AWS Glueの「AmazonS3イベント通知を使用した加速クロール」とは何か
Amazon S3 イベント通知を使用した加速クロールを業務で利用する機会がありました。そこで得られた知見などをここで共有したいと思います。
AWS Glueとは何か、AWS Glue Crawlerとは何かという基本的な情報は省きますので、こちらを知りたい場合は以下の資料などでの参照をお願いします。
AWS BlackBelt Glue
「AmazonS3イベント通知を使用した加速クロール」とは何か
簡単にまとめると「GlueCrawlerがS3イベントとSQSを使うことで、通常よりも読み込むデータ量が少なくなり、結果的にコスト削減や処理速度が上がる仕組み」となります。
通常のクローラーの場合は以下のように、クローラーに設定されたS3のパスをクローリングして、その結果をDataCatalogに保存します。
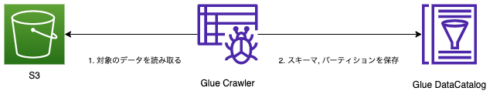
加速クロールでは以下の図のように、通常のクローラーの構成に加えてS3のイベント通知機能とSQSを利用します。
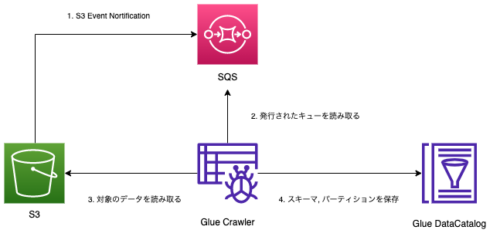
あらかじめS3のイベント通知機能にSQSを設定しておくことにより、S3にデータの追加があった場合SQSが発行されます。またGlue Crawlerを作成する時点でSQSを登録して、加速クロールの設定をしておきます。この設定によってクローリングを実行する際にSQSに発行されたキューを読み取ることで、必要なファイルのみを読み取ることができるようになります。これにより必要ないファイルを読み込むことがなくなるため、クローラーの実行速度の向上と費用の削減が見込めます。
ただし加速(=Accelerating)とは書いてありますが、私が使ってみた範囲では速度的な意味では劇的に速くはなるわけではありませんでした。これに関してはGlueCrawlerがかかった時間はデータ量やファイル数、クローラーの設定によって大きく変化するため、他のユースケースでは違うかもしれません。そのため私が使用したプロジェクトでは主にクローラーが読み込むデータ量が減ることによって、コストが削減される効果を主な使用目的としていました。
【補足】 Glueのコストの計算方法
今回の加速クロールではGlueのコストの話が出ることが多いため、一度Glueのコストの計算方法について補足します。ここではAWS Glue Pricingを参考に説明をします。
$0.44 per DPU-Hour, billed per second, with a 10-minute minimum per crawler run
Glueのコスト計算はDPU/hをもとに計算されます。つまり上記のリンクによると東京リージョン(ap-northeast-1)であれば、1時間あたり1DPU使うと、$0.44のコストがかかります。
DPUとはGlueの性能の単位です。多ければ多いほどたくさんのCPUを使っていることになります。また最低実行時間が10分とあります。そのためクローラーが3分で終わったとしても、10分の料金がかかることになりますので注意しておきましょう。
ここまでDPUという言葉が何度か登場しましたが、クローラーではDPUの数は自動的に決められるためユーザーが設定できることはありません。データ量が多ければクローラーがDPUをたくさん使うためDPU/hが大きくなり、コストも上がります。
例: 1DPUを10分使用した場合
※ 1DPU/h = $0.44、 最低実行時間10分
$ 1 * 10 / 60 * 0.44 $ 0.73
また実際Glueを使用すると「DPU hours」という項目に使用したDPU/hが表示されますが、こちらには10分以下でも0.73以下が表示されることがあります。そのためDPUは1つ2つといった整数単位で付与されるものではなさそうです。
「AmazonS3イベント通知を使用した加速クロール」はいつ使うのか
本題に戻りここでは加速クロールを使うべき時について説明します。Glue Crawlerには複数の設定がありますが、今回は読み込み方法とスキーマの更新の設定に絞って説明をしたいと思います。
Glue Crawlerは以下の3種類の読み込み方法があります。
- Crawl all sub-folders
- Crawl new sub-folders only
- Crawl based on events
1は常に全て読み込む方法です。デフォルトの設定ではこちらになります。2は新しく追加されたファイルのみ読み込む方法です。AWS公式サイトでは増分クロールとして紹介されています。3は「AmazonS3イベント通知を使用した加速クロール」となっています。これ以降は1を全体クロール、2を増分クロール、3を加速クロールと呼びます。
全体クロールを選択した場合は実行するたびに対象のデータを全てを読み込むため、実行時間もそうですが何よりコストが大きくなります。そのため読み込むべきデータが大量にあり、かつ定期的にデータの追加がある場合は全体クロールは適していません。そこで費用や処理速度を改善するために増分クロールや加速クロールを考えることになります。
増分クロールと加速クロールはどちらも読み込むべきデータを削減する点は共通しています。これらの大きな違いは、GlueCrawlerで設定できる他の設定が異なることです。
Glue Crawlerはクローリングを行なった後に、既存のDataCatalogのスキーマを更新することができます。AWS公式サイトではクローラー設定オプションの設定の「AWS Glue コンソールでのクローラー設定オプションの設定」で紹介されています。
こちらも3種類の設定があります。
a. Update the table definition in the data catalog(Data Catalog でテーブル定義を更新する)
b. Add new columns only(新しい列の追加のみ)
c. Ignore the change and don’t update the table in the data catalog(変更を無視し、Data Catalog のテーブルを更新しない)
全体クロールと加速クロールでは全て選択することができますが、増分クロールはcしか設定ができなくなっています。つまり増分クロールはデータのカラムなどに更新があった場合、クローラーを実行してもスキーマの更新をすることができません。
