BigQueryからGeminiを呼び出し、テーブルのデータを分類させてみた
2024.4.8

はじめに
こんにちは、Shunです。
皆さん、生成AIを利用していますか?
文章の要約、校正やプログラムコードの書き換えなど、多種多様な利用方法が一般的になってきました。
今回は、生成AIを活用する一つの方法として、テーブル内のデータを分類させることに焦点を当てます。
これを実現するために、Google Cloudが提供するBigQueryとGeminiを使用します。
参考: リモートモデルと ML.GENERATE_TEXT 関数を使用してテキストを生成する
Geminiとは
GeminiはGoogleが開発した汎用性と高性能を兼ね備えた最新のAIモデルです。
テキスト、画像、音声、動画、コードなど、多様な種類の情報を理解、操作できるマルチモーダル機能を持ち、複雑な問題解決能力が特徴です。Geminiは、データセンターからモバイルデバイスまで幅広い環境で効率的に動作し、開発者や企業がAIを使った新しいアプリケーションの開発を強化します。
参考: 最大かつ高性能 AI モデル、Gemini を発表 – AI をすべての人にとってより役立つものに
料金
Gemini Proの料金は、以下の通りです。
画像入力: $0.0025 / 画像
ビデオ入力: $0.002 / 秒
テキスト入力: $0.000125 / 1,000 文字
実装手順
1. データセットの準備
今回は、ビールを販売している酒店のレビューを分析する。というシナリオで実施します。
データセットは以下の通りです。(もちろん、これも生成AIによって作成しました)
田川市,キリンラガービール,2024-09-08,2024-09-12,少し価格が高い。 福津市,アサヒスーパードライ,2024-04-09,2024-04-10,香ばしい麦の味が楽しめる。 小郡市,アサヒスーパードライ,2024-01-24,2024-01-28,苦味が強めで好みが分かれるかも。 大牟田市,キリン一番搾り,2024-03-08,2024-03-10,香り高く、後味がすっきりしている。 小郡市,キリン一番搾り,2024-10-27,2024-11-01,友達とワイワイ飲むのに最適! 大野城市,キリン一番搾り黒生,2024-08-04,2024-08-05,軽い口当たりだが、味わいはしっかり。 田川市,キリンラガービール,2024-07-06,2024-07-07,パッケージからすぐに購入を決めました。 うきは市,アサヒザ・リッチ,2024-01-14,2024-01-16,飲み飽きない味わいでリピートしている。 大野城市,サッポロクラシック,2024-01-19,2024-01-23,コスパが高くて嬉しい。 中間市,キリン一番搾り,2024-01-01,2024-01-06,ブランドの雰囲気が好きです。 朝倉市,アサヒスーパードライ,2024-03-01,2024-03-06,CMに出ている八村塁選手の影響で購入しました。 