Amazon Redshift で COPY コマンドを使用し Amazon S3 からデータをロードする
2026.2.25

概要
Amazon S3 にある CSV ファイルを、Amazon Redshift の COPY コマンドでロードする手順を解説する記事です。
以下の 4 ステップで進めます。
- S3 に CSV ファイルをアップロード
- IAM ロールを作成・付与
- Redshift でテーブル作成
- CSV ファイルのデータロード
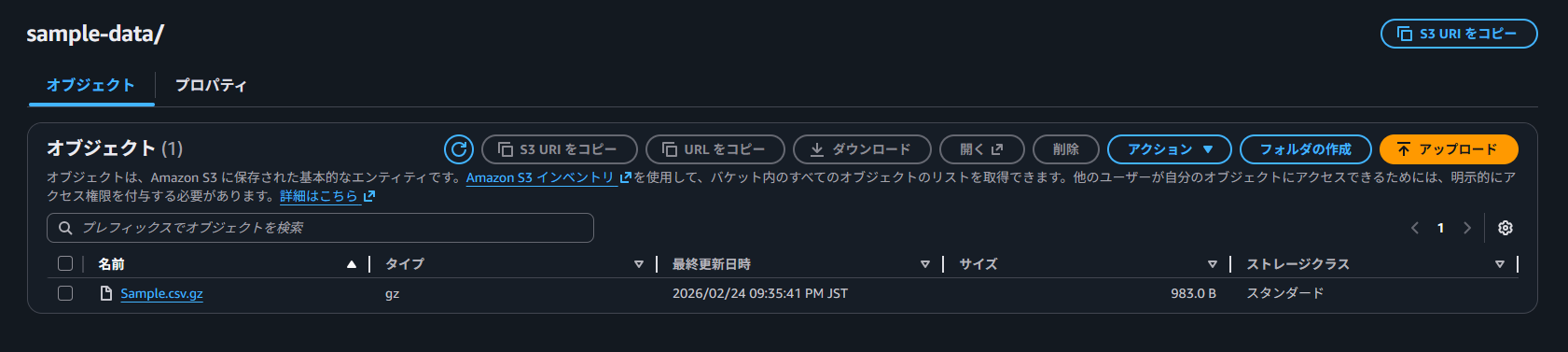
1. S3 に CSV ファイルをアップロード
まず、Redshift にロードする元となる CSV ファイルを用意し、S3 バケットにアップロードします。
今回は、以下のような EC サイトの注文を模したサンプルデータを生成 AI で作成しました。
ORD001,2025-01-15,CUST001,山田太郎,PROD101,ノートパソコン,電子機器,1,120000,120000,クレジットカード,東京都渋谷区1-2-3,配送完了,2025-01-15 10:30:00,2025-01-18 14:20:00 ORD002,2025-01-16,CUST002,佐藤花子,PROD102,ワイヤレスマウス,周辺機器,2,3000,6000,銀行振込,神奈川県横浜市中区4-5-6,配送完了,2025-01-16 11:15:00,2025-01-19 09:45:00 ORD003,2025-01-17,CUST003,鈴木一郎,PROD103,メカニカルキーボード,周辺機器,1,8000,8000,代金引換,大阪府大阪市北区7-8-9,配送中,2025-01-17 14:20:00,2025-01-20 16:30:00 ORD004,2025-01-18,CUST004,田中美咲,PROD104,27インチモニター,電子機器,1,45000,45000,クレジットカード,愛知県名古屋市中区10-11-12,配送完了,2025-01-18 09:45:00,2025-01-21 11:00:00 ORD005,2025-01-19,CUST005,高橋健太,PROD105,USB-Cケーブル,周辺機器,5,1500,7500,コンビニ決済,福岡県福岡市博多区13-14-15,処理中,2025-01-19 16:30:00,2025-01-19 16:30:00 ORD006,2025-01-20,CUST006,伊藤由美,PROD106,外付けSSD 1TB,ストレージ,1,15000,15000,クレジットカード,北海道札幌市中央区16-17-18,配送完了,2025-01-20 13:10:00,2025-01-23 