Amazon SageMaker Debuggerを試してみる

こんにちは。データサイエンスチームのmotchieです。
この記事では、Amazon SageMakerの新機能、Amazon SageMaker Debuggerの使い方をご紹介します。
SageMaker Debuggerとは
Amazon SageMakerは、機械学習モデルの開発を支援するAWSのマネージドサービスです。
SageMakerはこれまで、データのラベリング、ノートブック環境の作成、モデルのトレーニング、デプロイなど、様々な機能を提供し、機械学習パイプラインの効率化を支援してきました。
今回紹介するAmazon SageMaker Debuggerは、モデルのトレーニングを支援する新機能です。
SageMaker Debuggerを使えば、トレーニング中のモデル内部の状態をS3に出力できます(重み/勾配/各レイヤーの出力/lossなどなど)。
また、出力されたデータを使い、事前に用意した様々なルールに基づいて、モデルのトレーニング中の問題発生を自動で検知できます。
SageMakerのDeep Learningコンテナでトレーニングを行っている場合、対応するバージョンのコンテナを使えば、トレーニングに用いるスクリプトに変更を加えることなく、SageMaker Debuggerの機能を有効化できます。
更に、モデル内部の状態をS3に出力する際、TensorBoard用のログとして出力できます。
このTensorBoard形式での出力機能は、PyTorchなど、TensorFlow以外のフレームワークでも使用できます。
このように、SageMaker Debuggerを使えば、ほぼスクリプトの修正なしで、トレーニング中のモデルの問題を自動で検知し、モデル内部を可視化し、問題を調査することができ、とても便利です。
特にトレーニングに長時間を要する大規模なモデルにおいては、トレーニング中に問題を素早く検知し解決できることで、検証サイクルの改善が期待できます。
それでは早速、SageMaker Debuggerの使い方を見ていきましょう。
この記事では、フレームワークはPyTorchを使い、SageMakerのDeep Learningコンテナ上で、MNISTデータセットを用いた手書き数字画像の分類モデルをトレーニングしていきます。
モデル内部の状態、Tensorsの出力、Built-in Rulesによるモデルの問題の自動検知、出力されたTensorsをTensorBoardで可視化する方法をご紹介します。
事前準備
ノートブックインスタンスの作成
あらかじめログ出力用にS3バケットを作成しておいてください。
実行環境として、SageMakerのノートブックインスタンスを立ち上げます。今回は、東京リージョン(ap-northeast-1) でインスタンスタイプは ml.t2.medium を使いたいと思います。
ノートブックインスタンスの作成方法については、以下のドキュメントを参照ください。
なお、IAMロールの設定では、SageMaker Debuggerでログを出力するS3バケットへ、アクセスできる権限を付与しておいてください。
AWSドキュメント: Amazon SageMaker ノートブックインスタンスの作成
Amazon SageMaker コンソールからノートブックインスタンスを開き、 [Open JupyterLab (JupyterLab を開く)] を選択します。
JupyterLabビューで、conda_pytorch_p36 の環境を指定してNotebookを作成します。
以降のコマンドは、ノートブックのセル上での実行を想定しています。
ライブラリのインストール
S3に出力されるモデルの内部状態(Tensors)の取得のため、smdebugをインストールしておきます。
!python -m pip install smdebug
スクリプトの取得
この記事では、Using Amazon SageMaker Debugger with your own PyTorch containerのExampleを参考に、以下のスクリプトを利用します。
ノートブックインスタンス上に、スクリプトを取得しておきます。
!wget https://github.com/awslabs/amazon-sagemaker-examples/raw/714652a4f96fd764a247a4cee30425293db86c59/sagemaker-debugger/pytorch_custom_container/scripts/pytorch_mnist.py
トレーニングスクリプトの設定
今回、SageMakerのDeep Learningコンテナを使って、PyTorchモデルのトレーニングを行います。
Zero Script Change対応バージョンのコンテナを使う場合、SageMaker Debuggerのセットアップはコンテナ側で行ってくれるため、スクリプトの修正は必要ありません。
例えば、以下のPyTorch公式のMNISTトレーニングスクリプトをそのまま使って、SageMaker Debuggerでモデル内部の状態をS3に出力することが出来ます。
GitHub: pytorch/examples: examples/mnist/main.py
必要なのは、SageMaker python SDKのEstimatorからモデルのトレーニングを行う際、Debug HookのConfigを与えるだけです(詳しくは後述)。
ただし、独自コンテナを使ってモデルのトレーニングを行う場合や、独自のスカラ値を出力したり、train eval predict などフェーズごとにログ分けるなど、自身で細かくカスタマイズして使いたい場合、トレーニングスクリプト内でHookのセットアップを自身で行う必要があります。
今回使用するスクリプトでは、スクリプト内でHookをセットアップし、train と eval のフェーズで分けてログを出力しています。
以下でコードを抜粋し、Hookのセットアップの流れをご紹介します。
なお、繰り返しになりますが、今回はSageMakerのDeep Learningコンテナを使うため、Hookのセットアップはコンテナ側で自動で行われるため、本来スクリプトの修正は必要ありません。
