Google BigQueryからAmazon Redshiftにデータを移行してみる

更新履歴
– 2020/1/8 記事内容の修正を行いました。
はじめに
こんにちは。データサイエンスチームのmotchieです。
データウェアハウス(DWH)を使うことで、大規模なデータに対する高速なクエリ処理が実現し、BIを初めとした様々なデータ活用が可能になります。
クラウドDWHといえば、Amazon RedshiftやGoogle BigQueryなどが有名です。
re:Invent2019では、Redshiftの新機能 Amazon Redshift RA3 ノードが発表されました。
RA3ノードはAWS Nitro Systemベースの次世代コンピュートインスタンスで、頻繁にアクセスされるデータはノード上のSSD、それ以外はS3へ自動で配置されるマネージドストレージを備えています。
RA3ノードによって、以下のように、Redshiftは大きな進歩を遂げました。
・従来のDS2ノードに比べて、同じコストで2倍のパフォーマンスと2倍のストレージ容量
・他のクラウドDWHに比べて、最大3倍の処理速度
・処理能力(インスタンス数)とストレージ(S3/SSD)の柔軟なスケーリング
更に、Advanced Query Accelerator (AQUA) for Amazon Redshift(※執筆現在プレビュー期間)によって、他のクラウドDWHに比べて最大10倍もの処理速度が実現するとのことです。
クラウドDWHは日々進歩を続けています。
さて、今回の記事では、クラウドDWH間でのデータ移行について紹介したいと思います。
RedshiftからBigQueryに移行するケース(AWS->GCP)では、BigQuery Data Transfer Service APIを使う方法がありますが、
BigQueryからRedshiftに移行する場合(GCP->AWS)については、あまり情報が見当たらないように思います。
そこでこの記事では、BigQueryからRedshiftにデータを移行する手順を1つご紹介します。
具体的には、BigQueryのデータをGoogle Cloud Storage(GCS)経由でAmazon S3に出力し、AWS GlueでETLを行い、Redshiftにデータを格納してみたいと思います。
なお、この記事では、ゼロからRedshiftクラスターを立ち上げ、BigQueryで公開されているデータセットを使って移行を行うため、
事前に稼働中のRedshiftクラスターや自前のBigQueryデータがない場合でもお試しいただけます。
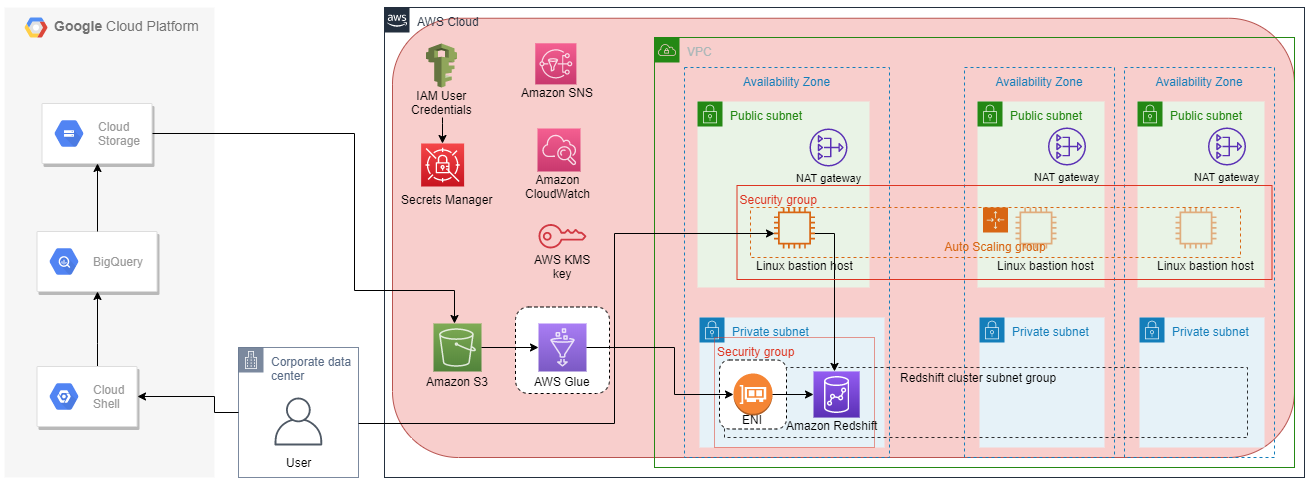
リソースの全体像
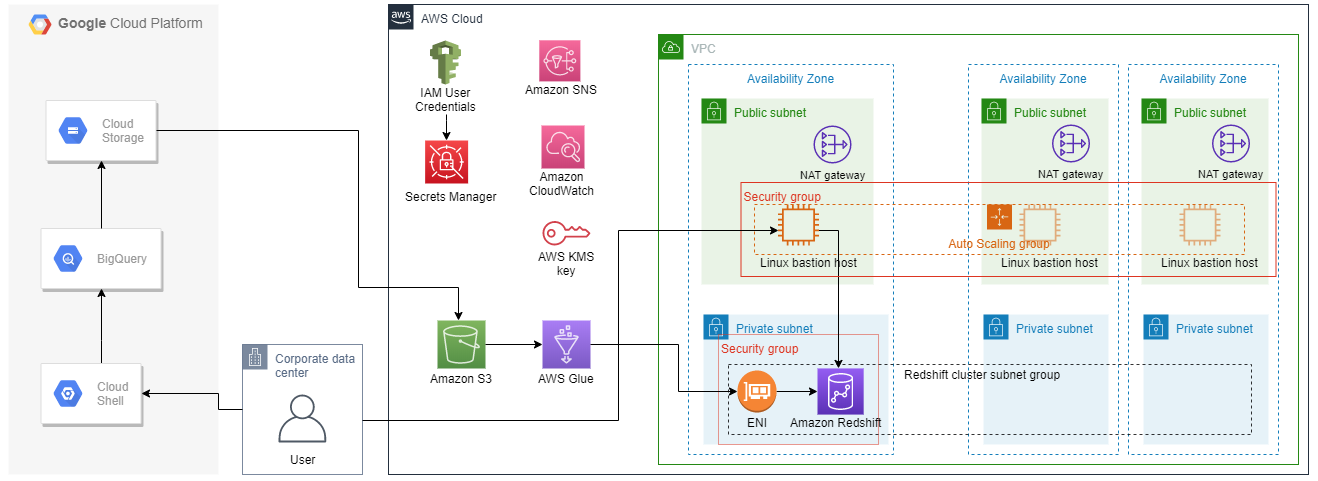
流れ
- CloudFormationテンプレートでRedshiftクラスターを作成する
- BigQueryの一般公開データセットを、GCS経由でS3に出力する
- S3のデータにGlueでETLを行い、Redshiftにデータを格納する
- Redshiftに接続して、クエリを投げてみる
- リソースの削除
前提条件として、AWS・GCP上でリソースにアクセスできる十分な権限が必要になります。
1. CloudFormationテンプレートでRedshiftクラスターを作成する
以下のAWSブログのAWS CloudFormationテンプレートをベースに、Redshiftクラスターを作成していきたいと思います。
Amazon Web Services ブログ:AWS CloudFormation を使用して Amazon Redshift クラスターの作成を自動化する
上記のテンプレートを活用することで、ベストプラクティスに沿って設計されたRedshiftクラスターが一発で作成できます。
設計とテンプレートの詳細については、上記ブログ記事をご確認ください。
1.1 テンプレートの取得
上記ブログ記事のCloudFormationテンプレートを取得します。
・ aws-vpc-blog.template
・ linux-bastion-blog.templat
・ redshift-blog.template
aws s3 cp s3://aws-bigdata-blog/artifacts/Automate_Redshift_Cluster_Creation_CloudFormation/aws-vpc-blog.template ./ aws s3 cp s3://aws-bigdata-blog/artifacts/Automate_Redshift_Cluster_Creation_CloudFormation/linux-bastion-blog.template ./ aws s3 cp s3://aws-bigdata-blog/artifacts/Automate_Redshift_Cluster_Creation_CloudFormation/redshift-blog.template ./
1.2 テンプレートにリソースを追加
今回、BigQueryのデータをRedshiftに移行する際に、追加のリソースが必要になります。
・GCSからS3へデータをコピーするための、IAMユーザー認証情報とS3バケット
・GlueからRedshiftへアクセスするためのネットワーク設定
テンプレートをカスタマイズして、リソースを追加してからデプロイしたいと思います。
1.2.1 linux-bastion-blog.template
まず、linux-bastion-blog.template (Bastionスタック用テンプレート)を修正していきます。
修正後のテンプレートは以下で確認できます。
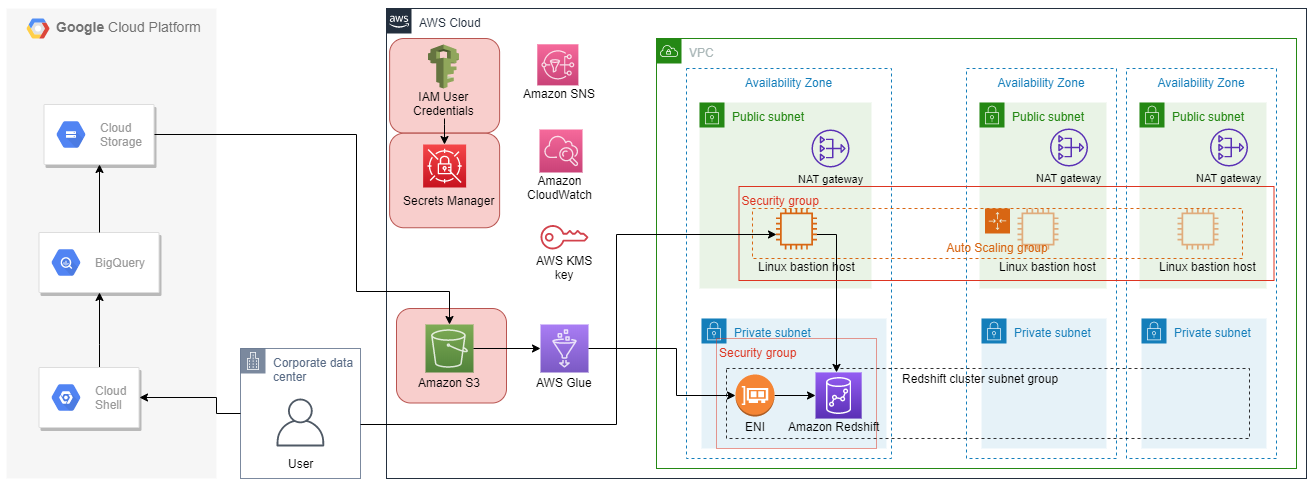
追加したリソースを赤色でハイライトしています。内容は以下の通りです。
・ データ格納用S3バケット
・ gsutilコマンド用のIAMユーザー・認証情報
・ 認証情報をセキュアに保存する用のAWS Secrets Manager
テンプレートの修正箇所をハイライトしています。
- Name: AutoScalingGroupName
Value: !Ref BastionAutoScalingGroup
# ---
BigQueryDataS3Bucket:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
AccessControl: Private
BucketName: !Join [ "-", [ !Ref 'AWS::StackName', "bigquery-data-bucket", !Ref 'AWS::AccountId' ] ]
S3UserForBoto:
Type: AWS::IAM::User
Properties:
Policies:
- PolicyDocument:
Version: 2012-10-17
Statement:
- Action:
- 's3:PutObject'
Effect: Allow
Resource: !Join
- "/"
- - !GetAtt BigQueryDataS3Bucket.Arn
- "*"
PolicyName: s3-put-policy-from-gcs-for-boto
UserName: !Join [ "-", [ !Ref 'AWS::StackName', "s3-user-for-boto", !Ref 'AWS::Region' ] ]
AccessKeyForBoto:
Type: AWS::IAM::AccessKey
Properties:
UserName: !Ref S3UserForBoto
SecretsForBoto:
Type: AWS::SecretsManager::Secret
Properties:
Name: !Sub "secrets-for-boto-user-${AWS::StackName}"
SecretString: !Sub '{"aws_access_key_id": "${AccessKeyForBoto}", "aws_secret_access_key": "${AccessKeyForBoto.SecretAccessKey}"}'
# ---
Outputs:
Redshiftスタックでデータ格納用S3バケット名が必要なため、以下の修正によって値を出力しています。
BastionSecurityGroupID:
Description: Use this Security Group to reference incoming traffic from the SSH bastion host/instance
Value: !Ref BastionSecurityGroup
Export:
Name: !Sub '${AWS::StackName}-BastionSecurityGroupID'
# ---
BigQueryDataS3BucketName:
Description: Bucket name will be imported in redshift cluter stack
Value: !Ref BigQueryDataS3Bucket
Export:
Name: !Sub '${AWS::StackName}-BigQueryDataS3BucketName'
# ---
1.2.2 redshift-blog.template
次に、redshift-blog.template (Redshiftスタック用テンプレート) を修正していきます。
修正後のテンプレートは以下で確認できます。
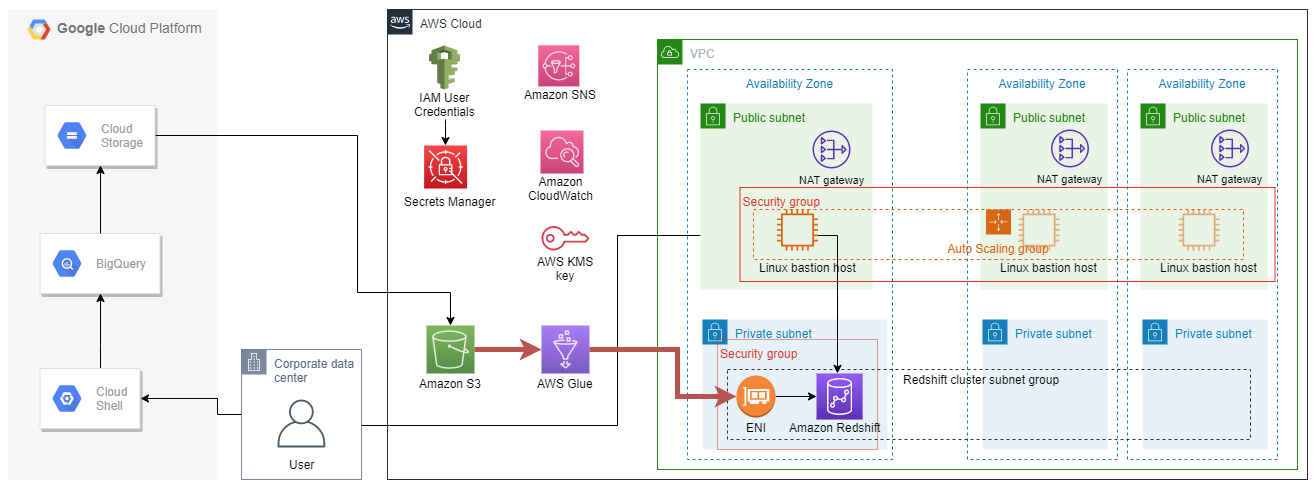
追加したネットワーク設定が用いられる経路を赤色でハイライトしています。
GlueからVPC内のRedshiftにアクセスする際、ネットワークインターフェース(ENI)が必要になります。
AWS ドキュメント:VPC の JDBC データストアに接続する
Redshift・Glueが利用するセキュリティグループに対して、すべてのTCP ポートに対する自己参照のインバウンドルールを追加しています。なお、ENI本体は、GlueからRedshiftへの接続を作成し、ETLジョブを実行する際に作成されます。
テンプレートの修正箇所をハイライトしています。
-
Key: Compliance
Value: !Ref TagCompliance
# ---
RedshiftSecurityGroupIngress:
Type: 'AWS::EC2::SecurityGroupIngress'
Properties:
IpProtocol: "-1"
SourceSecurityGroupId: !Ref RedshiftSecurityGroup
GroupId: !Ref RedshiftSecurityGroup
MyGlueIAMRole:
Type: 'AWS::IAM::Role'
Properties:
RoleName: !Sub "AWSGlueServiceRole-${AWS::StackName}"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "glue.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
Policies:
-
PolicyName: !Sub "${AWS::StackName}-Glue-Read-S3-Policy"
PolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Action:
- s3:GetBucketLocation
- s3:GetObject
- s3:ListMultipartUploadParts
- s3:ListBucket
- s3:ListBucketMultipartUploads
Resource:
- !Join
- ""
- - "arn:aws:s3:::"
- {'Fn::ImportValue': !Sub '${ParentSSHBastionStack}-BigQueryDataS3BucketName'}
- "/*"
# ---
RedshiftLoggingS3Bucket:
テンプレートの修正は以上です。
それでは、各スタックをデプロイしていきます。
1.3 スタックの作成
VPCスタック、Bastionスタック、Redshiftスタックの順で作成します。
まずパラメータをまとめて作成しておきます。
スタック名などは同じで問題ないですが、EMAIL_NOTIFICATION_LIST と KEY_PAIR_NAME (事前にEC2キーペアの作成が必要です)は自身の値に変更してください。
また、MASTER_USER_PASSWORD の値は、Glueの接続設定とRedshiftへアクセスする際に必要になります。自身で設定した値を失念しないよう、気を付けてください。
# 自身の値に置き換えて実行してください EMAIL_NOTIFICATION_LIST="YOUR_EMAIL_ADDRESS" KEY_PAIR_NAME="YOUR_EC2_KEY_PAIR_NAME" # VPCスタック用パラメータ VPC_STACK_NAME=techblog-vpc-stack # Redshiftスタック用パラメータ REDSHIFT_STACK_NAME=techblog-redshift-stack MASTER_USER_PASSWORD="TestPass2019" GLUE_CATALOG_DB_NAME="bq-test-db" # Bastionスタック用パラメータ BASTION_STACK_NAME=techblog-bastion-stack # 踏み台サーバへのSSH接続元を制限するため、自身のIPAddressを取得、CIDR表記で指定 REMOTE_ACCESS_CIDR="$(dig +short myip.opendns.com @resolver1.opendns.com)/32"
VPCスタックを作成します。完了まで数分かかります。
aws cloudformation create-stack \
--stack-name $VPC_STACK_NAME \
--template-body file://aws-vpc-blog.template \
--parameters \
ParameterKey=ClassB,ParameterValue=0 \
--capabilities CAPABILITY_IAM
マネジメントコンソールでCloudFormationを開き、スタック作成の完了を確認してから、Bastionスタックの作成に移ってください。
Bastionスタックを作成します。以下のコマンドを実行します。
aws cloudformation create-stack\
--stack-name $BASTION_STACK_NAME\
--template-body file://linux-bastion-blog.template\
--parameters\
ParameterKey=ParentVPCStack,ParameterValue=$VPC_STACK_NAME\
ParameterKey=NotificationList,ParameterValue=$EMAIL_NOTIFICATION_LIST\
ParameterKey=KeyPairName,ParameterValue=$KEY_PAIR_NAME\
ParameterKey=RemoteAccessCIDR,ParameterValue=$REMOTE_ACCESS_CIDR\
ParameterKey=EnableX11Forwarding,ParameterValue=true\
--capabilities CAPABILITY_IAM CAPABILITY_NAMED_IAM
スタックの作成まで数分かかります。
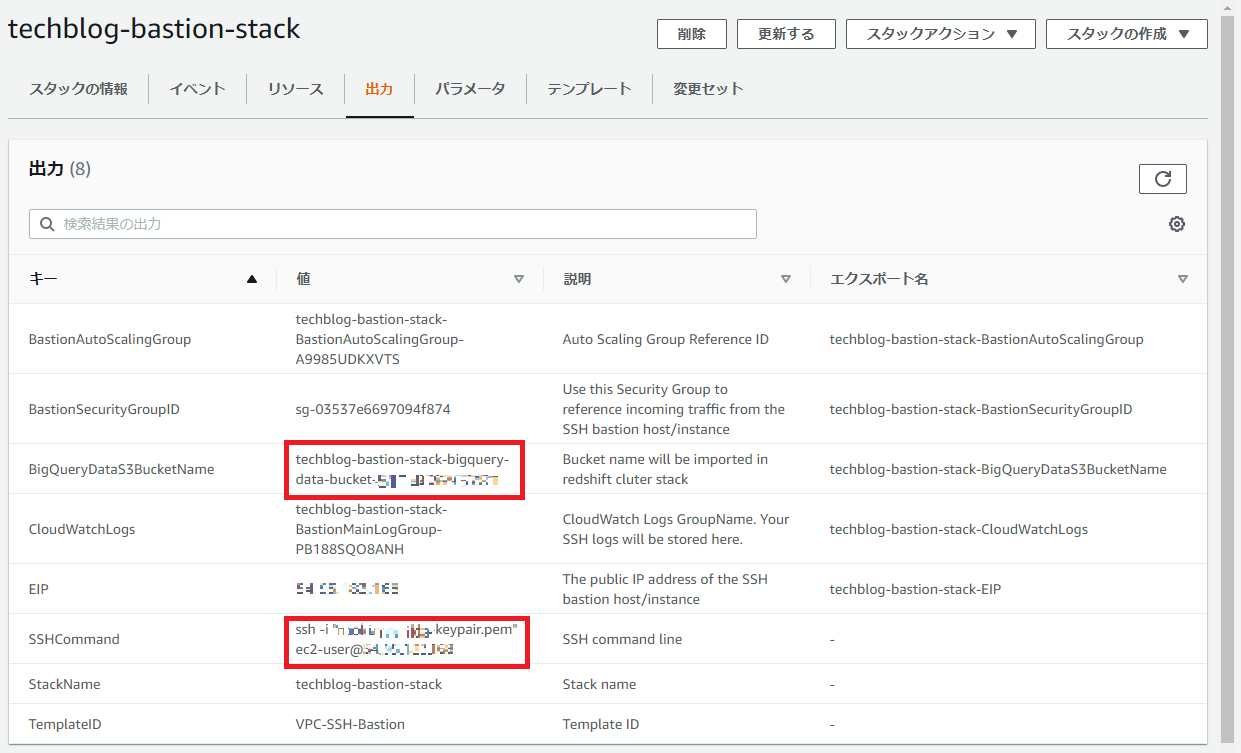
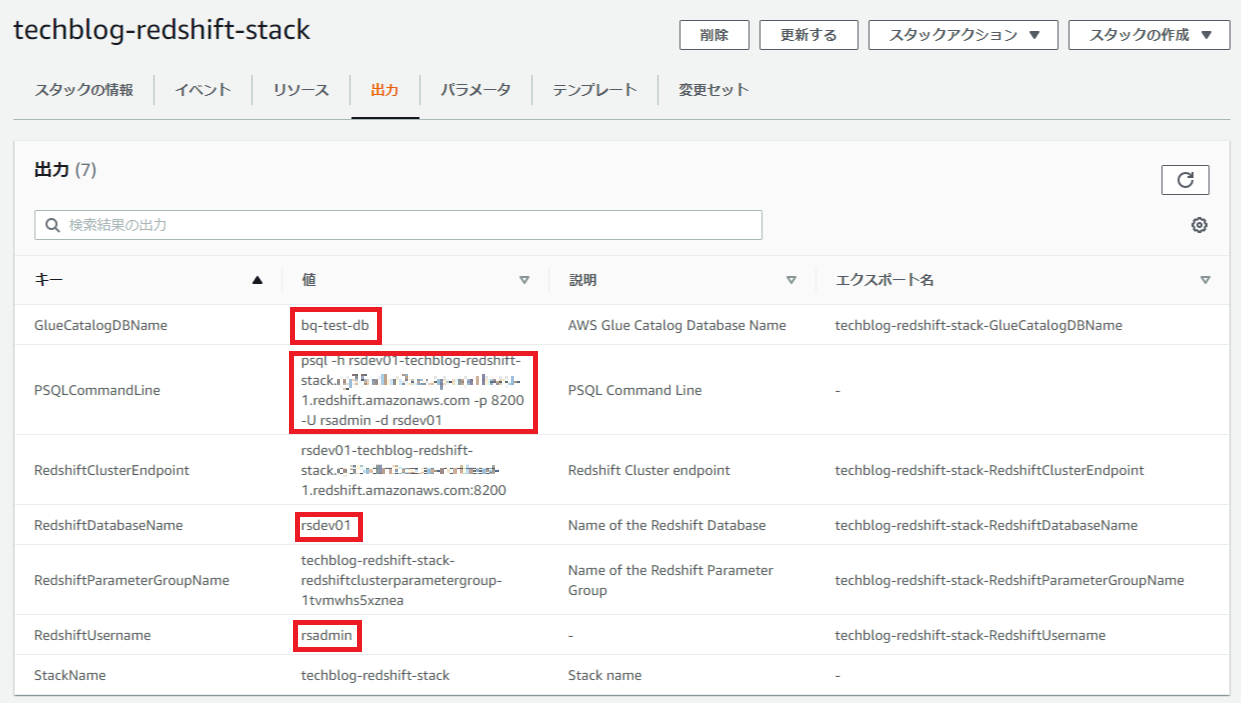
スタックの出力する以下の値は、以降の手順で必要になるため、マネジメントコンソールで確認・取得しておいてください。
最後に、Redshiftスタックを作成します。以下のコマンドを実行します。
aws cloudformation create-stack\
--stack-name $REDSHIFT_STACK_NAME\
--template-body file://redshift-blog.template\
--parameters\
ParameterKey=ParentVPCStack,ParameterValue=$VPC_STACK_NAME\
ParameterKey=ParentSSHBastionStack,ParameterValue=$BASTION_STACK_NAME\
ParameterKey=MasterUserPassword,ParameterValue=$MASTER_USER_PASSWORD\
ParameterKey=NotificationList,ParameterValue=$EMAIL_NOTIFICATION_LIST\
ParameterKey=S3BucketForRedshiftIAMRole,ParameterValue=$S3_BUCKET_NAME\
ParameterKey=GlueCatalogDatabase,ParameterValue=$GLUE_CATALOG_DB_NAME\
ParameterKey=TagOwner,ParameterValue=$EMAIL_NOTIFICATION_LIST\
--capabilities CAPABILITY_IAM CAPABILITY_NAMED_IAM
同様に、スタックの出力する以下の値は、以降の手順で必要になるため、マネジメントコンソールで確認・取得しておいてください。
以上でAWSのリソースが作成できました。作成したリソースを赤色でハイライトしています。Glue関連のリソースは後ほど手順3で作成します。