みやま市,サッポロエーデルピルス,2024-01-11,2024-01-12,独特の甘みがあり、ビール苦手な人にも。 北九州市,アサヒドライブラック,2024-06-18,2024-06-21,バランスが良く、どんな場面でも楽しめる。 宮若市,サッポロ黒ラベル,2024-07-24,2024-07-27,クリーミーな泡が特徴的。 嘉麻市,サントリーゴールデンエール,2024-11-13,2024-11-14,もう少し安く販売してほしいです。 久留米市,キリン一番搾り黒生,2024-05-07,2024-05-08,冷え冷えにして飲むと最高。 飯塚市,キリン一番搾り黒生,2024-09-19,2024-09-20,缶デザインがおしゃれで、ギフトにも最適。 柳川市,サントリープレミアムモルツ,2024-04-20,2024-04-22,缶に穴が開いていました。 みやま市,キリンラガービール,2024-03-17,2024-03-19,色が美しく、見た目にも楽しめる。 太宰府市,アサヒドライブラック,2024-10-19,2024-10-24,前はもっと安かったような気がします。 大野城市,アサヒザ・リッチ,2024-01-04,2024-01-09,ホップの香りが強く、ビール好きにはたまらない。
2. BigQueryの設定
まず、BigQueryのデータセットを作成します。
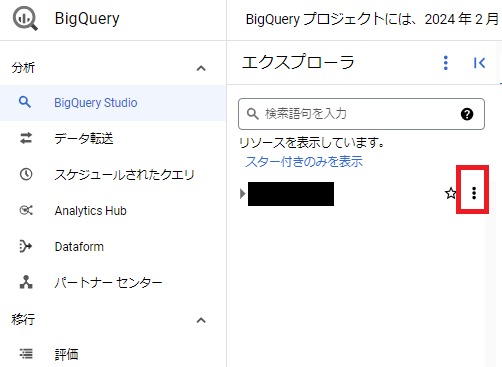
設定は以下の通り、行います。
- データセットID: 任意の名前
- ロケーションタイプ: リージョン
- リージョン: asia-northeast1 (東京)
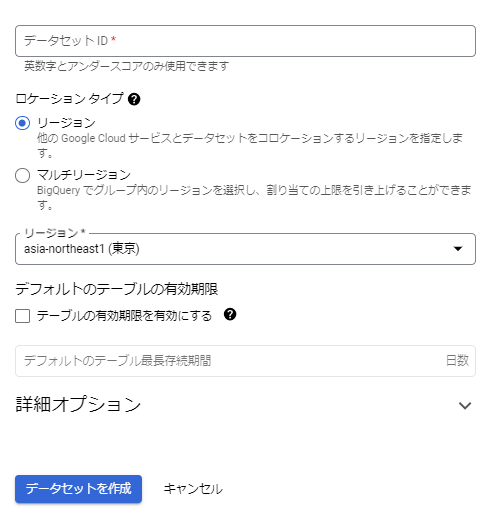
続いて、作成したデータセットへテーブルを作成します。
- テーブルの作成元: アップロード
- ファイルを選択: 先ほどのビールのデータセット
- テーブル: 任意の名前
- スキーマ: テキストとして編集
- テキスト: 以下のJSONで定義します。
[ { "name": "store", "type": "STRING", "mode": "NULLABLE" }, { "name": "product_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "purchase_date", "type": "DATE", "mode": "NULLABLE" }, { "name": "review_date", "type": "DATE", "mode": "NULLABLE" }, { "name": "review_content", "type": "STRING", "mode": "NULLABLE" } ]
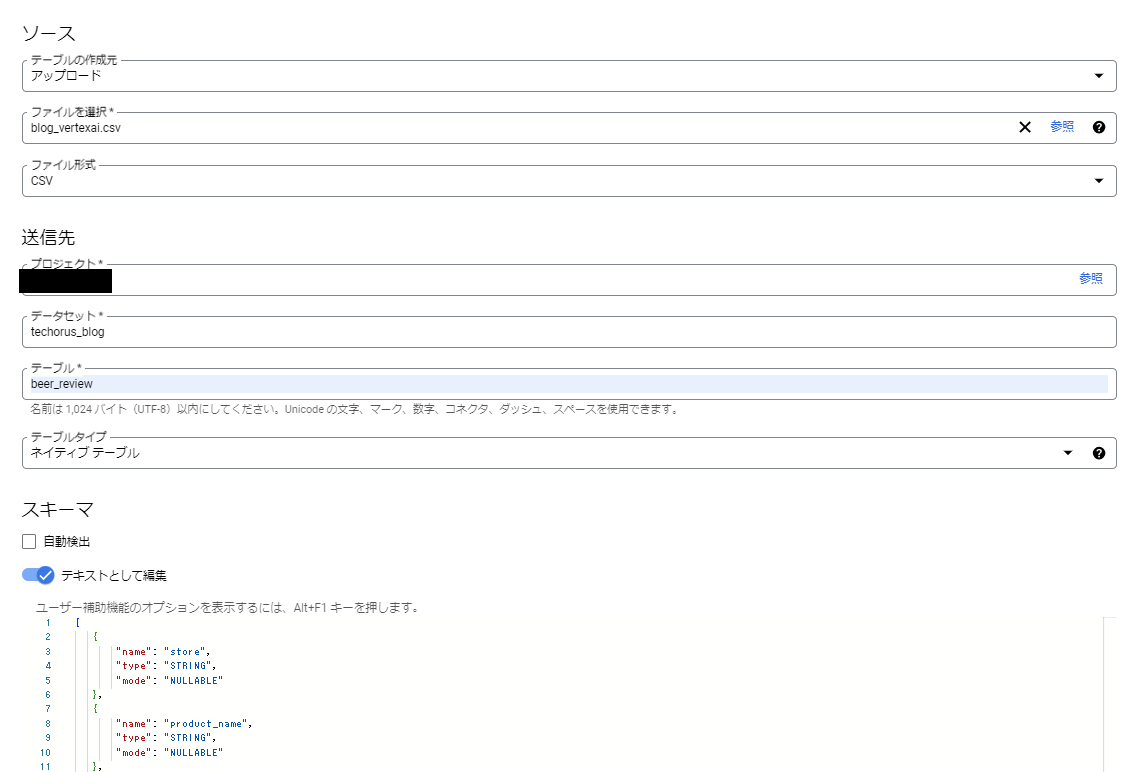
テーブルのプレビューからデータを確認することができます。
