Amazon BedrockのKnowledge BaseでRAGを構築し、RDSのデータを分析するアプリケーションを開発する


はじめに
こんにちは!
第一SAチームのshikaです。
普段、あるAmazon RDS上のデータベース(MySQL)に対し、SQLを実行してデータを参照しています。
毎回SQLクエリを実行するのが手間だったので、データ検索を容易にするWebアプリケーションを開発しました。
このアプリケーションには、AWSの生成AIサービス「Amazon Bedrock」を活用しており、生成AIを用いた対話式の検索機能を実現しています。
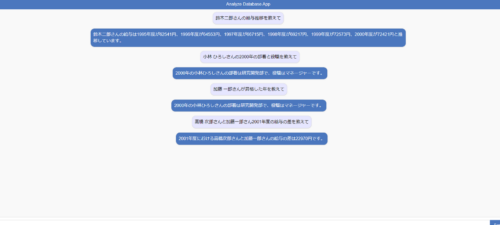
できあがったアプリケーションの画面は以下です。
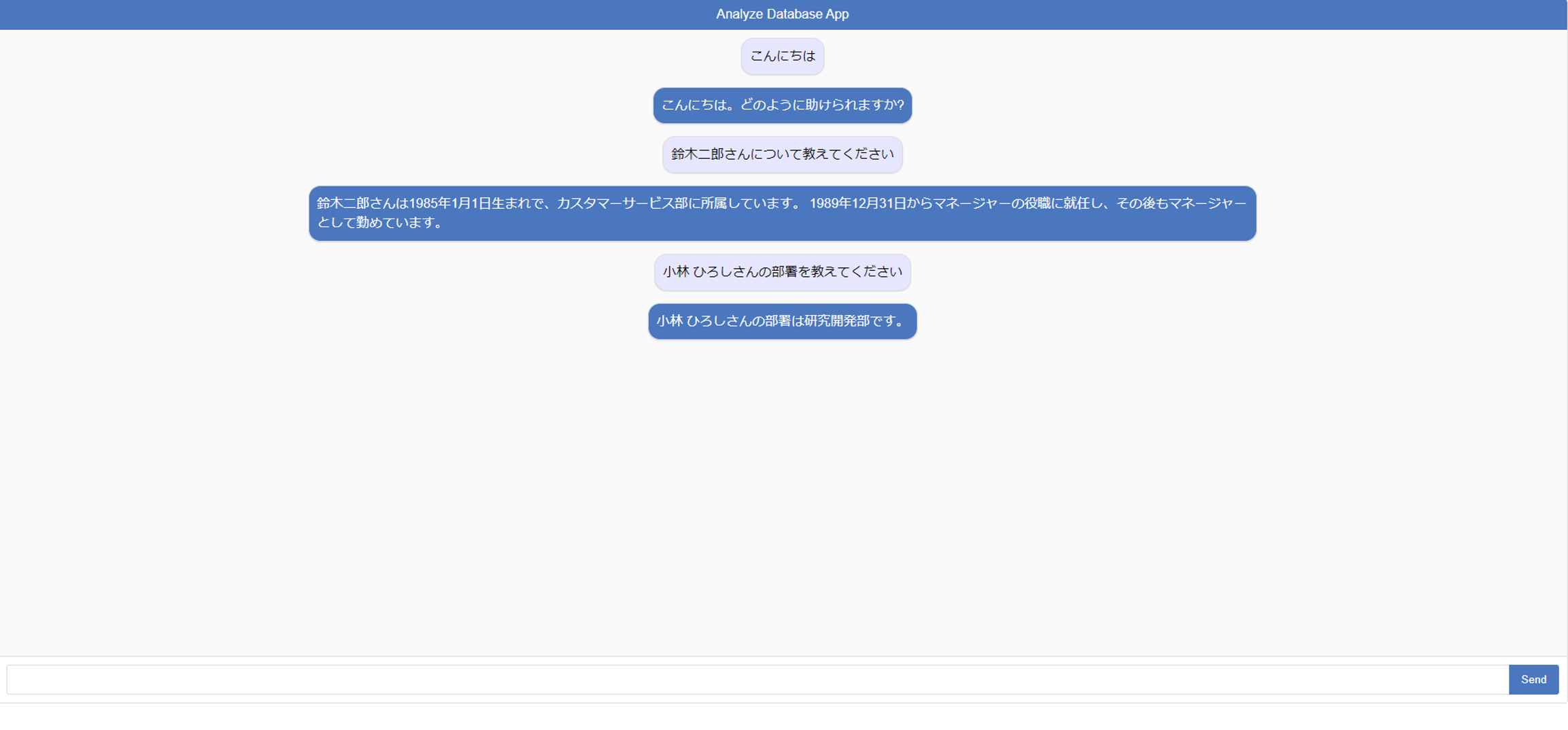
データはテストデータを使ってます。以下の通り、架空の会社の従業員情報に関するデータです。

本記事ではこのアプリケーションの構成、仕組みについて、特にAmazon Bedrockの部分を重点を置いて解説してみます!
