[AWS re:Invent 2024] Amazon S3 Metadata (Preview) を試してみる

はじめに
re:Invent 2024でAmazon S3 Metadataが発表されました。こちらはS3 Tablesを使ってS3にあるオブジェクトデータの情報(メタデータ)にアクセスしやすくするサービスとなっています。数件であればマネジメントコンソールから確認すると思うのですが、それなりの量のS3のオブジェクトを探そうとすると、CLIやSDKを使って検索していると思います。
そのような場合、今回発表されたS3 Metadataを利用すると、登録済みのバケットのオブジェクトの情報が自動でS3 Tables上に書き込まれるようになり、Athenaなどを利用してS3のオブジェクトの検索が簡単になります。定期的にオブジェクトの検索を行なっている場合は、S3 Metadataを利用すると作業工数が減らせる可能性がありそうでした。
こちらは2025年1月現在でプレビューですが、概要を掴むために検証してみようと思います。最初にS3 Metadataの概要を確認した後に、構築を行います。その後CLIやクエリを実行して実際に使ってみます。
また機能の詳細は以下のセッションやAWS公式ページが詳しいので、一次情報を確認したい方は以下を参照してみて下さい。
参考: Amazon S3 Metadata (Preview)
概要
Amazon S3 Metadataは以下のような特徴があります。
Amazon S3 メタデータ (プレビュー) は、オブジェクト メタデータに簡単にアクセスでき、クエリも簡単に行えるようにすることで、S3 データの潜在能力を最大限に活用します。S3 に保存されているオブジェクトの豊富なメタデータを表示、保存、クエリすることで、ビジネス分析、リアルタイム推論アプリケーションなどに必要なデータをすばやく見つけることができます。