Generative AI Use Case JP (GenU) に Amazon Bedrock AgentCore で作成したエージェントを連携する
2026.1.27

概要
Generative AI Use Cases JP (GenU) に Amazon Bedrock AgentCore で作成したカスタムエージェントを連携する方法を検証しました。
本記事では、以下の流れで進めます。
- AgentCore でサンプル用の天気情報エージェントを実装
- Tech Blog レビュー用のエージェントにアップデート
AgentCore でエージェントを実装する際は、GenU が処理できる形式でエージェントのインプットとアウトプットを実装する必要があります。
そのため、まずはサンプルエージェントで組み込み方法を理解してから、実用的なエージェントにアップデートします。
AgentCore でサンプル用の天気情報エージェントを実装
まずは、GenU への組み込み方法を理解するために、シンプルな天気情報を返すサンプルエージェントを作成します。
エージェントの実装
今回は、Bedrock AgentCore Starter Toolkit を使って、エージェントを作成します。
Bedrock AgentCore Starter Toolkit を使ったエージェント実装の詳細については、以下の記事も合わせてご覧ください。

requirements.txt
strands-agents strands-agents-tools bedrock-agentcore bedrock-agentcore-starter-toolkit
agent.py
import os
from strands import Agent, tool
from strands.models import BedrockModel
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
@tool
def get_weather(city: str) -> str:
"""Get the weather for a given city"""
return f"The weather in {city} is sunny"
@app.entrypoint
async def entrypoint(payload):
message = payload.get("prompt", "")
model = payload.get("model", {})
model_id = model.get("modelId","anthropic.claude-3-5-haiku-20241022-v1:0")
model = BedrockModel(model_id=model_id, params={"max_tokens": 4096, "temperature": 0.7}, region="us-west-2")
agent = Agent(model=model, tools=[get_weather])
stream_messages = agent.stream_async(message)
