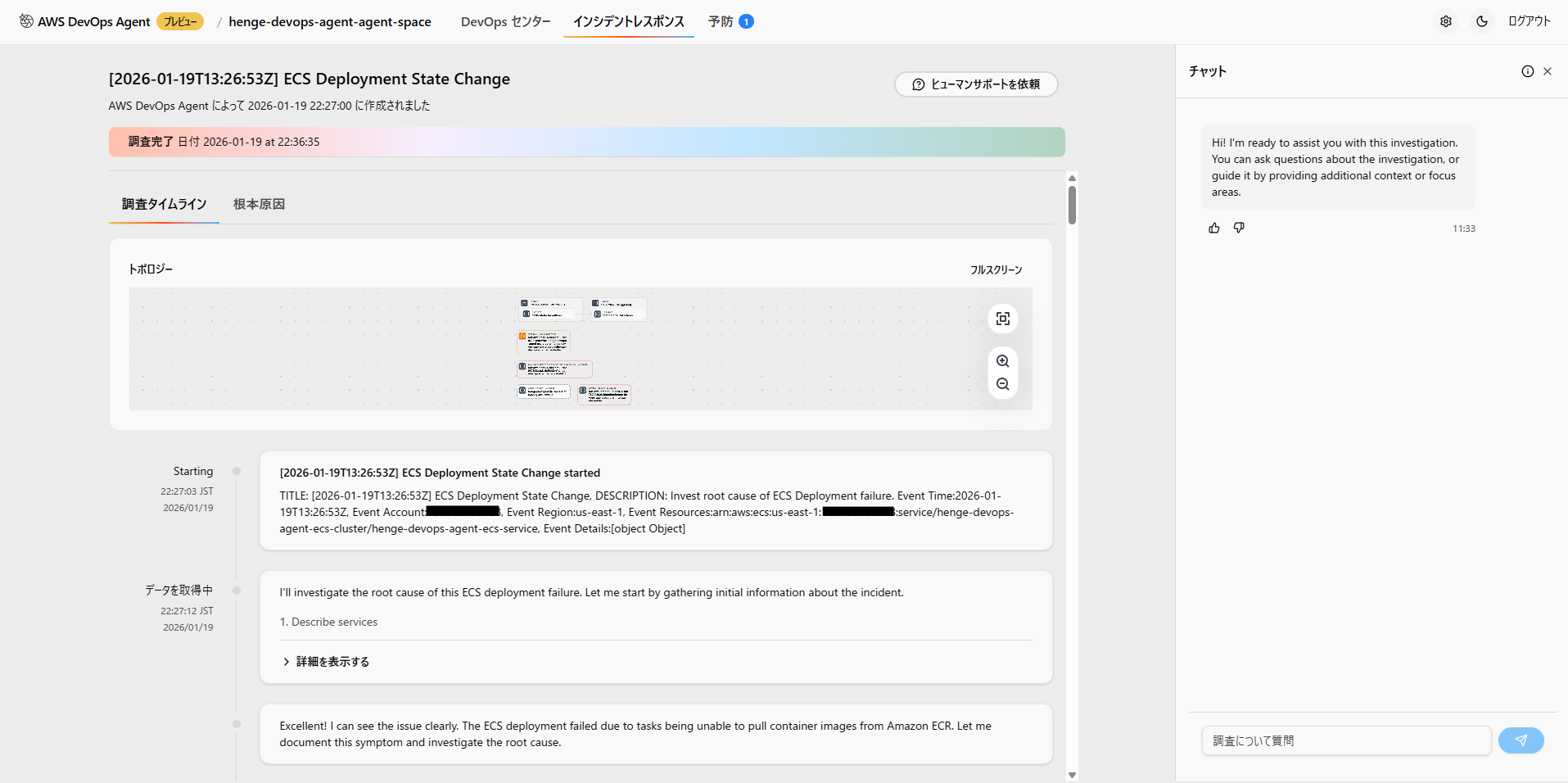
AWS が提供している AI が自動的にトラブルシューティングをしてくれる機能としては、CloudWatch の調査機能というものが 2025 年 6 月頃にリリースされており、自動的に調査をしてくれるという点では DevOps Agent は目新しいサービスではありません。
しかし、DevOps Agent の特長は様々なツールとの連携であり、そこが他の AI トラブルシューティングツールを大きく異なると考えています。
DevOps Agent は Slack や、GitHub を始めとしたサードパーティー製の SaaS とネイティブに連携して、障害調査の際にそれらのツールからも情報を収集することができます。
昨今では AWS 環境内だけでインフラ環境が完結しないケースも多く、アプリ情報は GitHub に集約することが多いため、これらの情報へアクセスできることでトラブルシューティングの成功率がグッと上がりそうですね。
詳細は後続にて説明しますが、今回はこれらの連携機能を活用してみようと思います!