S3 メタデータは、オブジェクトのサイズやソースなどのシステム定義の詳細を含むオブジェクト メタデータと、タグを使用して製品 SKU、トランザクション ID、コンテンツ評価などの情報をオブジェクトに注釈付けできるカスタム メタデータをサポートしています。出典: Amazon S3 Metadata (Preview)
またS3 Metadataは、同じくre:Invent 2024で発表されたS3 Tablesを利用しています。S3 Metadataについてより理解を深めたい場合は、S3 Tablesについても確認するとより理解ができるはずです。
参考: Amazon S3 Tables
構築してみる
ここからは実際にS3 Metadataを構築していきます。内容は以下のAWS公式ブログを参考にしています。
参考: Analyzing Amazon S3 Metadata with Amazon Athena and Amazon QuickSight
1. S3 Tablesの作成
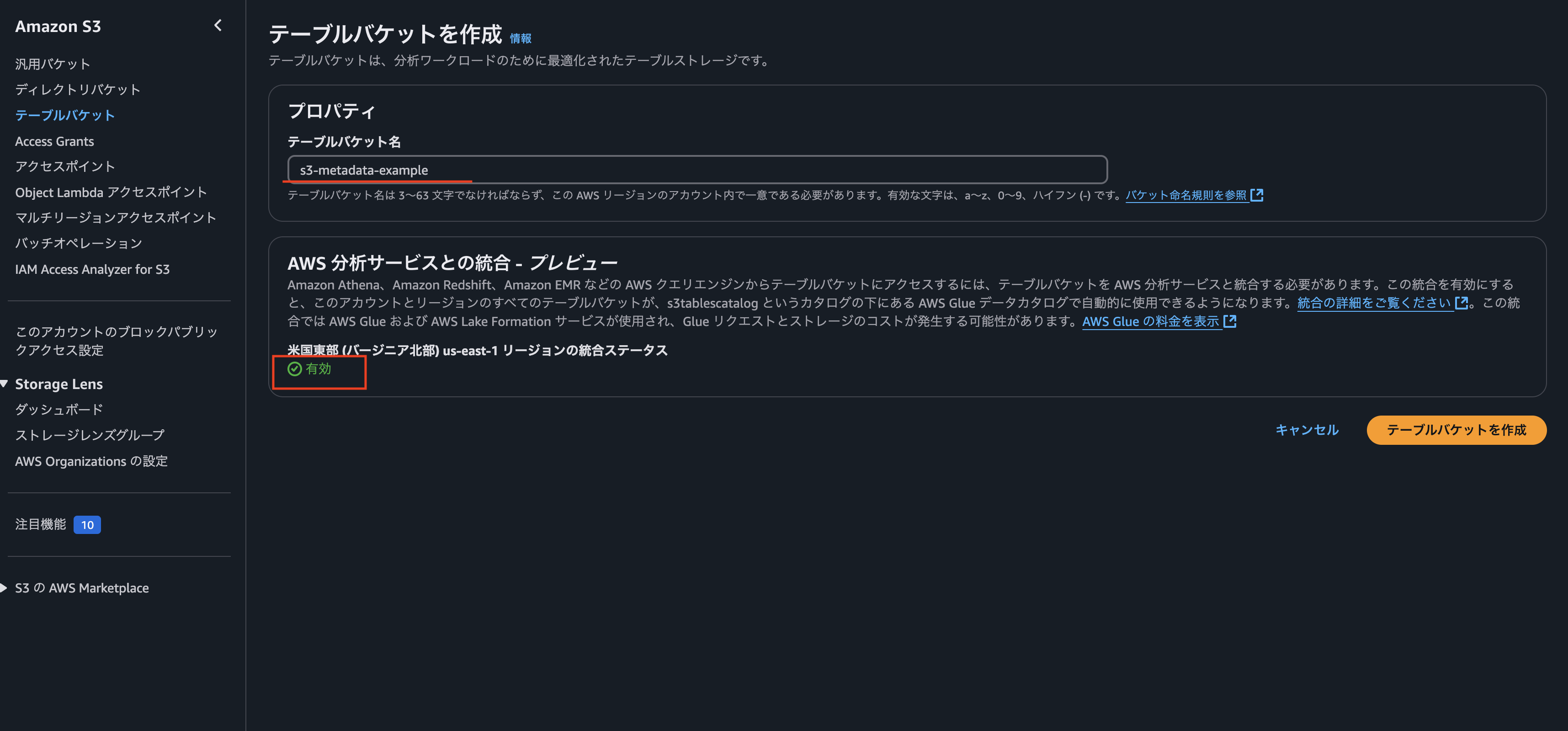
まずはMetadataを登録するためのテーブルバケットを作成します。2025年1月現在、東京リージョンではS3 Metadataは提供されていません。そのため今回はus-east-1(バージニア北部)で行っています。
もし「AWS 分析サービスとの統合 – プレビュー」を有効化していない場合は、まずこちらを有効化しましょう。S3 Tablesの検証などを行った人は、すでに有効化済みになっていると思います。
2. S3 Metadataの設定
検証用のバケットを作成して、そのバケットにS3 Metadataの設定をします。先ほど1で設定したテーブルバケットを設定しましょう。バケットもS3 Metadataが有効なリージョンに作成する必要があります。今回だとus-east-1に作成しています。

