【生成 AI】Llama 3.2 が Google Cloud で利用できるようになりました #Vertex AI
2024.9.30

はじめに
こんにちは、フクナガです。
この度、Meta社が提供する基盤モデル「Llama 3.2」が Google Cloud で利用可能となりました。
参考:Meta’s Llama 3.2 is now available on Google Cloud
私のブログで Llama を取り扱ったことがないので、基本的な情報とともに利用方法をご案内していきたいと思います!
Llama 3.2 とは
Meta 社が提供する基盤モデルです。性能の高さから話題になることも多いですが、日本語性能のLLMである「Llama-3-ELYZA-JP」のベースとなったモデルとしても取り上げられています。
Gemini や Claude と並び、覚えておきたい基盤モデルの1つですね!
ちなみに Claude の利用方法についても記事化しているので、興味のある方はぜひチェックしてみてください!
【生成 AI】Claude 3.5 SonnetをGoogle Cloudで使ってみた #Vertex AI
Llama 3.2 の魅力
- 画像推論などマルチモーダルでの利用が可能
視覚理解の力が求められるタスクにおいて、他社基盤モデルの Claude 3 Haiku や GPT-4o mini と競合するパフォーマンスを達成しています。 - 軽量ながら高パフォーマンスを実現した1Bや3Bモデルの提供
参考:Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
様々なドキュメントから特長を調べましたが、「画像推論などのマルチモーダル機能」がアップデートの目玉だったようです。
Llama 3.2 を使い始めるまで
1. 下記へアクセスし、規約に合意する

