【セッションレポート】Amazon S3 によるデータレイク構築と最適化 #AWS Summit Japan 2025

はじめに
こんにちは、フクナガです。
今年も 2 日間にわたって AWS Summit Japan が開催されました!
非常に多くの素晴らしいセッションがあり、イベント終了後もアーカイブ視聴によるキャッチアップに追われる日々を送っております。
今回の記事では私が聴講した「Amazon S3 によるデータレイク構築と最適化」というセッションを取り上げてご紹介いたします。
ちなみに、本セッションは AWS Summit Japan サイトからユーザー登録いただくことで
アーカイブ視聴が可能なセッションとなっておりますので、気になった方はぜひ見てみてください!
AWS Summit Japan 2025
ユーザー登録はこちらから
※本情報は、2025年6月30日時点での情報となります。
セッション情報
タイトル
Amazon S3 によるデータレイク構築と最適化(AWS-04)
スピーカー
吉澤 巧 様
アマゾン ウェブ サービス ジャパン合同会社 デジタルサービス技術本部 デジタルサービスソリューション部
ソリューションアーキテクト
前提知識
このセッションはデータ分析に関するセッションとなります。
特にデータレイク部分にフォーカスされたセッションですので、データ分析に関する基本的なワードを抑えると非常に見やすくなると思います!
データ分析頻出単語
(1) データレイク
分析に利用するデータを保管する場所のことで、構造化データや非構造化データなどの区分なく保存します。
参考:データレイクとは
(2) データウェアハウス
データを分析可能な状態で保管している場所のことを言います。
参考:データウェアハウスとは何ですか?
(3) データマート
データウェアハウスに格納されているデータを目的や用途に合わせて加工し、格納する場所のことを言います。
参考:データマートとは何ですか?
(4) 全体像のイメージ
弊社のサービスページにちょうどイメージしやすい図がありましたので、そちらでご説明させていただきます。
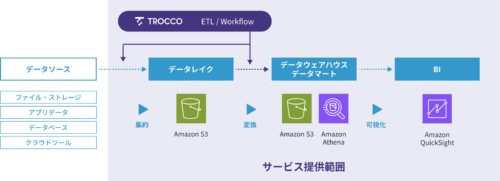
出典:最短6週間で始めるAWS上でのデータ分析 データ分析スターターパック
様々なデータを「データレイク」に集約し、そこから「データウェアハウス」に連携、「データウェアハウス」でデータを加工して「データマート」を作成し、BIツールなどで可視化をする、というのが一般的な流れです。
そのほかにも様々なデータ分析のアーキテクチャパターンはありますが、最も基本系はこの流れであると認識しておくと理解が早くなると思います!
セッションの要約
- 生データ、処理済みデータ、キュレーションデータなどデータごとで複数のレイヤーに分けて保存することでスケーラブルなアーキテクチャを設計可能である
- 生データでは日時ごとに Prefix が分かれているケースが多く、負荷やスケールまでの時間を考慮すると、ランダム性を持った要素を Prefix の上位に置く構成にすることなど Prefix 構成を見直す必要がある
- AWS Lake Formation を利用すると、属性ごとや列ごとなどきめ細かいアクセス制御を実現できる
- Apache Iceberg を活用することにより、パーティションの動的な変更を可能にし、パーティションを活用したクエリの最適化を実現しやすくできる
- Amazon S3 Tables で、Apache Iceberg Table の運用負荷を下げながら構築が可能である
- S3 ストレージクラスの使い分けと、ライフサイクルルールにより、コストを最適化できる
セッションレポート
このセッションでは、Amazon S3 をデータレイクとして利用する前提で、どういった点に気を付ける必要があるのか、が網羅的に解説されていました。
Amazon S3 をデータレイクとして採用するようなデータ分析基盤を構築予定の場合は、非常に参考になるセッションです。
本ブログでは、私の中で印象に残った内容をいくつか絞ってご紹介いたします。
1. S3 によるデータレイクの課題
このセッションでは、「クエリ遅延」「アクセス制御」「コスト」「対象データの検索性」を課題として挙げていました。
これらの課題を解決する方法として、設計方法や AWS マネージドサービスの特長について紹介するという流れのセッションです。
2. スケーラブルなアーキテクチャ設計
このセッション内では、「データの保管場所」「Prefix 設計」の 2 つが紹介されていました。
本ブログでは、私が特に興味を持った「Prefix 設計」をご紹介します。
Prefix 設計
S3 における Prefix とは、S3 に格納されたオブジェクトの所在を表す文字列のことを言います。
ファイル管理における、フォルダやパスに近いものと認識してもらえればと思います。