3. Lake Formationの設定
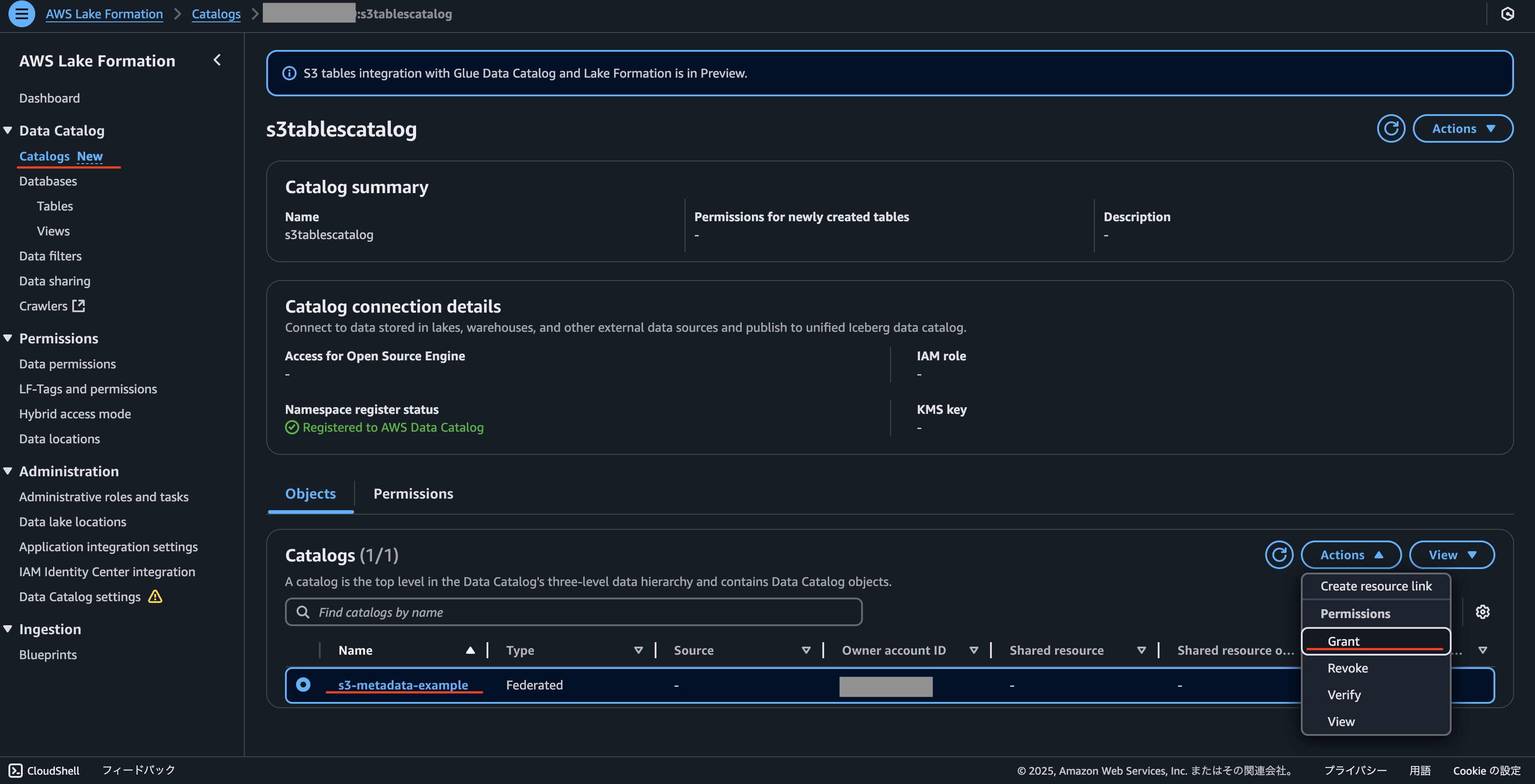
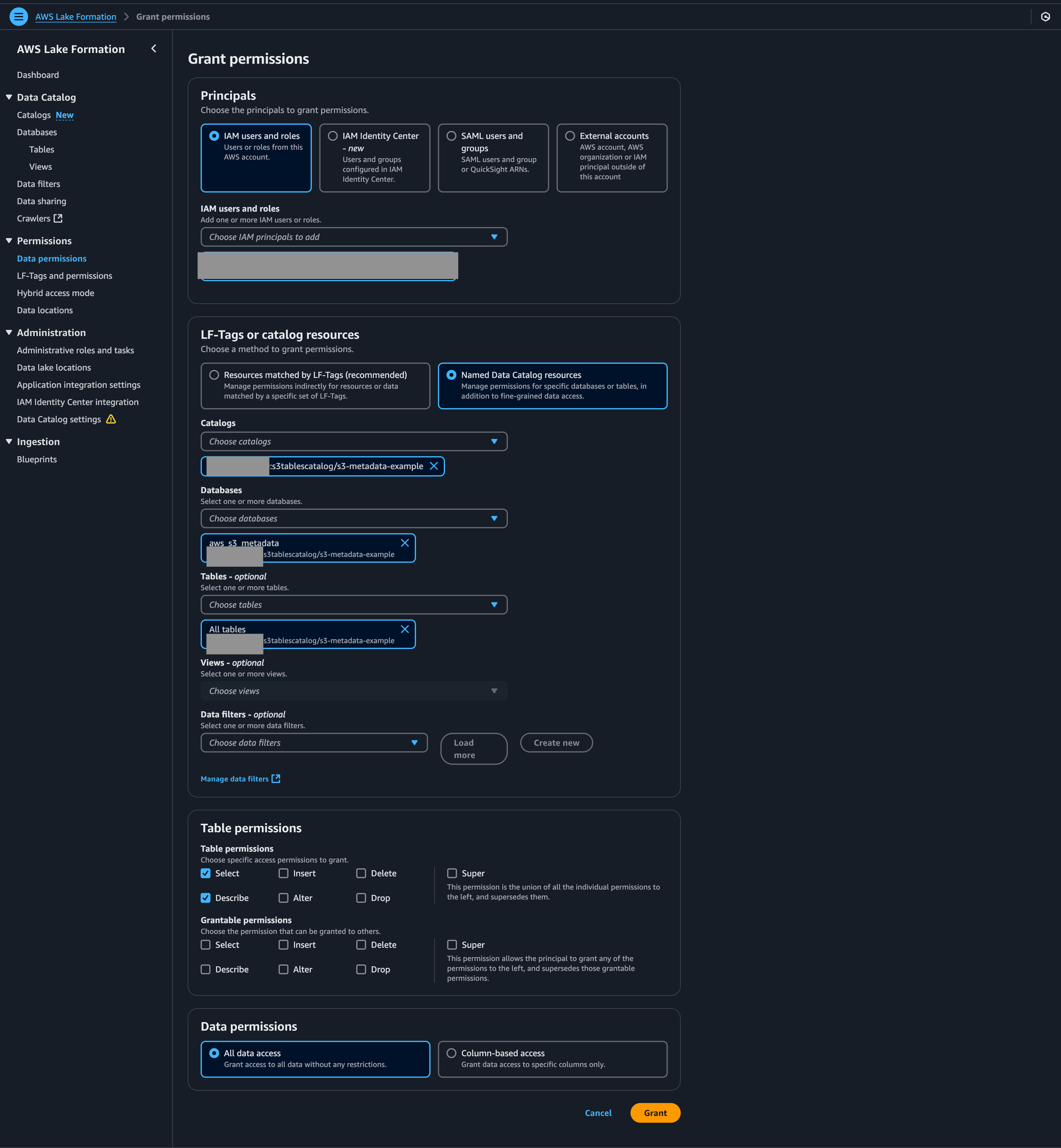
AthenaでS3 TablesをクエリするためにはLake Formationでクエリを実行する権限を設定する必要があります。
対象のページを開いて、今自分が使っているUser、またはRoleに対して、クエリを実行する権限を設定してみて下さい。
4. オブジェクトを追加する
S3 バケットにオブジェクトを追加して、レコードを作成します。
今回はテキストファイルを追加しています。
- sample001.txt
- sample002.txt
- sample003.txt
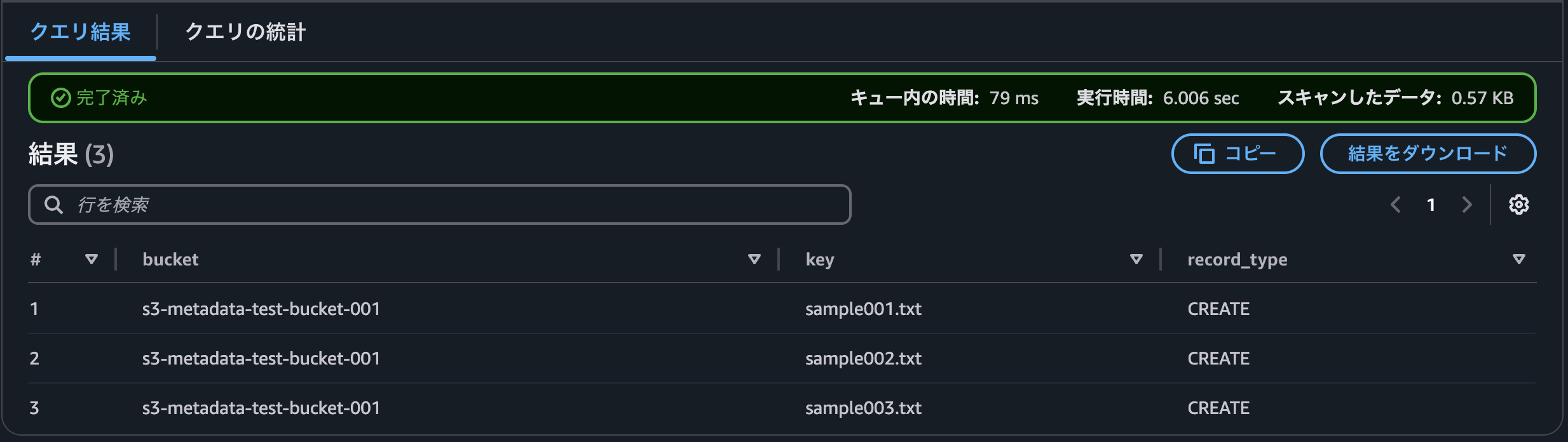
5. Athenaでクエリを実行する
クエリを実行して、レコードが追加されていることを確認します。
オブジェクトを追加して、レコードが反映されるまで10分ほどかかります。
SELECT
bucket,
key,
record_type
FROM
"aws_s3_metadata"."s3metadata_s3_metadata_test_bucket_001"
WHERE
bucket = 's3-metadata-test-bucket-001'
AND
record_type = 'CREATE'
AND
( key = 'sample001.txt' OR key = 'sample002.txt' OR key = 'sample003.txt' )
limit 10;
結果は以下になります。