3. GeminiとBigQueryの接続
まず、エクスプローラから追加を選択します。
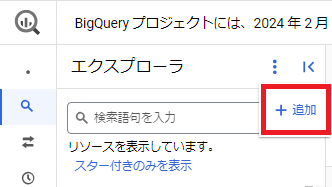
続いて、外部データソースへの接続を選択します。
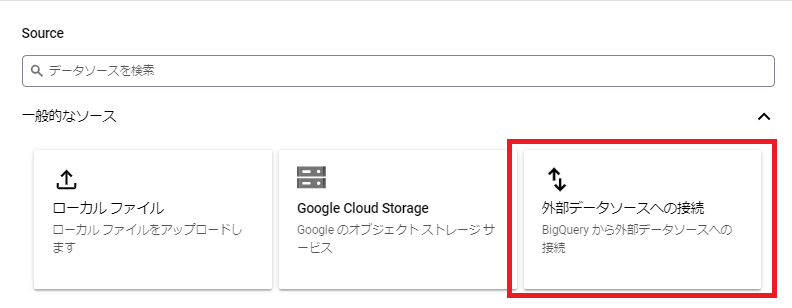
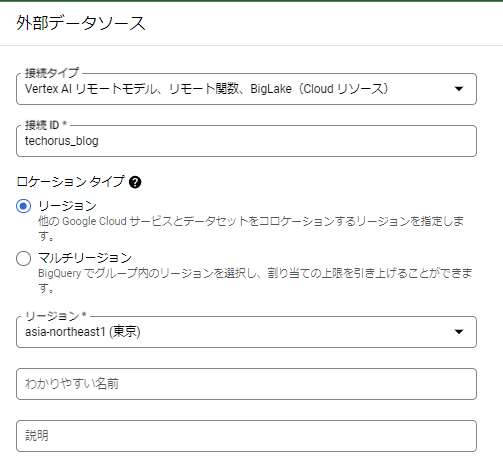
以下のように設定します。
- 接続タイプ: Vertex AI リモートモデル、リモート関数、BigLake(Cloud リソース)
- 接続ID: 任意の名前
- ロケーションタイプ: リージョン
- リージョン: asia-northeast1 (東京)
次に、権限付与を行っていきます。
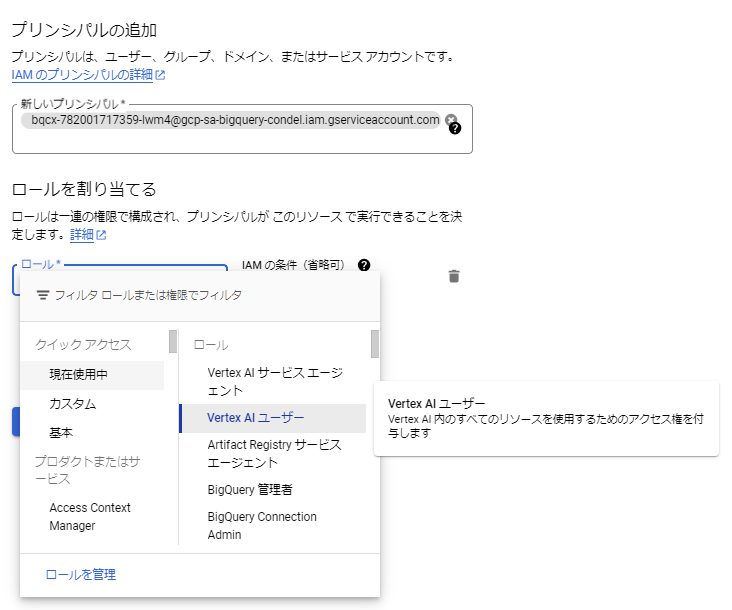
作成した接続情報のサービスアカウントIDをコピーします。
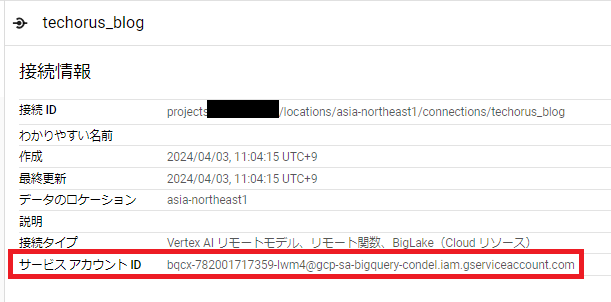
[IAMと管理] > [IAM] > [アクセス権を付与]から以下のように設定します。
- 新しいプリンシパル: 接続情報のサービスアカウントID
- ロール: Vertex AI ユーザー
4. モデルの作成
ここでは、BigQueryで使用するGeminiのモデルを作成します。
BigQueryへ以下のクエリを実行します。
# データセット内へgemini_proというモデルを作成する CREATE OR REPLACE MODEL [データセット名].gemini_pro # 外部接続先を指定する REMOTE WITH CONNECTION `asia-northeast1.[接続ID]` # モデルがホストしている箇所を指す OPTIONS( ENDPOINT = 'gemini-pro' )
これにより、 データセット内へgemini-proというモデルが作成されます。
5. Geminiを使用
Geminiを呼び出す際は、ML.GENERATE_TEXTという関数を使用します。
ML.GENERATE_TEXT関数を用いることで、BigQuery テーブルに保存されているテキストに対して自然言語生成タスクを実行できます。
言語タスクとしては、分類、感情分析、エンティティ抽出、質問応答、要約、テキストのスタイル変更、広告コピー生成、コンセプトなどを実行することができます。
実行する際は、promptパラメータを通じてモデルにテキストを送ることで、出力を得ることができます。
出力は、ml_generate_text_resultから受け取ることができます。
ml_generate_text_result: モデルへの呼び出しからの JSON レスポンス。生成されたテキストは content 要素に格納されます。
出典: ML.GENERATE_TEXT 関数
以下は、Gemini APIからのレスポンス例です。
{