2. 「Llama 3.2 API Service」を有効化する
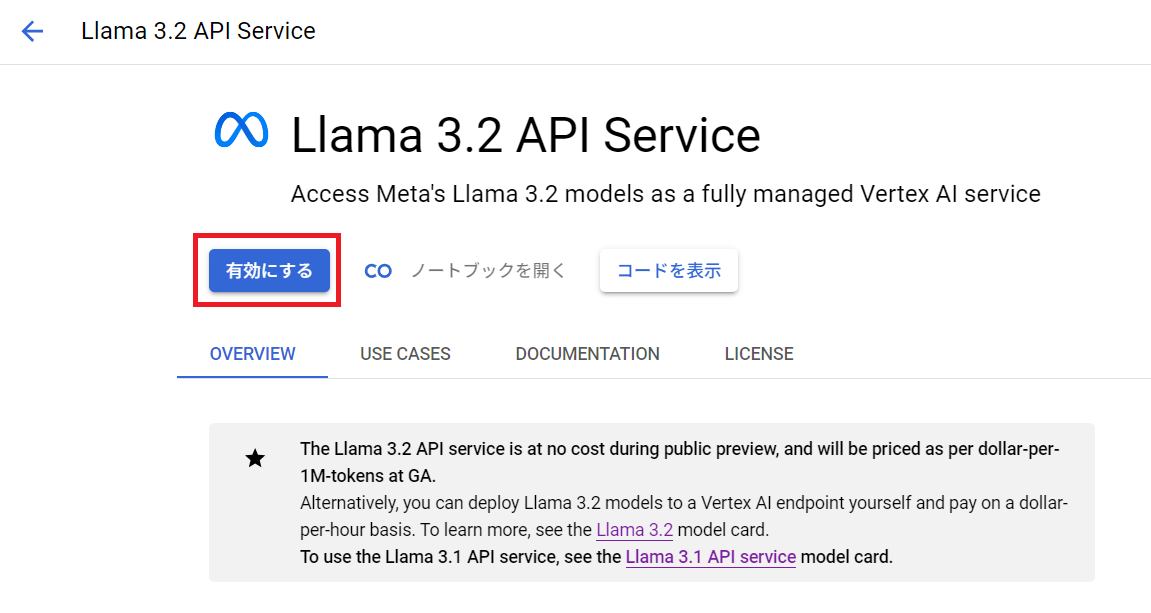
※有効化されない場合は少し下にスクロールして右上に表示される「有効にする」を押下することで、有効化できることがございます
3. 右側にある「プレイグラウンド」を使って、有効化できているか確認する
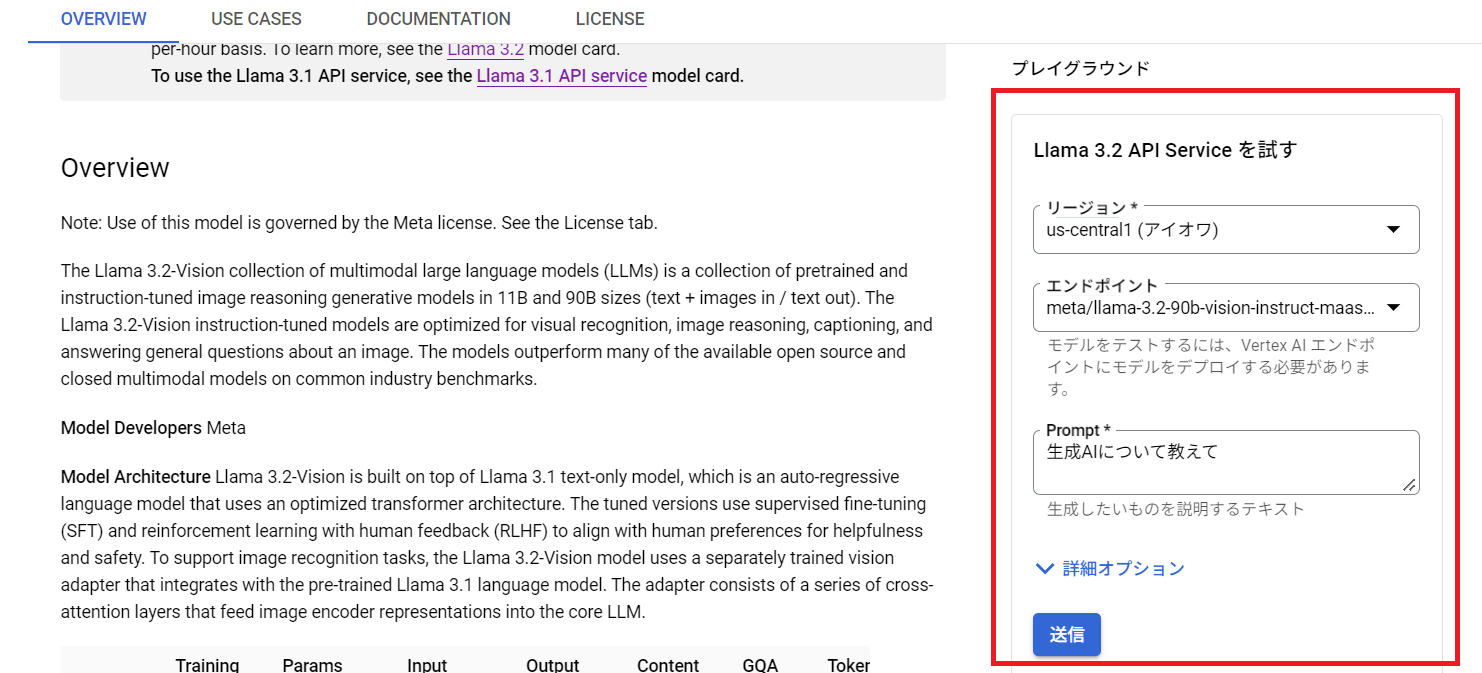
Llama 3.2 を使ってみた
公式のドキュメントに Cloud Shell での実行方法が案内されていましたので、そちらで試してみます!
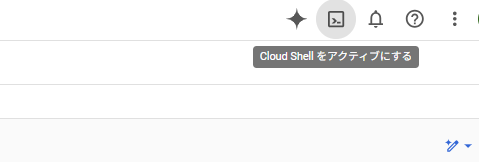
1. コンソール右上の「Cloud Shell をアクティブにする」アイコンを押下
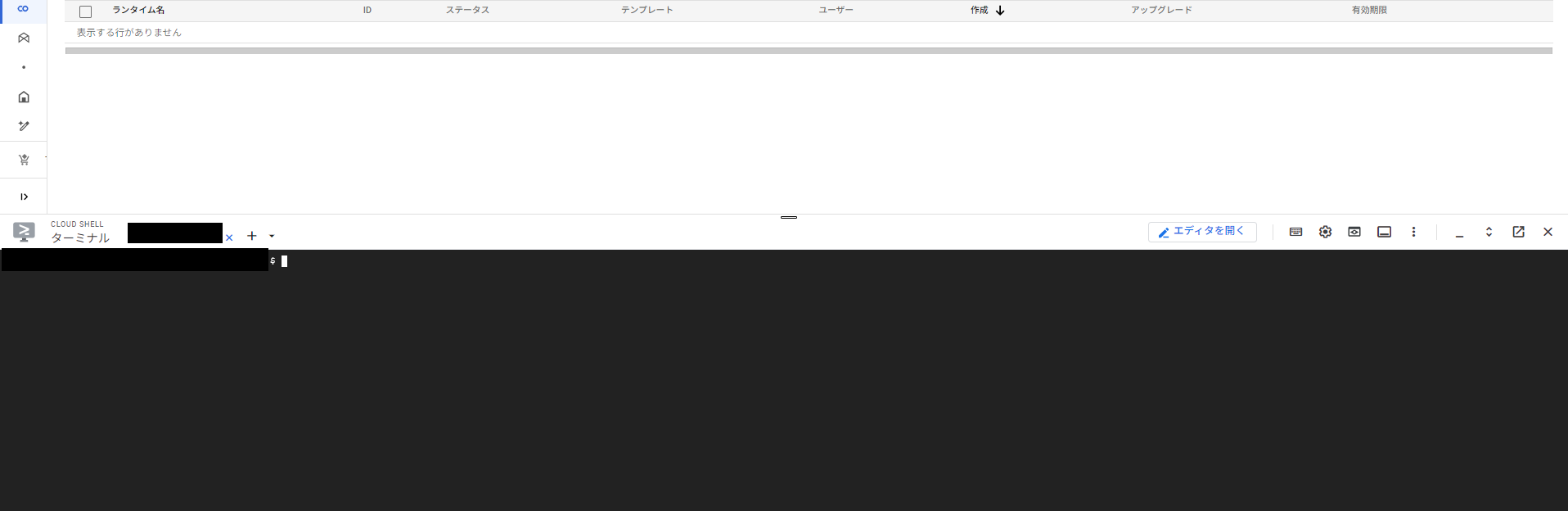
正常に実行されると画面下部にCLIの実行画面が表示されます。
2. 下記のコマンドを実行し、環境変数を登録する
ENDPOINT=us-central1-aiplatform.googleapis.com REGION=us-central1 PROJECT_ID="YOUR_PROJECT_ID"
※「”YOUR_PROJECT_ID”」は、ご自身のGoogle Cloud プロジェクト ID に置き換えてください。
3. サンプルコードを実行する
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" https://${ENDPOINT}/v1beta1/projects/${PROJECT_ID}/locations/${REGION}/endpoints/openapi/chat/completions \
-d '{"model":"meta/llama-3.2-90b-vision-instruct-maas","stream":false, "messages":[{"role": "user", "content": [{"image_url": {"url": "gs://github-repo/img/gemini/intro/landmark3.jpg"}, "type": "image_url"}, {"text": "What’s in this image?", "type": "text"}]}], "max_tokens": 40,"temperature":0.4,"top_k":10,"top_p":0.95, "n":1}'
コロッセオの画像を入力し、「画像内に何が入っているのか?」というプロンプトを実行するという内容です。
入力に使った画像
※実行時に下記のポップアップが表示されますので、「承認」を押下してください。
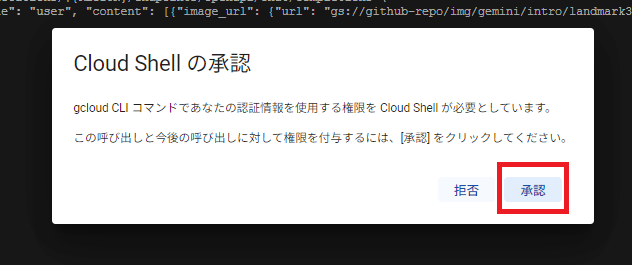
結果確認
下記が出力されました。
{"choices":[{"finish_reason":"length","index":0,"logprobs":null,"message":{"content":"The image depicts the Colosseum, a historic amphitheater in Rome, Italy. The structure is illuminated from within, with warm orange lights visible through its many arches and windows. The","role":"assistant"}}],"model":"meta/llama-3.2-90b-vision-instruct-maas","object":"chat.completion","system_fingerprint":"","usage":{"completion_tokens":36,"prompt_tokens":264,"total_tokens":300}}
※一部省略しています
返答文の箇所を抜き出してみます。
The image depicts the Colosseum, a historic amphitheater in Rome, Italy. The structure is illuminated from within, with warm orange lights visible through its many arches and windows.
[日本語訳]
画像は、イタリアのローマにある歴史的な円形劇場であるコロッセオを描いています。構造物は内部から照らされており、多くのアーチや窓を通して暖かいオレンジ色の光が見えます。
コロッセオの画像であることを認識し、その他の要素も説明してくれていますね。
マルチモーダルなモデルの模範的なユースケースです。