もし作成できたらテーブルのスキーマを確認してみると良いです。S3 Metadataのスキーマは固定で、AWS側が自動で設定を行ってくれます。スキーマの詳細は以下で確認できます。
参考: S3 Metadata tables schema
検証してみる
1. データを追加する
以下の画像を手動でマネジメントコンソールからS3バケットに追加しました。検証のためにいろんな拡張子を準備しています。
- sample.txt
- sample.csv
- sample.json
- sample.parquet
- sample.png
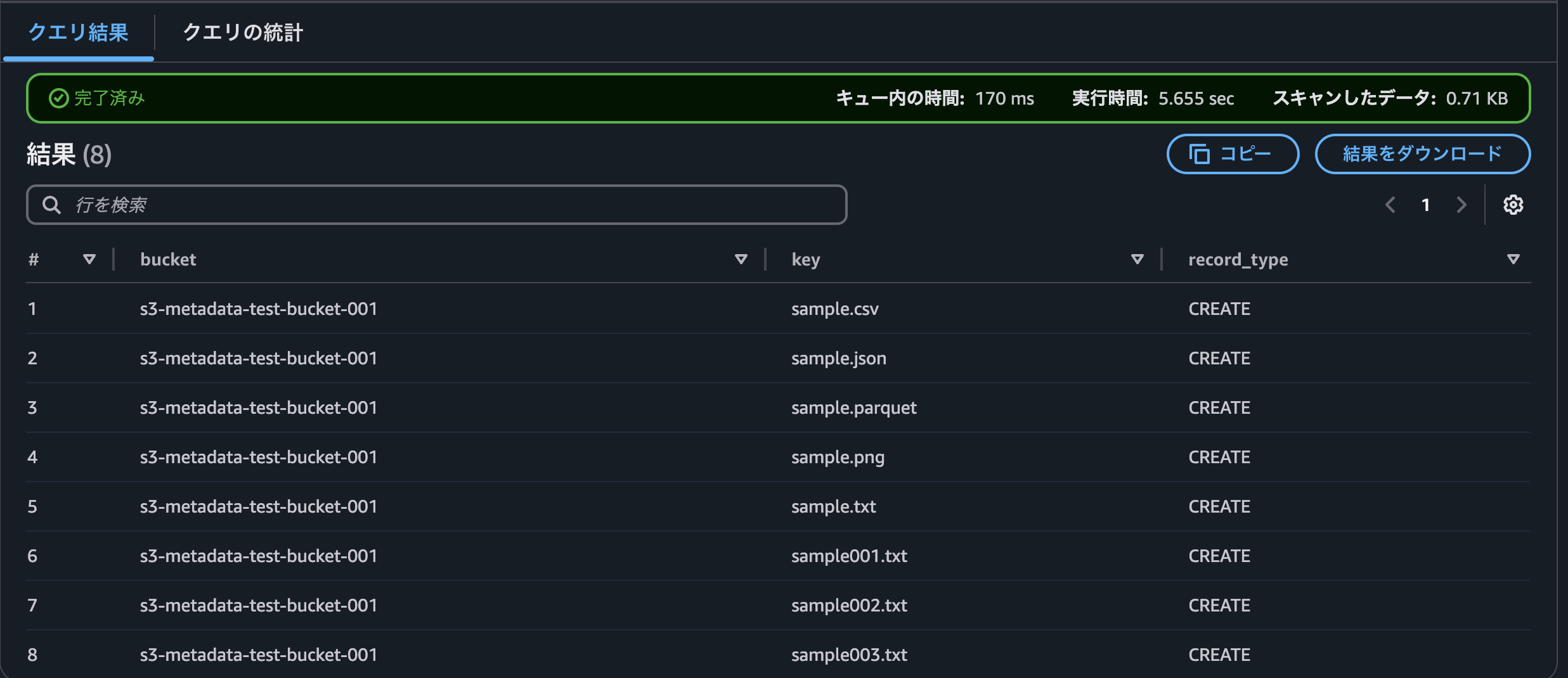
10分ほどした後に、作成したオブジェクトのレコードの追加が確認できました。
レコードの反映は現時点だとそこまで早くはないようです。
SELECT
bucket,
key,
record_type
FROM
"aws_s3_metadata"."s3metadata_s3_metadata_test_bucket_001"
WHERE
bucket = 's3-metadata-test-bucket-001'
AND
record_type = 'CREATE'
limit 10;
2. タグを追加する
次にオブジェクトにタグを追加してみます。
$ aws s3api put-object-tagging \
--profile xxx \
--region us-east-1 \
--bucket s3-metadata-test-bucket-001 \
--key sample.json \
--tagging '{"TagSet": [{ "Key": "createdBy", "Value": "admin" }]}'
以下をAthenaで実行します。
SELECT
bucket,
key,
