[AWS re:Invent 2024] S3 TablesをEMR経由で設定してAthenaから検索する

はじめに
先日のre:InventでS3の新機能としてS3 Tablesが発表されました。S3 TablesはApache Icebergを手軽に扱えるようになったサービスですが、それに加えて運用コストを下げる機能が実装されています。
2024年12月現在S3 Tablesを使うにはSparkを利用する必要があります。AWS CLIでテーブルは作成できるのですが、スキーマが作成できないためSparkが必須になっています。そのため今回はEMRを立ち上げて、S3 Tablesを操作して、その後作成したスキーマをAthena経由で確認していこうと思います。
機能の概要を簡単に確認した後に、実装方法について説明していきます。機能の詳細についてはre:Invent2024で行われたBreakoutSessionが詳しいので、こちらを確認してみて下さい。
概要
S3 TablesはApache Icebergが扱えることが特徴ですが、他にも以下の機能があります。
- セキュリティ
Lake Formation経由でカラム単位でセキュリティの管理が可能になる。 -
自動テーブルメンテナンス
圧縮、スナップショット管理、参照されていないファイルの削除などの重要なメンテナンスタスクを自動化する。 -
パフォーマンスの強化
従来のS3バケットにIcebergテーブルを保存する場合と比較して、クエリパフォーマンスが最大3倍、トランザクション数が最大10倍/秒になる。
参考:Build a managed transactional data lake with Amazon S3 Tables
検証の流れ
S3 TablesをEMR経由で設定を行い、最後にAthenaから検索してみます。
検証の流れは以下になります。設定はコンソールやCLIなど、対応が楽な方で実装しています。
- S3 Tablesの作成
- EMRの設定
- S3 Tablesにテーブルとスキーマを作成してデータを入れる
- Athenaから確認する
また全体のチュートリアルの流れはこちらを参考にしています。
Tutorial: Getting started with S3 Tables
Build a managed transactional data lake with Amazon S3 Tables
1. S3 Tablesの作成
マネージドコンソールから作成していきます。S3 Tablesは2024年12月現在、東京リージョンでは提供されていません。そのため提供されているリージョンを指定する必要があります。今回はus-east-1から作成します。
以下の画面から作成をします。この時「AWS 分析サービスとの統合 – プレビュー」も有効化します。後でEMRやAthenaから利用するときに使います。
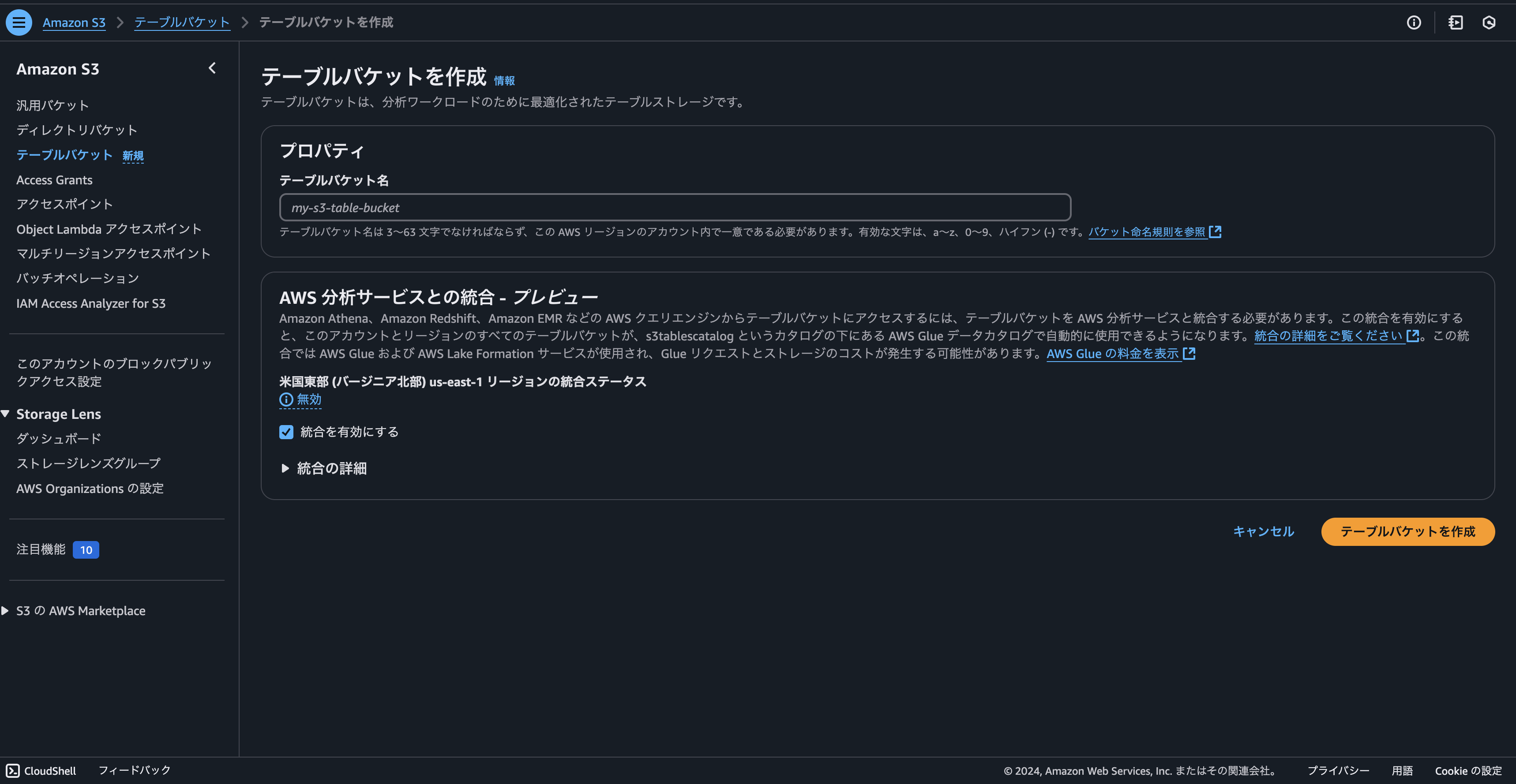
またこちらの機能は2024年12月現在プレビューになります。詳細は公式ドキュメントを確認して下さい。