"candidates": [
{
"content": {
"parts": [
{
"text": string
}
]
},
"finishReason": enum (FinishReason),
"safetyRatings": [
{
"category": enum (HarmCategory),
"probability": enum (HarmProbability),
"blocked": boolean
}
],
"citationMetadata": {
"citations": [
{
"startIndex": integer,
"endIndex": integer,
"uri": string,
"title": string,
"license": string,
"publicationDate": {
"year": integer,
"month": integer,
"day": integer
}
}
]
}
}
],
"usageMetadata": {
"promptTokenCount": integer,
"candidatesTokenCount": integer,
"totalTokenCount": integer
}
}
これの情報を踏まえて、ml_generate_text_resultのtextを抽出する、以下のクエリを実行します。
SELECT
STRING(_ml_generate_text_result_candidates.content.parts[0].text) AS content_text,
FROM
ML.GENERATE_TEXT(
MODEL [データセット名].gemini_pro,
(
SELECT '日本のビールメーカーについて教えてください。' AS prompt
),
STRUCT(
1000 AS max_output_tokens
)
)
LEFT JOIN
UNNEST(JSON_EXTRACT_ARRAY(ml_generate_text_result.candidates)) AS _ml_generate_text_result_candidates
以下の結果の通り、Geminiを呼び出せています。
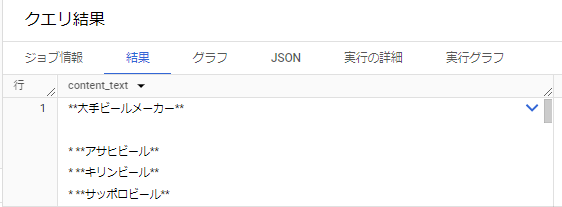
**大手ビールメーカー** * **アサヒビール** * **キリンビール** * **サッポロビール** * **サントリービール** * **オリオンビール** **中堅ビールメーカー** * **エビスビール** (サッポロビール傘下) * **ハートランドビール** (キリンビール傘下) * **一番搾り** (キリンビール傘下) * **スーパードライ** (アサヒビール傘下) * **プレミアムモルツ** (サントリービール傘下) **地ビールメーカー** * **よなよなエール** (ヤッホーブルーイング) * **常陸野ネストビール** (木内酒造)
続いて、本ブログの主題であるテーブル内のデータを分析してみます。