record_type,
object_tags
FROM
"aws_s3_metadata"."s3metadata_s3_metadata_test_bucket_001"
WHERE
key = 'sample.json'
limit 10;
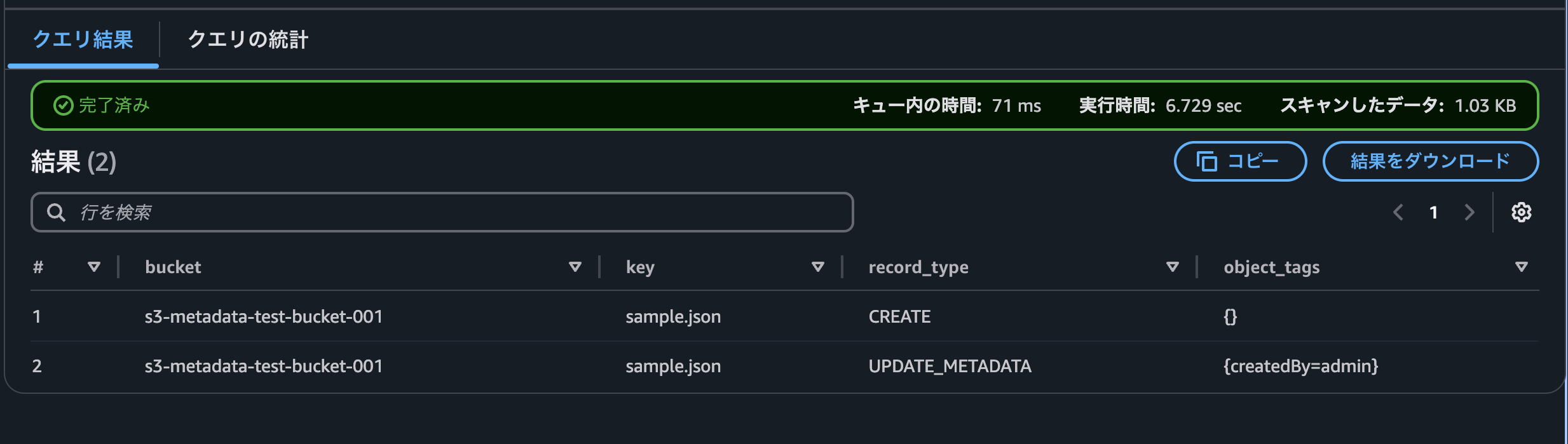
約10分後にUPDATE_METADATAのレコードが追加されていました。またobject_tagsに今回追加したタグが追加されていました。
3. データを削除する
次にデータを削除してみます。
$ aws s3api delete-object \ --profile xxx \ --region us-east-1 \ --bucket s3-metadata-test-bucket-001 \ --key sample.csv
以下をAthenaで実行します。
SELECT
bucket,
key,
record_type,
size,
storage_class
FROM
"aws_s3_metadata"."s3metadata_s3_metadata_test_bucket_001"
WHERE
key = 'sample.csv'
limit 10
結果は以下になりました。約10分後にDELETEのレコードが追加されていました。またDELETEレコードにはsizeやstorage_classなど必須カラムではないデータは含まれていませんでした。
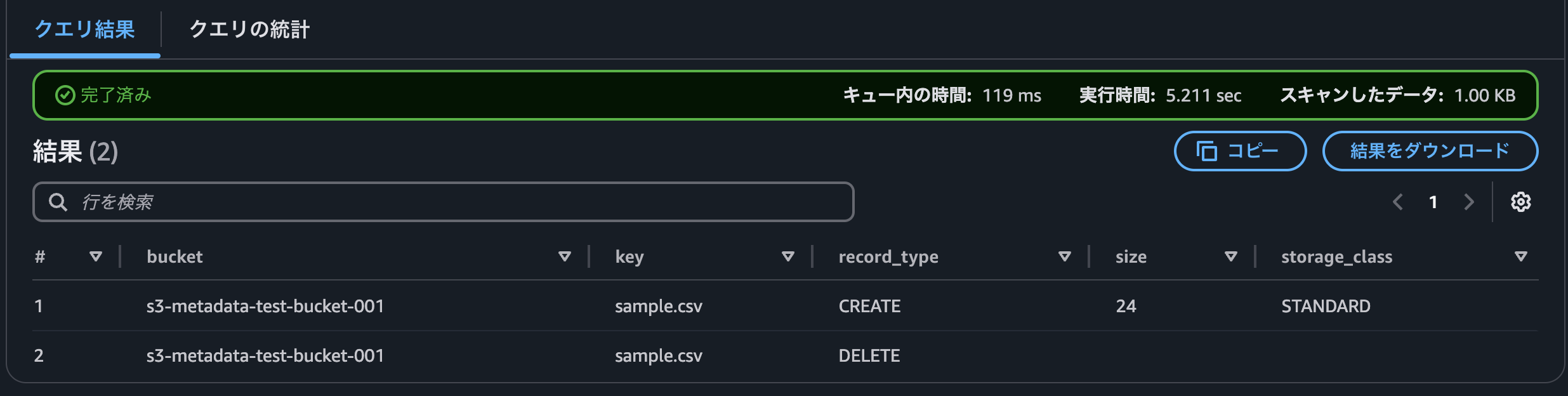
削除されたレコードの詳細を知るためには、record_typeがCREATEまたはUPDATE_METADATEのレコードとJOINして確認する必要がありそうでした。またUPDATE_METDATAはCREATEのレコードと同じく全てのカラムに値が入っていました。