Using Amazon S3 Tables with AWS analytics services
作成後は一覧が確認ができます。2024年12月現在マネージドコンソールではテーブルの削除やスキーマの操作など詳細な操作はできないので、基本的にCLIやSparkから操作します。
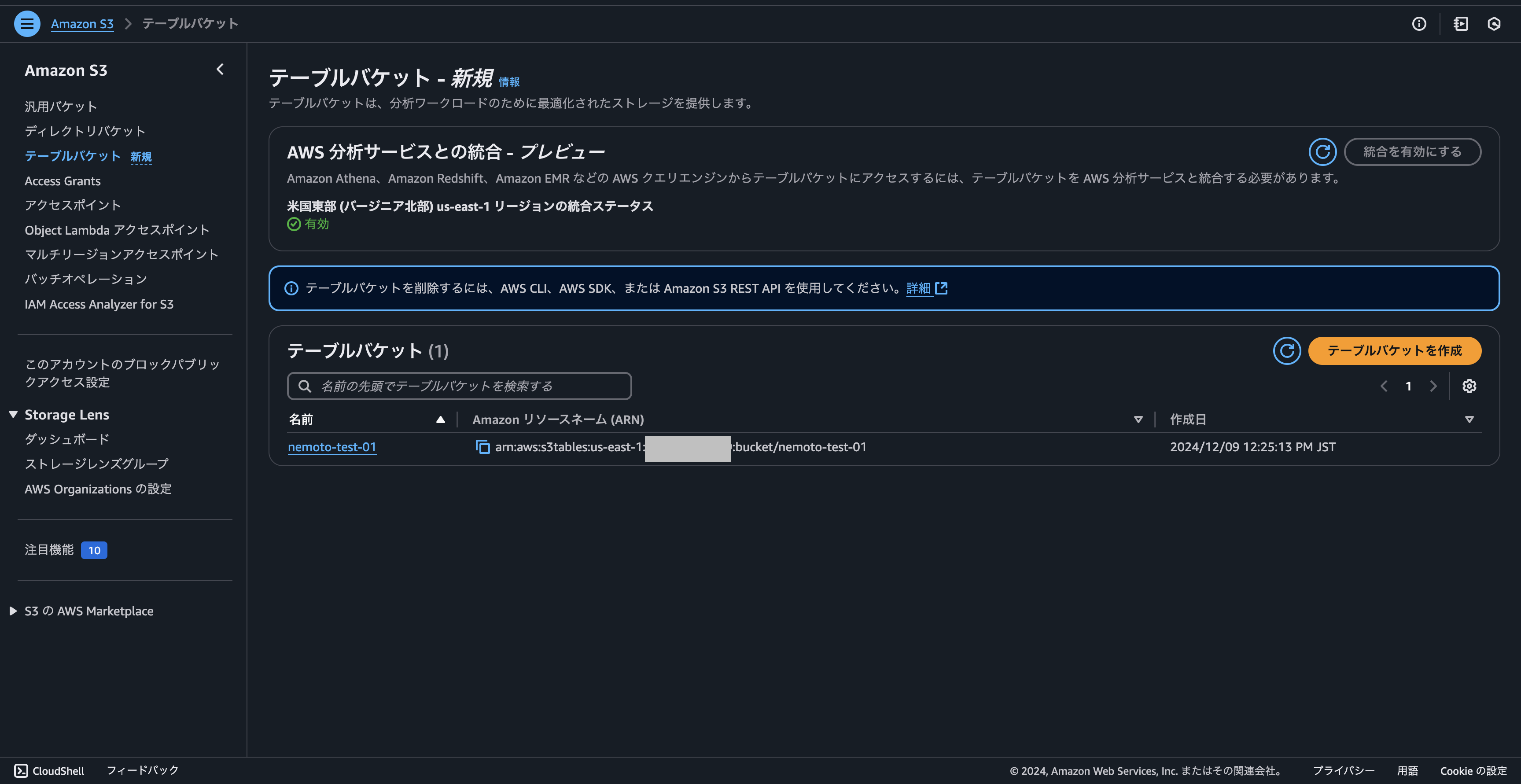
2. EMRの設定
次にEMRを作成します。こちらのブログに掲載されている構成を参考に必要なものだけ使っています。
参考:Build a managed transactional data lake with Amazon S3 Tables
変更点は2点です。
1. 今回はEMRはCloudFormationからではなくCLIから実行したいため、EMRを立ち上げる設定を除いています。
2. EMRはSessionManagerからアクセスしたいため、インスタンスプロファイルにPolicyを追加しています。
AWSTemplateFormatVersion: '2010-09-09'
Description: 'EMR Cluster with Spark, Hive, Hadoop, Iceberg, JupyterHub, and JupyterEnterpriseGateway'
Parameters:
Environment:
Type: String
Default: dev
AllowedValues: [dev, test, prod]
Description: Environment type
VpcId:
Type: AWS::EC2::VPC::Id
Description: VPC ID for the EMR cluster
Resources:
EMRMasterSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Security group for EMR Master Node
VpcId: !Ref VpcId
Tags:
- Key: Name
Value: !Sub emr-master-sg-${Environment}
- Key: Environment
Value: !Ref Environment
EMRSlaveSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Security group for EMR Slave Nodes
VpcId: !Ref VpcId
Tags:
- Key: Name
Value: !Sub emr-slave-sg-${Environment}
- Key: Environment
Value: !Ref Environment
# Allow all traffic between master and slave nodes
MasterToSlaveIngress:
Type: AWS::EC2::SecurityGroupIngress
Properties:
GroupId: !Ref EMRSlaveSecurityGroup