その他の構成要素の説明は概要程度とします。
仕組み
構成は以下のようになっています。
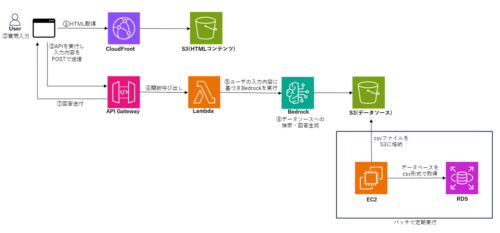
・データソース部分(S3(データソース)、EC2、RDS)
分析したいRDS上のテーブルをAmazon Bedrockが検索できるようにS3上に格納します。
EC2のcronで、RDSのデータベースをcsv出力、ヘッダーの追加、S3にアップロードするという定期処理を登録しておきます。
・フロント部分(CloudFront、S3(HTMLコンテンツ)、API Gateway)
HTML、CSS、JavascriptのみのシンプルなHTMLファイルを作成しました。
「send」ボタンを押すと、javascript関数を呼び出し、API Gatewayに登録しているREST APIを実行し、POSTメソッドでユーザの入力データを送付します。
・データ検索部分(Lambda、Bedrock)
この部分をこれ以降で詳しく説明します。
Amazon BedrockでのRAGについて
Amazon BedrockでRAGを行う方法は以下の2パターンがあります。
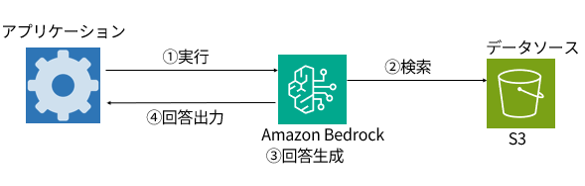
1. Knowledge base for Amazon Bedrockを使用したRAG