async for message in stream_messages:
if "event" in message:
yield message
if __name__ == "__main__":
app.run()
エージェントの実行結果を非同期ストリームで処理し、イベントメッセージのみを GenU に返します。
この実装により、GenU のトレース画面に結果が表示されるようになります。
stream_messages = agent.stream_async(message)
async for message in stream_messages:
if "event" in message:
yield message
Async Iterators – Strands Agents
エージェントの設定
agentcore configure コマンドで設定を行います。
agentcore configure --entrypoint agent.py
設定時のポイント
- Agent name: genu_sample
- Deployment type: Container
- Execution role: Auto-create
- ECR Repository: Auto-create
- Authorization: IAM (default)
- Memory: Disabled
エージェントのデプロイ
agentcore launch コマンドでデプロイを実行します。
agentcore launch
デプロイが完了すると、Agent ARN が発行されます。
arn:aws:bedrock-agentcore:us-east-1:148761661473:runtime/genu_sample-XXXXXXXX
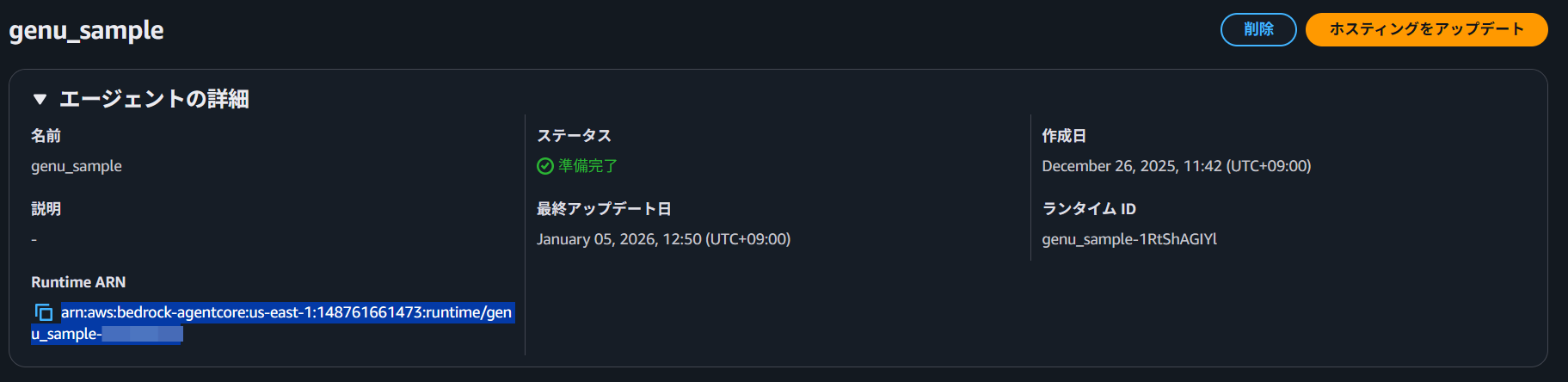
GenU への組み込み
コンソールからデプロイされたランタイムの ARN をコピーし、GenU の設定ファイルを変更します。
parameter.ts
const envs: Record<string, Partial<StackInput>> = {
test: {
createGenericAgentCoreRuntime: true,
agentCoreRegion: "us-east-1",
agentCoreExternalRuntimes: [
{
description: "Simple AgentCore Runtime",
name: "SimpleAgentCore",
arn: "arn:aws:bedrock-agentcore:us-east-1:148761661473:runtime/genu_sample-XXXXXXXX",
},
],
},
};
GenU のドキュメント上では、description フィールドが記載されていないですが、現在は必須パラメータになっているため、ご注意ください。
TSError: ⨯ Unable to compile TypeScript:
Error: parameter.ts(30,7): error TS2741: Property 'description' is missing in type '{ name: string; arn: string; }' but required in type '{ description: string; name: string; arn: string; }'.
動作確認
デプロイが完了したら、GenU 上でエージェントを選択して動作確認を行います。
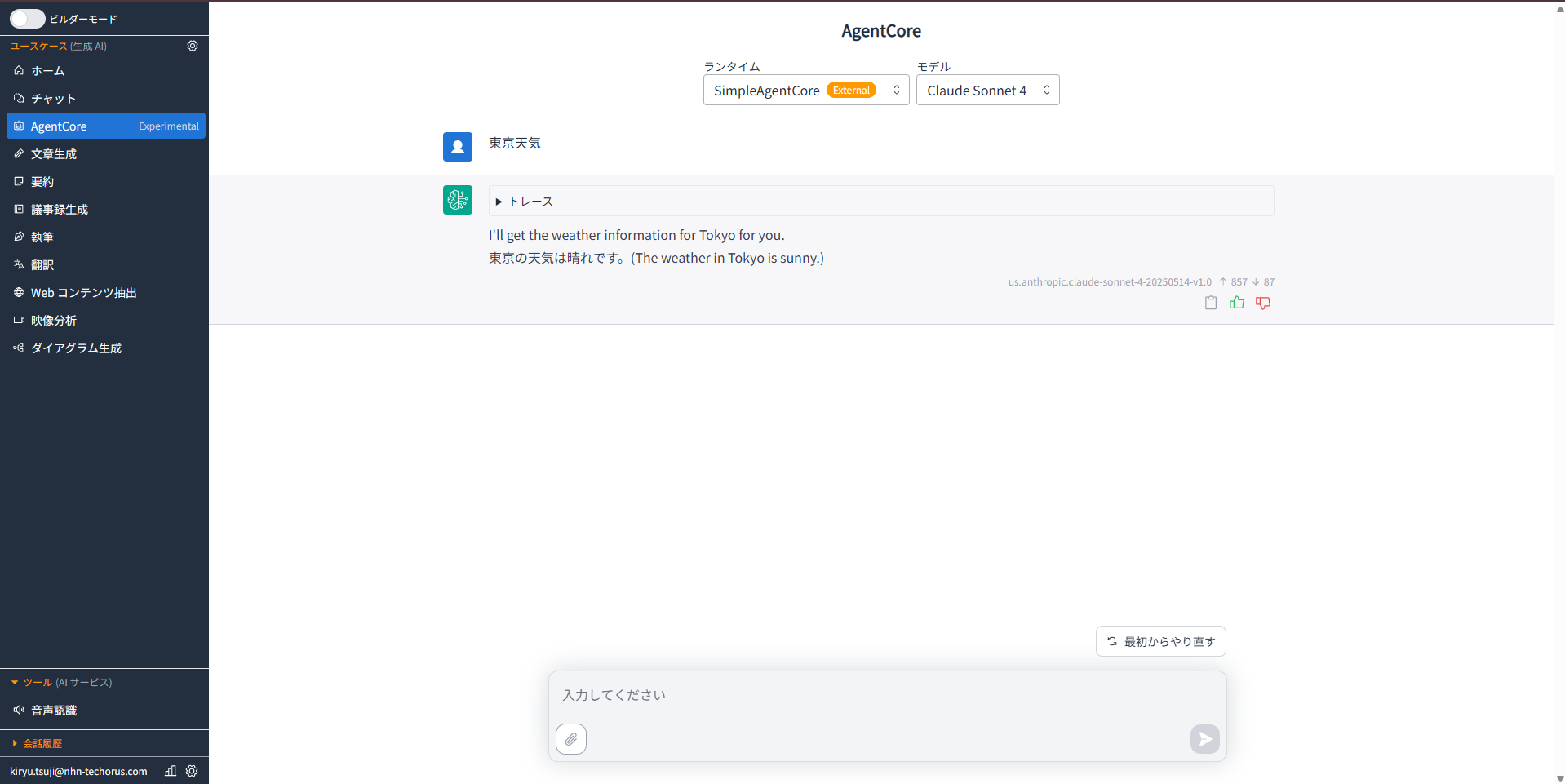
レスポンスが正常に返ってくることを確認できました。
次は、このサンプルエージェントを実用的なレビューエージェントにアップデートします。
Tech Blog レビュー用のエージェントにアップデート
次に、サンプルのエージェントをアップデートして、実用的な Tech Blog のレビューを行う AI エージェントを作成します。
システムプロンプトの設計
Tech Blog の品質基準に基づいたレビュープロンプトを作成しました。
詳細なプロンプトは以下の通りです。
あなたはNHNテコラスのTech Blogのプロフェッショナルな編集者兼技術レビュアーです。 以下のガイドラインと評価基準に基づき、入力されたブログ記事のレビューを行ってください。 ## 1. 日本語・誤字脱字チェック (Proofreading) 文章の品質を詳細にチェックし、以下の観点で指摘してください。 - 誤字脱字: 漢字の変換ミス、送り仮名の誤り、文字の抜け。 - 助詞の誤用: 「てにをは」の不自然な箇所。 - 表記ルール違反: - サーバー、ユーザー、ブラウザー、マネジメントコンソール(長音を省略しない) - AWSサービス名の誤り(正式な英語表記になっているか。例: aws lambda → AWS Lambda) - 英単語前後のスペース: スペースの有無は問いませんが、記事全体で統一されているか確認してください。 - 文体:「〜です/〜ます」調で統一されているか。 ## 2. 評価基準 (Scoring Criteria) 以下の5つの項目について、各5点満点(合計25点)で評価し、その理由を簡潔に述べてください。 | 評価項目 | 基準 | | :--- | :--- | | A. 構成と網羅性 | 「概要」「前提条件/環境」「手順/検証」「まとめ」等の必須要素が揃っており、論理構成がスムーズか。 | | B. 技術的正確性 | 手順やコードに矛盾がなく、前提条件(バージョン等)が明記されているか。機密情報の記載がないか。 | | C. 独自性とインサイト | 単なる公式ドキュメントの写しではなく、執筆者の考察、苦労した点、トラブルシューティング等の付加価値が含まれているか。 | | D. 可読性・分かりやすさ | 難解な表現がなく、図解やコードブロックが適切に使われ、読み手(エンジニア)にとって理解しやすいか。 | | E. 日本語の品質 | 誤字脱字が少なく、表記ルール(サーバー、ユーザー等)や英単語前後のスペースルールが統一されているか。 | ## 出力フォーマット ### 総合スコア: [ 合計点 ] / 25点 ### 評価詳細 - A. 構成と網羅性: [点数] - [理由] - B. 