SourceSecurityGroupId: !Ref EMRMasterSecurityGroup
IpProtocol: -1
FromPort: -1
ToPort: -1
Description: Allow all traffic from master node
SlaveToMasterIngress:
Type: AWS::EC2::SecurityGroupIngress
Properties:
GroupId: !Ref EMRMasterSecurityGroup
SourceSecurityGroupId: !Ref EMRSlaveSecurityGroup
IpProtocol: -1
FromPort: -1
ToPort: -1
Description: Allow all traffic from slave nodes
# Allow communication between slave nodes
SlaveToSlaveIngress:
Type: AWS::EC2::SecurityGroupIngress
Properties:
GroupId: !Ref EMRSlaveSecurityGroup
SourceSecurityGroupId: !Ref EMRSlaveSecurityGroup
IpProtocol: -1
FromPort: -1
ToPort: -1
Description: Allow all traffic between slave nodes
# Add egress rules
MasterSecurityGroupEgress:
Type: AWS::EC2::SecurityGroupEgress
Properties:
GroupId: !Ref EMRMasterSecurityGroup
IpProtocol: -1
FromPort: -1
ToPort: -1
CidrIp: 0.0.0.0/0
Description: Allow all outbound traffic
SlaveSecurityGroupEgress:
Type: AWS::EC2::SecurityGroupEgress
Properties:
GroupId: !Ref EMRSlaveSecurityGroup
IpProtocol: -1
FromPort: -1
ToPort: -1
CidrIp: 0.0.0.0/0
Description: Allow all outbound traffic
EMRServiceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: elasticmapreduce.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AmazonElasticMapReduceRole
EMRInstanceProfile:
Type: AWS::IAM::InstanceProfile
Properties:
Roles:
- !Ref EMRInstanceRole
EMRInstanceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AmazonElasticMapReduceforEC2Role
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/AmazonS3TablesFullAccess
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore # 追加
2-1. VPCとサブネットを確認する
VPCとサブネットはデフォルトのものを使用します。us-east-1にあるデフォルトのVPCとサブネットを確認します。VPC IDとSubnet IDを確認しておいて下さい。
https://us-east-1.console.aws.amazon.com/vpcconsole/home?region=us-east-1#vpcs:
2-2. CloudFormationを実行する
CloudFormationを実行して、セキュリティグループとEMRのサービスロールとインスタンスプロファイルを作成します。こちらもus-east-1に作成します。
$ aws cloudformation create-stack \ --profile [自分のプロファイル] \ --stack-name [Stack名 なんでもいい] \ --template-body file://s3table-blog-resource-setup-cfn.yml \ --parameters ParameterKey=VpcId,ParameterValue=[デフォルトのVPC ID] \ --capabilities CAPABILITY_IAM \ --region us-east-1
2-3. EMRを作成する
次にEMRを作成します。コマンドはチュートリアルものを参考にしています。
Tutorial: Getting started with S3 Tables
$ aws emr create-cluster --profile [自分のプロファイル] \ --release-label emr-7.5.0 \ --applications Name=Spark \ --configurations file://configurations.json \ --region us-east-1 \ --name My_Spark_Iceberg_Cluster \ --log-uri [EMRのログの出力先のS3 どこでもいい] \ --instance-type m5.xlarge \ --instance-count 2 \ --service-role [EMRServiceRoleの名前] \ --ec2-attributes \ InstanceProfile=[EMRInstanceProfileの名前],SubnetId=[デフォルトのサブネットID]
configurations.json
[{