Amazon BedrockがS3上のデータソースへ検索を行い、回答生成・出力を行う。
手軽で安価にRAGを行える。
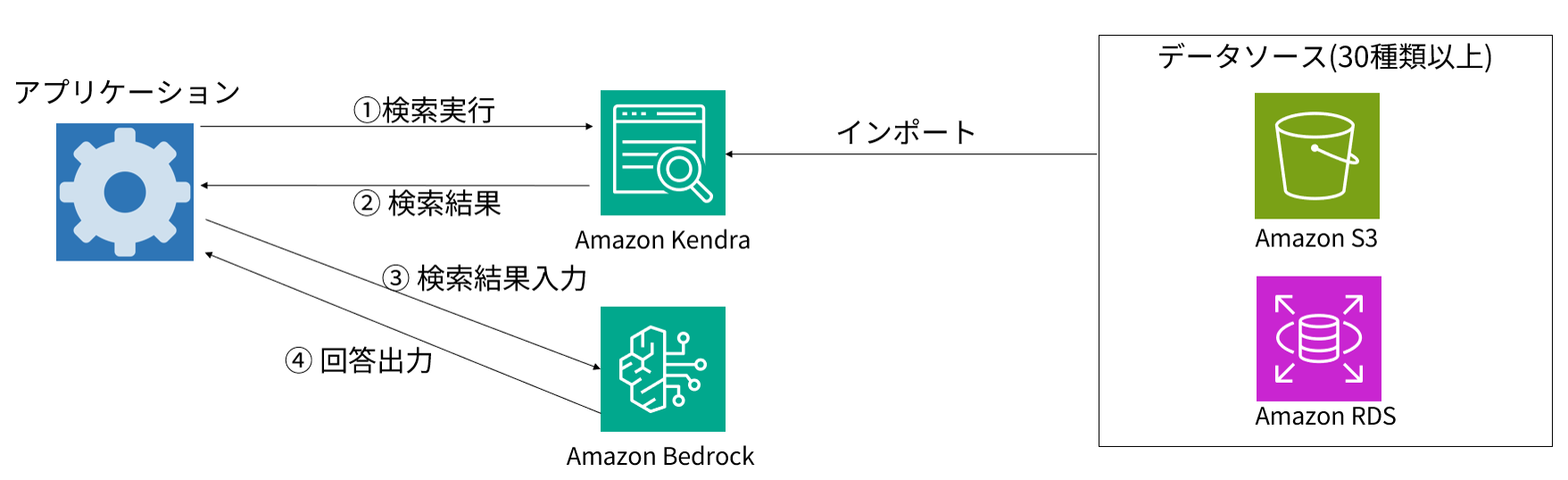
2. Amazon Kendraを使用したRAG
Amazon Kendraがデータソースに対し検索をかけ、Amazon Bedrockは、その検索結果に基づき回答を生成を行う。
データソースはS3やRDS、BOX、Slack等30種類以上に対応。
今回は1番のKnowledge base for Amazon Bedrockを使用したRAGを使いました。
データ検索部分(Lambda、Bedrock)の構築手順
1. Knowledge base for Amazon Bedrockの設定
まずはナレッジベースを作成します。
(1) Amazon Bedrockコンソールの「ナレッジベース」から、「ナレッジベースを作成」を選択します。
(2) 名前やIAMロールを設定します。
ナレッジベース名:任意のものを入力
IAMロール:指定がない場合は「新しいサービスロールを作成して使用」を選択

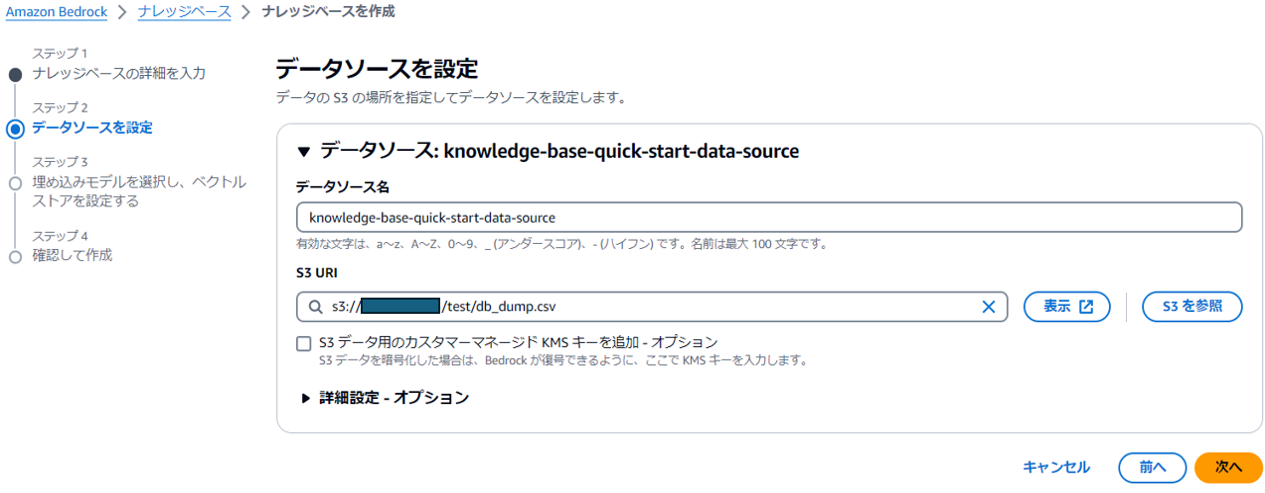
(3) データソースの設定を行います。
Amazon RDSから出力したcsvファイルが格納されているS3のパスを指定します