ユースケースごとにカスタムしてみた
①文字だけでリクエストを送る
先ほどご紹介したデモでは、「画像の解析をする」というユースケースが取り扱われていました。
しかし、生成 AI のメインのユースケースは、「文章を送って文章が返ってくる」というユースケースだと思います。
その場合のリクエスト例を記載します。
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" https://${ENDPOINT}/v1beta1/projects/${PROJECT_ID}/locations/${REGION}/endpoints/openapi/chat/completions \
-d '{"model":"meta/llama-3.2-90b-vision-instruct-maas","stream":false, "messages":[{"role": "user", "content": [ {"text": "What is gen ai?", "type": "text"}]}], "max_tokens": 500,"temperature":0.4,"top_k":10,"top_p":0.95, "n":1}'
上記のリクエストでは「What is gen ai?」という質問を Llama 3.2 にしているユースケースとなります。
その文言部分を変更して適宜利用してみてください。
もちろん、変数も利用可能です。
prompt="What is gen ai? Answer within 100 words."
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" https://${ENDPOINT}/v1beta1/projects/${PROJECT_ID}/locations/${REGION}/endpoints/openapi/chat/completions \
-d '{"model":"meta/llama-3.2-90b-vision-instruct-maas","stream":false, "messages":[{"role": "user", "content": [ {"text": "'"$prompt"'", "type": "text"}]}], "max_tokens": 500,"temperature":0.4,"top_k":10,"top_p":0.95, "n":1}'
実行した結果、下記が返ってきました。
Gen AI, short for Generative Artificial Intelligence, refers to a type of artificial intelligence that can generate new content, such as text, images, music, or videos, based on patterns and structures it has learned from existing data. Gen AI models use complex algorithms and machine learning techniques to create novel outputs that are often indistinguishable from those created by humans. Examples of Gen AI include language models like ChatGPT, image generators like DALL-E, and music generators like Amper Music. Gen AI has the potential to revolutionize various industries, including art, entertainment, and education.
[日本語訳]
「Gen AI」は「生成的人工知能」の略であり、既存のデータから学んだパターンや構造に基づいて、テキスト、画像、音楽、ビデオなどの新しいコンテンツを生成できる人工知能の一種を指します。Gen AIモデルは、複雑なアルゴリズムと機械学習技術を使用して、新しい出力を作成しますが、これらはしばしば人間が作成したものと区別がつかないことがあります。Gen AIの例としては、ChatGPTのような言語モデル、DALL-Eのような画像生成器、Amper Musicのような音楽生成器があります。Gen AIは、芸術、エンターテインメント、教育を含むさまざまな産業を革新する可能性を秘めています。
任意の画像で試してみる
Cloud Storage に配置した画像を Llama 3.2 に読み込ませてみようと思います!
今回は、下記のブログのサムネになった社員3人で撮った写真です。

