BigQueryの画面上からConversational Analytics(会話型分析)が可能になりました
2026.3.2

はじめに
以前にConversational Analytics APIで自然言語でデータ分析を行うの記事で、Conversational Analytics APIをStreamlit経由で起動した環境から実行する方法をご紹介しました。
2026年01月29日のアップデートによりStreamlitでアプリケーションを立ち上げずとも会話形式での分析を行えるようになりました。
リリース状況について
Conversational Analytics の機能は2026年03月02日現在プレビューの機能になります。
現在のリリース状況につきましては、サービスのリリースノートをご参照ください。
Google Cloud release notes
設定の流れ
BigQueryのメニュー画面に「エージェント (プレビュー)」という項目が増えておりますのでこちらを選択します。
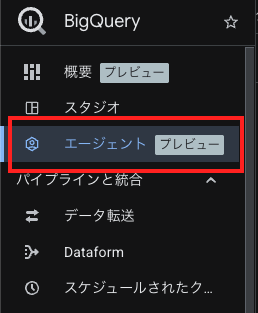
サンプルとして、3つのエージェントが提供されています。
- The Look Ecommerce
- ECサイトのデータを自然言語で分析するサンプル
- Agent for BigQuery Agent Analytics Data
- コンタクトセンターやチャット対応ログをKPI視点で分析するサンプル
- TPC-DS Retail Insights
- 大規模小売データを使った経営/業務分析を自然言語で行うサンプル
新規でエージェントを作成する場合は「+新しいエージェント」から作成することが可能です。
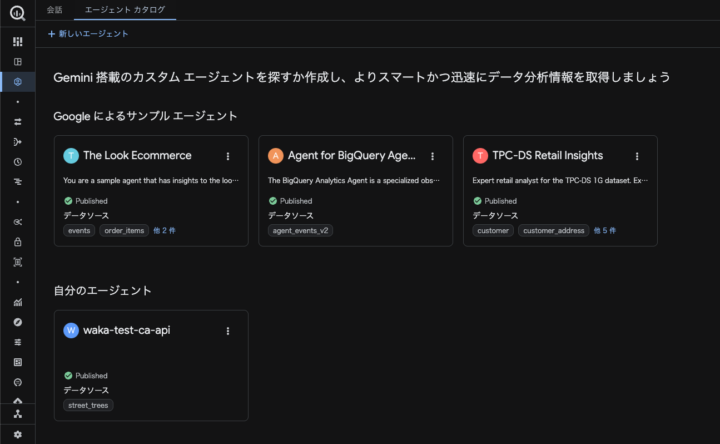
エージェントが参照に利用するデータソースを「ソースを追加」から選択できます。
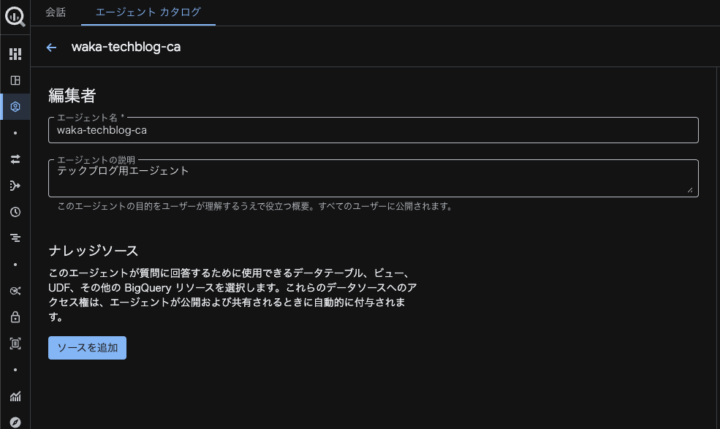
最初にBigQueryのテーブルやビューを選択できます。
本記事では、以下のSQLにてサンプル用のテーブルとデータの作成を行ったものを使用します。
create_sample_tables.sql
-- BigQuery Conversational Analytics サンプルテーブル作成
-- 1. 商品マスタテーブル
CREATE OR REPLACE TABLE {PROJECT_ID}.{DATASET_ID}.products (
product_id STRING,
product_name STRING,
category STRING,
price NUMERIC,
cost NUMERIC
);
-- 2. 顧客マスタテーブル
CREATE OR REPLACE TABLE {PROJECT_ID}.{DATASET_ID}.customers (
customer_id STRING,
customer_name STRING,
region STRING,
registration_date DATE,
customer_segment STRING
);
-- 3. 売上トランザクションテーブル
CREATE OR REPLACE TABLE {PROJECT_ID}.{DATASET_ID}.sales (