フォルダを指定した場合、フォルダ配下の全てのファイルを検索対象とすることができます。
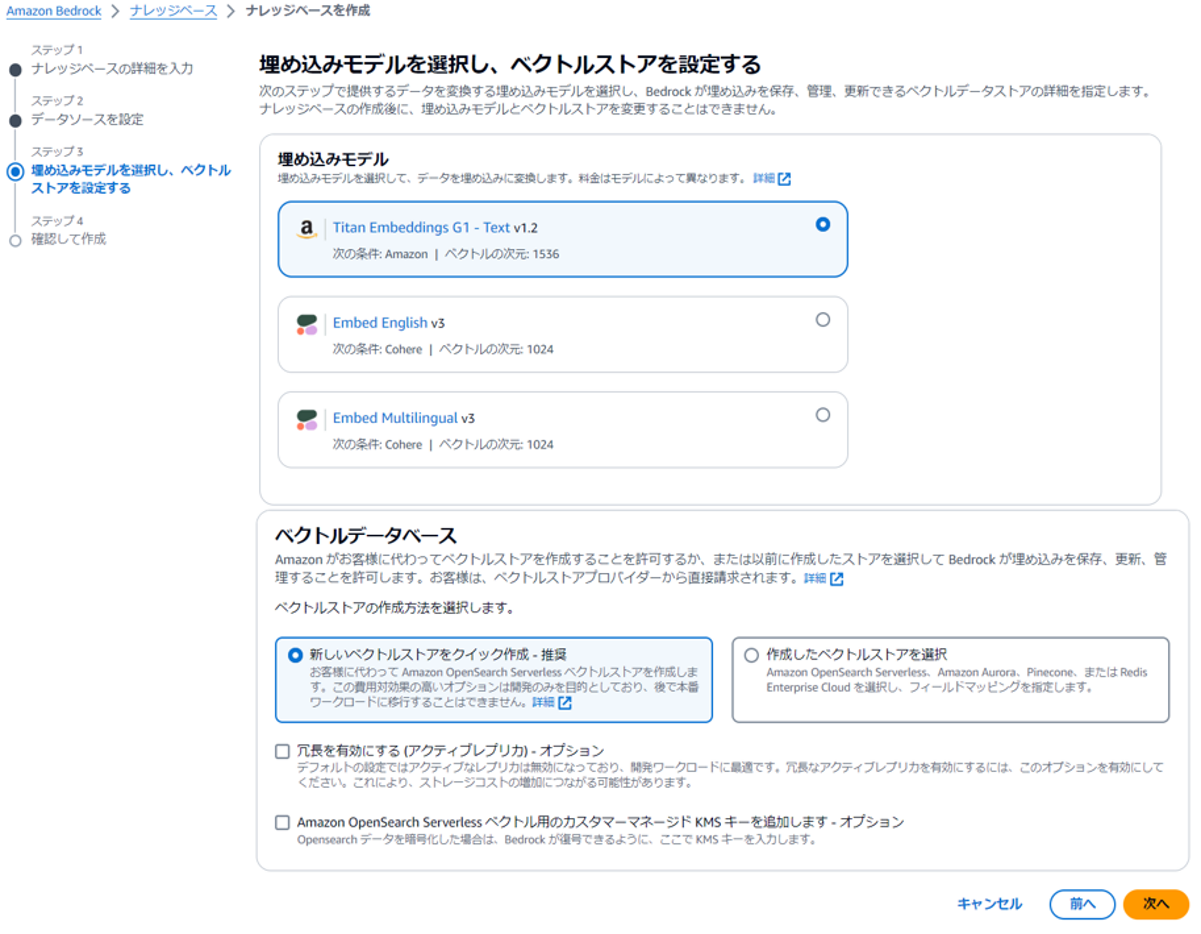
(4) 埋め込み基盤モデルの選択と、ベクトルデータベース(データソースのインデックス)の設定をします。
ナレッジベースを使う場合、基盤モデルは3種類の埋め込み基盤モデルのいずれかを選択します。
ベクトルデータベースは、データソースに対し検索を行うのに必要なデータベースです。
「新しいベクトルストアをクイック作成」を選択すると、ベクトルストアとしてOpenSearch Serverlessが自動的に作成されます。
最後に確認画面でナレッジベースが作成されます。ナレッジベースの作成には数分かかる場合があります。
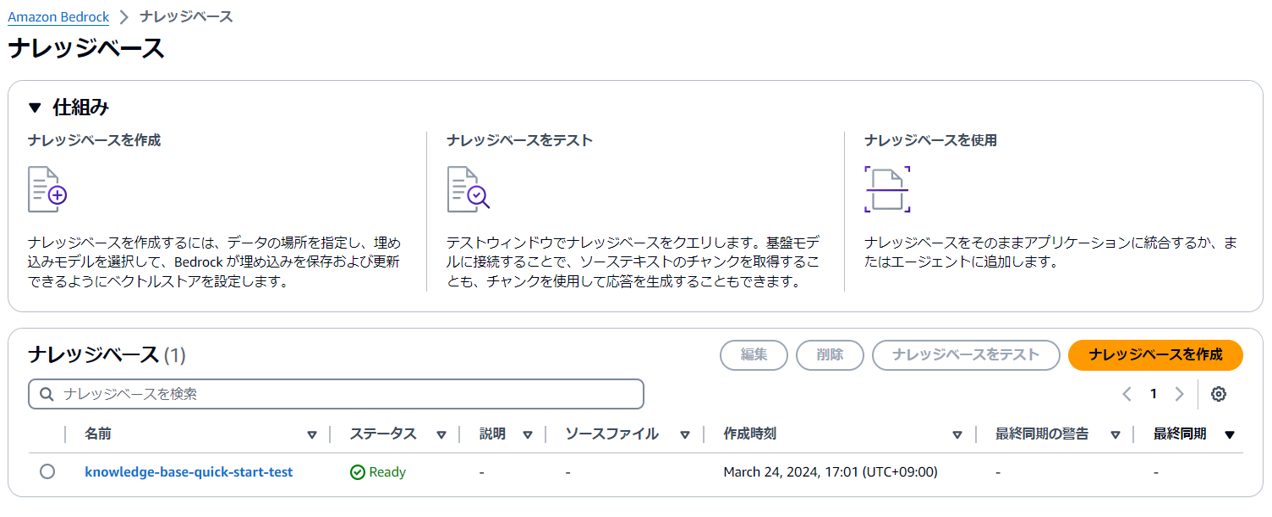
(5) データソースを選択し、「同期」を行います。
こちらを行うことで、Amazon BedrockにS3の情報を認識させます。
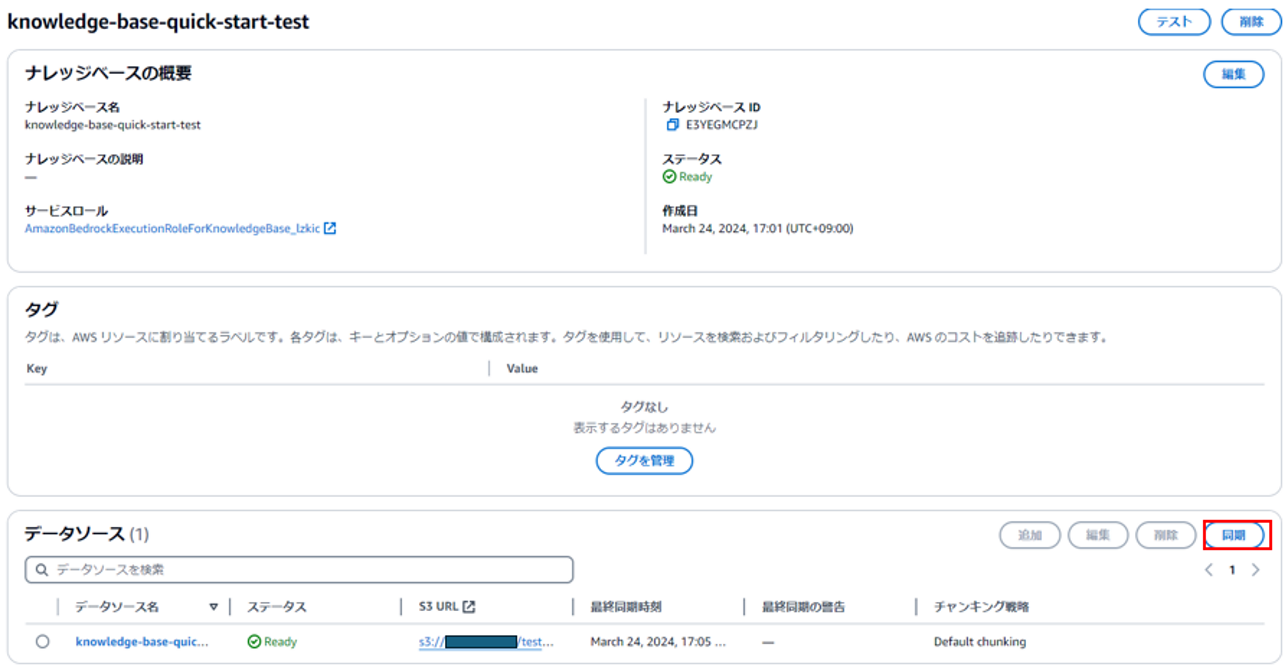
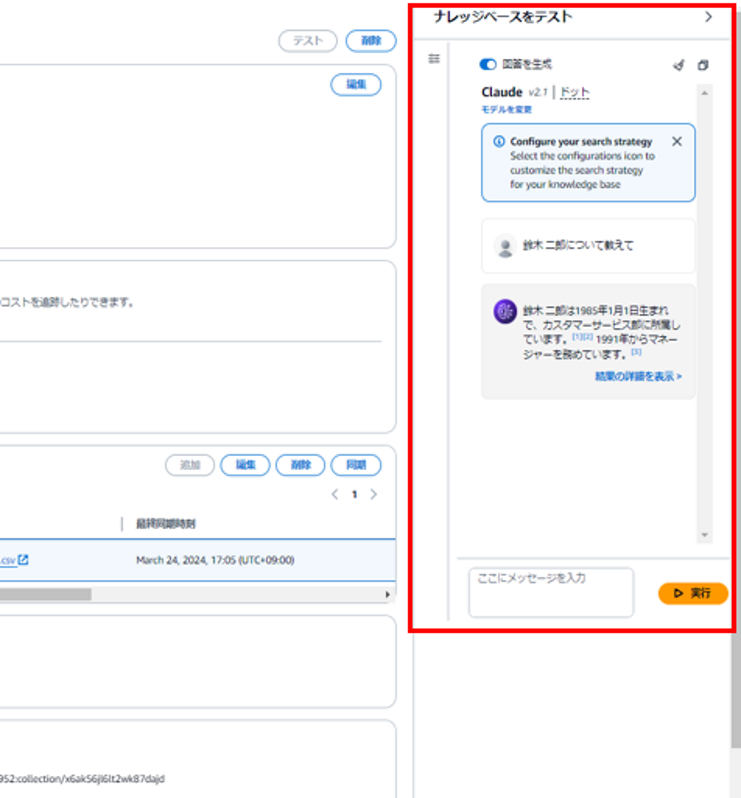
同期が完了すると、コンソール上でナレッジベースのテストが行えるようになります。
2. Agent for bedrockの設定