テーブル内のレビューを、ブランド、価格、味、デザイン、その他で分類し、categoryというカラムを作成するクエリを実行します。
CREATE or REPLACE TABLE [データセット名].[新しいテーブル名] AS
SELECT
review_content,
product_name,
JSON_VALUE(ml_generate_text_result.candidates[0].content.parts[0].text) as category
FROM ML.GENERATE_TEXT(
MODEL [データセット名].gemini_pro,
(SELECT
CONCAT(
'次の顧客の声を分類してください。分類は次のいずれかを選んでください。¥n¥n',
'ブランド、価格、味、デザイン、その他。¥n¥n',
'顧客の声:',
review_content
) AS prompt,
review_content,
product_name
FROM `[データセット名].[分類するテーブル名]`),
STRUCT(1000 as max_output_tokens, 0.2 as temperature)
)
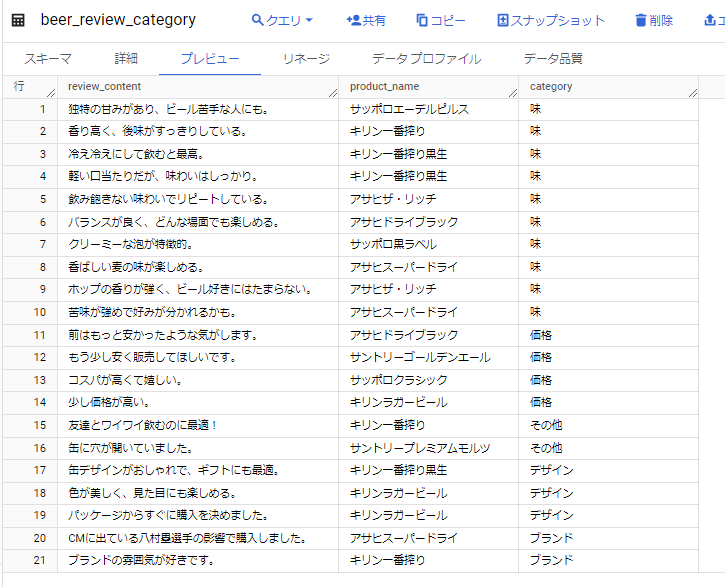
新しいテーブルが作成され、プレビューから各商品のレビューをカテゴリー別に振り分けた結果を確認することができます。
次に、レビューの分類基準を変更してみます。
顧客のレビューをポジティブ、ネガティブ、その他で分類してみることにします。
この変更は、先ほどのプロンプト文を修正するだけで対応可能です。
実際に分類を試みた結果、ネガティブな分類の結果がnull値として出力されています。
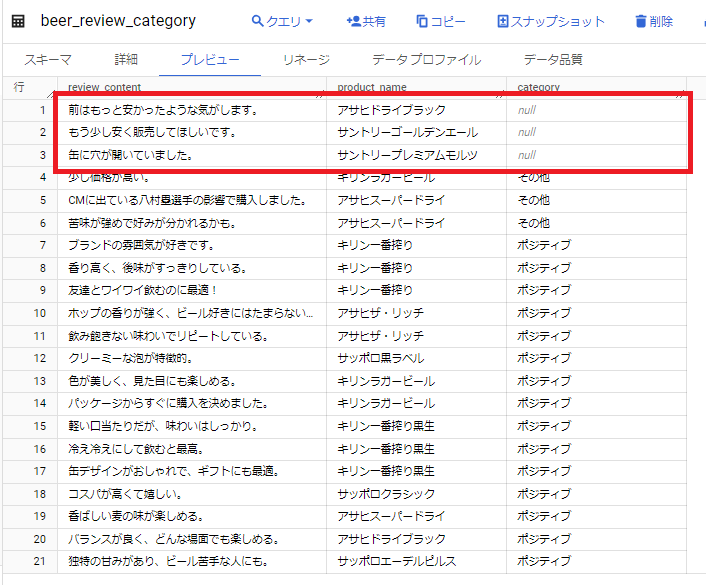
ネガティブな内容については、出力ができないような制限があるのかと思い調べてみましたが、明確な情報は見つかりませんでした。
まとめ
BigQueryとGeminiを組み合わせることで、自然言語を用いて簡単にデータの分類を行うことができました。
今回は小規模なデータセットを使用しましたが、データ量が増えるほど、この方法のメリットが大きくなります。
生成AIを活用する方法はまだまだたくさんありますので、今後もさまざまな試みを行っていきたいと思います。
最後まで読んでいただきありがとうございます!

Google Cloud Partner Top Engineer 2025、2024 AWS All Cert、ビール検定1冠


Recommends
こちらもおすすめ
-

FIT2018 第17回情報科学技術フォーラム参加報告(1)FIT2018概要編
2018.9.20





Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16