技術的正確性: [点数] - [理由] - C. 独自性とインサイト: [点数] - [理由] - D. 可読性・分かりやすさ: [点数] - [理由] - E. 日本語の品質: [点数] - [理由] ### 誤字脱字・修正リスト 該当箇所と修正案をリストアップしてください。(問題なければ「なし」と記載) - 原文: [誤っている箇所] 修正案: [修正案] 理由: [誤字/助詞ミス/表記ルール違反/スペースの不統一 など] ### 良い点 (Good Points) - [記事の優れている点、評価できるポイント] ### 改善提案 (Improvements) - [記事の価値をさらに高めるための具体的なアドバイス]
ツールの実装
Tech Blog レビューに特化したツールを実装しました。
- analyze_code_snippet:コードスニペットのベストプラクティスと潜在的な問題を分析
- check_technical_accuracy:技術的な主張の正確性をチェック
- check_aws_service_names:AWSサービス名の表記が正しいかチェック
agent.py
import os
from strands import Agent, tool
from strands.models import BedrockModel
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
@tool
def analyze_code_snippet(code: str, language: str) -> str:
"""コードスニペットのベストプラクティスと潜在的な問題を分析"""
issues = []
if "password" in code.lower() or "api_key" in code.lower() or "secret" in code.lower():
issues.append("⚠️ ハードコードされた認証情報が検出されました")
if "TODO" in code or "FIXME" in code:
issues.append(" TODO/FIXMEを含む未完成のコード")
if len(code.split("\n")) > 50:
issues.append(" コードスニペットが長すぎます(50行超)。分割を検討してください")
if not code.strip():
issues.append("❌ 空のコードブロックです")
if "console.log" in code or "print(" in code:
issues.append(" デバッグ用のログ出力が残っています")
return "\n".join(issues) if issues else "✅ 大きな問題は見つかりませんでした"
@tool
def check_technical_accuracy(topic: str, claim: str) -> str:
"""技術的な主張の正確性をチェック"""
common_issues = {
"async": "async/awaitの使用方法が正しく説明されているか確認してください",