Agent for bedrockの設定を行います。プログラムからナレッジベースを呼び出す場合は、このエージェント経由で行う必要があります。
(1) Amazon Bedrockコンソールの「エージェント」から、「エージェントを作成」を選択します。
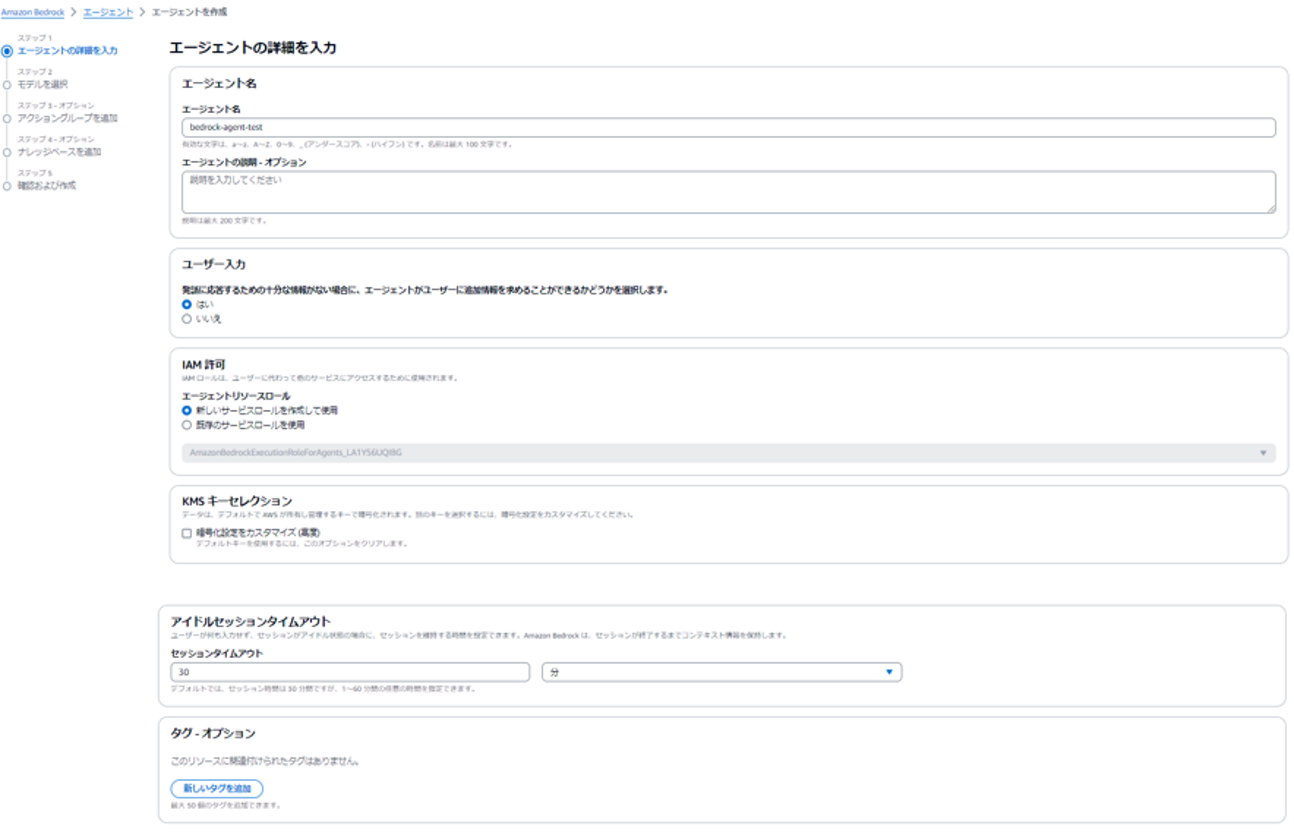
(2) エージェント名やIAMロールを設定します。
エージェント名:任意のものを入力
IAMロール:指定がない場合は「新しいサービスロールを作成して使用」を選択
(3) エージェントへの指示を行うモデルの選択、エージェントへの指示内容を記載します。こちらの指示内容によって精度が大きく変わるため、なるべく具体的に記載をします。
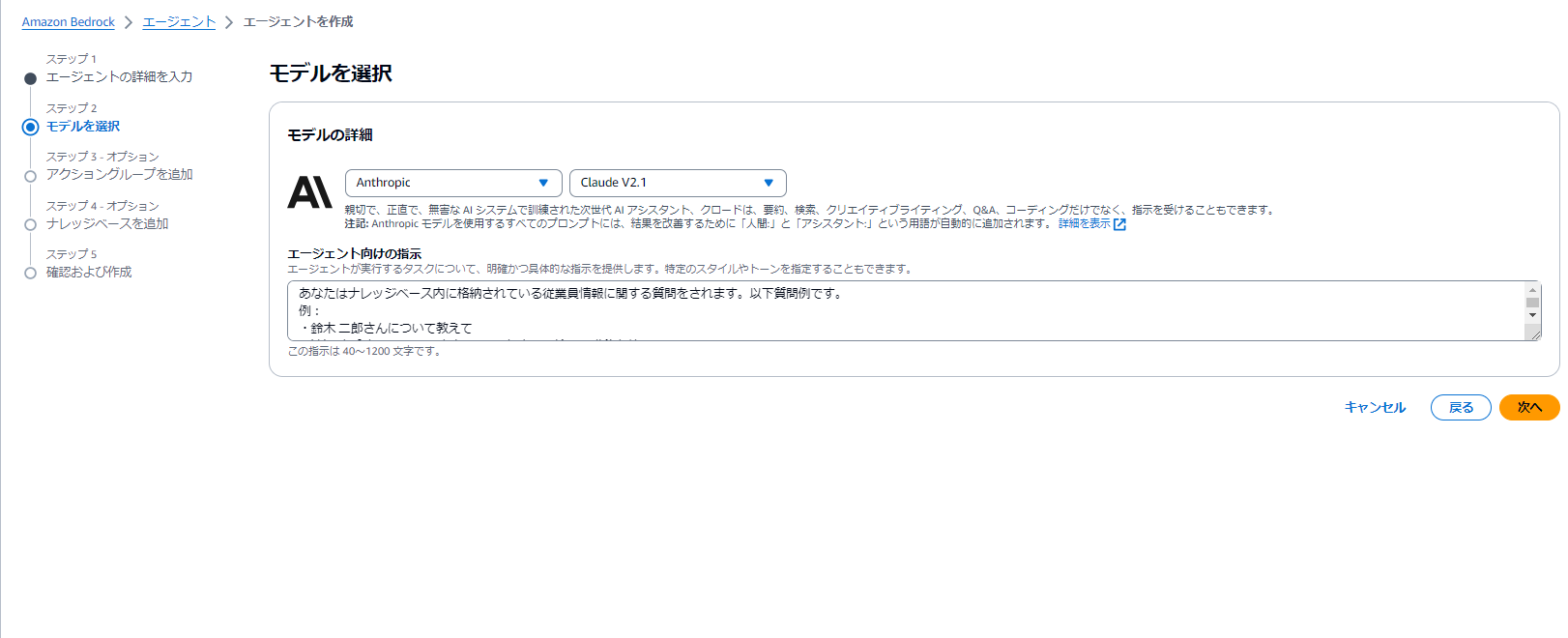
モデルはanthropic.claude-v2:1とし、指示内容は以下のように記載しました。
あなたはナレッジベース内に格納されている従業員情報に関する質問をされます。以下質問例です。
例:
・鈴木 二郎さんについて教えて
・渡辺 春香さんの、1985年から1990年までの給与の推移を教えて
・加藤 一郎さんの部署を教えて質問を受け付けたら、ナレッジベースのデータに基づき回答を生成してください。 言語は日本語とします。
(4) 続いてナレッジベースの選択と、エージェントからナレッジベースへの指示内容を記載します。