10:15:00 ORD007,2025-01-21,CUST007,渡辺誠,PROD107,Webカメラ,周辺機器,2,8500,17000,銀行振込,宮城県仙台市青葉区19-20-21,配送完了,2025-01-21 10:50:00,2025-01-24 15:40:00 ORD008,2025-01-22,CUST008,中村愛,PROD108,ノイズキャンセリングヘッドセット,音響機器,1,12000,12000,クレジットカード,広島県広島市中区22-23-24,配送中,2025-01-22 15:25:00,2025-01-25 09:20:00 ORD009,2025-01-23,CUST009,小林大輔,PROD109,レーザープリンター,事務機器,1,35000,35000,代金引換,京都府京都市下京区25-26-27,処理中,2025-01-23 11:40:00,2025-01-23 11:40:00 ORD010,2025-01-24,CUST010,加藤麻衣,PROD110,ドキュメントスキャナー,事務機器,1,28000,28000,クレジットカード,埼玉県さいたま市大宮区28-29-30,配送完了,2025-01-24 14:55:00,2025-01-27 13:10:00
COPY コマンドの GZIP オプションを試すため、このファイルを Sample.csv.gz として GZIP 形式で圧縮し、S3 バケットにアップロードしておきます。
2. IAM ロールを作成・付与
次に、Redshift が S3 バケットにアクセスするための権限を持つ IAM ロールを作成し、Redshift クラスターにアタッチします。
IAM ロールの信頼関係ポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
続いて、S3 バケットへの読み取り権限を許可する IAM ポリシーを作成し、ロールにアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::cold-airflow-redshift-load-data-148761661473",
"arn:aws:s3:::cold-airflow-redshift-load-data-148761661473/*"
]
}
]
}
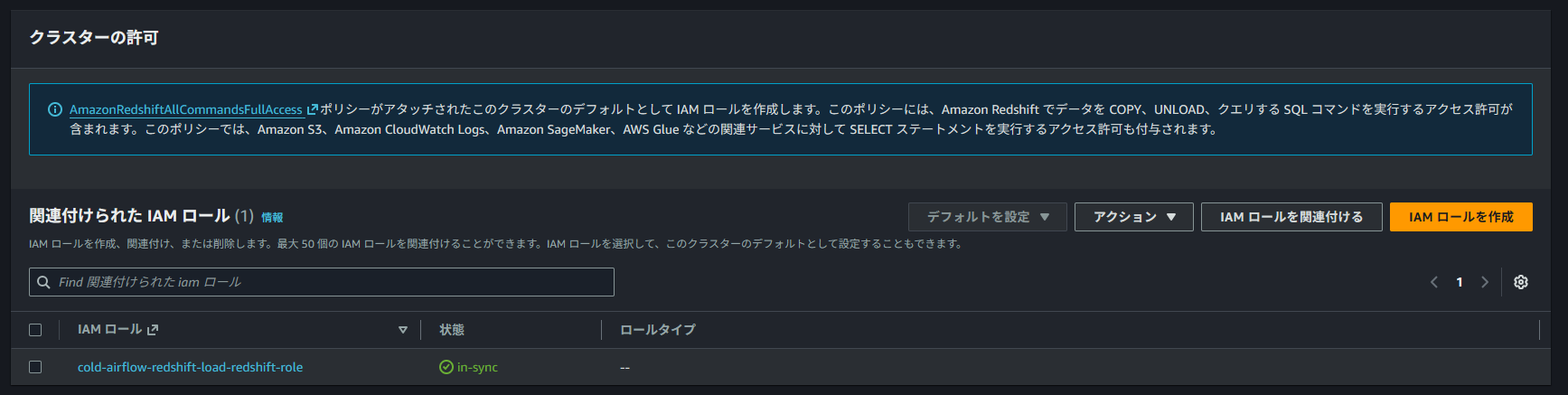
作成した IAM ロールを、対象の Redshift クラスターに関連付けます。
これはクラスターのプロパティ画面から設定できます。
3. Redshift でテーブル作成
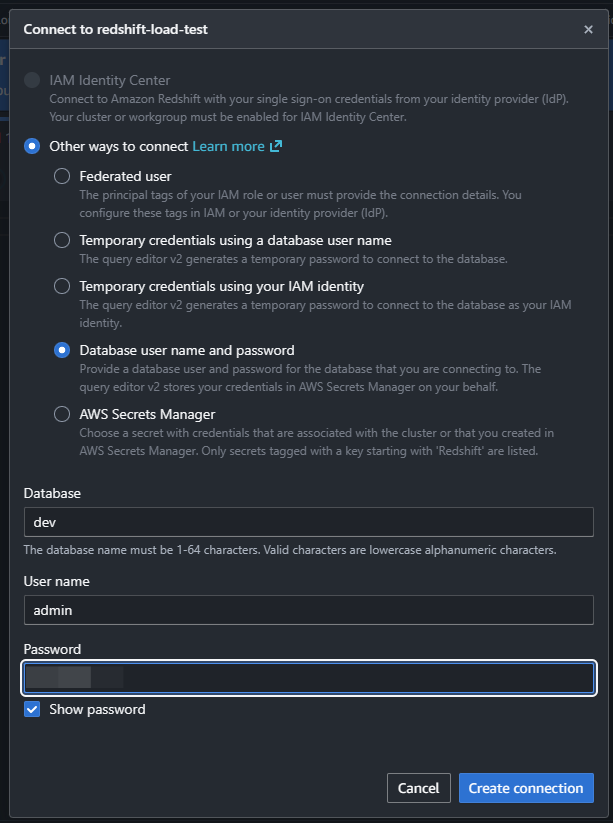
