Amazon BedrockのKnowledge Baseを構築し、Claude 3 Haikuを使ってみた

はじめに
こんにちは、Shunです!
BedrockのKnowledge Baseはご利用されたことはありますか?
先日、Knowledge Baseを利用する機会があったのですが、非常に簡単に実装できたので、そのやり方をご紹介します!
Knowledge base for Amazon Bedrockとは
Amazon Bedrock のナレッジベースでは、データソースを情報のリポジトリにまとめることができます。ナレッジベースを使用すると、検索拡張生成 (RAG) を活用したアプリケーションを簡単に構築できます。RAG は、データソースから情報を取得することでモデルレスポンスの生成を強化する手法です。
出典: Knowledge bases for Amazon Bedrock
料金
Knowledge baseは、無料で利用することができます。
ただし、Knowledge Baseから呼び出されるモデルや使用するストレージの料金は発生します。
サポートリージョン
2024年4月19日時点でサポートされているリージョンは以下です。
- us-east-1 (バージニア北部)
- us-west-2 (オレゴン)
参考:Amazon Bedrock のナレッジベースでサポートされているリージョンとモデル
サポートファイル
2024年4月19日時点でサポートされているファイルは以下です。
- プレーンテキスト(.txt)
- マークダウン(.md)
- HTML(.html)
- Microsoft Word ドキュメント(.doc/docx)
- カンマで区切られた値(.csv)
- Microsoft Excel スプレッドシート(.xls/.xlsx)
- ポータブルドキュメント(.pdf)
構成図
今回実施する構成は以下の通りです。アプリの箇所は、Knowledge baseのテスト機能を使用します。
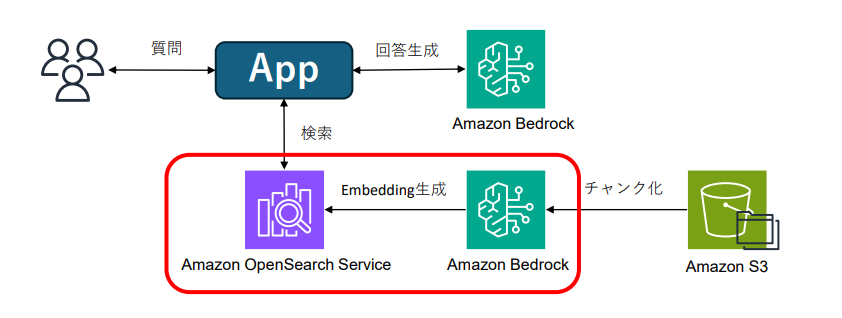
赤枠で囲んでいる箇所がKnowledge Baseで稼働しているサービスとなります。
環境構築
オレゴンリージョンで実施します。
1. S3の構築
Knowledge Baseのデータソースは、S3で作成します。
サポート対象のファイルをデータソースとして、アップロードしておいてください。
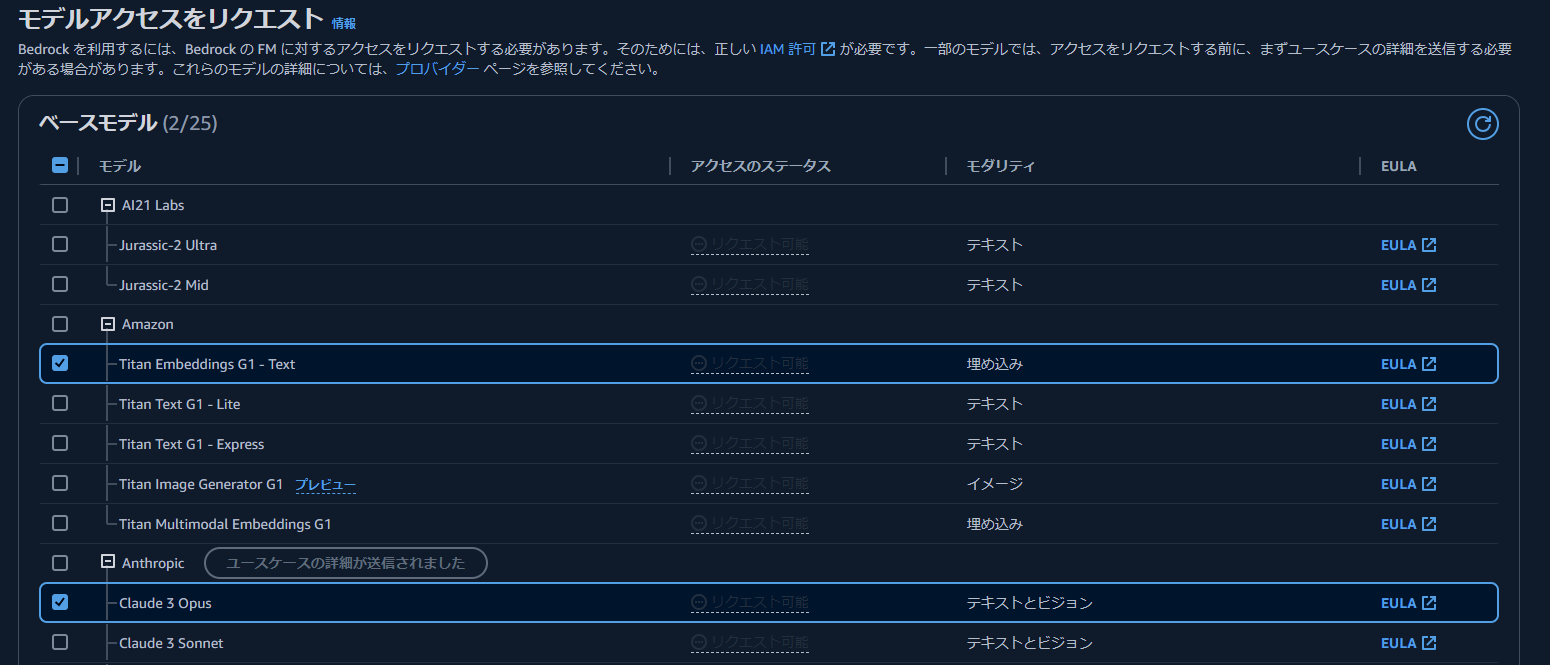
2. Bedrockのモデルアクセスを有効化
Knowledge Baseの作成前に、Bedrockのモデルを有効化します。
