【セッションレポート】AI アプリケーションのためのデータエンジニアリング戦略 – Amazon Bedrock で実現する構造化データ活用 #AWS Summit Japan 2025

はじめに
こんにちは、フクナガです。
今年も 2 日間にわたって AWS Summit Japan が開催されました!
イベントでは、多くの素晴らしいセッションが行われておりましたが、
今回の記事では私が聴講した「AI アプリケーションのためのデータエンジニアリング戦略 – Amazon Bedrock で実現する構造化データ活用」というセッションを取り上げてご紹介いたします。
ちなみに、本セッションは AWS Summit Japan サイトからユーザー登録いただくことでアーカイブ視聴が可能なセッションとなっておりますので、気になった方はぜひ見てみてください!
AWS Summit Japan 2025
ユーザー登録はこちらから
※本情報は、2025年6月30日時点での情報となります。
セッション情報
タイトル
AI アプリケーションのためのデータエンジニアリング戦略 – Amazon Bedrock で実現する構造化データ活用(AWS-46)
スピーカー
森下 裕介 様
アマゾン ウェブ サービス ジャパン合同会社 技術統括本部 エンタープライズ技術本部 ソーシャルソリューション&サービスグループ ソリューションアーキテクト
前提知識
このセッションにおいて重要なのは「構造化データ」です。
構造化データと非構造化データの違いについておさらいしておきましょう。
構造化データは、厳密なフォーマットで管理されているデータのことを言います。
今回のセッションでは Amazon Redshift などに構築されたテーブルで管理されるデータを構造化データとして取り扱っています。
非構造化データは構造化データのようなルールはなく、画像、音声、動画ファイル、テキストドキュメントなど様々あります。
参考:構造化データと非構造化データの違いは何ですか?
セッションの要約
ポイントを簡単にまとめます。
お時間のある方は、次の詳細なレポートもご覧ください。
- 構造化データを取り扱う場合、自然言語での質問を SQL 変換する必要がある
- SQL 変換する際、一般的なアプローチに加え、データの性質を把握したうえでの書き換えが必要になる(ここが大変)
- Amazon Bedrock Knowledge Bases が構造化データ取得のサポートを開始した
参考:Amazon Bedrock ナレッジベースが構造化データ取得のサポートを開始 - Amazon Bedrock Knowledge Bases を使えば、ユーザー側で難しい実装をしなくても構造化データの活用を始められる!
※現在(2025/06/30)は、Amazon Redshift と Amazon Sagemaker Lakehouse からの構造化データ取得のみがサポートされています。
セッションレポート
本セッションでは、生成 AI において構造化データと非構造化データを取り扱う場合ではどういったことに気を付けなければならないのか、という内容が語られていました。
構造化データの生成 AI 活用のアプローチについて順序だてて説明されており、非常にわかりやすいセッションです!
印象深い箇所についてレポートしていきます。
1. 「データが差別化要因」というメッセージ
AWS のセッションで繰り返し伝えられるのが「生成 AI 活用において重要なのは、それぞれが持っているデータである。」というメッセージです。
同じ大規模言語モデルを誰もが使え、AWS などのプラットフォームによって簡単に生成 AI アプリケーションが実装できてしまうため、他社との差別化が図りづらい状況にあります。
そんな中で重要になるのは長い年月をかけて貯めてきたデータである、という内容です。
これまでは、非構造化データ(PDF、画像データ、テキストデータなど)をベースに回答する RAG 手法などが取り上げられがちでしたが、構造化データも多くの企業で長年取り扱われてきたはずです。
そんな構造化データを生成 AI で活用するアプローチが出てくることで、
データ活用と各社の差別化がさらに広がっていきそうですね!
2. 構造化データの取り扱いに必要な「NL2SQL」
Natural Language to SQL つまり自然言語を SQL に変換するアプローチです。
非構造化データでよく利用される RAG のアプローチは Embedding モデルを利用してベクトルデータへ変換し検索を行うというものでした。
構造化データを利用する際には、各テーブルの関係や内容を把握したうえで回答をする必要があります。
例)
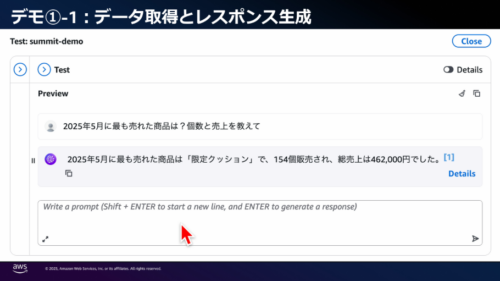
Q:2025 年 5 月に最も売れた商品は何ですか?
→回答するには、商品についてのテーブルと販売ログに関するテーブルなど複数のテーブルを紐づけて集計する必要があるため、ベクトル検索などのアプローチでは回答できない。
そのため、自然言語を SQL に変換して、テーブルに対してクエリを実行したうえで回答するというアプローチが必要になる、というわけです。
3. 生成 AI を使って SQL 化するのは思ったよりも難しい
Claude などのモデルの進化により、コーディングにおける生成 AI 活用はかなり進んでいます。
その背景から NL2SQL はそこまで難しい作業ではないのではないか、と思う人もいるかもしれません。
その難しさについていくつかの例を用いてセッション内で紹介されていました。
詳細は省きますが結論としては、環境固有の設計や命名、テーブルの関係を意識した SQL 変換が非常に難しい、というのが理由になります。
こういった環境に適応するために、SQL 変換を行うためのプロンプトエンジニアリングをしていくなどの工夫は可能ですが、なかなか大変ですよね。
4. Amazon Bedrock Knowledge Bases が「NL2SQL」を実行してくれる!
2024 年 12 月に Amazon Bedrock Knowledge Bases が構造化データ取得のサポートを開始した、という発表がありました。
参考:Amazon Bedrock ナレッジベースが構造化データ取得のサポートを開始
このニュースを見たときはそこまで注視していなかったのですが、今回のセッションを見て改めて素晴らしさを感じました。
なんてすばらしいアップデートなんだ。。。
また、このセッションでは構造化データに対して自然言語で検索をするデモを行っておりました。
Amazon Bedrock Knowledge Bases を使うと非常に簡単に実装できるかつ、構成がシンプルになるのでとてもよさそうです!
まとめ
本記事では、「AI アプリケーションのためのデータエンジニアリング戦略 – Amazon Bedrock で実現する構造化データ活用」というセッションについてご紹介させていただきました。
生成 AI が実用フェーズへ入っている現在、異なる性質を持ったデータに対して適切なアプローチができるかが重要になってきていると思います。
構造化データ、非構造化データの両方に対応している Amazon Bedrock Knowledge Bases は生成 AI でのデータ活用において非常に良い選択肢と言えそうです!
非常にわかりやすいセッションでしたので、ぜひアーカイブでチェックしてみてください!
その他のセッションレポート


2025 Japan AWS Ambassadors / Google Cloud Partner Top Engineer 2026 / Google Cloud Partner Top Engineer 2025 / 2024 Japan AWS Top Engineers 選出されました! 生成 AI 多めで発信していますが、CI/CDやIaCへの関心も高いです。休日はベースを弾いてます。


Recommends
こちらもおすすめ




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16