実現したいこと
今回は DevOps Agent を用いてトラブル対応における自動化の範囲を広げるということを試みます。
よくあるトラブル対応の流れとしては、トラブル発生 → 検知 → 調査 → 対策ですが、CloudWatch や SNS などを利用して検知のみを自動化するという運用が一般的です。
この運用ではトラブルを発見・通知するまではシステムにより自動化され、その後の調査や対策は運用者が実施する流れとなります。
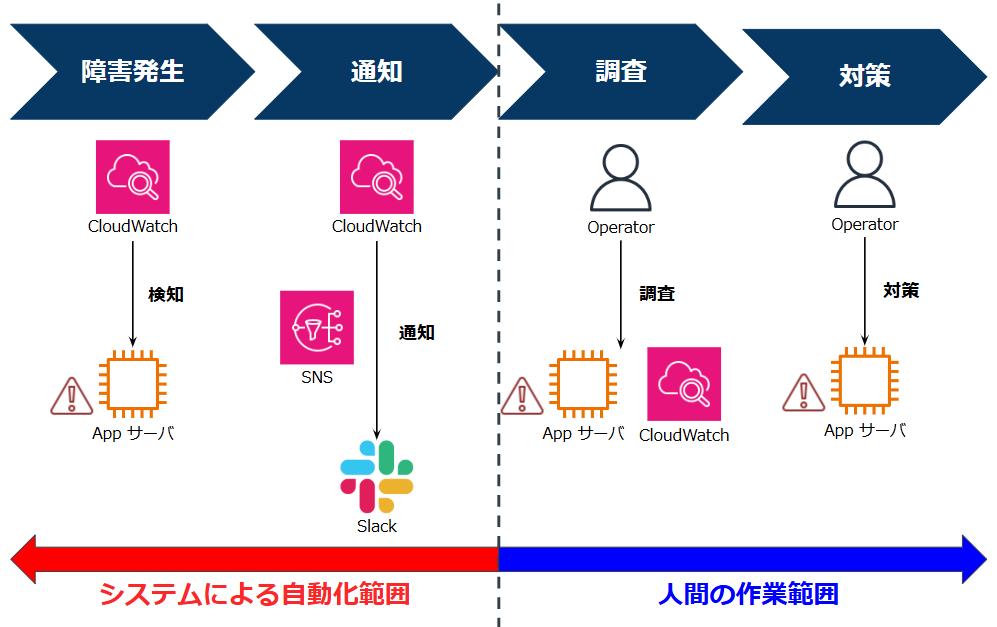
しかし、トラブル対応では 3 つ目の調査がネックになるケースがよく見られます。
ログの量や種類が多くて見切れない、アプリ・インフラ両方をトラブルシューティングする知見がない、などの問題が発生して結局原因が特定できないなんてこともありがちです。
そこで登場するのが DevOps Agent です。
手間がかかりがちで広い範囲の知識を要求する調査を DevOps Agent に任せることで、検知から調査までの一連を自動化することができます。
DevOps Agent は原因特定から対策の提案まで行ってくれるため、運用者がやるべきことは調査内容を確認して対策を実施するだけであり、トラブル対応の手間を非常に下げることができます。