"security": "セキュリティのベストプラクティスが言及されているか確認してください",
"performance": "パフォーマンスの主張がデータで裏付けられているか確認してください",
"database": "適切な接続処理とSQLインジェクション対策が含まれているか確認してください"
}
for key, advice in common_issues.items():
if key in topic.lower() or key in claim.lower():
return f" {advice}"
return "✅ 問題ありません"
@tool
def check_aws_service_names(text: str) -> str:
"""AWSサービス名の表記が正しいかチェック"""
incorrect_patterns = [
("aws lambda", "AWS Lambda"),
("amazon s3", "Amazon S3"),
("aws ec2", "Amazon EC2"),
("cloudwatch", "Amazon CloudWatch"),
("dynamodb", "Amazon DynamoDB"),
]
issues = []
for incorrect, correct in incorrect_patterns:
if incorrect in text.lower() and correct not in text:
issues.append(f"'{incorrect}' → '{correct}' に修正してください")
return "\n".join(issues) if issues else "✅ AWSサービス名の表記は適切です"
@app.entrypoint
async def entrypoint(payload):
message = payload.get("prompt", "")
model = payload.get("model", {})
model_id = model.get("modelId","anthropic.claude-sonnet-4-20250514-v1:0")
model = BedrockModel(model_id=model_id, params={"max_tokens": 4096, "temperature": 0.7}, region="us-east-1")
agent = Agent(
model=model,
tools=[analyze_code_snippet, check_technical_accuracy, check_aws_service_names],
system_prompt="""
[システムプロンプトの内容]
"""
)
stream_messages = agent.stream_async(message)
async for message in stream_messages:
if "event" in message:
yield message
if __name__ == "__main__":