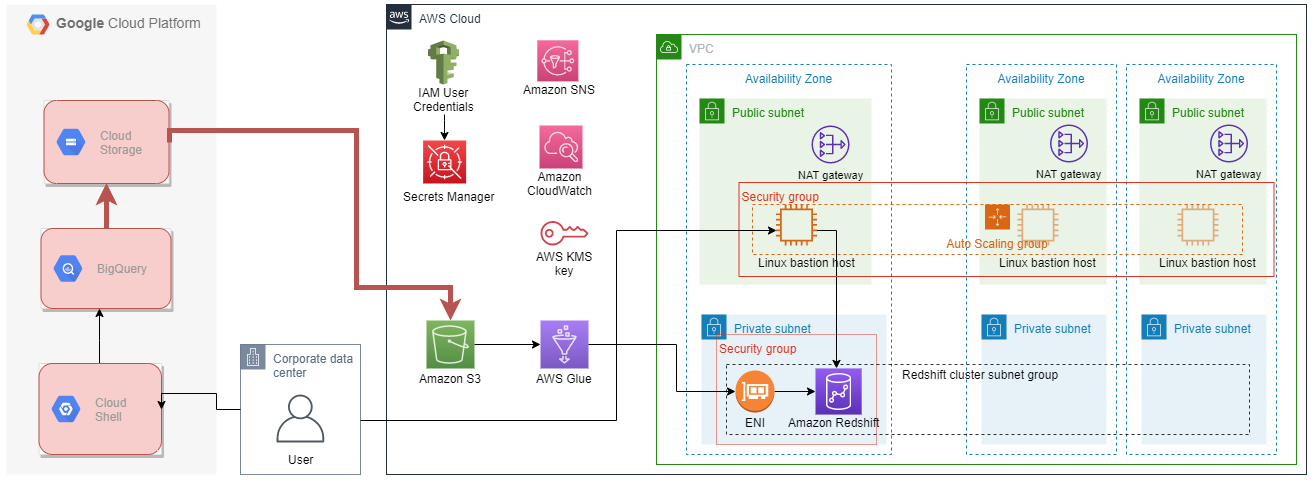
2. BigQueryの一般公開データセットを、GCS経由でS3に出力する
次はGCPに移ってバケットの作成、データの移行を行っていきます。下の構成図において、赤色でハイライトした部分が関連するリソースになります。
2.1 一般公開データセット
BigQueryでは、一般公開データセットと呼ばれる様々なデータがあらかじめ用意されており、
ユーザーは自身のデータと組み合わせて分析を行うことができます。
今回は、BigQueryの一般公開データセットの中から、Google Analytics Sampleのデータを使いたいと思います。
以下のようなクエリが実行できます。後ほど、Redshiftでも同様のクエリを投げてみたいと思います。
SELECT device.browser, SUM ( totals.transactions ) AS total_transactions FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` GROUP BY device.browser ORDER BY total_transactions DESC

2.2 GCSバケットの作成
GCPのコンソールを開き、Cloud Shellを起動します。以下のコマンドはCloud Shellから実行します。
GCSのバケットを作成します。バケット名は適宜変更して実行してください。
GCS_BUCKET_NAME="techblog-bq-to-rs-test-1" gsutil mb -l us-east1 gs://$GCS_BUCKET_NAME/
Creating gs://techblog-bq-to-rs-test-1/…
2.3 BigQueryからGCSにエクスポート
データをBigQueryからGCSに出力します。今回は bq extract コマンドを使用します。
なお、出力データが1GBを超える場合は、ワイルドカード * を使用して、データを分割する必要があることに注意してください。
テーブルデータのエクスポート:エクスポートの制限事項
bq --location=US extract --destination_format AVRO --compression SNAPPY 'bigquery-public-data:google_analytics_sample.ga_sessions_20170801' gs://$GCS_BUCKET_NAME/file*.avro
Waiting on bqjob_r53a25b3547d65fb_0000016f7a31fa56_1 … (2s) Current status: DONE
2.4 GCSからS3にデータをコピー
gsutilツールを利用して、GCSからS3にデータをコピーすることが出来ます。
そのためには、S3にアクセスできるIAMユーザー認証情報を.boto構成ファイル(~/.boto)に追加する必要があります。詳細については、以下のドキュメントをご覧ください。
Cloud Storage の相互運用性
gsutil config: Additional Configuration-Controllable Features
AWSマネジメントコンソールでSecret Managersを開き、先ほどBastionスタック内で作成したIAMユーザー認証情報を取得します。

Cloud Shellに戻って、お好きなエディターで.boto構成ファイル(~/.boto)を開き、IAMユーザーの認証情報を書き込みます。
なお、S3バケットは東京リージョン(ap-northeast-1)での作成を想定し、s3_host の値を設定しています。他のリージョンにおけるエンドポイントの値については、以下をご確認ください。
Amazon Simple Storage Service エンドポイントとクォータ
[Credentials] aws_access_key_id = XXXXXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXX s3_host = s3.ap-northeast-1.amazonaws.com
gsutilを使って、GCSからS3にファイルをコピーします。
変数 S3_BUCKET_NAME には、Bastionスタック作成時 BigQueryDataS3BucketName として出力されていたバケット名を入力してください。AWSマネジメントコンソール > CloudFormation > スタック > 自身のBastionスタック名 > 出力 のタブで確認できます。
S3_BUCKET_NAME="REPLACE_VALUE_WITH_YOUR_S3_BUCKET_NAME" gsutil cp gs://$GCS_BUCKET_NAME/*.avro s3://$S3_BUCKET_NAME/
Copying gs://techblog-bq-to-rs-test-1/file000000000000.avro [Content-Type=application/octet-stream]…
– [1 files][ 2.8 MiB/ 2.8 MiB]
Operation completed over 1 objects/2.8 MiB.
以上で、BigQueryのデータをS3に出力できました。
次は再びAWSのマネジメントコンソールに戻って、Glueの設定を行っていきます。
3. S3のデータにGlueでETLを行い、Redshiftにデータを格納する
AWS Glueは、データの抽出、変換、ロードという、ETL処理をスムーズに行うためのマネージドサービスです。
今回、Glueを使って、S3のデータからデータカタログを構築、Redshiftへの接続を設定、ETLジョブを作成、実行し、S3のデータを変換してRedshiftにロードしてみたいと思います。
以下の構成図において、関連するリソースを赤色でハイライトしています。
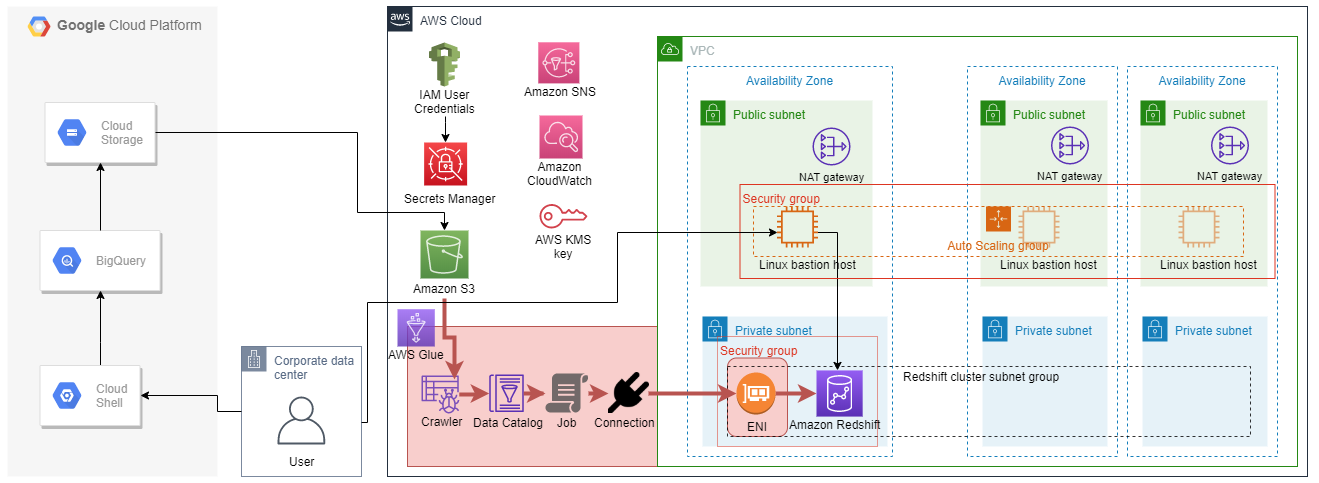
3.1 データカタログの構築
S3にコピーされたBigQuery一般公開データセットをGlueクローラでクロールし、データカタログを構築します。
AWSのマネジメントコンソールから AWS Glue > クローラ を開きます。
以下の画像の手順で、クローラの設定を行っていきます。

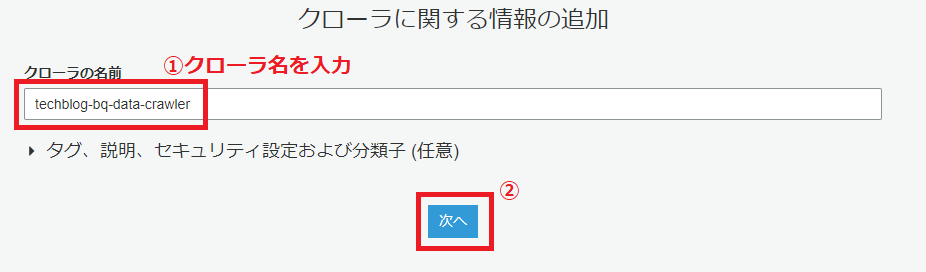
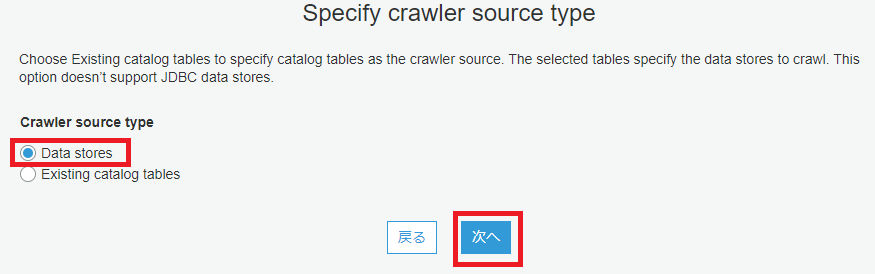
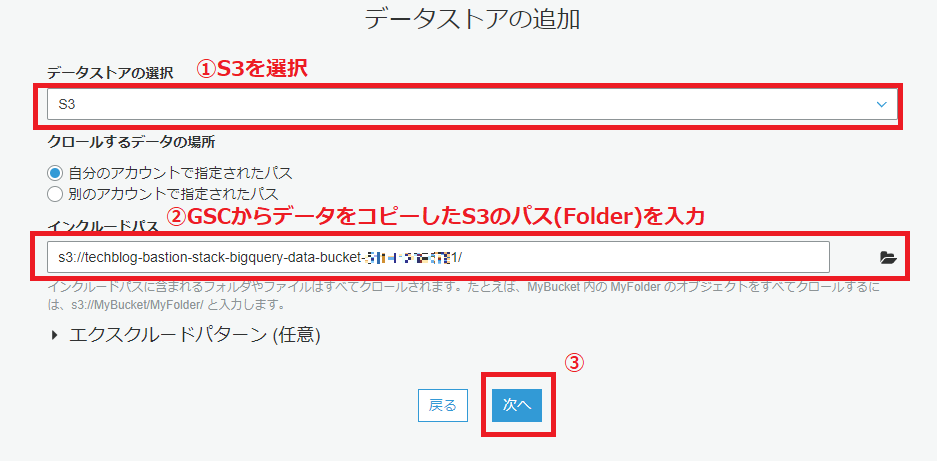
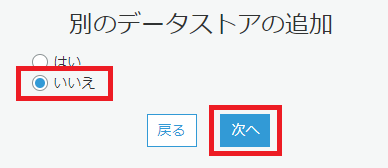
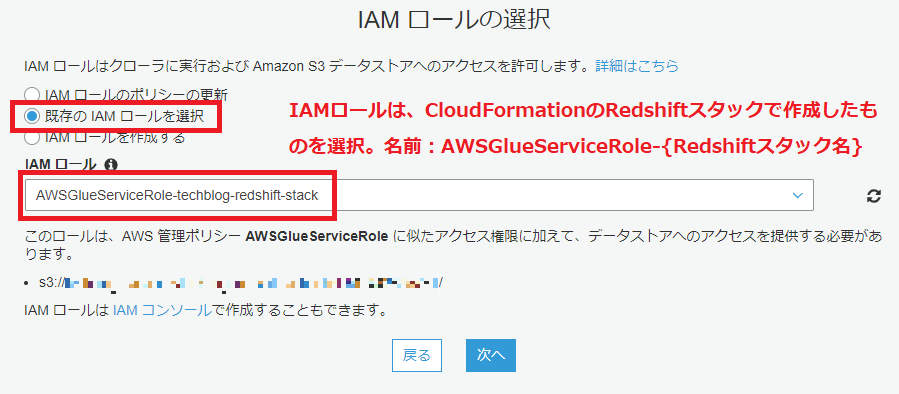
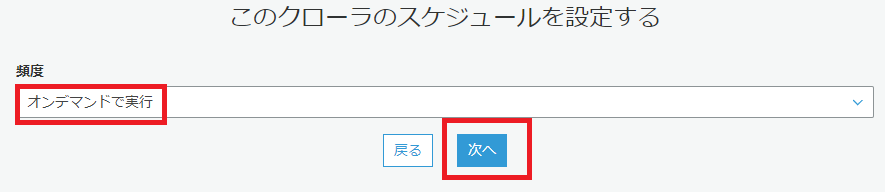
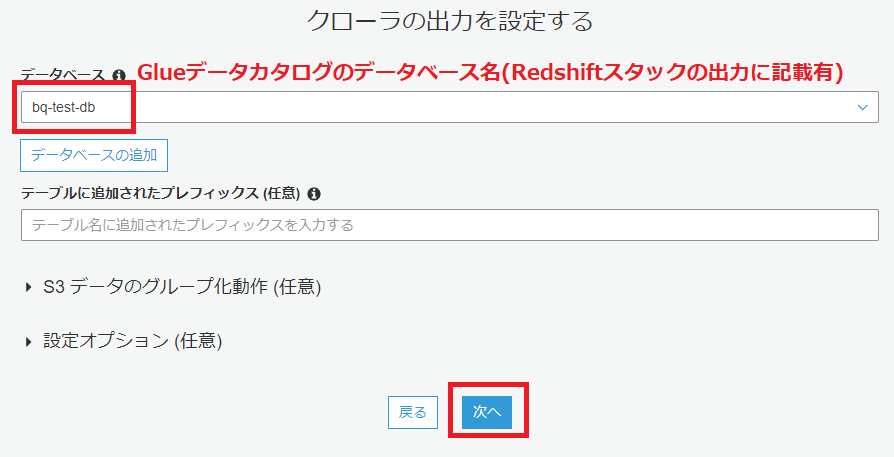
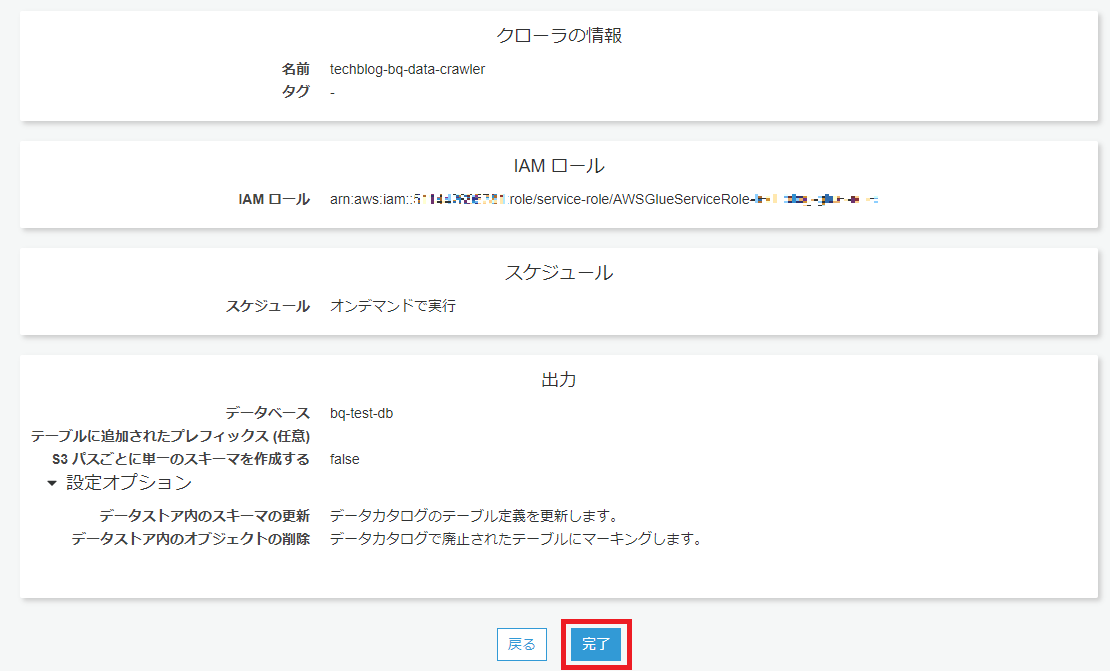
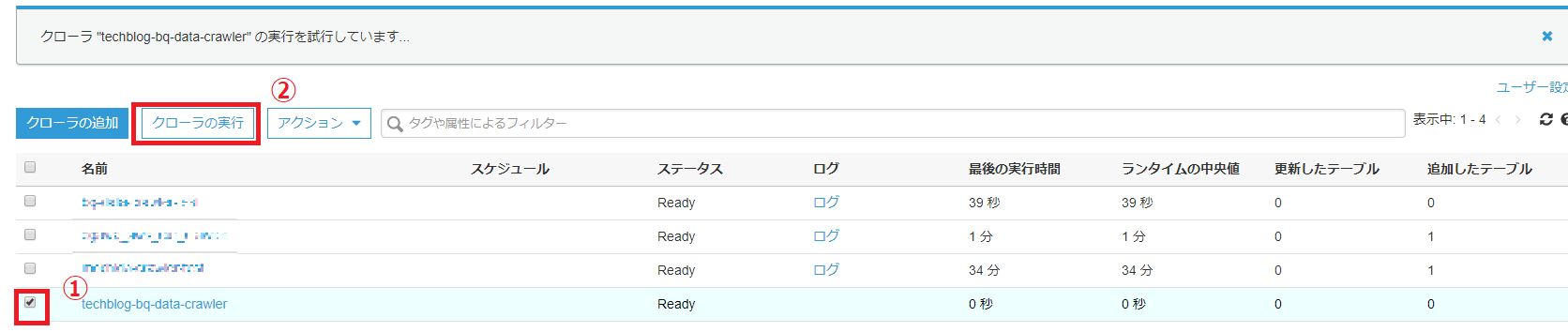
クローラの実行は1分ほどで完了します。
構築されたデータカタログはテーブルとして確認できます。
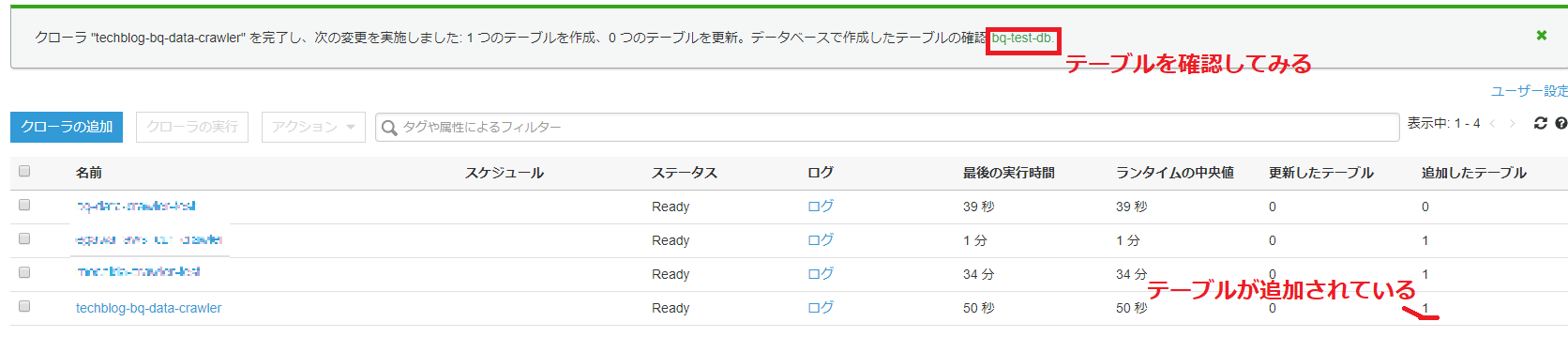
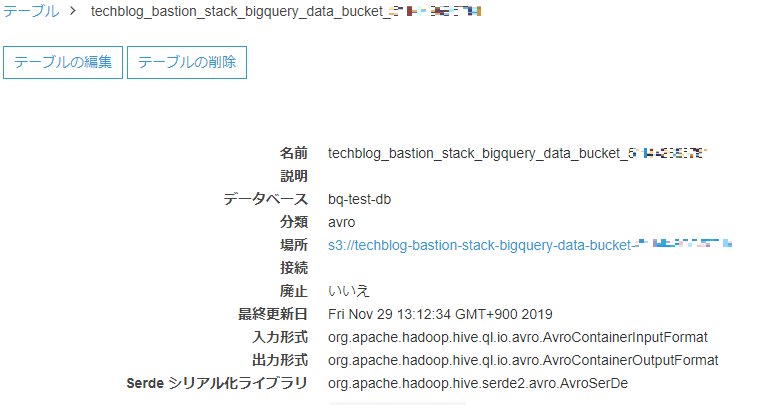
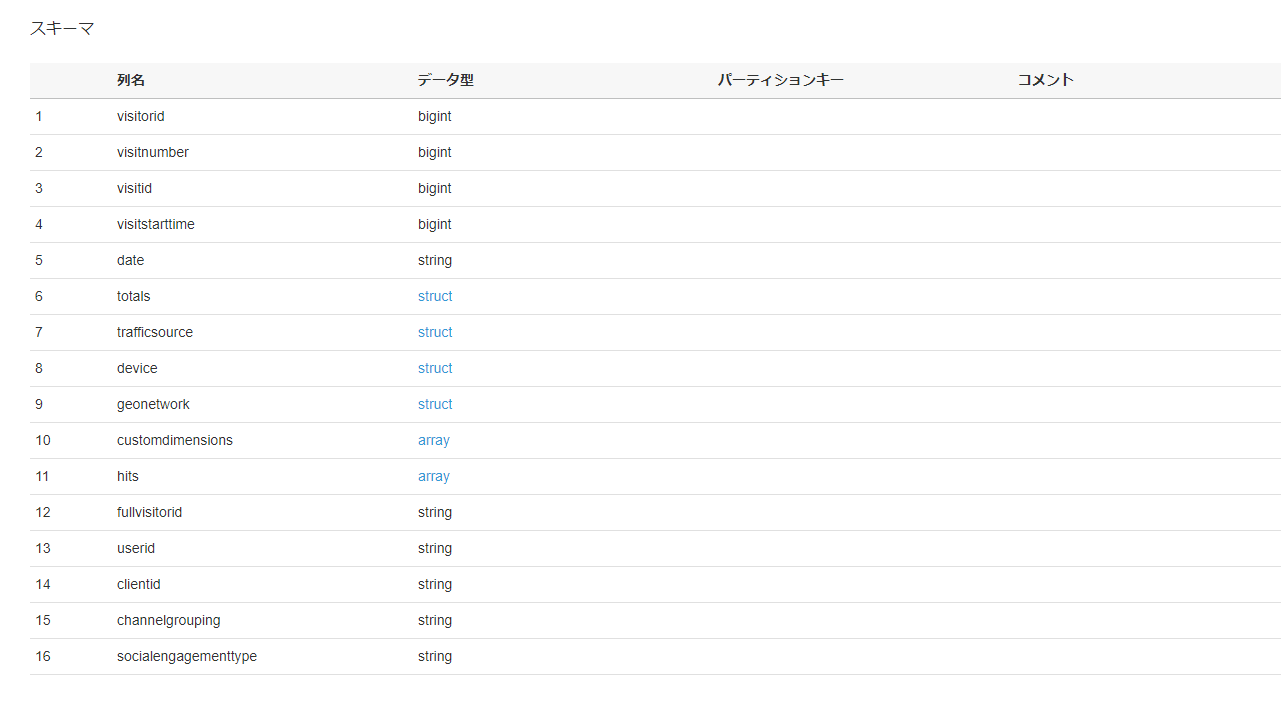
3.2 Connectionの設定
次に、GlueからRedshiftへの接続(Connection)を設定します。

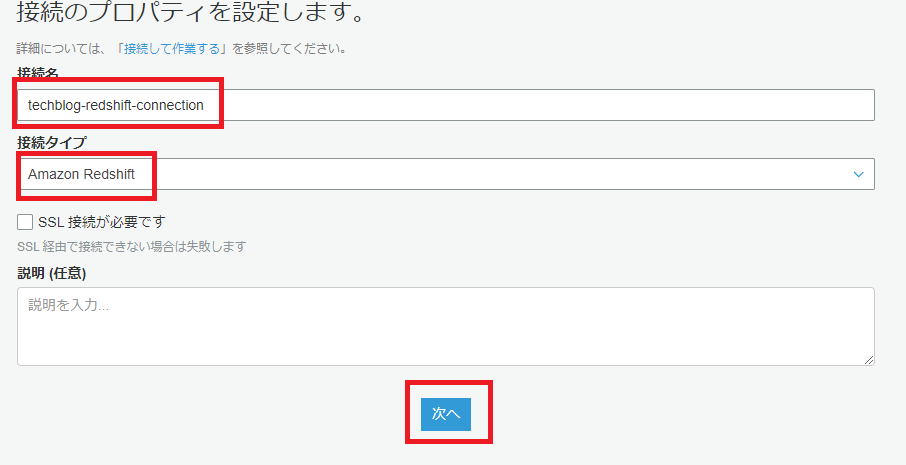
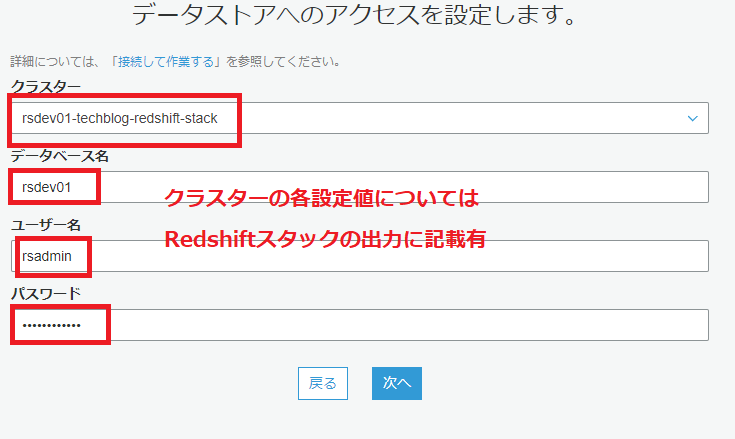
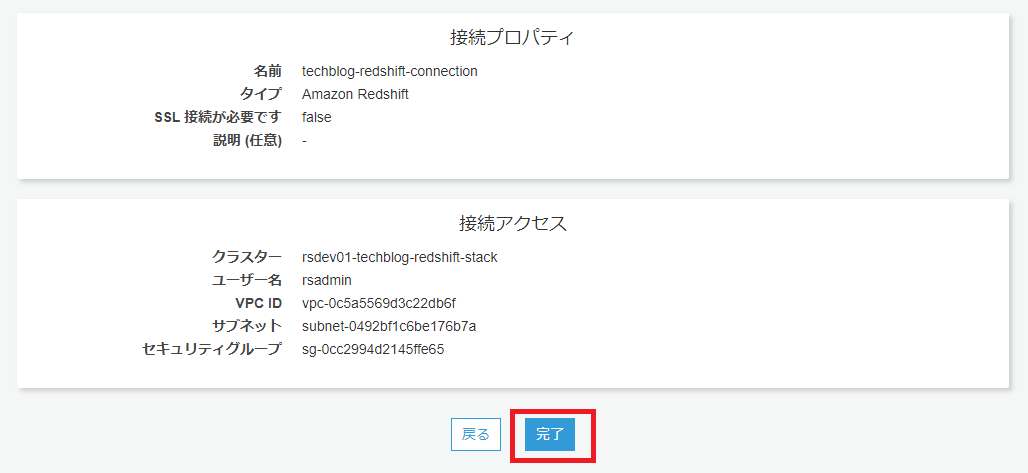
接続の設定が上手くいっているか、テストしてみます。
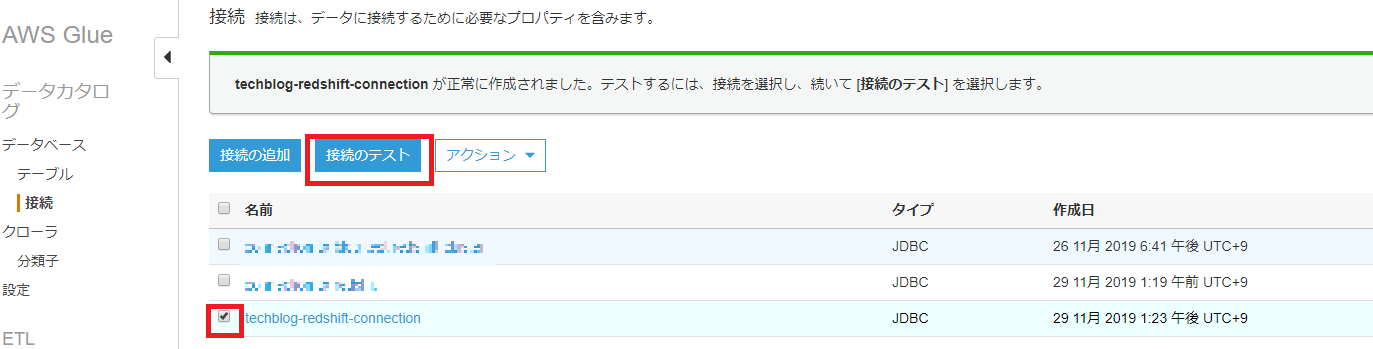
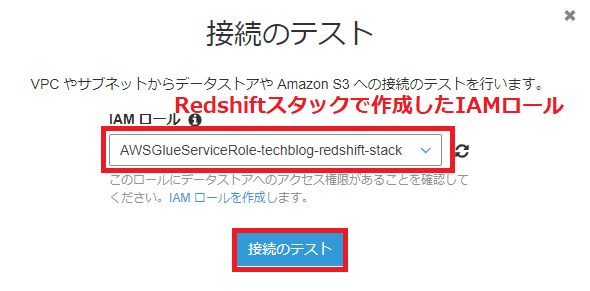

無事に接続の設定が完了しました。
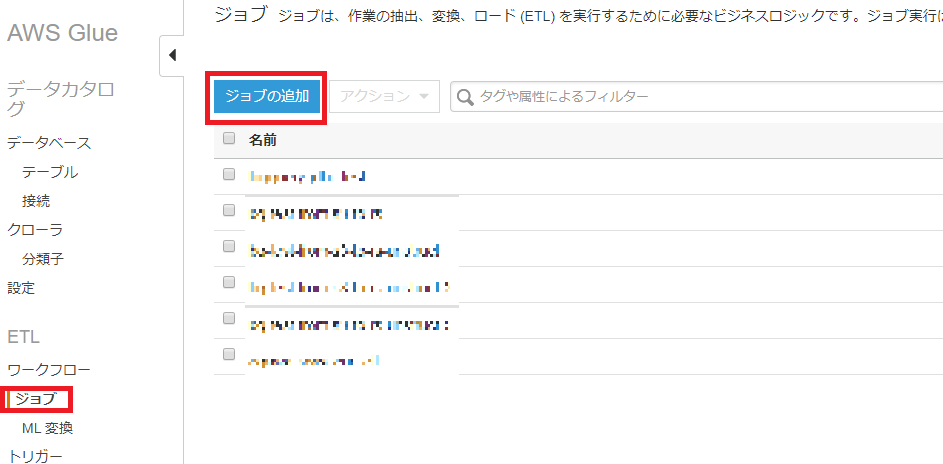
3.3 ETLジョブの作成
最後にGlueジョブを作成し、S3からRedshiftへデータのETLを行います。
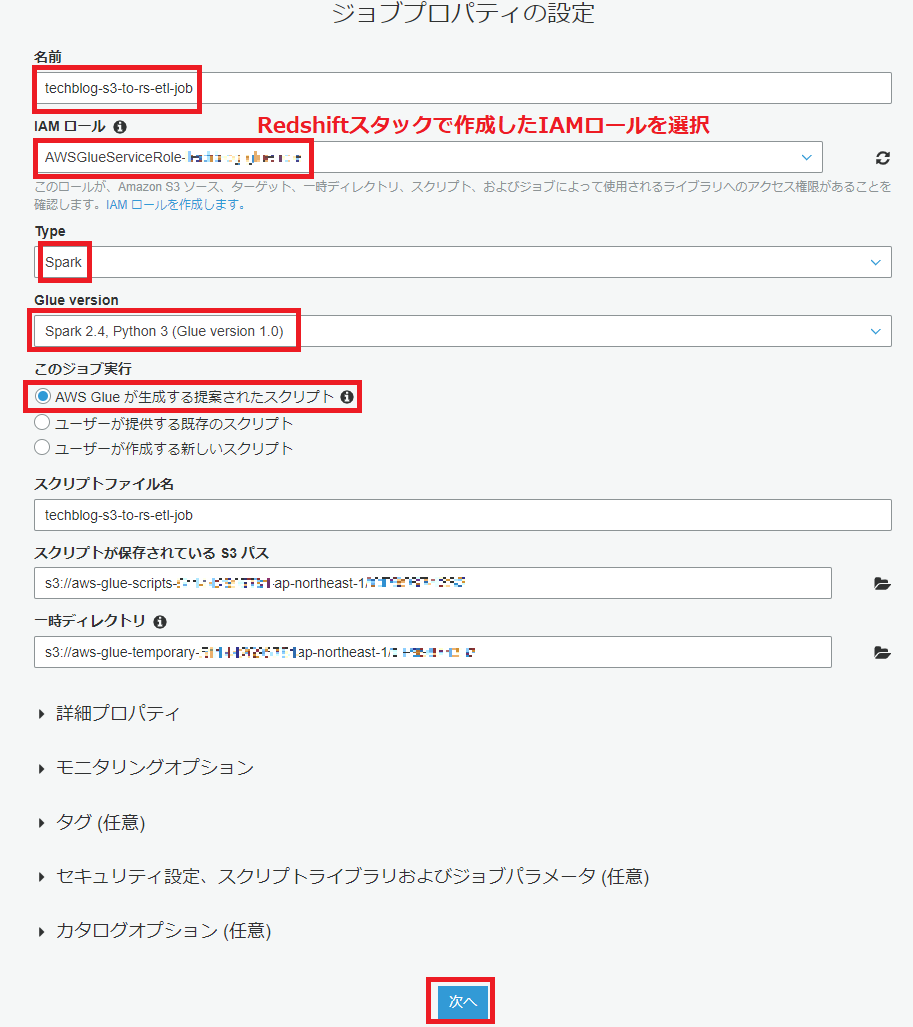
データソースの選択では、先ほどGlueクローラを使って構築したデータカタログのテーブルを選択します。
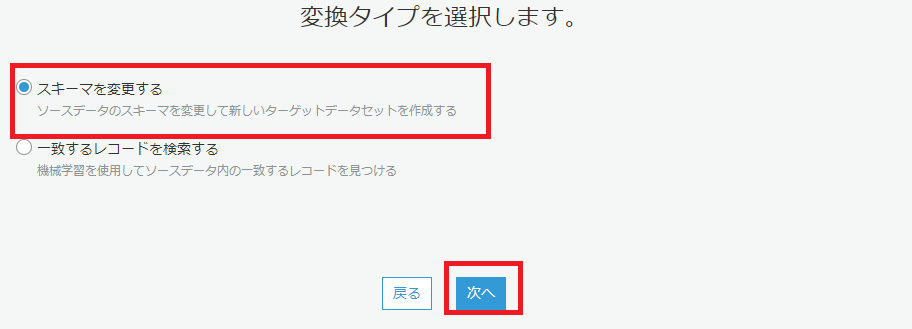

なお、RedshiftはArray・Structのデータ型に対応していないため、ETLで型を変換してからRedshiftに読み込む必要があります。