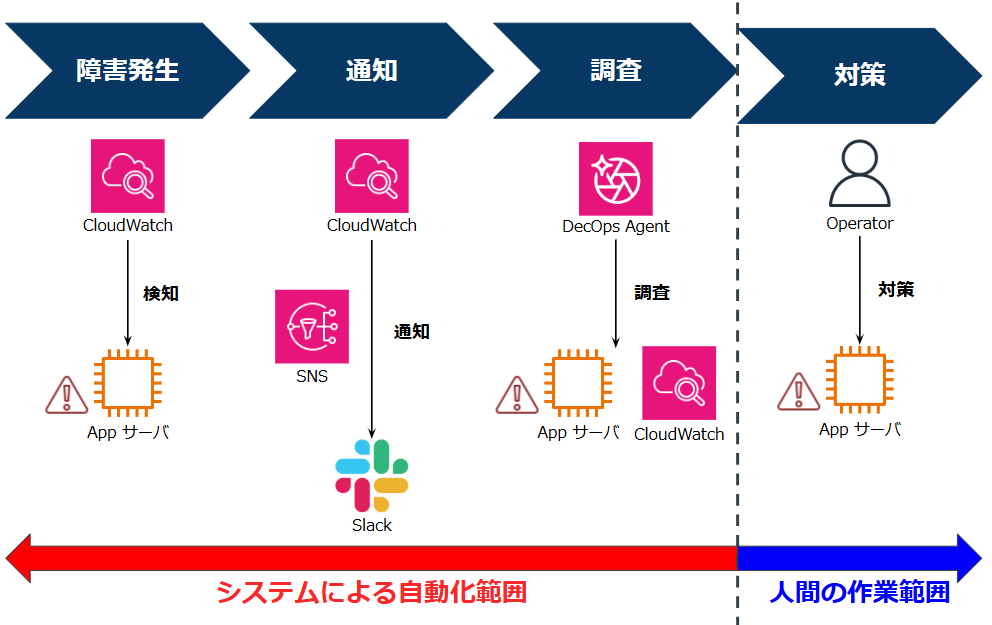
検証構成
上記の実現したいことを本当に実現できるのか検証してみようと思います。
検証で使用した構成が以下の図のようなものとなります。
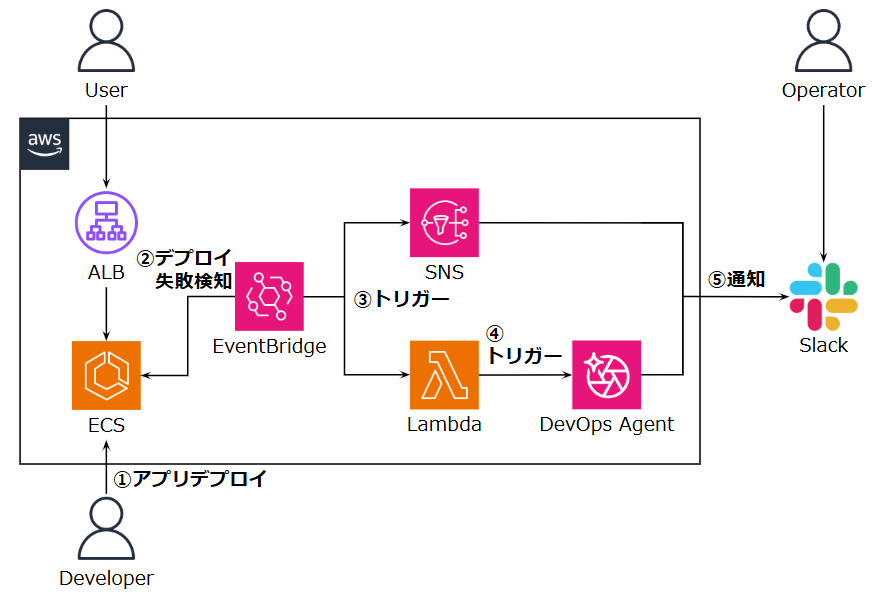
アプリ部分は ALB + ECS のシンプルな構成です。
アプリデプロイの失敗を監視するために EventBridge などのサービスで Slack へ通知するようにしています。
今回起こすトラブルの内容としては ECS へのデプロイを想定しています。
デプロイが失敗すると以下の流れでトラブルシューティングが開始されます。
- 開発者が ECS へデプロイ実行
- デプロイ失敗を EventBridge が検知
- EventBridge がデプロイのイベント情報を SNS と Lambda へ送信
- Lambda がデプロイのイベント情報を DevOps Agent に送信
- SNS や DevOps Agent がそれぞれ検知状況や調査内容を Slack へ通知
ECS デプロイ失敗に限定されますが、この構成では検知から調査までを自動化することができそうです!