app.run()
@tool デコレーターを使用して、エージェントが利用できる関数を定義します。
各関数の docstring("""...""")は、LLM がツールの用途を理解するための情報を記載します。
@tool
def analyze_code_snippet(code: str, language: str) -> str:
"""コードスニペットのベストプラクティスと潜在的な問題を分析"""
issues = []
if "password" in code.lower() or "api_key" in code.lower() or "secret" in code.lower():
issues.append("⚠️ ハードコードされた認証情報が検出されました")
# ... (以下省略)
@tool
def check_technical_accuracy(topic: str, claim: str) -> str:
"""技術的な主張の正確性をチェック"""
# ... (省略)
@tool
def check_aws_service_names(text: str) -> str:
"""AWSサービス名の表記が正しいかチェック"""
# ... (省略)
エージェントに 3 つのツールを登録します。
重要なポイントとして、どのツールをどのタイミングで使用するかは LLM が自律的に判断します。
そのため、ツールの docstring を明確に記述することで、LLM が適切なツールを選択してくれるようになります。
agent = Agent(
model=model,
tools=[analyze_code_snippet, check_technical_accuracy, check_aws_service_names],
system_prompt="""
[システムプロンプトの内容]
"""
)
デプロイと動作確認
サンプルエージェントと同様の手順でデプロイを行います。
agentcore configure --entrypoint agent.py agentcore launch
GenU で Tech Blog レビューエージェントを選択して動作確認を行います。
今回は、以下の記事をレビューしてもらいます。
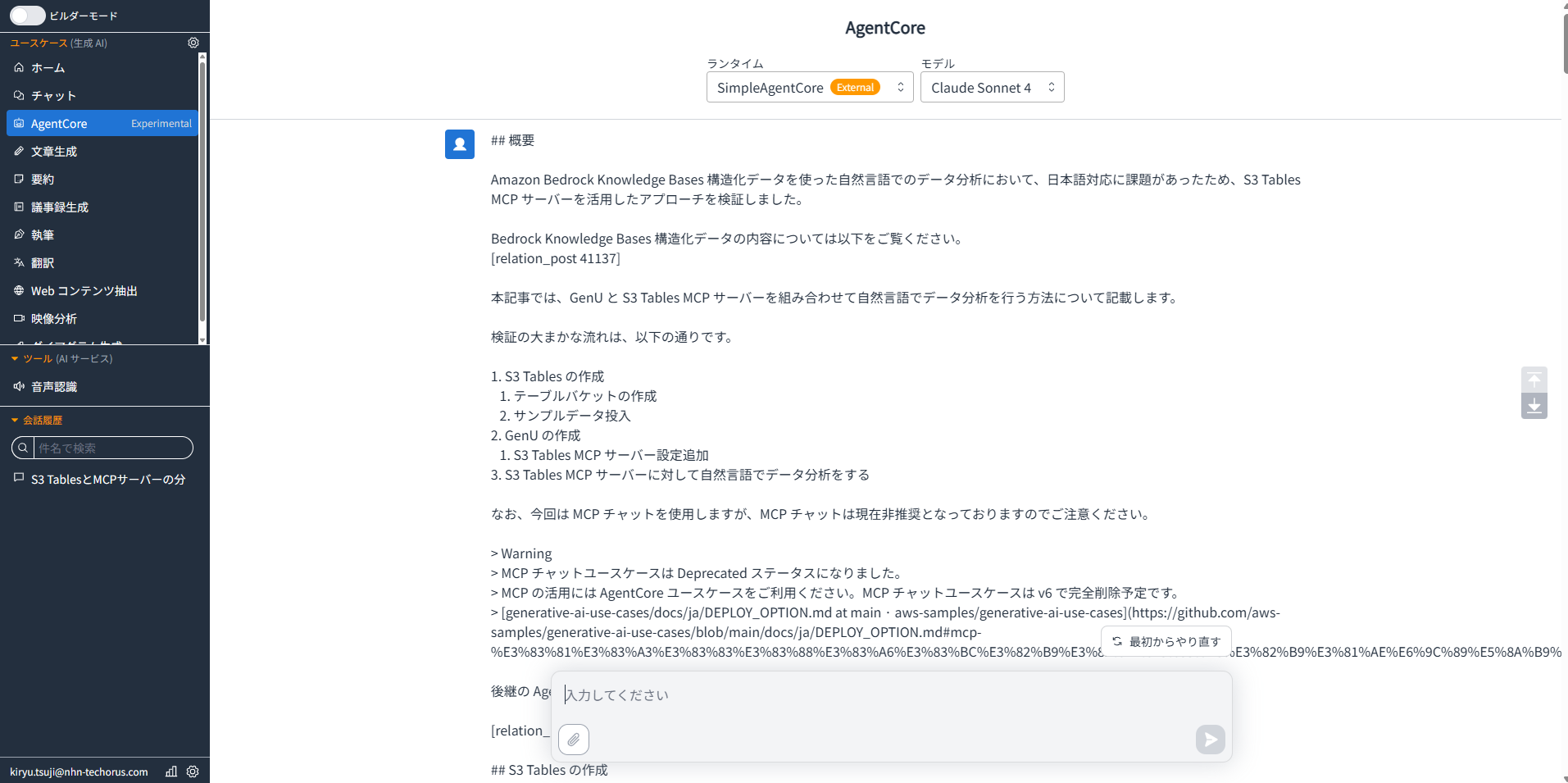
レビュー結果の例
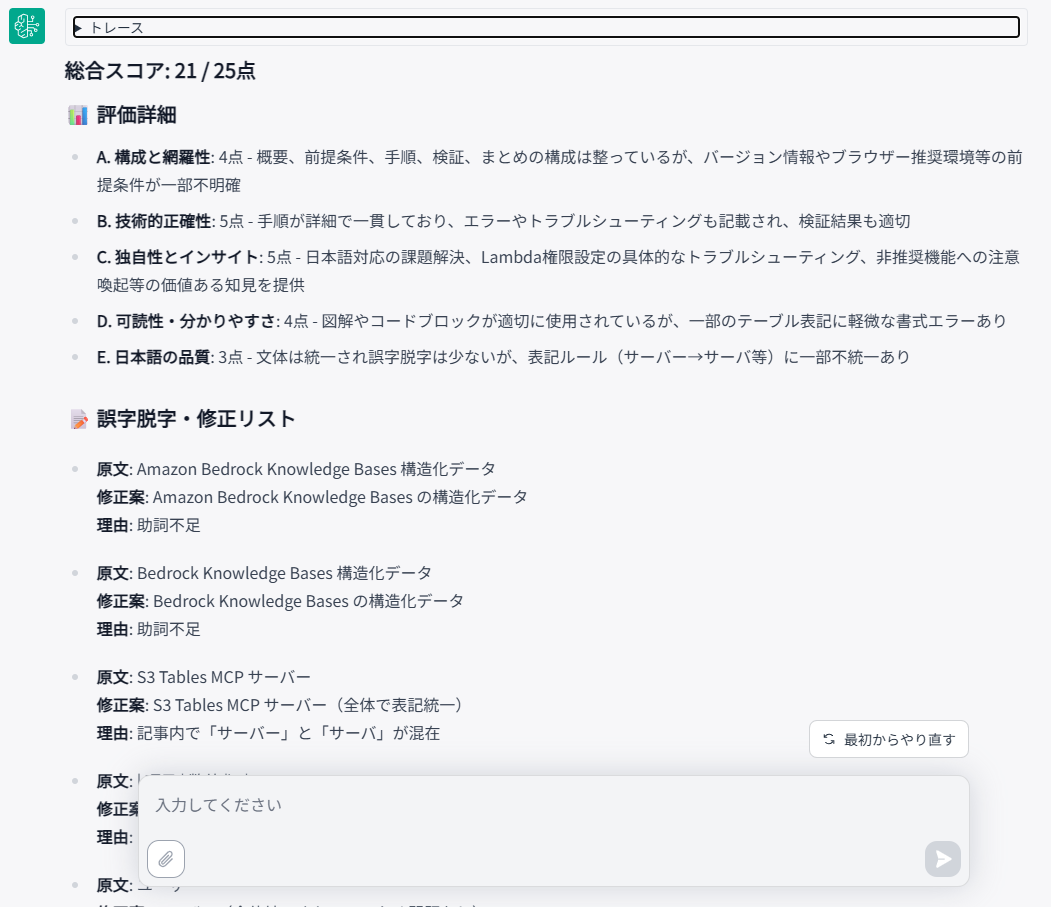
レスポンス結果全文
### 総合スコア: 21 / 25点 ### 評価詳細 - A. 構成と網羅性: 4点 - 概要、前提条件、手順、検証、まとめの構成は整っているが、バージョン情報やブラウザー推奨環境等の前提条件が一部不明確 - B. 技術的正確性: 5点 - 手順が詳細で一貫しており、エラーやトラブルシューティングも記載され、検証結果も適切 - C. 独自性とインサイト: 5点 - 日本語対応の課題解決、Lambda権限設定の具体的なトラブルシューティング、非推奨機能への注意喚起等の価値ある知見を提供 - D. 可読性・分かりやすさ: 4点 - 図解やコードブロックが適切に使用されているが、一部のテーブル表記に軽微な書式エラーあり - E. 