今回は、「Titan Embeddings G1 – Text」と「Claude 3 Haiku」を使用します。
(ナレッジベースからのテストにおいて、Claude 3 Opusが表示されなかったため、Haikuのモデルを使用します。)
3. Knowledge baseの構築
Bedrockのナビゲーションペイン下部の「ナレッジベース」を選択します。

ナレッジベースを作成します。
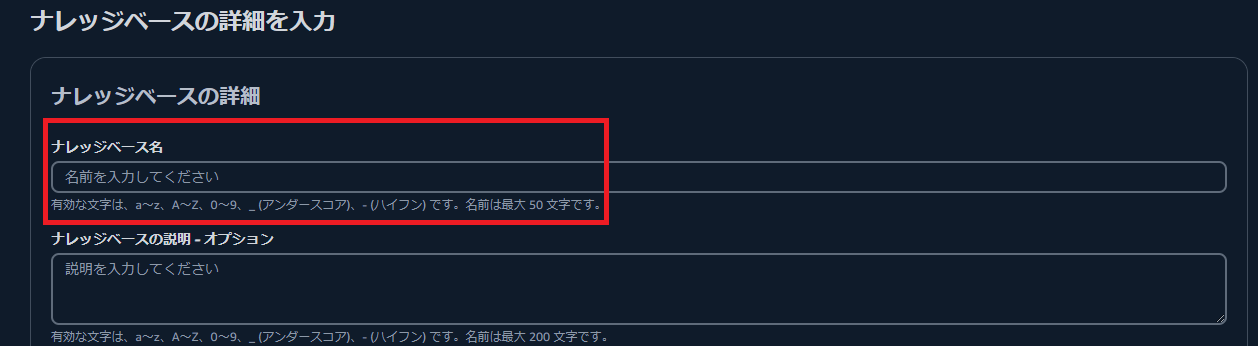
ナレッジベース名を入力します。IAMなどはデフォルト設定で問題ありません。
続いて、データソース名と先ほど作成したS3バケットを選択します。
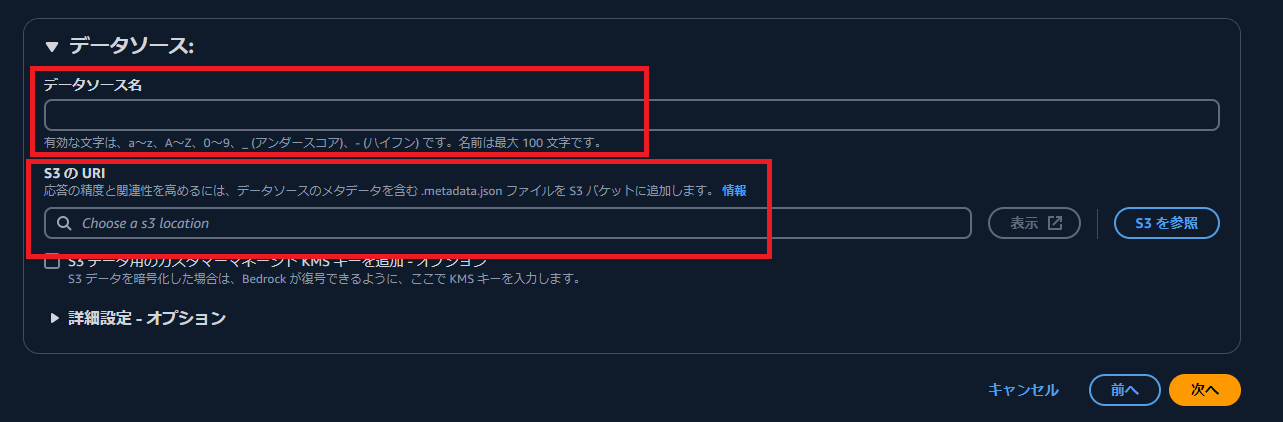
埋め込みモデルに「Titan Embeddings G1 – Text」を選択し、ベクトルデータベースは「クイック作成」を選択します。
このクイック作成により、S3のデータソースがEmbeddingされ、OpenSearch Serviceへ保管されます。
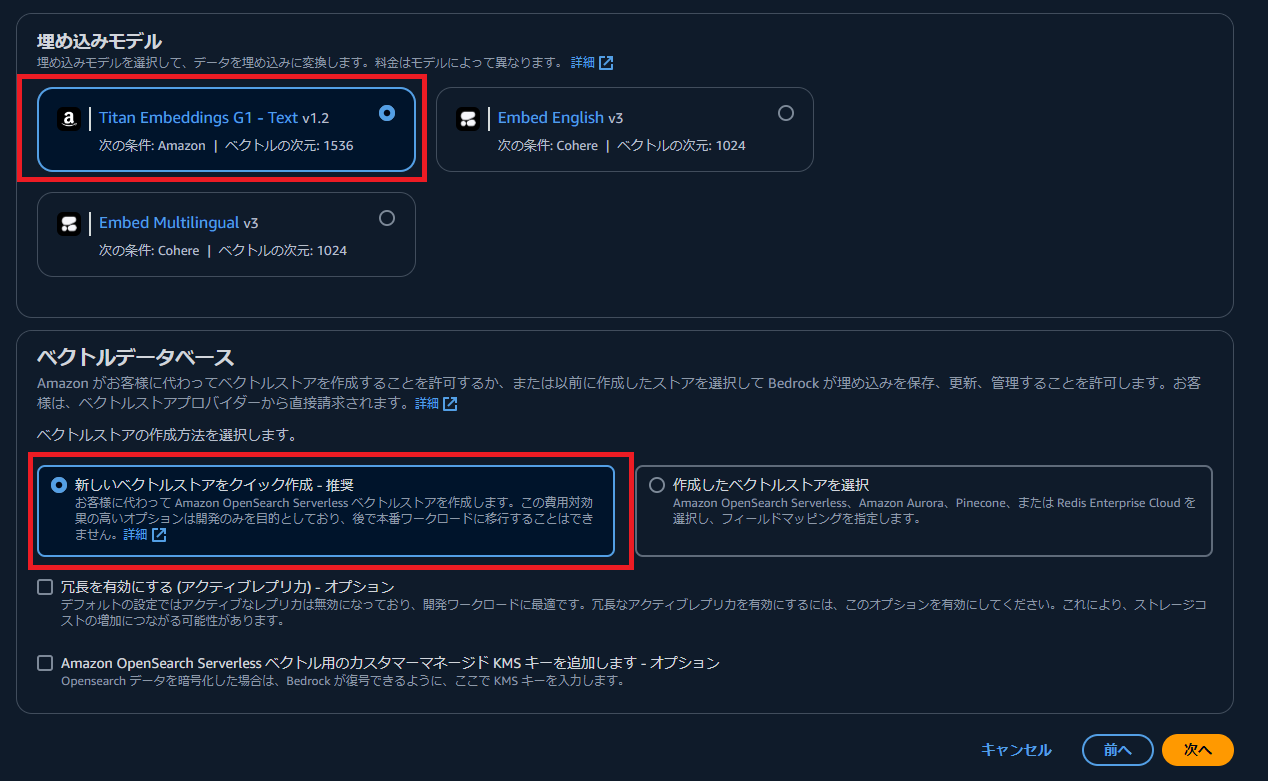
(もしエラーが発生した場合は、適切なモデルのアクセスが有効化されているかを確認してください。)
データソースの作成が完了したら、同期を実施します。