sale_id STRING,
sale_date DATE,
customer_id STRING,
product_id STRING,
quantity INT64,
total_amount NUMERIC,
discount_amount NUMERIC,
payment_method STRING
);
-- ダミーデータ挿入
-- 商品データ
INSERT INTO {PROJECT_ID}.{DATASET_ID}.products VALUES
('P001', 'ノートパソコン', '電子機器', 120000, 80000),
('P002', 'ワイヤレスマウス', '電子機器', 3000, 1500),
('P003', 'キーボード', '電子機器', 8000, 4000),
('P004', 'モニター', '電子機器', 35000, 20000),
('P005', 'オフィスチェア', '家具', 45000, 25000),
('P006', 'デスク', '家具', 60000, 35000),
('P007', 'デスクライト', '家具', 8000, 4000),
('P008', 'ノート', '文房具', 500, 200),
('P009', 'ボールペン', '文房具', 150, 50),
('P010', 'ファイル', '文房具', 300, 100);
-- 顧客データ
INSERT INTO {PROJECT_ID}.{DATASET_ID}.customers VALUES
('C001', '山田太郎', '東京', '2023-01-15', 'プレミアム'),
('C002', '佐藤花子', '大阪', '2023-02-20', 'スタンダード'),
('C003', '鈴木太郎', '東京', '2023-03-10', 'プレミアム'),
('C004', '田中花子', '福岡', '2023-04-05', 'スタンダード'),
('C005', '伊藤太郎', '名古屋', '2023-05-12', 'ベーシック'),
('C006', '渡辺花子', '東京', '2023-06-18', 'プレミアム'),
('C007', '中村太郎', '大阪', '2023-07-22', 'スタンダード'),
('C008', '小林花子', '札幌', '2023-08-30', 'ベーシック'),
('C009', '加藤太郎', '東京', '2023-09-14', 'プレミアム'),
('C010', '吉田花子', '福岡', '2023-10-25', 'スタンダード');
-- 売上データ(2024年のデータ)
INSERT INTO {PROJECT_ID}.{DATASET_ID}.sales VALUES
('S001', '2024-01-05', 'C001', 'P001', 1, 120000, 5000, 'クレジットカード'),
('S002', '2024-01-08', 'C002', 'P002', 2, 6000, 0, '銀行振込'),
('S003', '2024-01-12', 'C003', 'P005', 1, 45000, 2000, 'クレジットカード'),