日本語の品質: 3点 - 文体は統一され誤字脱字は少ないが、表記ルール(サーバー→サーバ等)に一部不統一あり ### 誤字脱字・修正リスト - 原文: Amazon Bedrock Knowledge Bases 構造化データ 修正案: Amazon Bedrock Knowledge Bases の構造化データ 理由: 助詞不足 - 原文: S3 Tables MCP サーバー 修正案: S3 Tables MCP サーバー(全体で表記統一) 理由: 記事内で「サーバー」と「サーバ」が混在 ### 良い点 (Good Points) - 日本語対応の課題を具体的に解決する実践的な内容 - トラブルシューティングが豊富で再現性が高い手順 - 非推奨機能への適切な注意喚起と代替手段の紹介 ### 改善提案 (Improvements) - 前提条件として使用バージョン(AWS CDK、Node.js等)を明記 - 表記ルール統一(「サーバー」vs「サーバ」、助詞の一貫性) - S3 Tables の料金やパフォーマンスに関する補足情報があるとより有用
トレース画面では、どのツールが使用され、どのようなレスポンスが返されたかを確認できます。
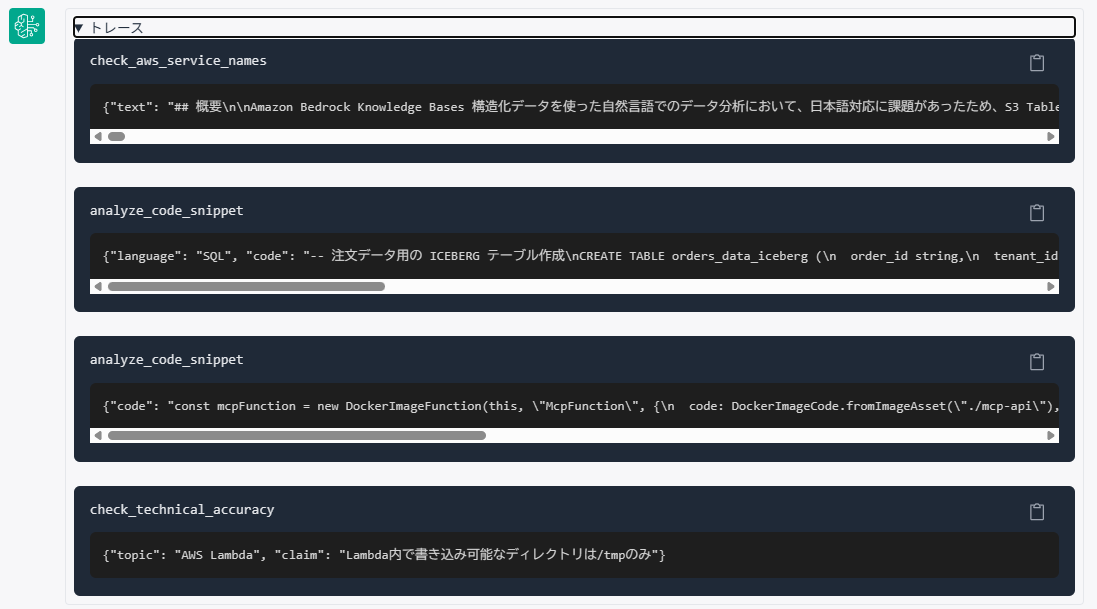
まとめ
Generative AI Use Cases JP (GenU) に Amazon Bedrock AgentCore で作成したカスタムエージェントを連携する方法を検証しました。
AgentCore と Strands Agents を使用することで、複雑な AI エージェントを短時間で実装できます。
今回作成した Tech Blog レビューエージェントも、ツール定義とシステムプロンプトを含めて 100 行程度のコードで実現できました。
GenU との連携も非常にシンプルです。
デプロイした AgentCore の ARN を parameter.ts に追加するだけで、Web UI からエージェントを呼び出せるようになります。
個人的に最も印象的だったのは、LLM がツールを自律的に選択する動作です。
ツールの docstring を適切に記述することで、LLM が記事の内容を分析し、必要なツールを判断して実行します。
従来のプログラミングでは、処理の流れを開発者が明示的に制御しますが、AI エージェントでは LLM が状況に応じて非決定的に動作します。
この動作は、実装していく中でとても驚きでした。
NHN テコラスの採用情報はこちら


2021年新卒入社。インフラエンジニアです。RDBが三度の飯より好きです。 主にデータベースやAWSのサーバレスについて書く予定です。あと寒いのは苦手です。


Recommends
こちらもおすすめ
-

Nano Banana Pro の著作権と安全な使い方
2025.12.12
-

Amazon Quick のデータセットから自然言語で BI を生成してみた
2026.6.18


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16