AWSドキュメント:Amazon Redshift:サポートされていない PostgreSQL データ型
下の画像の通り、デフォルトでArrayはstring型へ変換されているようです。
Arrayの中身を展開し、適切なデータ型を付与して格納したい場合、自身で変換を追加する必要があります。
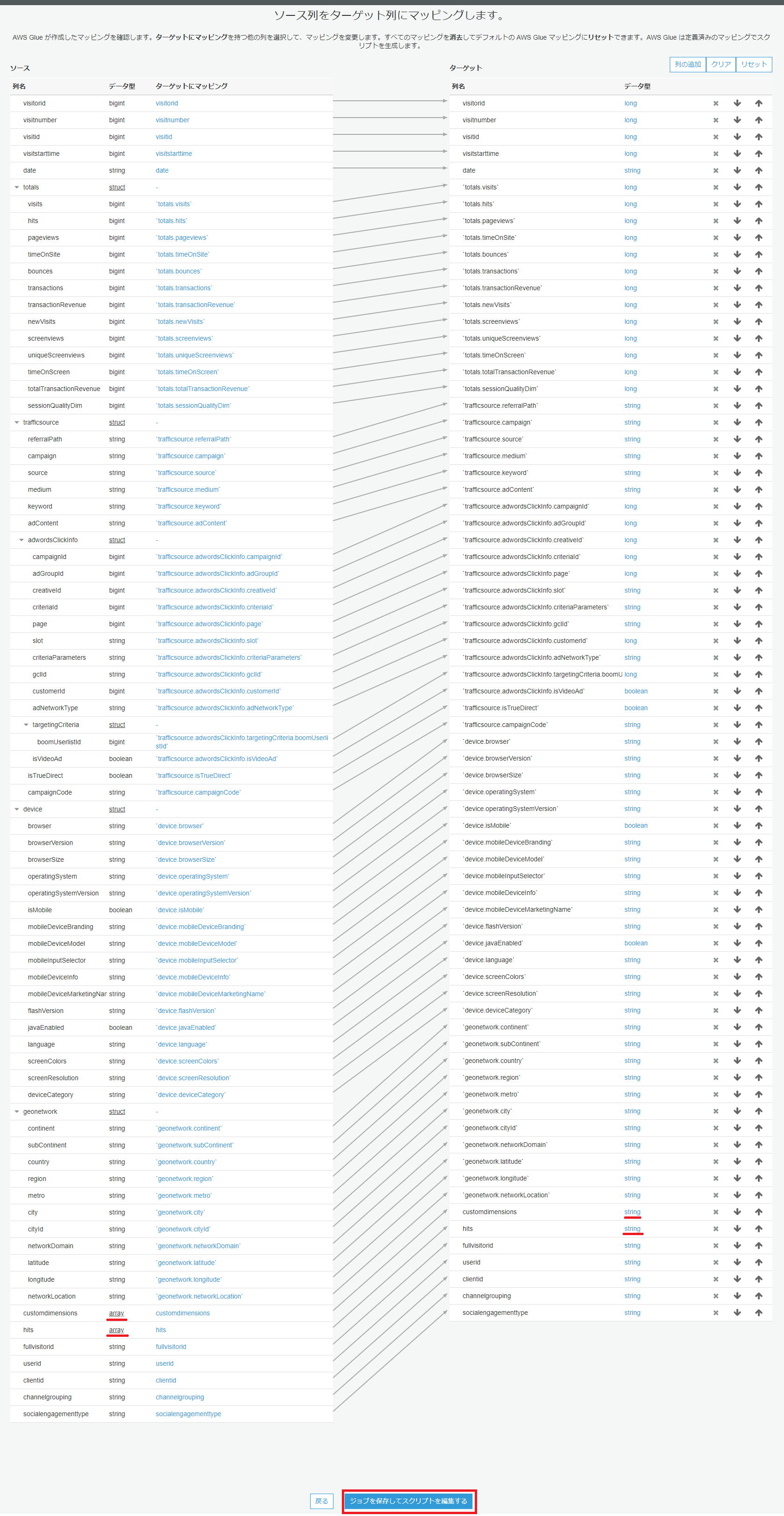
今回、hits の列は除外し、customdimmensions のArrayの中身を展開し、long型の customdimensions.index とstring型のcustomdimensions.value としてRedshiftに格納してみたいと思います。
コード例は以下のようになります。GlueのDynamicFrameからSparkのDataFrameに一旦変換し、Sparkのexplode関数でArrayの中身を展開した後、GlueのDynamicFrameに戻しています。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [TempDir, JOB_NAME]
args = getResolvedOptions(sys.argv, ['TempDir','JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "bq-test-db", table_name = "techblog_bastion_stack_bigquery_data_bucket_xxx", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "bq-test-db", table_name = "techblog_bastion_stack_bigquery_data_bucket_xxx", transformation_ctx = "datasource0")
## @type: ExplodeArray
## @args: []
## @return: explodedframe0
## @inputs: [frame = datasource0]
import pyspark.sql.functions as F
from awsglue.dynamicframe import DynamicFrame
df = datasource0.toDF()
df = df.withColumn("exploded_customdimensions", F.explode("customdimensions"))
df = df.drop("customdimensions")
df = df.withColumn("customdimensions.index", df.exploded_customdimensions.index)
df = df.withColumn("customdimensions.value", df.exploded_customdimensions.value)
explodedframe0 = DynamicFrame.fromDF(df, glueContext, "exploded")
## @type: ApplyMapping
## @args: [mappings = [("visitorid", "long", "visitorid", "long"), ("visitnumber", "long", "visitnumber", "long"), ("visitid", "long", "visitid", "long"), ("visitstarttime", "long", "visitstarttime", "long"), ("date", "string", "date", "string"), ("totals.visits", "long", "`totals.visits`", "long"), ("totals.hits", "long", "`totals.hits`", "long"), ("totals.pageviews", "long", "`totals.pageviews`", "long"), ("totals.timeOnSite", "long", "`totals.timeOnSite`", "long"), ("totals.bounces", "long", "`totals.bounces`", "long"), ("totals.transactions", "long", "`totals.transactions`", "long"), ("totals.transactionRevenue", "long", "`totals.transactionRevenue`", "long"), ("totals.newVisits", "long", "`totals.newVisits`", "long"), ("totals.screenviews", "long", "`totals.screenviews`", "long"), ("totals.uniqueScreenviews", "long", "`totals.uniqueScreenviews`", "long"), ("totals.timeOnScreen", "long", "`totals.timeOnScreen`", "long"), ("totals.totalTransactionRevenue", "long", "`totals.totalTransactionRevenue`", "long"), ("totals.sessionQualityDim", "long", "`totals.sessionQualityDim`", "long"), ("trafficsource.referralPath", "string", "`trafficsource.referralPath`", "string"), ("trafficsource.campaign", "string", "`trafficsource.campaign`", "string"), ("trafficsource.source", "string", "`trafficsource.source`", "string"), ("trafficsource.medium", "string", "`trafficsource.medium`", "string"), ("trafficsource.keyword", "string", "`trafficsource.keyword`", "string"), ("trafficsource.adContent", "string", "`trafficsource.adContent`", "string"), ("trafficsource.adwordsClickInfo.campaignId", "long", "`trafficsource.adwordsClickInfo.campaignId`", "long"), ("trafficsource.adwordsClickInfo.adGroupId", "long", "`trafficsource.adwordsClickInfo.adGroupId`", "long"), ("trafficsource.adwordsClickInfo.creativeId", "long", "`trafficsource.adwordsClickInfo.creativeId`", "long"), ("trafficsource.adwordsClickInfo.criteriaId", "long", "`trafficsource.adwordsClickInfo.criteriaId`", "long"), ("trafficsource.adwordsClickInfo.page", "long", "`trafficsource.adwordsClickInfo.page`", "long"), ("trafficsource.adwordsClickInfo.slot", "string", "`trafficsource.adwordsClickInfo.slot`", "string"), ("trafficsource.adwordsClickInfo.criteriaParameters", "string", "`trafficsource.adwordsClickInfo.criteriaParameters`", "string"), ("trafficsource.adwordsClickInfo.gclId", "string", "`trafficsource.adwordsClickInfo.gclId`", "string"), ("trafficsource.adwordsClickInfo.customerId", "long", "`trafficsource.adwordsClickInfo.customerId`", "long"), ("trafficsource