('S004', '2024-01-15', 'C001', 'P003', 1, 8000, 0, 'クレジットカード'),
('S005', '2024-02-03', 'C004', 'P008', 10, 5000, 500, '代金引換'),
('S006', '2024-02-10', 'C005', 'P002', 1, 3000, 0, 'クレジットカード'),
('S007', '2024-02-14', 'C006', 'P006', 1, 60000, 5000, '銀行振込'),
('S008', '2024-02-20', 'C007', 'P004', 2, 70000, 3000, 'クレジットカード'),
('S009', '2024-03-01', 'C008', 'P009', 20, 3000, 0, '代金引換'),
('S010', '2024-03-05', 'C009', 'P001', 1, 120000, 10000, 'クレジットカード'),
('S011', '2024-03-12', 'C010', 'P007', 2, 16000, 1000, '銀行振込'),
('S012', '2024-03-18', 'C001', 'P004', 1, 35000, 0, 'クレジットカード'),
('S013', '2024-04-02', 'C002', 'P005', 1, 45000, 2000, 'クレジットカード'),
('S014', '2024-04-10', 'C003', 'P010', 5, 1500, 0, '代金引換'),
('S015', '2024-04-15', 'C004', 'P001', 1, 120000, 8000, 'クレジットカード'),
('S016', '2024-05-01', 'C005', 'P003', 1, 8000, 500, '銀行振込'),
('S017', '2024-05-08', 'C006', 'P002', 3, 9000, 0, 'クレジットカード'),
('S018', '2024-05-20', 'C007', 'P006', 1, 60000, 5000, '銀行振込'),
('S019', '2024-06-03', 'C008', 'P008', 15, 7500, 500, '代金引換'),
('S020', '2024-06-15', 'C009', 'P004', 1, 35000, 2000, 'クレジットカード');
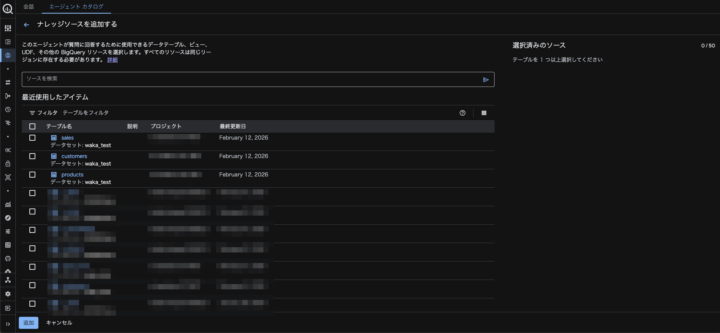
BigQueryのデータソース追加後、Geminiがデータを確認するうえで精度を上げるためのオプションを選択することができます。
検証済みクエリや用語集の項目は、会話形式で分析する際に精度を上げることに繋がります。
後述の「精度向上のためのオプションについて」の項目にて設定の有無による回答の違いを比較します。
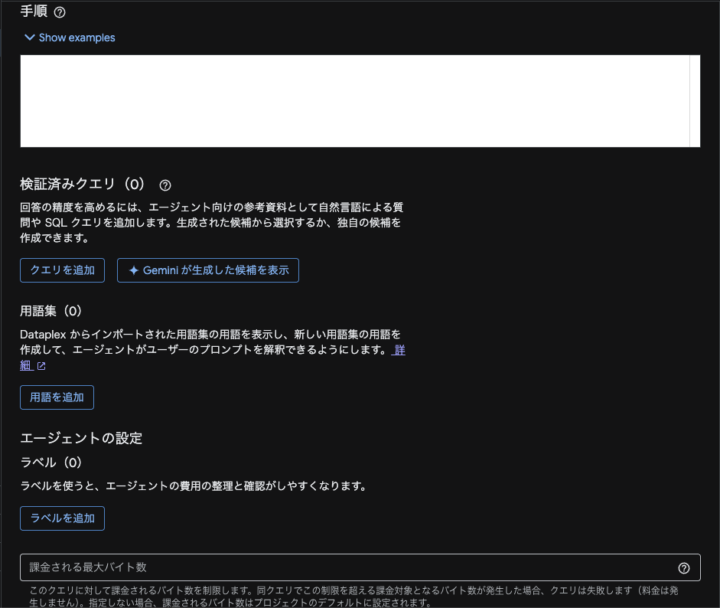
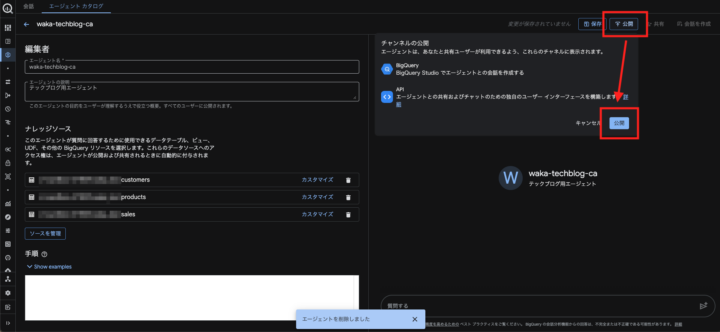
「公開」を行うことで、エージェントを用いた会話形式での分析を行うことができ、公開範囲の絞り込みも可能です。