"Classification":"iceberg-defaults",
"Properties":{"iceberg.enabled":"true"}
}]
2-4. SessionManager経由でEMRに入る
EMRが起動したら、EMRのプライマリ(MASTER)のインスタンスのIDを確認した後に、対象のEC2からSessionManager経由でアクセスします。
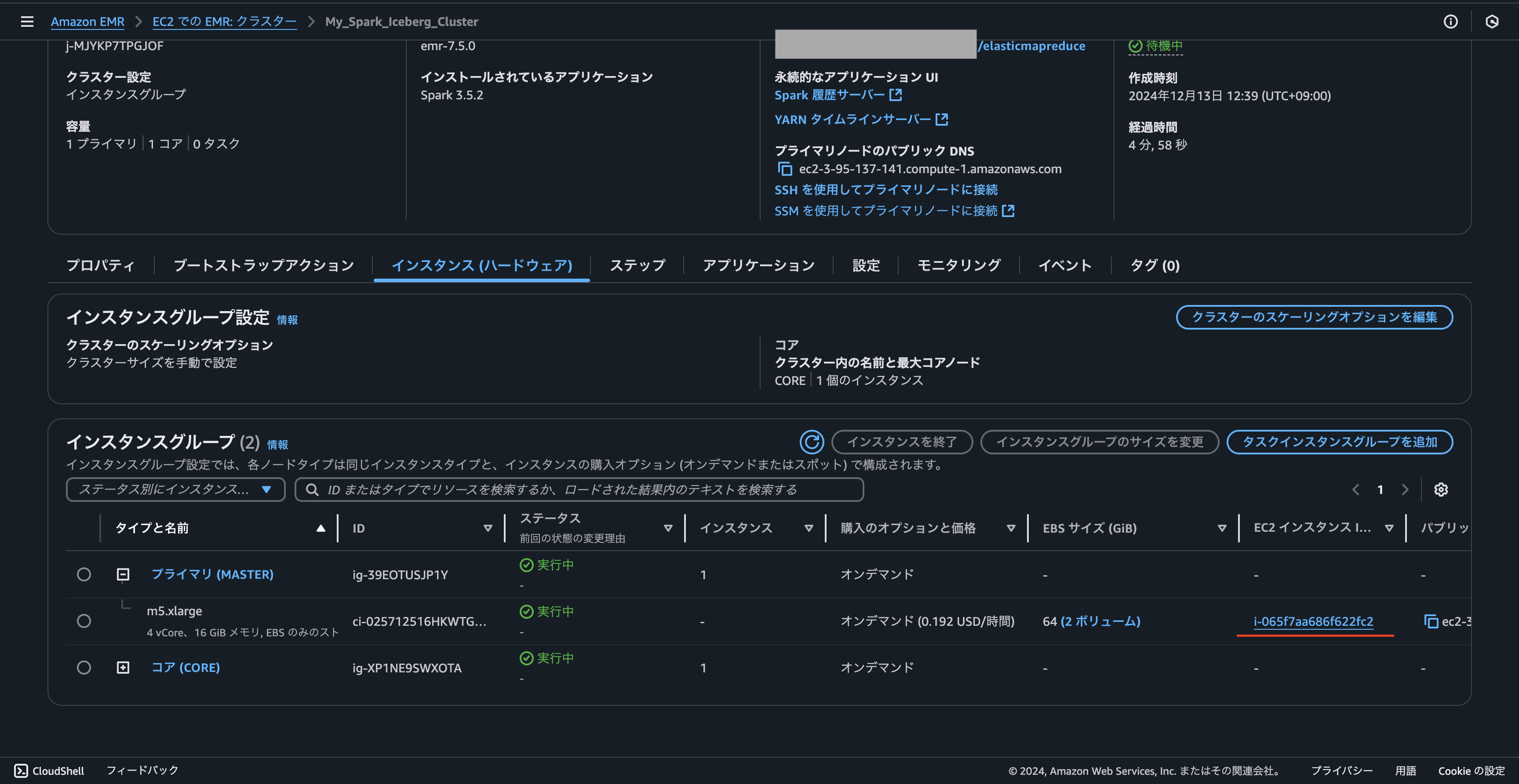
アクセスしたら、以下を実行すれば準備完了です。
$ sudo su
3. S3 Tablesにテーブルとスキーマを作成してデータを入れる
EMRに入れたら、次はS3Tablesの操作を行います。こちらは以下のチュートリアルのコマンドを参考にします。
Tutorial: Getting started with S3 Tables
3-1. Sparkを起動する
$ spark-shell \ --packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \ --conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \ --conf spark.sql.catalog.s3tablesbucket.warehouse=[作成したS3TablesのARN] \ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
3-2. namespaceを作成する
scala> spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.example_namespace")
3-3. テーブルを作成する
scala> spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.example_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg
""")
3-4. INSERTする
scala> spark.sql(
"""
INSERT INTO s3tablesbucket.example_namespace.example_table
VALUES
(11, 'ABCDEFG', 100)
""")
この時WARNINGが確認できますが、クエリは成功しているため一旦先に進みます。
WARN RedshiftStrategy: Pushdown failed:Something went wrong: a query tree was generated with no Redshift SourceQuery found. software.amazon.glue.spark.redshift.RedshiftPushdownException: Something went wrong: a query tree was generated with no Redshift SourceQuery found.