どのカラムが必須なのかは以下から確認ができます
参考: S3 Metadata tables schema
4. 削除されたオブジェクトのsizeとstorage_classを確認する
DELETEされた情報を捕捉するためのJOINをするクエリを実行してみました。
WITH a AS (
SELECT
key,
size,
storage_class,
record_timestamp
FROM
s3metadata_s3_metadata_test_bucket_001
WHERE
bucket = 's3-metadata-test-bucket-001'
AND
record_type = 'CREATE'
),
b AS (
SELECT
key,
record_timestamp
FROM
s3metadata_s3_metadata_test_bucket_001
WHERE
bucket = 's3-metadata-test-bucket-001'
AND
record_type = 'DELETE'
)
SELECT
a.key,
a.size,
a.storage_class,
a.record_timestamp AS create_record_timestamp,
b.record_timestamp AS delete_record_timestamp
FROM
b
LEFT OUTER JOIN a ON b.key = a.key
ORDER BY b.record_timestamp
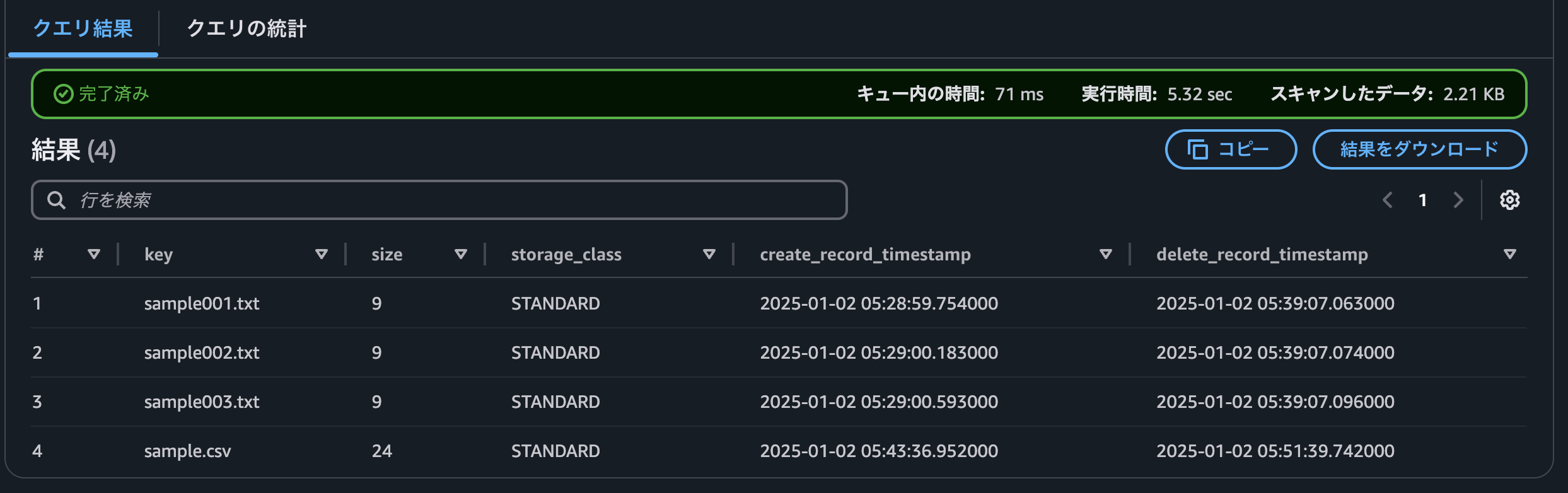
一覧が確認できました。(sample001.txt, sample002.txt, sample003.txtも裏で削除していたので、クエリに表示されています)