精度向上のためのオプションについて
検証済みクエリ
検証済みクエリを登録することで、類似した質問に対してそのクエリを参考に回答が生成されるようになります。
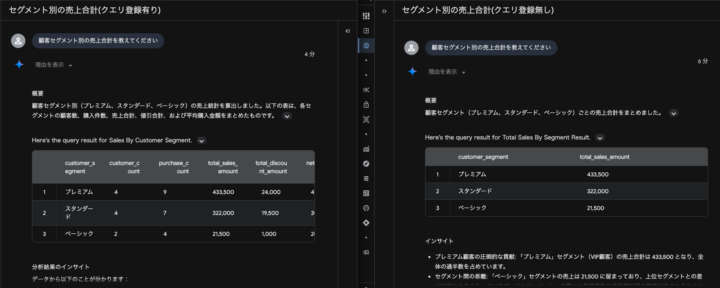
例として、以下のクエリをセグメント別の合計を出す際のクエリとして登録を行います。
SELECT
c.customer_segment AS `セグメント`,
COUNT(DISTINCT s.customer_id) AS `顧客数`,
COUNT(s.sale_id) AS `購入件数`,
SUM(s.total_amount) AS `売上合計`,
SUM(s.discount_amount) AS `値引合計`,
SUM(s.total_amount - s.discount_amount) AS `純売上合計`,
ROUND(AVG(s.total_amount), 0) AS `平均購入金額`
FROM `{PROJECT_ID}.{DATASET_ID}.sales` s
JOIN `{PROJECT_ID}.{DATASET_ID}.customers` c
ON s.customer_id = c.customer_id
GROUP BY c.customer_segment
ORDER BY `売上合計` DESC;
クエリを登録していない場合は指示通り金額の合計を算出してくれますが、クエリ登録を行った際は指定の通り値引き額や購入個数などの分析ができています。
用語集
独自の指標や専門用語が定義されたデータセットの分析においても、本機能を用いることで意図通りの値を算出可能です。
なお、プレビュー中の機能のためか、日本語の表記が「期間」となっておりますがおそらく用語(Term)のことだと思われます。
(英語表記に変更してもAgentの設定周りは日本語で表示されていたため元の用語は確認できませんでした。)
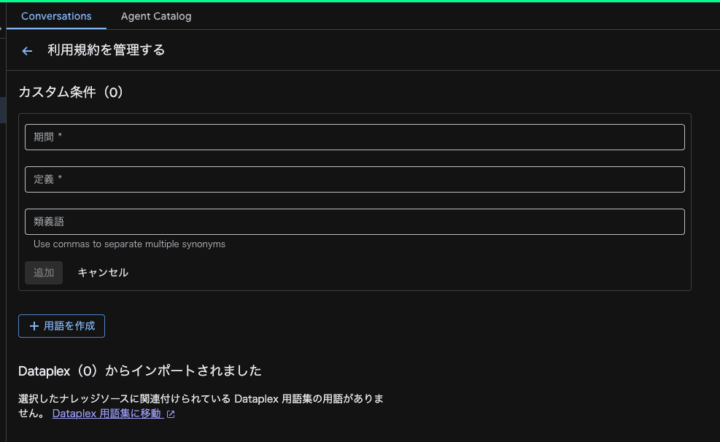
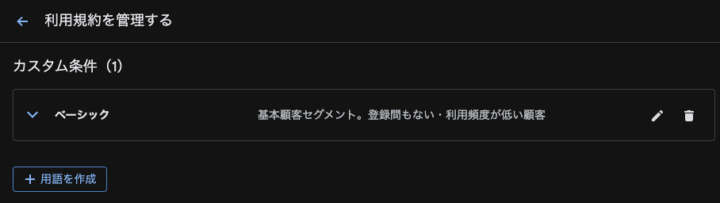
例えばcustomersテーブルから「ベーシック」という単語を新規顧客向けに使っていると仮定し用語の登録を行います。
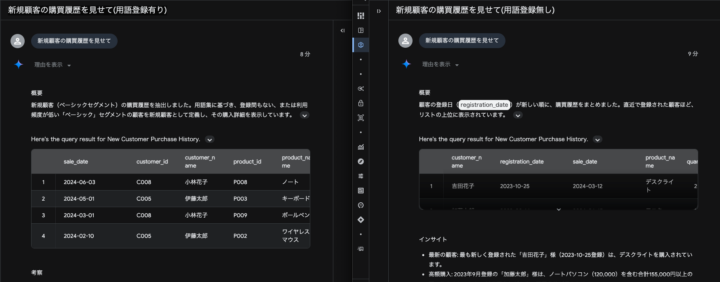
「新規顧客の購買履歴を見せて」と質問した場合、用語登録前はデフォルトの動作として登録日が新しい順にデータを取得しますが、
用語登録後はcustomersテーブルの「ベーシック」セグメントのユーザーに絞り結果を取得しています。
おわりに
自然言語を用いた会話形式でのデータ分析がGoogle CloudのGUI上から行うことができるようになったため非エンジニアの方もBigQueryに溜まったデータをより有効活用しやすくなりました。
NHN テコラスの採用情報はこちら


2022年に中途入社した人です。好きなAWSサービスはLambdaです。


Recommends
こちらもおすすめ
-

Amazon Bedrockのウォーターマーク検出を試してみた!
2024.5.23



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16