Redshift のクエリエディタ v2 を使い、データベースに接続して作業を進めます。
まず、S3 からロードしたデータを格納するためのテーブルを、以下の SQL で作成します。
CREATE TABLE IF NOT EXISTS orders (
order_id VARCHAR(20) NOT NULL,
order_date DATE,
customer_id VARCHAR(20),
customer_name VARCHAR(50),
product_id VARCHAR(20),
product_name VARCHAR(100),
category VARCHAR(50),
quantity INTEGER,
unit_price INTEGER,
total_amount INTEGER,
payment_method VARCHAR(50),
shipping_address VARCHAR(200),
status VARCHAR(20),
created_at TIMESTAMP,
updated_at TIMESTAMP,
PRIMARY KEY (order_id)
);
4. CSV ファイルのデータロード
では、COPY コマンドを実行して、S3 からデータをロードします。
COPY orders FROM 's3://cold-airflow-redshift-load-data-148761661473/sample-data/Sample.csv.gz' IAM_ROLE 'arn:aws:iam::148761661473:role/cold-airflow-redshift-load-redshift-role' CSV GZIP DELIMITER ',' REGION 'us-east-1' ACCEPTINVCHARS TRUNCATECOLUMNS TIMEFORMAT 'YYYY-MM-DD HH:MI:SS';
パラメータの説明については以下の通りです。
| パラメータ | 説明 |
|---|---|
| FROM | データソースの S3 パスを指定します。 |
| IAM_ROLE | S3 へのアクセスに使用する IAM ロールの ARN を指定します。 |
| REGION | S3 バケットが存在するリージョンを指定します。 |
| CSV | 入力データが CSV 形式であることを指定します。 |
| GZIP | 入力ファイルが GZIP 形式で圧縮されていることを示します。 |
| DELIMITER | フィールドの区切り文字(今回はカンマ)を指定します。 |
| ACCEPTINVCHARS | VARCHAR 列に無効な UTF-8 文字が含まれていてもロードを許可します。 |