.adwordsClickInfo.adNetworkType", "string", "`trafficsource.adwordsClickInfo.adNetworkType`", "string"), ("trafficsource.adwordsClickInfo.targetingCriteria.boomUserlistId", "long", "`trafficsource.adwordsClickInfo.targetingCriteria.boomUserlistId`", "long"), ("trafficsource.adwordsClickInfo.isVideoAd", "boolean", "`trafficsource.adwordsClickInfo.isVideoAd`", "boolean"), ("trafficsource.isTrueDirect", "boolean", "`trafficsource.isTrueDirect`", "boolean"), ("trafficsource.campaignCode", "string", "`trafficsource.campaignCode`", "string"), ("device.browser", "string", "`device.browser`", "string"), ("device.browserVersion", "string", "`device.browserVersion`", "string"), ("device.browserSize", "string", "`device.browserSize`", "string"), ("device.operatingSystem", "string", "`device.operatingSystem`", "string"), ("device.operatingSystemVersion", "string", "`device.operatingSystemVersion`", "string"), ("device.isMobile", "boolean", "`device.isMobile`", "boolean"), ("device.mobileDeviceBranding", "string", "`device.mobileDeviceBranding`", "string"), ("device.mobileDeviceModel", "string", "`device.mobileDeviceModel`", "string"), ("device.mobileInputSelector", "string", "`device.mobileInputSelector`", "string"), ("device.mobileDeviceInfo", "string", "`device.mobileDeviceInfo`", "string"), ("device.mobileDeviceMarketingName", "string", "`device.mobileDeviceMarketingName`", "string"), ("device.flashVersion", "string", "`device.flashVersion`", "string"), ("device.javaEnabled", "boolean", "`device.javaEnabled`", "boolean"), ("device.language", "string", "`device.language`", "string"), ("device.screenColors", "string", "`device.screenColors`", "string"), ("device.screenResolution", "string", "`device.screenResolution`", "string"), ("device.deviceCategory", "string", "`device.deviceCategory`", "string"), ("geonetwork.continent", "string", "`geonetwork.continent`", "string"), ("geonetwork.subContinent", "string", "`geonetwork.subContinent`", "string"), ("geonetwork.country", "string", "`geonetwork.country`", "string"), ("geonetwork.region", "string", "`geonetwork.region`", "string"), ("geonetwork.metro", "string", "`geonetwork.metro`", "string"), ("geonetwork.city", "string", "`geonetwork.city`", "string"), ("geonetwork.cityId", "string", "`geonetwork.cityId`", "string"), ("geonetwork.networkDomain", "string", "`geonetwork.networkDomain`", "string"), ("geonetwork.latitude", "string", "`geonetwork.latitude`", "string"), ("geonetwork.longitude", "string", "`geonetwork.longitude`", "string"), ("geonetwork.networkLocation", "string", "`geonetwork.networkLocation`", "string"), ("fullvisitorid", "string", "fullvisitorid", "string"), ("userid", "string", "userid", "string"), ("clientid", "string", "clientid", "string"), ("channelgrouping", "string", "channelgrouping", "string"), ("socialengagementtype", "string", "socialengagementtype", "string"), ("customdimensions.index", "long", "`customdimensions.index`", "long"), ("customdimensions.value", "string", "`customdimensions.value`", "string")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = explodedframe0]
applymapping1 = ApplyMapping.apply(frame = explodedframe0, mappings = [("visitorid", "long", "visitorid", "long"), ("visitnumber", "long", "visitnumber", "long"), ("visitid", "long", "visitid", "long"), ("visitstarttime", "long", "visitstarttime", "long"), ("date", "string", "date", "string"), ("totals.visits", "long", "`totals.visits`", "long"), ("totals.hits", "long", "`totals.hits`", "long"), ("totals.pageviews", "long", "`totals.pageviews`", "long"), ("totals.timeOnSite", "long", "`totals.timeOnSite`", "long"), ("totals.bounces", "long", "`totals.bounces`", "long"), ("totals.transactions", "long", "`totals.transactions`", "long"), ("totals.transactionRevenue", "long", "`totals.transactionRevenue`", "long"), ("totals.newVisits", "long", "`totals.newVisits`", "long"), ("totals.screenviews", "long", "`totals.screenviews`", "long"), ("totals.uniqueScreenviews", "long", "`totals