3-5. 検索してみる
scala> spark.sql("SELECT * FROM s3tablesbucket.example_namespace.`example_table` ").show()
INSERTが成功していることが確認できると思います。
4. Athenaから確認する
次にS3 TablesをAhtenaから確認したいと思います。しかしS3 TablesはLake Formationと連携しているため、テーブルを作成しただけの状態ではクエリを実行することができません。クエリを実行するための許可をLake Formationから設定する必要があります。
今回はIAM Userからアクセスキーを発行して、Lake FormationでIAM Userを許可して、ローカルからCLI経由でAthenaを実行してみようと思います。
IAM Identity Center(SSO)経由でログインしている場合は、画面からS3 TablesのAthenaを実行するにはLake FormationとIdentity Centerとの連携が必要になります。対応する場合はIdentity Centerの管理者に依頼しましょう。
4-1. IAM User作成とアクセスキーの発行
IAM Userを作成して、アクセスキーを発行します。ポリシーは以下を設定しています。
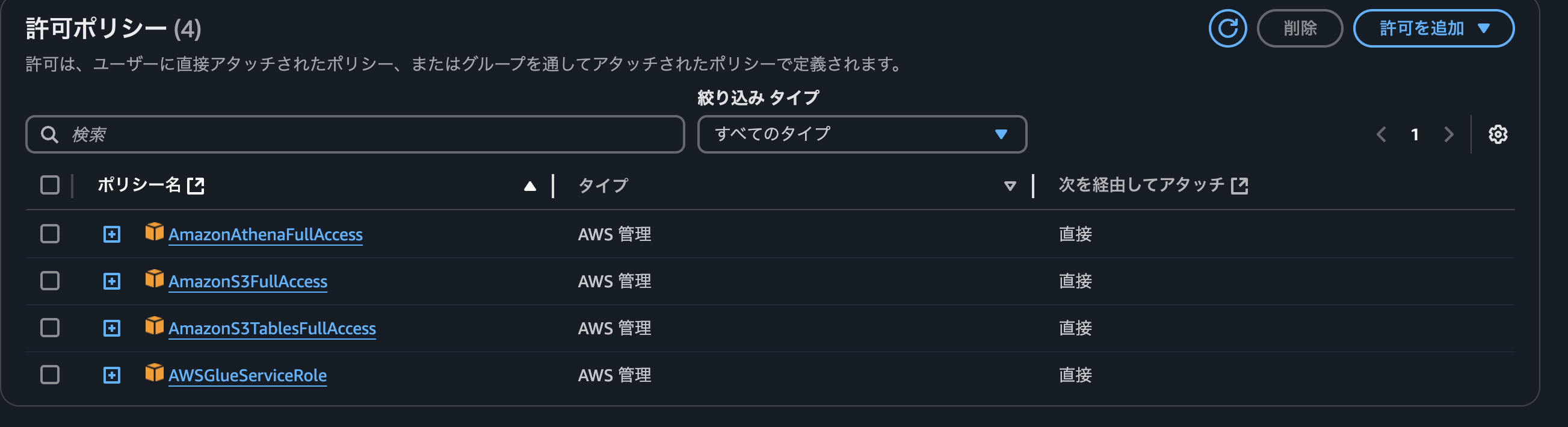
4-2. ローカルにアクセスキーを登録する
$ aws configure --profile [任意のプロファイル名]
4-3. Lake Formationの設定をする
次にLake Formationの設定をします。こちらは画面から行います。
Lake Formation > (サイドバー)Catalogs > s3tablescatalog > [自分が作ったS3Tablesの名前] > テーブル > Actions > Grant
その後以下のように設定をしました。最初の「IAM users and roles」には4-1で作成したものを選択して下さい。
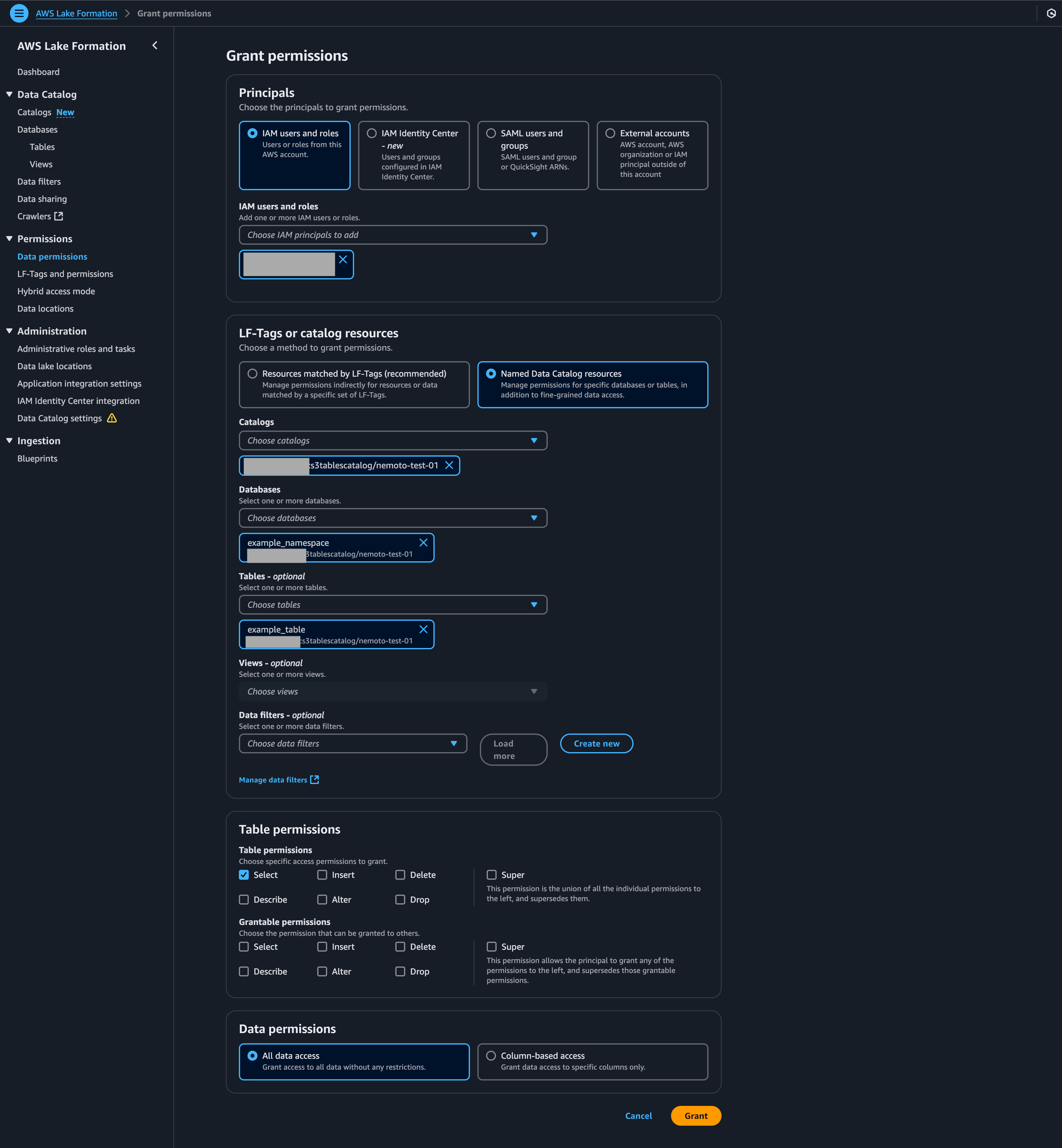
4-4. Athenaを実行する
まずクエリを実行します。
$ aws athena start-query-execution \ --profile [4-2で設定したプロファイル名] \ --query-string "SELECT * FROM example_table" \ --work-group [自分が使っているワークグループ] \ --query-execution-context Database=example_namespace,Catalog=s3tablescatalog/[自分が作ったS3Tablesの名前]