DevOps Agent で利用した連携機能
この自動化を実現するにあたって必要な DevOps Agent の連携機能について簡単に触れます。
今回は Webhook によるエージェントの呼び出し と Slack への通知機能 の 2 つを利用しました。
DevOps Agent による調査を実行させる方法の 1 つとして Webhook が備わっています。
障害関連の情報を Webhook URL に送信することで、DevOps Agent が障害調査を開始します。
この機能によって Lambda 関数などをトリガーに自動的に調査を開始させることが可能です。
また、DevOps Agent では調査進捗や結果を Slack へ通知させることもできます。
調査開始時に指定のチャンネルへ調査を開始した旨を投稿し、以後そのスレッドに調査進捗や結果を追記する形式です。
AWS 環境や Agent のコンソール画面など別途ツールへアクセスする必要がないのは便利ですね。
検証結果
では、実際に検証してみます。
この検証では意図的にトラブルを起こす必要があるわけですが、今回は ECS から ECR へのネットワークを遮断することで、ECR の保管してあるイメージをプルすることができずにデプロイが失敗するようにしました。
ちなみにネットワークの遮断方法は NAT Instance の停止です。
そのため、DevOps Agent の調査結果では ECS と ECR 間のネットワークの問題がトラブルの根本原因であり、NAT Instance を起動することで解決できると報告されることが望ましい結果となります。
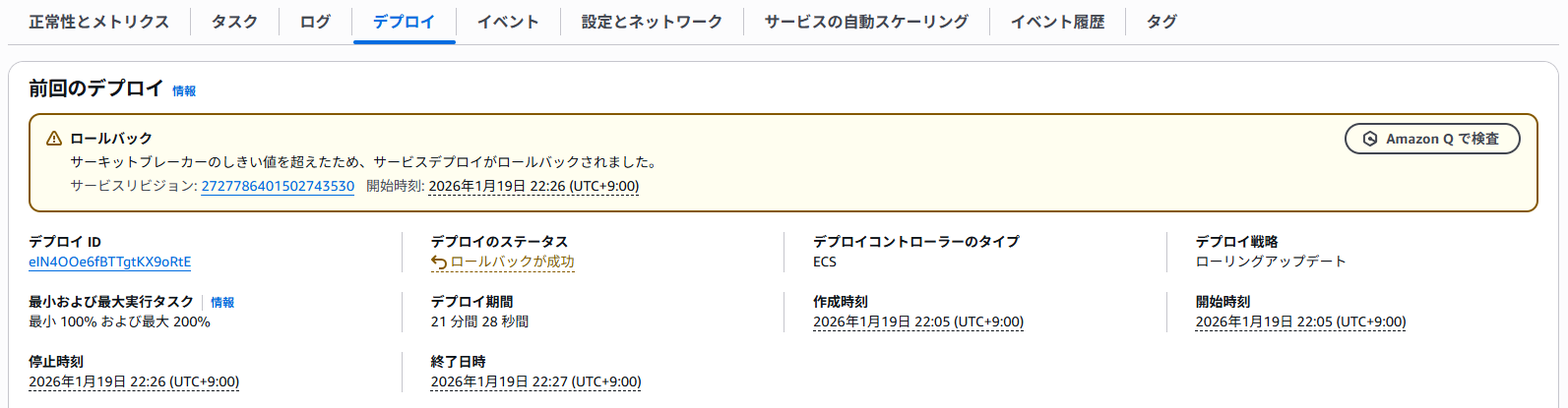
早速検証を開始し、予定通りデプロイが失敗しロールバックされました。
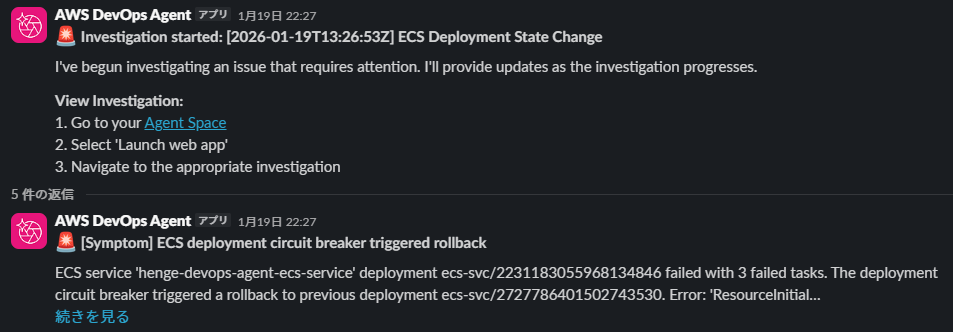
と、同時に Slack にも SNS と DevOps Agent からの通知が届きました。