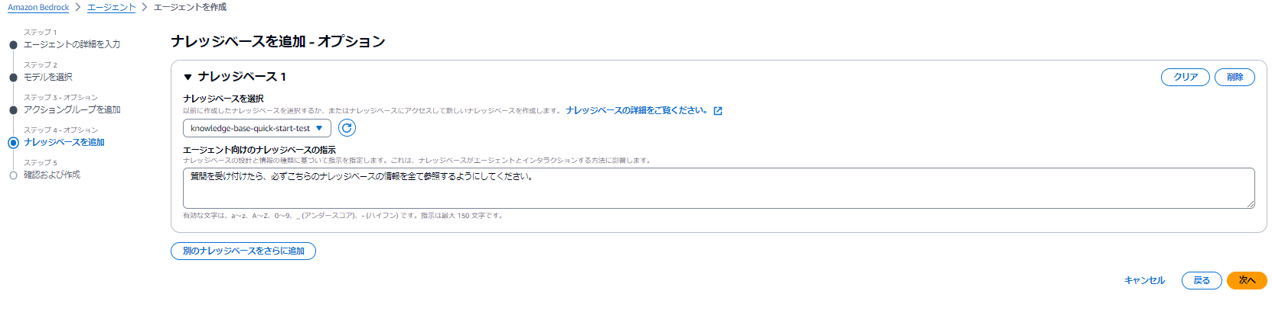
確認画面の後、エージェントが作成されます。
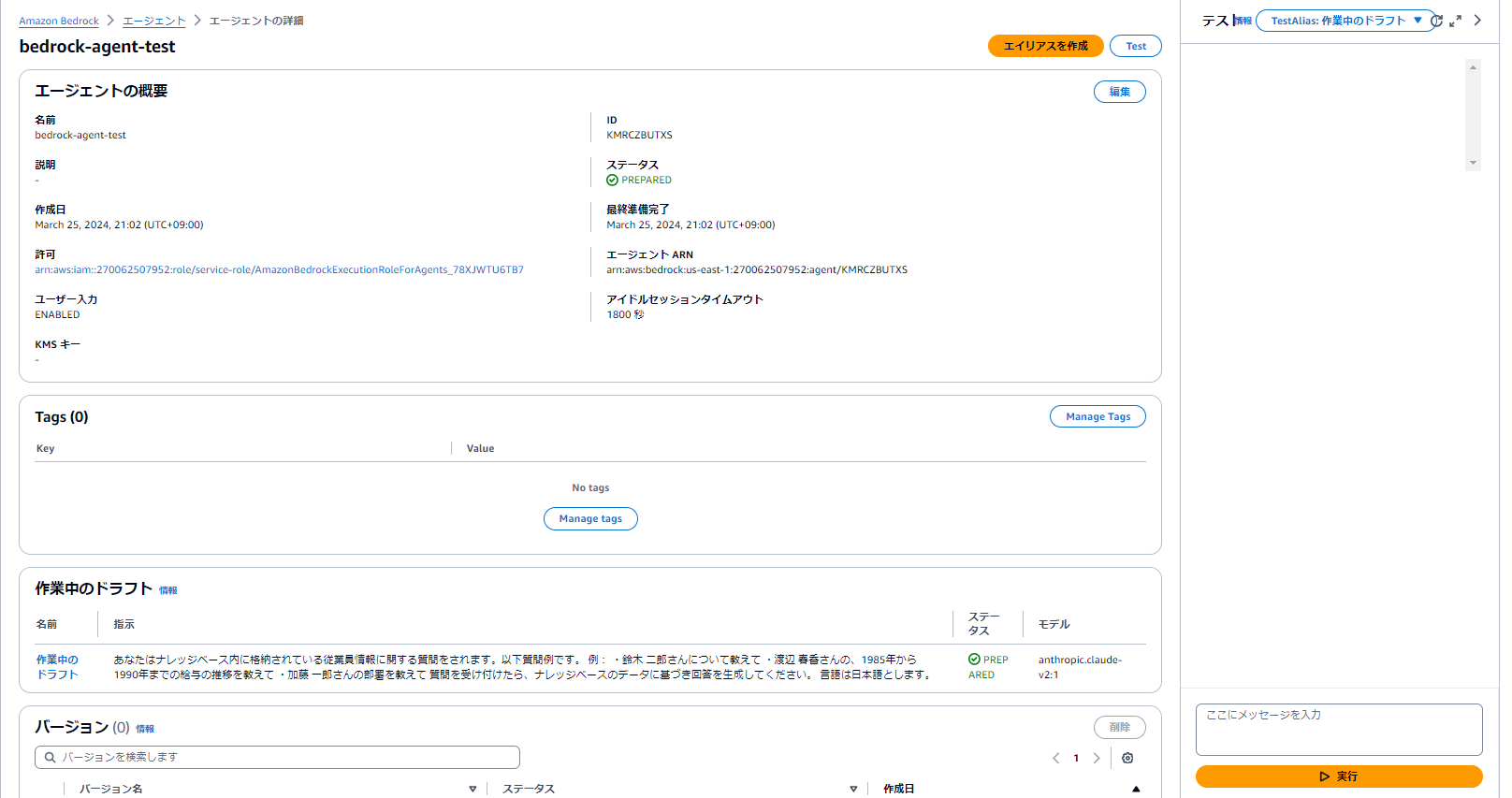
エージェントの画面からもテスト実行ができます。
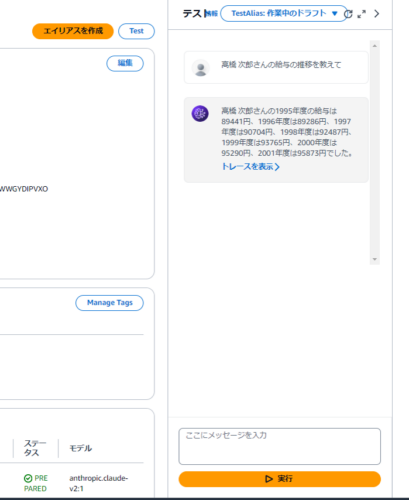
(5) 次に「エイリアスを作成」を選択し、エイリアスを作成します。
このエイリアスで、エージェントのバージョンを識別します。
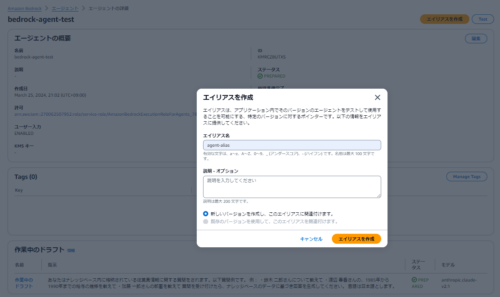
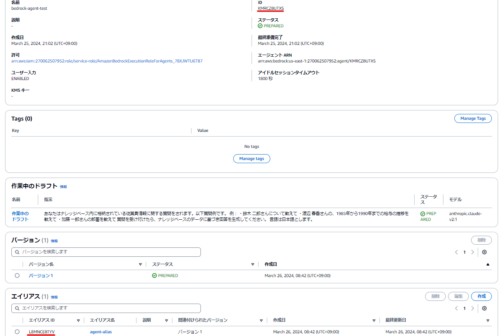
エイリアスが作成できました。
「エージェントID」と「エイリアスID」は、プログラムからAPI経由で実行する際に必要になります。
3. Lambda関数作成
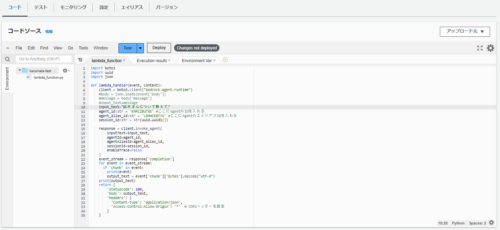
Lambda関数を以下のように作成しました。
agent_Idに先ほど作成したAgentのID、agentAliasIdにAgentのエイリアスIDを指定します。
import boto3
import uuid
import json
def lambda_handler(event, context):