リクエスト例を記載します。
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" https://${ENDPOINT}/v1beta1/projects/${PROJECT_ID}/locations/${REGION}/endpoints/openapi/chat/completions \
-d '{"model":"meta/llama-3.2-90b-vision-instruct-maas","stream":false, "messages":[{"role": "user", "content": [{"image_url": {"url": "gs://[Cloud Storage上のパスとファイル名を入力]"}, "type": "image_url"}, {"text": "What’s in this image?", "type": "text"}]}], "max_tokens": 500,"temperature":0.4,"top_k":10,"top_p":0.95, "n":1}'
Cloud Storageのパスとファイル名は下記のように記載します。
gs://sample-folder/test/aaa.jpg
実行した結果、下記が返ってきました。
The image depicts three men sitting on a bench, with the man in the middle wearing a white t-shirt that reads \”FCHORUS\” and the other two men wearing similar shirts with the word \”CHORUS\” printed on them. The men are all dressed in casual attire, with the man on the left wearing gray pants and the man on the right wearing blue shorts. They are all wearing white sneakers with blue laces.\n\nIn the background, there are plants and a cityscape visible through a window behind the men. The overall atmosphere of the image suggests that the men are posing for a photo or participating in some kind of promotional event.
[日本語訳]
画像には、ベンチに座っている3人の男性が描かれています。中央の男性は「FCHORUS」と書かれた白いTシャツを着ており、他の2人の男性は「CHORUS」と書かれた似たようなシャツを着ています。男性たちは全員カジュアルな服装をしており、左の男性はグレーのパンツを、右の男性は青いショーツを履いています。彼らは全員、青い靴ひもが付いた白いスニーカーを履いています。
背景には、男性たちの後ろの窓を通して植物や都市の景観が見えます。画像全体の雰囲気は、男性たちが写真撮影のためにポーズをとっているか、何らかのプロモーションイベントに参加していることを示唆しています。
ちなみに、Tシャツに書かれていた「TECHORUS」を「FCHORUS」と勘違いして理解していたのですが、画像の解像度的にそう見えてもしょうがないなという感じでした!

逆に精度の高さを証明したかもしれませんね!
まとめ
今回のブログでは、Llama 3.2 の概要と Google Cloud での利用方法をご紹介しました。
様々なモデルを使えることで、ユースケースごとにどのモデルの精度が高いかなどの比較がしやすくなると思います。
これを機に、Llama も積極的に使っていこうと思いました!

2025 Japan AWS Ambassadors / Google Cloud Partner Top Engineer 2026 / Google Cloud Partner Top Engineer 2025 / 2024 Japan AWS Top Engineers 選出されました! 生成 AI 多めで発信していますが、CI/CDやIaCへの関心も高いです。休日はベースを弾いてます。


Recommends
こちらもおすすめ
-
企業内の各事業部門における生成AIの活用方法
2024.8.9



{kind=link}
Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16