今回は同じチャンネルに通知してしまっていますが、二重通知になっているので通知したい相手に応じて別チャンネルの方が良さそうですね。
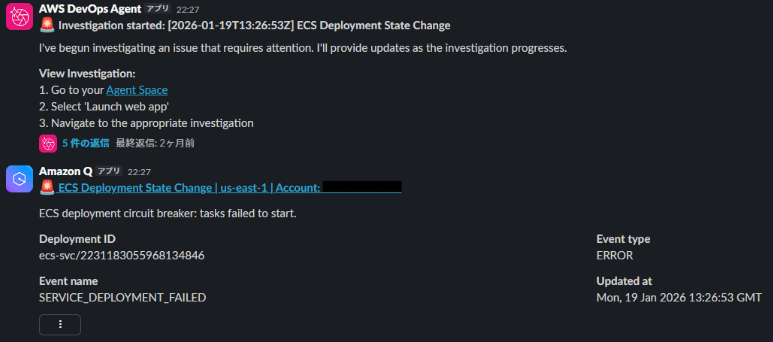
その後 10 分ほど待機しているとスレッドに調査結果が追記されました。
すべて英語なので若干分かりづらいですが、Root Causes の投稿で望み通り NAT Instance が停止されたことが原因だと記載されていました。
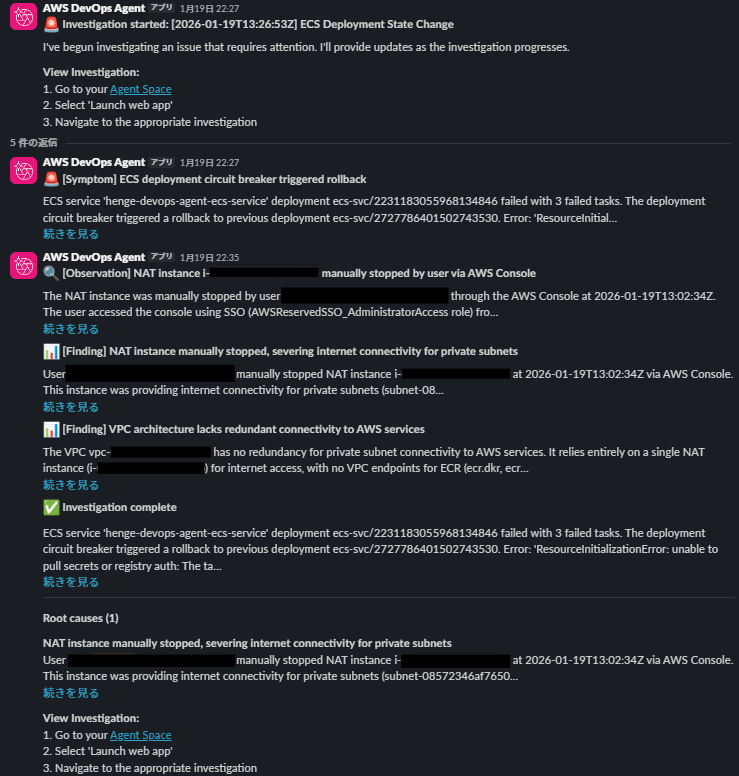
Root causes (1)
NAT instance manually stopped, severing internet connectivity for private subnets
(機械翻訳)
根本原因 (1)
NAT インスタンスが手動で停止され、プライベートサブネットのインターネット接続が切断された
ECS のデプロイを実行してからはただ Slack の画面を眺めているだけでしたが、問題なくトラブル対応における調査までをシステム側で実施してくれました!
まとめ
今回は DevOps Agent をトラブル検知のシステムに組み込み、トラブル対応フローにおいて自動化範囲の拡大する運用方法についてご紹介しました。
DevOps Agent という新しいサービスが発表されてからこのサービスをどのように活用するのが良いか考えていましたが、今回のユースケースが 1 つの回答だと思っています。
皆さんもこの記事を参考に DevOps Agent を日々の運用にご活用ください!

第二SAチームのhengeです。 ゲームとゴルフが好きなエンジニアです。 よろしくお願いします。


Recommends
こちらもおすすめ
-

Amazon Bedrock 経由で Claude Code を利用するまで
2026.3.18




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16