同期後、「ナレッジベースをテスト」が出てきますので、そこからモデルを選択します。
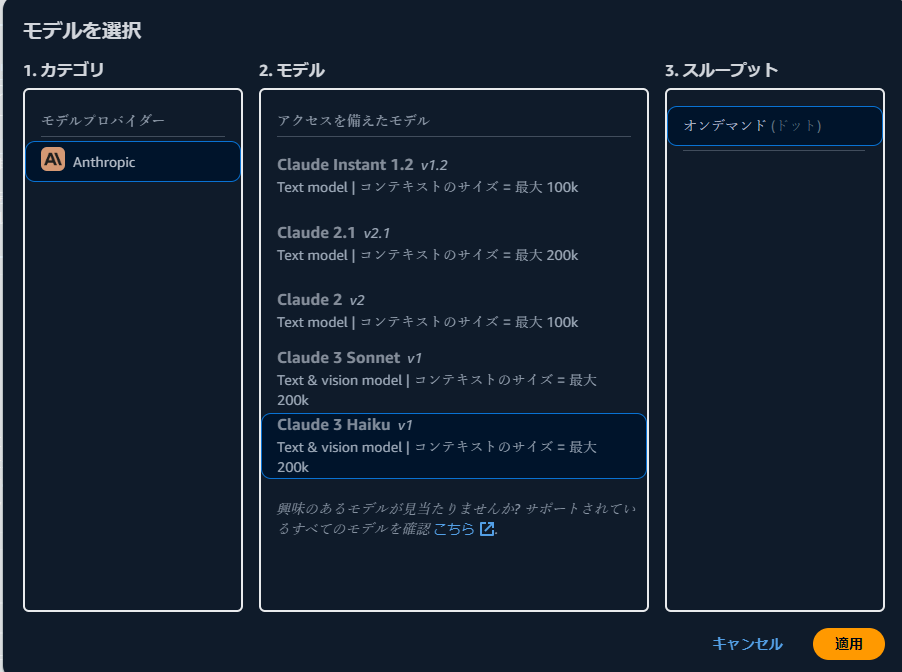
「Claude 3 Opus」を使おうと思っていたら、何故かここに表示されません。ここはまだプレビューなのかな。。
使えないものはしょうがないので、「Claude 3 Haiku」を選択します。
4. Knowledge baseを使って見る
私は、S3へNBA 2023-2024 レギュラーシーズンの成績をPDFとして格納しています。
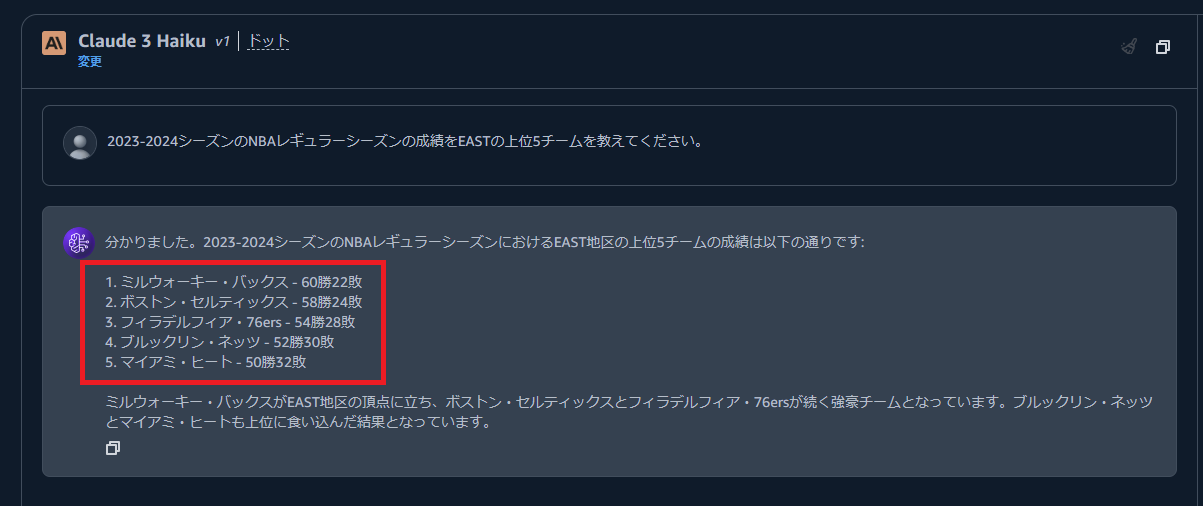
まず、Knowledge Baseを搭載していないBedrockに以下のことを聞いてみます。
2023-2024シーズンのNBAレギュラーシーズンの成績をEASTの上位5チームを教えてください。
実際の順位は以下です。
- ボストン・セルティックス – 64勝18敗
- ニューヨーク・ニックス – 50勝32敗
- ミルウォーキー・バックス – 49勝33敗
- クリーブランド・キャバリアーズ – 48勝34敗
- オーランド・マジック – 47勝35敗
出典: NBA日本公式サイト | 順位表
以下のように、回答は返ってきますが実際の結果とは異なり、ハルシネーションを起こしています。