モジュールのインポート
# SageMaker Debugger: Import the package import smdebug.pytorch as smd
Hookのセットアップ
# SageMaker Debugger: This function created the debug hook required to log tensors.
# In this example, weight, gradients and losses will be logged at steps 1,2, and 3,
# and saved to the output directory specified in hyperparameters.
def create_smdebug_hook():
# This allows you to create the hook from the configuration you pass to the SageMaker pySDK
hook = smd.Hook.create_from_json_file()
return hook
モデル/lossをHookに登録
# SageMaker Debugger: Create the debug hook,
# and register the hook to save tensors.
hook = create_smdebug_hook()
hook.register_hook(model)
def train(model, device, optimizer, hook, epochs, log_interval, training_dir):
criterion = nn.CrossEntropyLoss()
# SageMaker Debugger: If you are using a Loss module and would like to save the
# values as we are doing in this example, then add a call to register loss.
hook.register_loss(criterion)
フェーズ(train/eval)ごとに分けてTensorsを出力
for epoch in range(epochs):
model.train()
hook.set_mode(smd.modes.TRAIN)
def test(model, hook, test_loader, device, loss_fn):
model.eval()
hook.set_mode(smd.modes.EVAL)
PyTorchにおけるHookの使い方については、以下もご覧ください。
GitHub: awslabs/sagemaker-debugger: sagemaker-debugger/docs/pytorch.md
Debug Hookの設定
SageMaker python SDKでEstimatorを作成してモデルのトレーニングを行う際、Debug HookのConfigを与えることが出来ます。
SageMakerのDeep Learningコンテナを使う場合、自動で与えられたConfigを取得し、Hookのセットアップしてくれます。
Debug HookのConfigでは、取得したいモデル内部の値(Tensors)をCollectionとして指定します。
執筆時点では、PyTorchではBuilt in Collectionsとして、weights, biases, gradients, losses , 取得可能な全てのTensorsにマッチする all , Tensorsの中で include_regex の正規表現にマッチするものを取得する default の6種類が用意されています。また、独自のCollectionを定義してTensorを取得することも可能です。
今回は全てのTensorを取得してみたいと思います。
S3バケット名と保存場所のprefixについては、自身の値に置き換えて実行してください。
from sagemaker.debugger import DebuggerHookConfig, CollectionConfig
# 自身の値に置き換えてください
bucket = "your_s3_bucket_name"
prefix_for_tensors = "your_s3_prefix_to_save_tensors"
hook_config = DebuggerHookConfig(
s3_output_path=f"s3://{bucket}/{prefix_for_tensors}",
collection_configs=[
CollectionConfig("all")
]
)
また、SageMaker DebuggerにはTensorBoard用にログを出力する機能があります。
PyTorchなど、TensorFlow以外のフレームワークでも使うことができ、TensorBoardの強力な可視化機能を簡単に利用できます。
TensorBoard用の設定を行います。保存場所のprefixについては、自身の値に置き換えて実行してください。
from sagemaker.debugger import TensorBoardOutputConfig
# 自身の値に置き換えてください
prefix_for_tensorboard = "your_s3_prefix_for_tensorboard_logs"
tb_config = TensorBoardOutputConfig(f"s3://{bucket}/{prefix_for_tensorboard}")
Debugging Ruleの設定
Debugging Ruleとは、Debug HookによってS3に出力されたTensorをチェックし、モデルのトレーニングに問題が起きてないか判定する仕組みです。
SageMaker Debuggerでは、Built-in Rulesとして様々なRuleが用意されています。また、独自のRuleを定義することも可能です。
Ruleを使うことで、モデルのトレーニングが上手くいっていない状態を自動で検知することが出来ます。
執筆時点では、PyTorchで使用可能なBuilt-in Rulesとして下記のものが提供されています。簡単に訳してご紹介します。なお、()内の値はデフォルトのパラメータになります。
| Built-in Rules | 判定条件 |
|---|---|
| DeadRelu | ReLUレイヤーで、出力が閾値未満のユニットが一定以上を占めていないか |