client = boto3.client("bedrock-agent-runtime")
body = json.loads(event['body'])
message = body['message']
input_text=message
agent_id:str = 'KMRCZBUTXS' #AgentのIDを指定する
agent_alias_id:str = 'L8MNCEBTYV' #AgentのエイリアスIDを指定する
session_id:str = str(uuid.uuid1())
response = client.invoke_agent(
inputText=input_text,
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=session_id,
enableTrace=False
)
event_stream = response['completion']
for event in event_stream:
if 'chunk' in event:
print(event)
output_text = event['chunk']['bytes'].decode("utf-8")
print(output_text)
return {
'statusCode': 200,
'body': output_text,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
}
}
まずはLambdaから先ほど作成したAmazon Bedrockエージェントを呼び出せるかテストしてみます。
ユーザが入力した質問を変数として定義している部分をコメントアウトし、質問を直打ちします。
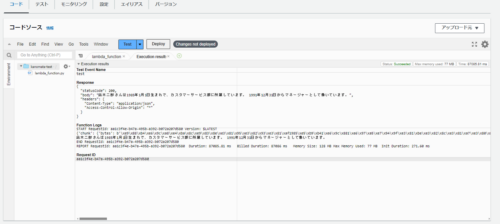
問題なく実行できていることを確認しました。
あとはこの関数をAPI Gateway経由で実行できるようにすれば完成です。
色々と質問してみましたが、正確に回答してくれます!
まとめ
シンプルではありますが、インフラエンジニアの私でも、Amazon Bedrockを使うことで、簡単にRAGを使った生成AIアプリケーションの開発ができました!
みなさんもぜひAmazon Bedrockを触ってみて、便利さや性能の高さを実感してみてください。


Recommends
こちらもおすすめ
-

VSCode で Claude Code を使用する
2026.5.26
-

Amazon Bedrock 経由で Codex CLI を利用するまで
2026.6.11


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16