クエリのステータスを確認します。Status=SUCCEEDEDであれば次に進みます。
$ aws athena get-query-execution \ --profile [4-2で設定したプロファイル名] \ --query-execution-id [レスポンスのID]
クエリの結果を取得します。
$ aws athena get-query-results \ --profile [4-2で設定したプロファイル名] \ --query-execution-id [レスポンスのID]
リソースを削除をする
作成したキーペアや、IAM Userは必要なければ削除をしましょう。EMRも停止して、CloudFormationも削除しておいて下さい。CloudFormationはセキュリティグループ以外は削除できるはずです。
またセキュリティグループは、全てのインバウンドルールを削除すると、削除できるようになります。
参照:Build a managed transactional data lake with Amazon S3 Tables > Cleaning Up
まとめ
今回は新しく実装されたS3TablesをEMRから作成して、Athenaから確認するところまで対応しました。現状だとSparkからしかスキーマの定義ができないので、EMRを使う場合の選択肢として考えれば良さそうです。
Icebergは以前からAWSで利用可能でしたが、CloudFormationで設定ができなかったため採用を見送っていました。その後まさかkeynoteでIcebergの名前が出てくるとは思わなくて、私自身リアルタイムで驚きながら公演を見ていました。
現状はS3 TablesはCloudFormationでは使えませんが、まだプレビュー版なので今後も動向を注視していこうと思います。

2018年新卒入社。エンジニア。フロントエンド&サーバサイドを担当。 Vue.js, Ruby on Rails, Ruby, Javaを主に使用する。 会社では全力で働き、家では全力で遊ぶ。


Recommends
こちらもおすすめ
-

1年間でブログを100本書いた話
2024.12.26




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16