例)
my-bucket/documents/2023/report.pdf
この Prefix ごとに毎秒 3,500 回以上の PUT/COPY/POST/DELETE リクエストまたは 5,500 回以上の GET/HEAD リクエストを許容できるのですが、実際のパフォーマンスに関するスケーリングは徐々に行われ、瞬時には行われません。
参考:設計パターンのベストプラクティス: Amazon S3 のパフォーマンスの最適化
ログなどによくある日時とセッションIDなどで分割される Prefix パターンでデータレイクを構成する場合、日時が変わったタイミングで別の Prefix へアクセスが瞬時に集中することが予想されます。その場合、スケールが間に合わずエラーになることが想定されます。そのため、ランダム性を持った要素を Prefix の上位に設定するなどの構成変更を行うことでこういったエラーを少なくし、スケーラブルなアーキテクチャを構成することが求められるという説明がされていました。
非常に細かい部分ですが、データレイクの構成を検討する際にはとても重要な要素だなと感じました。
3. アクセス制御について
センシティブなデータを扱うことも多いと思いますが、きめ細かなアクセス制御を実現する際に
AWS Lake Formation が利用できるというご紹介がありました。
特定列の要素ごとでのフィルタリングや、特定の列に対するアクセス制御などかなり細かく設定できそうです。
参考:Lake Formation でのデータフィルタリングとセルレベルのセキュリティ
4. クエリの最適化におけるパーティション活用について
(1) 正しいパーティション活用によるクエリ制限
適切なパーティション活用をしなければクエリの最適化はできない、という内容です。
参考:データのパーティション化
取り上げられていた例では、もともと「2025-06-25」という形式で日付指定をしていましたが、パーティションを活用するためには年、月、日と別々で条件指定する必要がありました。
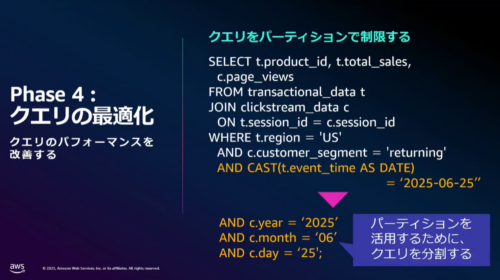
出典:Amazon S3 によるデータレイク構築と最適化
クエリ分割によってパーティション活用はできますが、より運用負荷を下げながら実践する方法として Apache Iceberg をはじめとするオープンテーブルフォーマットの活用が紹介されていました。
(2) Apache Iceberg をはじめとするオープンテーブルフォーマットの活用
Apache Iceberg を使用することは、パーティションの動的な追加・削除が可能になったり、パーティション活用のためのクエリの分割が不要になったりと様々なメリットがあり、パーティション活用によるクエリ最適化を考えるうえで非常によい選択肢であるという説明がされていました。
また、この Apache Iceberg をフルマネージドで構築する選択肢として Amazon S3 Tables が活用できるというお話もされていました。
参考:Amazon S3 Tables とテーブルバケットの使用
この Amazon S3 Tables については、弊社からもブログが出ておりますので見てみてください!

まとめ
本ブログでは、私が聴講した「Amazon S3 によるデータレイク構築と最適化」というセッションについて、気になったポイントをご紹介させていただきました。データ分析におけるデータレイクを適切に構築することがデータ分析基盤におけるパフォーマンスやコスト観点で重要であることを改めて認識することができるとても良いセッションだったなと感じます。
本ブログでは紹介しきれない内容もございますので、気になった方はぜひアーカイブでチェックしてみてください!
改めてのご案内ですが、本セッションは AWS Summit Japan サイトからユーザー登録いただくことで
アーカイブ視聴が可能なセッションとなっております!
AWS Summit Japan 2025
ユーザー登録はこちらから
※本情報は、2025年6月30日時点での情報となります。
その他のセッションレポート


2025 Japan AWS Ambassadors / Google Cloud Partner Top Engineer 2026 / Google Cloud Partner Top Engineer 2025 / 2024 Japan AWS Top Engineers 選出されました! 生成 AI 多めで発信していますが、CI/CDやIaCへの関心も高いです。休日はベースを弾いてます。


Recommends
こちらもおすすめ
-

TROCCOの接続方法をWebマーケティング観点でまとめてみた
2025.12.23




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16