SQLのサンプルについては、AWS公式ブログの方にいろいろ載っているので、こちらも読んでみて下さい。
Analyzing Amazon S3 Metadata with Amazon Athena and Amazon QuickSight
制限と制約について
ドキュメントを読むといくつか気になる点もありました。動画やブログでは記載されていない情報も多いため、検証をする人は以下のページを読んでみると詳細を確認することができます。いくつか気になったポイントを記載します。
S3 メタデータは、メタデータ テーブル設定を作成する前に汎用バケットにすでに存在していたオブジェクトには適用されません。
既存のデータには適用されないようでした。次のアクションから適用されるそうです。
メタデータ テーブルは読み取り専用であるため、メタデータ テーブル内のレコードを削除することはできません。
S3 Metadataのテーブルはユーザー側からレコードの操作はできないそうです。
メタデータ テーブル構成は、汎用バケット全体に対してのみ作成できます。プレフィックス レベルでメタデータ テーブル構成を適用することはできません。
対象はバケット単位になりそうです。S3 Metadataを利用したい場合はバケット単位で構成を検討する必要がありそうです。
参考: Metadata table limitations and restrictions
料金について
2025年1月現在、us-east-1で100万回の更新につき0.45ドルとありました。1回の変更をすると1レコードが追加されるため、1アクションごとに1回分の値段と考えて良さそうです。
また料金は以下から確認できます。
参考: Amazon S3 pricing > Management & insights > Storage management > S3 Metadata (Preview) pricing