次に、BedrockのKnowledge Baseを同期させたClaude 3 Haikuを使ってみます。
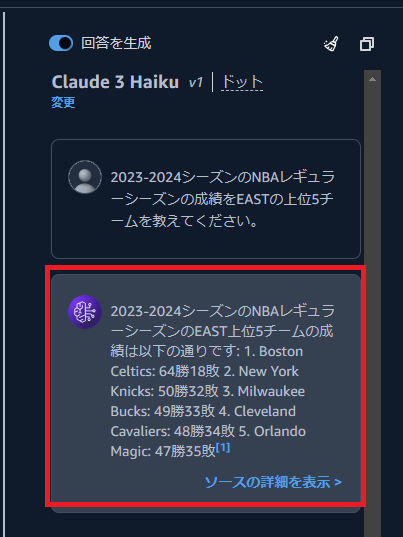
出力の形式は変わっていますが、正しい情報を出力することができました。
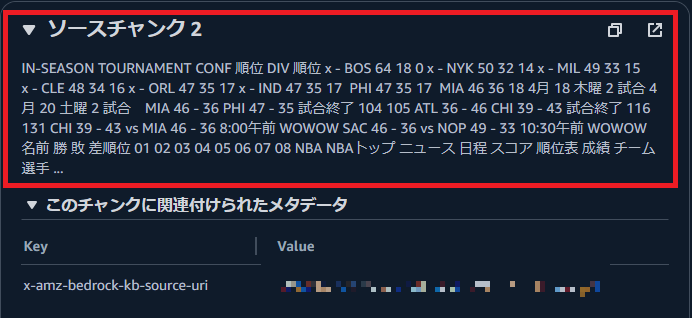
「ソースの詳細を表示」から元のドキュメントのどの箇所からデータを取得したのかを確認できます。
さいごに
今回、BedrockのKnowledge Baseを使用してRAGを作成する方法をご紹介しました。
環境構築は、S3へファイルを上げて、Bedrockと同期させるだけです。
非常に簡単に利用を開始でき、生成AIの弱点であるハルシネーションを抑制することができます!
一度、この便利さを皆さんも体験いただければ幸いです!
最後まで読んでいただきありがとうございます!
関連記事


Google Cloud Partner Top Engineer 2025、2024 AWS All Cert、ビール検定1冠


Recommends
こちらもおすすめ
-

Amazon CloudFrontでReactを動かす
2024.3.26


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16