ここまでをまとめると以下になります。
| 読み込み方法 | a.テーブル定義を更新する | b.新しい列の追加のみ | c.テーブル定義を更新しない |
|---|---|---|---|
| 全体クロール | ○ | ○ | ○ |
| 増分クロール | × | × | ○ |
| 加速クロール | ○ | ○ | ○ |
私が利用したプロジェクトでは1日で約数GB ~ 数十GBのデータを読み込む必要があり、かつ自動でスキーマの変更を反映して欲しかったため、増分クロールではなく加速クロールを選択しました。
加速クロールを利用する際の注意点について
私が実装の際につまづいたポイントや気になったポイントを記載します。
1. 発行されるSQSが多い場合は加速クロールは遅くなる
公式サイトにも記載がある通り、加速クロールを使用すれば必ず速くなるという訳ではありません。
Amazon S3 イベント通知を使用した加速クロール
ターゲットからのすべてのオブジェクトの一覧表示を要しない場合は、より速く再クロールできます。その代わりに、オブジェクトが追加または削除される特定のフォルダが一覧表示されます。
私が検証した結果は以下の通りでした。
※ かかった時間はデータ量やファイル数、クローラーの設定によって大きく変化します。あくまで参考程度に参照してください。
検証1. 合計800MB, 13件のParquetファイルの場合
=> 対象ファイルが少ないと、SQSありの方が早い
※ 40GBのデータが既にGlueDataCatalogに取り込まれている状態で実行
| 分類 | 時間 | DPU/h |
|---|---|---|
| SQSなし(全体クロール) | 1分40秒 | 0.0606110 |
| SQSあり(加速クロール) | 57秒 | 0.0332780 |
検証2. 合計1.6TB, 14148件のParquetファイルの場合
=> 対象ファイルが多いと、SQSありの方が遅くなる
※ 40GBのデータが既にGlueDataCatalogに取り込まれている状態で実行
| 分類 | 時間 | DPU/h |
|---|---|---|
| SQSなし(全体クロール) | 2分15秒 | 0.2820 |
| SQSあり(加速クロール) | 3分54秒 | 0.2288890 |
取り込むべきファイル数が多くなってくると、速度はむしろ加速クロールの方が遅くなってきていました。
そのため定期的にクローラーを実行しないようなデータなどは加速クロールには適していないことになります。
2. 加速クロールを使うとコスト削減につながる
前述の通り私が使用したプロジェクトでは加速クロールを使うことで必ずしも速くなる訳ではなかったですが、DPU/hに関しては非常に効果が大きかったです。加速クロールという名称から処理速度改善のための仕組みかと思っていましたが、どちらかといえばコスト削減の効果が大きかったです。
こちらも私が検証した結果は以下の通りでした。
※ かかった時間はデータ量やファイル数、クローラーの設定によって大きく変化します。あくまで参考程度に参照してください。
検証3. 1.6TBのデータが溜まっている状態で1セット(合計800MB, 13件のParquetファイル)を追加した場合
=> SQSを使う方が、読み込むデータ量は少ない(処理に必要なDPU/hが少ない)
| 分類 | 時間 | DPU/h |
|---|---|---|
| SQSなし(全体クロール) | 1分11秒 | 0.1781110 |
| SQSあり(加速クロール) | 59秒 | 0.0332780 |
またDPU/hについてはデータの蓄積が大きくなればなるほど、全体クロールに対して加速クロールによるコスト削減効果が大きくなってきました。
3. S3イベントの設定について
GlueCrawlerにはあらかじめS3イベント通知にSQSを設定しておく必要があります。SQSにトリガーさせたいパスをプレフィックスに設定する必要があるのですが、このプレフィックスはS3イベント通知は同一バケット内で重複ができないようになっています。
オブジェクトキー名のフィルタリングを使用したイベント通知の設定
そのためSQS用のS3イベント通知のプレフィックスに/path/to/sqs/* と設定した後に、同じパスに対してLambdaもS3イベント通知で連携したいと思っても設定をすることができません。そのため、SQS以外にもフックさせたい場合は、以下で紹介されているようにS3とSQSの間にSNSを入れてFan outさせる構造にする必要があります。
Design patterns: Set up AWS Glue Crawlers using S3 event notifications
まとめ
これまでの内容をまとめると、加速クローラーを含めてメリット、デメリットは以下になります。
全体クロール
- ○ スキーマを自動で更新することができる
- ○ データの確認のために手早く構築できる
- × データ量が多くなるたびに、コストが大きくなる
増分クロール
- ○ 追加されたデータのみを読み込むため、読み込み速度向上とコスト削減ができる
- × スキーマを自動で更新することができない
加速クロール
- ○ スキーマを自動で更新することができる
- ○ 追加されたデータのみを読み込むため、読み込み速度向上とコスト削減ができる
- × SQSやS3の設定が必要になるため、実装コストが他の設定と比べてやや高い
上記のように加速クロールは全体クロールと増分クロールのいいとこ取りをした性能を持っていますが、一方でSQSやS3など他のサービスを利用するため実装するコストは上がっています。そのため加速クロールの構成で実装するときは、自分達の利用用途や目的に合致するかしっかり検証する必要があります。
私たちのチームでも本番運用を続けているため、その後進展や改善ポイントがあれば改めて文章にまとめる予定です。

2018年新卒入社。エンジニア。フロントエンド&サーバサイドを担当。 Vue.js, Ruby on Rails, Ruby, Javaを主に使用する。 会社では全力で働き、家では全力で遊ぶ。


Recommends
こちらもおすすめ




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16