まとめ
今回はAmazon S3 Metadataの概要を確認した後に実際に環境を構築して、その後簡単にデータを操作してみました。
オブジェクト作成後にレコードは基本的に5~10分後に反映されます。こちらは現時点だとそこまで早くはないので反映速度が求められる事例には向いてなさそうでした。また既存のオブジェクトが変更されると、既存のレコードが更新されるのではなく、データの更新ごとに新しいレコードがINSERTされる仕組みになっていました。またユーザー側からテーブルのレコードの追加、削除はできないことも確認できました。
2025年1月現在、プレビューの機能ですが、S3にあるデータの管理に課題を抱えている場合は一度検証してみる価値はあると思います。私の場合LambdaなどからS3のデータを確認しようとすると、まずSDKなどからLISTをして、その後S3のkeyを正規表現でチェックして対象を選ぶ、といったことをしていました。SQLが使えるとこのようなデータを探す過程が工夫できそうなので、正式リリースされた際は再度仕様を確認してみようと思います。

2018年新卒入社。エンジニア。フロントエンド&サーバサイドを担当。 Vue.js, Ruby on Rails, Ruby, Javaを主に使用する。 会社では全力で働き、家では全力で遊ぶ。


Recommends
こちらもおすすめ
-

Amazon SageMaker Debuggerを試してみる
2019.12.25
-

無料で使えるAWSの初期トレーニングまとめ
2015.12.15
-

AWSとWordPressで企業Webサイトを構築する
2019.5.16



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16