.uniqueScreenviews`", "long"), ("totals.timeOnScreen", "long", "`totals.timeOnScreen`", "long"), ("totals.totalTransactionRevenue", "long", "`totals.totalTransactionRevenue`", "long"), ("totals.sessionQualityDim", "long", "`totals.sessionQualityDim`", "long"), ("trafficsource.referralPath", "string", "`trafficsource.referralPath`", "string"), ("trafficsource.campaign", "string", "`trafficsource.campaign`", "string"), ("trafficsource.source", "string", "`trafficsource.source`", "string"), ("trafficsource.medium", "string", "`trafficsource.medium`", "string"), ("trafficsource.keyword", "string", "`trafficsource.keyword`", "string"), ("trafficsource.adContent", "string", "`trafficsource.adContent`", "string"), ("trafficsource.adwordsClickInfo.campaignId", "long", "`trafficsource.adwordsClickInfo.campaignId`", "long"), ("trafficsource.adwordsClickInfo.adGroupId", "long", "`trafficsource.adwordsClickInfo.adGroupId`", "long"), ("trafficsource.adwordsClickInfo.creativeId", "long", "`trafficsource.adwordsClickInfo.creativeId`", "long"), ("trafficsource.adwordsClickInfo.criteriaId", "long", "`trafficsource.adwordsClickInfo.criteriaId`", "long"), ("trafficsource.adwordsClickInfo.page", "long", "`trafficsource.adwordsClickInfo.page`", "long"), ("trafficsource.adwordsClickInfo.slot", "string", "`trafficsource.adwordsClickInfo.slot`", "string"), ("trafficsource.adwordsClickInfo.criteriaParameters", "string", "`trafficsource.adwordsClickInfo.criteriaParameters`", "string"), ("trafficsource.adwordsClickInfo.gclId", "string", "`trafficsource.adwordsClickInfo.gclId`", "string"), ("trafficsource.adwordsClickInfo.customerId", "long", "`trafficsource.adwordsClickInfo.customerId`", "long"), ("trafficsource.adwordsClickInfo.adNetworkType", "string", "`trafficsource.adwordsClickInfo.adNetworkType`", "string"), ("trafficsource.adwordsClickInfo.targetingCriteria.boomUserlistId", "long", "`trafficsource.adwordsClickInfo.targetingCriteria.boomUserlistId`", "long"), ("trafficsource.adwordsClickInfo.isVideoAd", "boolean", "`trafficsource.adwordsClickInfo.isVideoAd`", "boolean"), ("trafficsource.isTrueDirect", "boolean", "`trafficsource.isTrueDirect`", "boolean"), ("trafficsource.campaignCode", "string", "`trafficsource.campaignCode`", "string"), ("device.browser", "string", "`device.browser`", "string"), ("device.browserVersion", "string", "`device.browserVersion`", "string"), ("device.browserSize", "string", "`device.browserSize`", "string"), ("device.operatingSystem", "string", "`device.operatingSystem`", "string"), ("device.operatingSystemVersion", "string", "`device.operatingSystemVersion`", "string"), ("device.isMobile", "boolean", "`device.isMobile`", "boolean"), ("device.mobileDeviceBranding", "string", "`device.mobileDeviceBranding`", "string"), ("device.mobileDeviceModel", "string", "`device.mobileDeviceModel`", "string"), ("device.mobileInputSelector", "string", "`device.mobileInputSelector`", "string"), ("device.mobileDeviceInfo", "string", "`device.mobileDeviceInfo`", "string"), ("device.mobileDeviceMarketingName", "string", "`device.mobileDeviceMarketingName`", "string"), ("device.flashVersion", "string", "`device.flashVersion`", "string"), ("device.javaEnabled", "boolean", "`device.javaEnabled`", "boolean"), ("device.language", "string", "`device.language`", "string"), ("device.screenColors", "string", "`device.screenColors`", "string"), ("device.screenResolution", "string", "`device.screenResolution`", "string"), ("device.deviceCategory", "string", "`device.deviceCategory`", "string"), ("geonetwork.continent", "string", "`geonetwork.continent`", "string"), ("geonetwork.subContinent", "string", "`geonetwork.subContinent`", "string"), ("geonetwork.country", "string", "`geonetwork.country`", "string"), ("geonetwork.region", "string", "`geonetwork.region`", "string"), ("geonetwork.metro", "string", "`geonetwork.metro`", "string"), ("geonetwork.city", "string", "`geonetwork.city`", "string"), ("geonetwork.cityId", "string", "`geonetwork.cityId`", "string"), ("geonetwork.networkDomain", "string", "`geonetwork.networkDomain`", "string"), ("geonetwork.latitude", "string", "`geonetwork.latitude`", "string"), ("geonetwork.longitude", "string", "`geonetwork.longitude`", "string"), ("geonetwork.networkLocation", "string", "`geonetwork.networkLocation`", "string"), ("fullvisitorid", "string", "fullvisitorid", "string"), ("userid", "string", "userid", "string"), ("clientid", "string", "clientid", "string"), ("channelgrouping", "string", "channelgrouping", "string"), ("socialengagementtype", "string", "socialengagementtype", "string"),("customdimensions.index", "long", "`customdimensions.index`", "long"), ("customdimensions.value", "string", "`customdimensions.value`", "string")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_cols", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_cols", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [catalog_connection = "techblog-redshift-connection", connection_options = {"dbtable": "techblog_bastion_stack_bigquery_data_bucket_xxx", "database": "rsdev01"}, redshift_tmp_dir = TempDir, transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "techblog-redshift-connection", connection_options = {"dbtable": "techblog_bastion_stack_bigquery_data_bucket_xxx", "database": "rsdev01"}, redshift_tmp_dir = args["TempDir"], transformation_ctx = "datasink4")
job.commit()
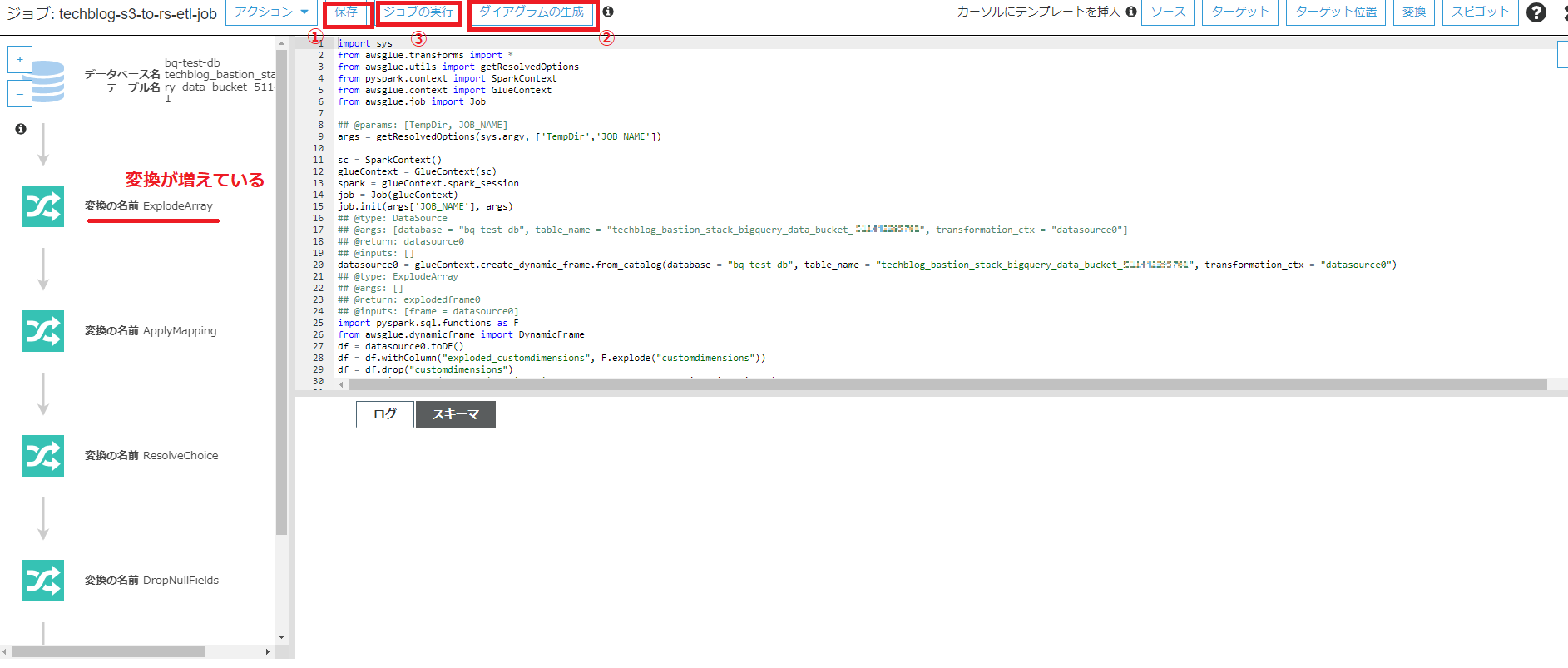
修正箇所をハイライトしています。修正箇所以外の部分には、テータカタログのテーブル名、GlueのConnection名、RedshiftのDB名など、環境ごとに異なる値が含まれているため、修正箇所以外も含めてコピペするとエラーになる恐れがあります。
ハイライトされた行の内容が同じになるよう修正後、 保存 -> ダイヤグラムの生成 を実行すると、画面左側のタブで ExplodeArray の変換ステップが追加されます。
ジョブの実行 より、ETLジョブを実行します。
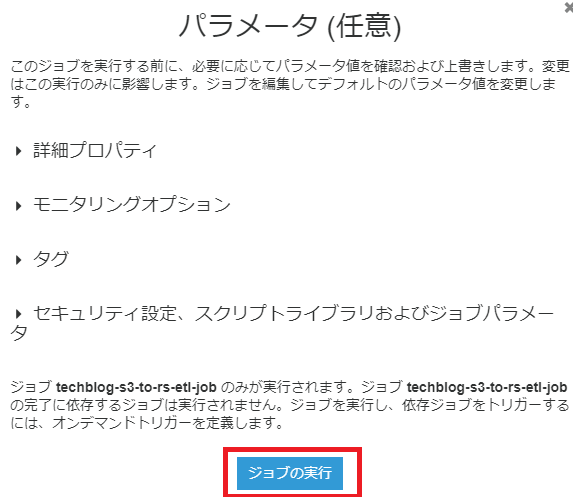

ジョブ実行から数分ほどで実行ステータスがSucceededに変わり、ジョブが完了し、データがRedshiftに読み込まれます。
4. Redshiftに接続してクエリを投げてみる

Redshiftに接続し、クエリを投げてみたいと思います。
Bastionサーバにssh接続するコマンド、Redshiftの接続コマンド/DB名/ユーザー名は、それぞれBastionスタック・Redshiftスタックの出力で確認できます。
Bastionサーバにssh接続します。
ssh -i "your-keypair-name.pem" ec2-user@xxx.xxx.xxx.xxx
Redshiftに接続します。パスワードはスタック作成時に自身で設定したもの(MASTER_USER_PASSWORD 変数で指定した値)になります。
psql -h rsdev01-redshiftmain.cg35ndlm2xxz.ap-northeast-1.redshift.amazonaws.com -p 8200 -U rsadmin -d rsdev01
Redshiftにテーブルが作成されていることを確認します。
rsdev01-techblog-redshift-stack.cg35ndlm2xxz.ap-northeast-1.redshift.amazonaws.com:8200 rsadmin@rsdev01=# \d
List of relations
schema | name | type | owner
--------+----------------------------------------------------------+-------+---------
public | techblog_bastion_stack_bigquery_data_bucket_xxxx| table | rsadmin
(1 row)
rsdev01-techblog-redshift-stack.cg35ndlm2xxz.ap-northeast-1.redshift.amazonaws.com:8200 rsadmin@rsdev01=# \d techblog_bastion_stack_bigquery_data_bucket_xxx
Table "public.techblog_bastion_stack_bigquery_data_bucket_xx"
Column | Type | Modifiers
-----------------------------------------------------------------+--------------------------+-----------
visitorid | bigint |
visitnumber | bigint |
visitid | bigint |
visitstarttime | bigint |
date | character varying(65535) |
totals.visits | bigint |
totals.hits | bigint |
totals.pageviews | bigint |
totals.timeonsite | bigint |
totals.bounces | bigint |
totals.transactions | bigint |
totals.transactionrevenue | bigint |
totals.newvisits | bigint |
totals.screenviews | bigint |
totals.uniquescreenviews | bigint |
totals.timeonscreen | bigint |
totals.totaltransactionrevenue | bigint |
totals.sessionqualitydim | bigint |
trafficsource.referralpath | character varying(65535) |
trafficsource.campaign | character varying(65535) |
trafficsource.source | character varying(65535) |
trafficsource.medium | character varying(65535) |
trafficsource.keyword | character varying(65535) |
trafficsource.adcontent | character varying(65535) |
trafficsource.adwordsclickinfo.campaignid | bigint |
trafficsource.adwordsclickinfo.adgroupid | bigint |
trafficsource.adwordsclickinfo.creativeid | bigint |
trafficsource.adwordsclickinfo.criteriaid | bigint |
trafficsource.adwordsclickinfo.page | bigint |