| ExplodingTensor | トレーニング中に出力されたTensorがInfやNaNを含んでいないか |
| PoorWeightInitialization | 各レイヤーにおいて初期の重みの分散が小さすぎないか |
| SaturatedActivation | tanhレイヤーやsigmoidレイヤーにおいて活性化が飽和していないか |
| VanishingGradient | 勾配の絶対値の平均が閾値未満になっていないか |
| WeightUpdateRatio | トレーニング中の重み更新の割合が閾値の範囲に収まっているか |
| AllZero | Tensorの値の割合の一定以上が0になっていないか |
| ClassImbalance | 各クラスのサンプルの出現回数をカウント。出現回数が最小のクラスと最大のクラスを比べて、割合の偏りが閾値を超えていないか。また、各クラス(特に最小クラス)の予測ミスが閾値を超えていないか |
| Confusion | 分類問題を混同行列を使って評価。対角成分の割合が閾値以下になっているか、また、非対角成分の割合が閾値以上を占めていないか |
| LossNotDecreasing | Lossが低下しているか |
| Overfit | validationとtrainingのlossの差が、trainingのlossに対して占める割合が閾値を超えていないか(trainingデータへの過学習) |
| Overtraining | trainingのlossやvalidationのlossが閾値よりも低下し続けているか |
| SimilarAcrossRuns | base_trial と other_trial のTrial間でTensorの値が類似しているか |
| TensorVariance | Tensorの分散が閾値以内に収まっているか |
| UnchangedTensor | ステップ間でTensorが変化していないことはないか |
今回は以下のRuleを設定してみます。ハイパーパラメータとして適切ではない値を指定してみて、Ruleがトレーニングの問題が検知できるか確認してみます。
なお、各Ruleのパラメータについては、デフォルトの設定を使っています。
from sagemaker.debugger import Rule, rule_configs
rules = [
Rule.sagemaker(rule_configs.exploding_tensor()),
Rule.sagemaker(rule_configs.vanishing_gradient()),
Rule.sagemaker(rule_configs.weight_update_ratio()),
Rule.sagemaker(rule_configs.loss_not_decreasing()),
]
モデルのトレーニング
それでは、これまでの手順で作成した設定を使い、PyTorchのEstimatorを作成し、モデルのトレーニングを行います。
今回、学習率(learning_rate)に大きな値を設定し、パラメータが発散してlossが下がらない状況を作り、勾配消失や勾配爆発など、トレーニングが上手くいかない状況をRuleが検知できるか見てみたいと思います。
from sagemaker.pytorch import PyTorch
from sagemaker import get_execution_role
role = get_execution_role()
training_dir = "/tmp/pytorch-smdebug"
script_path = "pytorch_mnist.py"
hyperparameters = {"random_seed": True, "epochs": 5, "learning_rate": 1e-1, "data_dir": training_dir}
estimator = PyTorch(
entry_point=script_path,
framework_version="1.3.1",
py_version="py3",
role=role,
train_instance_count=1,
train_instance_type="ml.c5.xlarge",
hyperparameters=hyperparameters,
debugger_hook_config=hook_config,
tensorboard_output_config=tb_config,
rules=rules
)
モデルの学習を実行します。
estimator.fit(wait=False)
出力の確認
トレーニング状況を確認してみましょう。Debugging Ruleの結果を取得してみます。
for d in estimator.latest_training_job.rule_job_summary():
print(f"{d['RuleConfigurationName']}: {d['RuleEvaluationStatus']}")
トレーニング開始は以下のような結果が出てきます。
ExplodingTensor: InProgress
VanishingGradient: InProgress
WeightUpdateRatio: InProgress
LossNotDecreasing: InProgress
モデルのトレーニングを開始してから10分ほど待って再度実行してみると、以下のように、ExplodingTensor(InfやNanを含むTensorの発生)、VanishingGradient(勾配消失)、WeightUpdateRatio(重みの更新率の異常)、LossNotDecreasing(lossが低下していない)など、モデルの問題が検出されました。
ExplodingTensor: Error
VanishingGradient: IssuesFound
WeightUpdateRatio: IssuesFound
LossNotDecreasing: Error
Ruleでトレーニングの問題が見つかった際、CloudWatchでは SageMaker Training Job State Change のEventとして検出することが出来ます。
EventによってLambdaがトリガーされるよう、CloudWatch Ruleを設定し、LambdaからTraining Jobの停止や通知を設定するような活用方法も考えられます。
Debugging RuleとCloudWatch Ruleを組み合わせた活用については、以下のExampleが参考になります。