| TRUNCATECOLUMNS | テーブル定義よりも長い文字列データを、列の長さに合わせて切り捨てます。 |
| TIMEFORMAT | TIMESTAMP 型や DATE 型の書式を指定します。 |
より詳細なオプションについては、公式ドキュメントをご参照ください。
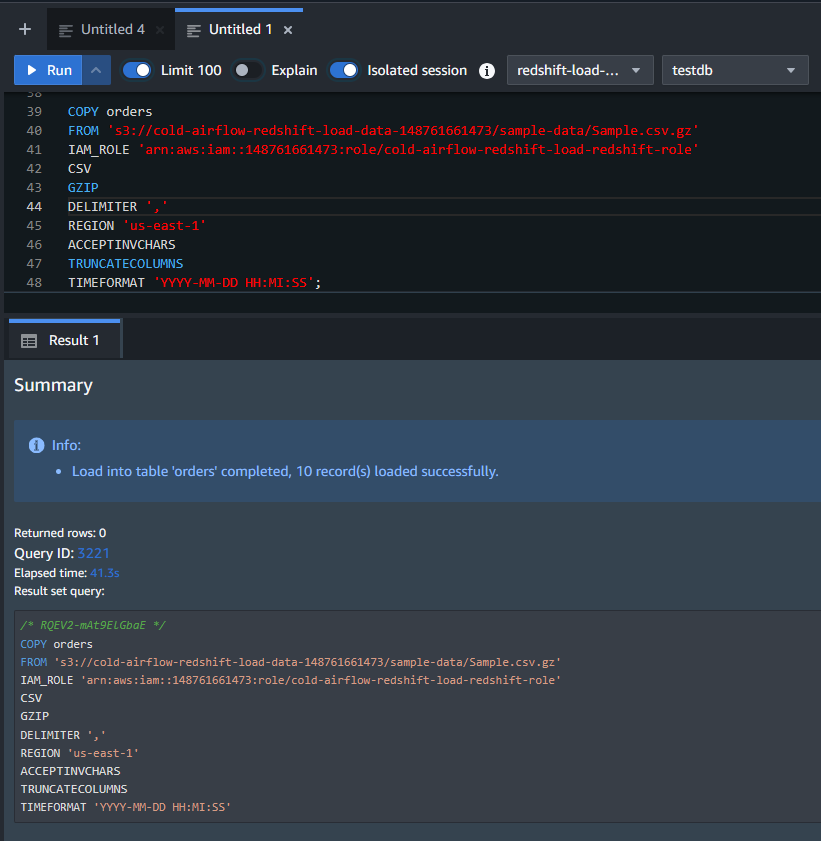
最後に、SELECT 文でテーブルの中身を確認し、データが正しくロードされたかを確認します。
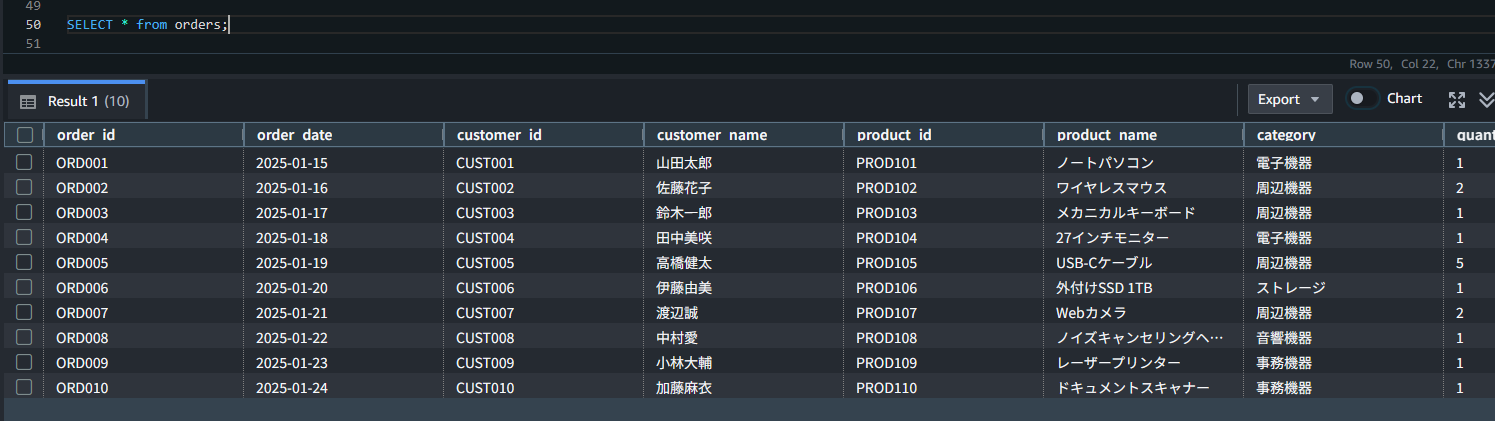
問題なくデータが表示され、ロードが成功したことが確認できました。
今回は、エラーが発生しませんでしたが、データロードのエラーが発生した場合は、「STL_LOAD_ERRORS テーブル」を使用してエラーを調査することが可能です。
Amazon Redshift で COPY を使用する際のデータロードエラーをトラブルシューティングする | AWS re:Post
まとめ
今回は、Amazon Redshift の COPY コマンドを使い、S3 に置かれた GZIP 圧縮済みの CSV ファイルからデータをロードする手順を解説しました。
COPY コマンドは、データ形式や圧縮形式、文字コード、エラーハンドリングなど、多彩なオプションを備えており、さまざまな形式のデータに柔軟に対応できます。
S3 をデータレイクとして活用している場合、COPY コマンドは Redshift へのデータ連携をスムーズかつ効率的に行うための強力な手段となります。
参考資料
Amazon Redshift の別のアカウントへのデータのコピーまたはアンロードを行う | AWS re:Post
COPY コマンドを使用し、Amazon S3 からロードする – Amazon Redshift
Amazon Redshift で COPY を使用する際のデータロードエラーをトラブルシューティングする | AWS re:Post
NHN テコラスの採用情報はこちら


2021年新卒入社。インフラエンジニアです。RDBが三度の飯より好きです。 主にデータベースやAWSのサーバレスについて書く予定です。あと寒いのは苦手です。


Recommends
こちらもおすすめ
-

Amazon S3のデータをAmazon Auroraにインポートする
2023.9.28
-

Amazon Redshift クラスターのスケジュールによる一時停止と再開
2026.2.27
-

【WinSCP】MFA環境でAmazon S3にアクセスするための手順まとめ
2025.1.27



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16