trafficsource.adwordsclickinfo.slot | character varying(65535) |
trafficsource.adwordsclickinfo.criteriaparameters | character varying(65535) |
trafficsource.adwordsclickinfo.gclid | character varying(65535) |
trafficsource.adwordsclickinfo.customerid | bigint |
trafficsource.adwordsclickinfo.adnetworktype | character varying(65535) |
trafficsource.adwordsclickinfo.targetingcriteria.boomuserlistid | bigint |
trafficsource.adwordsclickinfo.isvideoad | boolean |
trafficsource.istruedirect | boolean |
trafficsource.campaigncode | character varying(65535) |
device.browser | character varying(65535) |
device.browserversion | character varying(65535) |
device.browsersize | character varying(65535) |
device.operatingsystem | character varying(65535) |
device.operatingsystemversion | character varying(65535) |
device.ismobile | boolean |
device.mobiledevicebranding | character varying(65535) |
device.mobiledevicemodel | character varying(65535) |
device.mobileinputselector | character varying(65535) |
device.mobiledeviceinfo | character varying(65535) |
device.mobiledevicemarketingname | character varying(65535) |
device.flashversion | character varying(65535) |
device.javaenabled | boolean |
device.language | character varying(65535) |
device.screencolors | character varying(65535) |
device.screenresolution | character varying(65535) |
device.devicecategory | character varying(65535) |
geonetwork.continent | character varying(65535) |
geonetwork.subcontinent | character varying(65535) |
geonetwork.country | character varying(65535) |
geonetwork.region | character varying(65535) |
geonetwork.metro | character varying(65535) |
geonetwork.city | character varying(65535) |
geonetwork.cityid | character varying(65535) |
geonetwork.networkdomain | character varying(65535) |
geonetwork.latitude | character varying(65535) |
geonetwork.longitude | character varying(65535) |
geonetwork.networklocation | character varying(65535) |
fullvisitorid | character varying(65535) |
userid | character varying(65535) |
clientid | character varying(65535) |
channelgrouping | character varying(65535) |
socialengagementtype | character varying(65535) |
customdimensions.index | bigint |
customdimensions.value | character varying(65535) |
BigQueryと同様のクエリを投げてみます。
SELECT "device.browser", SUM ( "totals.transactions" ) AS total_transactions FROM techblog_bastion_stack_bigquery_data_bucket_xxx GROUP BY "device.browser" ORDER BY total_transactions DESC;
以下の通り、同じ実行結果が確認できました。
device.browser | total_transactions
--------------------------+--------------------
Opera |
Internet Explorer |
YaBrowser |
Safari (in-app) |
Mozilla Compatible Agent |
Opera Mini |
Edge |
UC Browser |
Android Browser |
Android Webview |
Nokia Browser |
Chrome | 40
Safari | 3
Firefox | 1
(14 rows)
以上でBigQueryからRedshiftへの移行手順は終了です。
5. リソースの削除
削除が必要なリソースは以下の通りです。
- GCSバケット (
GCS_BUCKET_NAME) - Glueのジョブ/接続/クローラ
- CloudFormationのRedshiftスタック・Bastionスタック・VPCスタック
AWSリソースの削除に関して、いくつか注意点があります。
* Glueのジョブ/接続/クローラは、CloudFormationを使わず手動で追加したため、AWSマネジメントコンソール > Glue を開き、各リソースを手動で削除してください。
* Redshiftスタック・Bastionスタック・VPCスタックを削除する際、スタック間に依存関係があるため、この順番で一つずつ削除してください
* Bastionスタックを削除する前に、S3バケット (S3_BUCKET_NAME )の中身を空にしておいてください(AWSマネジメントコンソール > S3 > バケットを選択して「空にする」をクリック)
* Redshiftスタックをを削除する前に、Glueジョブ時に作成されたENIを手動で削除してください(AWSマネジメントコンソール > EC2 > ネットワーク&セキュリティ > ネットワークインターフェース)。
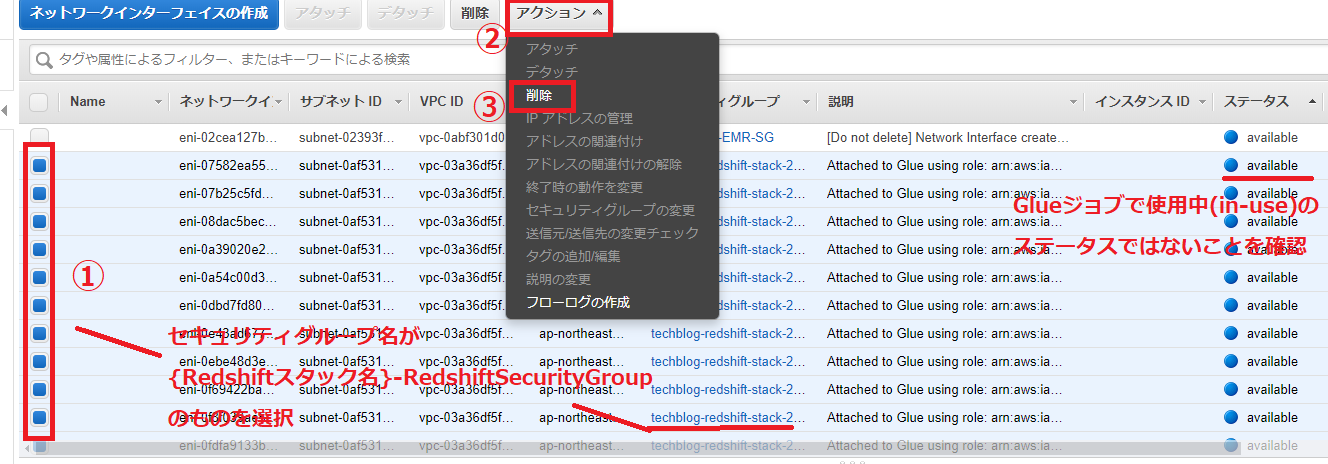
不要なコストを避けるため、検証後はAWS/GCPのマネジメントコンソールからリソースの削除をお願いします。
まとめ
この記事では、Google BigQueryからAmazon Redshiftにデータを移行する流れをご紹介しました。
AWSブログのCloudFormationテンプレートを使ってRedshift環境を構築し、
BigQueryの一般公開データセットのデータを、bq extract コマンドでGCSに出力、
.boto構成ファイルに認証情報を追加し、gsutilツールでGCSからS3にデータをコピー、
Glueを使って、S3からRedshiftへETLジョブを実行し、Redshiftにクエリを投げてデータを確認しました。
この記事の内容が少しでも参考になれば幸いです。

2017年4月、NHNテコラスに新卒入社。データサイエンスチームに所属し、AWSを活用したデータ分析サービスの設計開発を担当。


Recommends
こちらもおすすめ
-

2017年は本当に「ビッグデータ利活用元年」だったのか
2017.12.16
-

Glue Data Catalogにテーブルを登録したデータを対象に加速クロールを使う
2024.12.22




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16