Amazon SageMaker Debugger – Reacting to Cloudwatch Events from Rules
以降では、Debug HookによってS3に出力されたTensorを確認してみます。
TrialによるTensorの取得
SageMaker Debuggerでは、Trialというオブジェクトを使って、Training jobごとのTensorを取得できます。
from smdebug.trials import create_trial trial = create_trial(path=estimator.latest_job_debugger_artifacts_path())
Tensorの一覧が取得できます。
trial.tensor_names()
[‘CrossEntropyLoss_input_0’,
‘CrossEntropyLoss_input_1’,
‘CrossEntropyLoss_output_0’,
‘Net_conv1.bias’,
‘Net_conv1.weight’,
‘Net_conv2.bias’,
‘Net_conv2.weight’,
‘Net_fc1.bias’,
‘Net_fc1.weight’,
‘Net_fc2.bias’,
‘Net_fc2.weight’,
‘gradient/Net_conv1.bias’,
‘gradient/Net_conv1.weight’,
‘gradient/Net_conv2.bias’,
‘gradient/Net_conv2.weight’,
‘gradient/Net_fc1.bias’,
‘gradient/Net_fc1.weight’,
‘gradient/Net_fc2.bias’,
‘gradient/Net_fc2.weight’]
このように、各ステップにおけるTensorの値も確認できます。
trial.tensor("gradient/Net_fc1.weight").values()
{0: array([[ 0. , 0. , 0. , …, 0. ,
0. , 0. ],
[ 0. , 0. , 0. , …, 0. ,
0. , 0. ],
[-0.02159601, -0.00996249, -0.02803487, …, -0.05145397,
-0.03079144, -0.0200104 ],
…,
[-0.07065905, -0.03657869, -0.08962931, …, -0.15103655,
-0.09744397, -0.06175173],
[ 0. , 0. , 0. , …, 0. ,
0. , 0. ],
[ 0.05386365, 0.02484792, 0.06992311, …, 0.12833382,
0.07679842, 0.0499089 ]], dtype=float32),
500: array([[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
…,
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.]], dtype=float32),
1000: array([[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
…,
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.]], dtype=float32),
1500: array([[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
…,
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.],
[0., 0., 0., …, 0., 0., 0.]], dtype=float32),
(以下略)
500ステップの時点で、FC層の重みが0になっていることが確認できます。
TensorBoardによる可視化
Tensorsのより詳細な可視化については、TensorBoardを使うのが便利です。
ノートブックインスタンス上でTensorBoardを起動し、S3のログを可視化したいと思います。
TensorBoardは別のNotebookで実行したいと思います。ログのパスを確認しておきます。
print(f"logdir = \"s3://{bucket}/{prefix_for_tensorboard}/\"")
次に、JupyterLabの[File]->[New Launcher]をクリックし、conda_tensorflow_p36 の環境を選択し、新しいNotebookを作成します。
以降のコマンドは、conda_tensorflow_p36 環境のNotebook上で実行します。
先ほど確認したログのパスを変数に設定しておきます。
# 値を置き換えて実行してください logdir = "s3://your_s3_bucket_name/your_s3_prefix_for_tensorboard_logs/"
環境変数を設定し、TensorBoardでS3のファイルを読み込みます。
TensorFlowでS3からファイルを読み込む方法については、GitHub: tensorflow/examples: TensorFlow on S3もご覧ください。
下記は、東京リージョン(ap-northeast-1)のS3バケットにログが格納されている場合の実行例です。
なお、データが読み込まれてグラフが表示されるまで、数秒~数十秒ほど時間がかかる場合があります。
! S3_VERIFY_SSL=1 \
S3_USE_HTTPS=1 \
S3_REGION=ap-northeast-1 \
S3_ENDPOINT=s3.ap-northeast-1.amazonaws.com \
tensorboard --logdir {logdir}
TensorBoard 1.14.0 at http://ip-xxx-xx-xx-xx:6006/ (Press CTRL+C to quit)
ノートブックインスタンス上でTensorBoardが起動しました。デフォルトの6006ポートで起動した場合、ノートブックインスタンスの /proxy/6006/ からアクセスできます。
例えば、ノートブックインスタンス名がhoge-instance リージョンが ap-northeast-1 の場合は https://hoge-instance.notebook.ap-northeast-1.sagemaker.aws/proxy/6006/からアクセスできます。


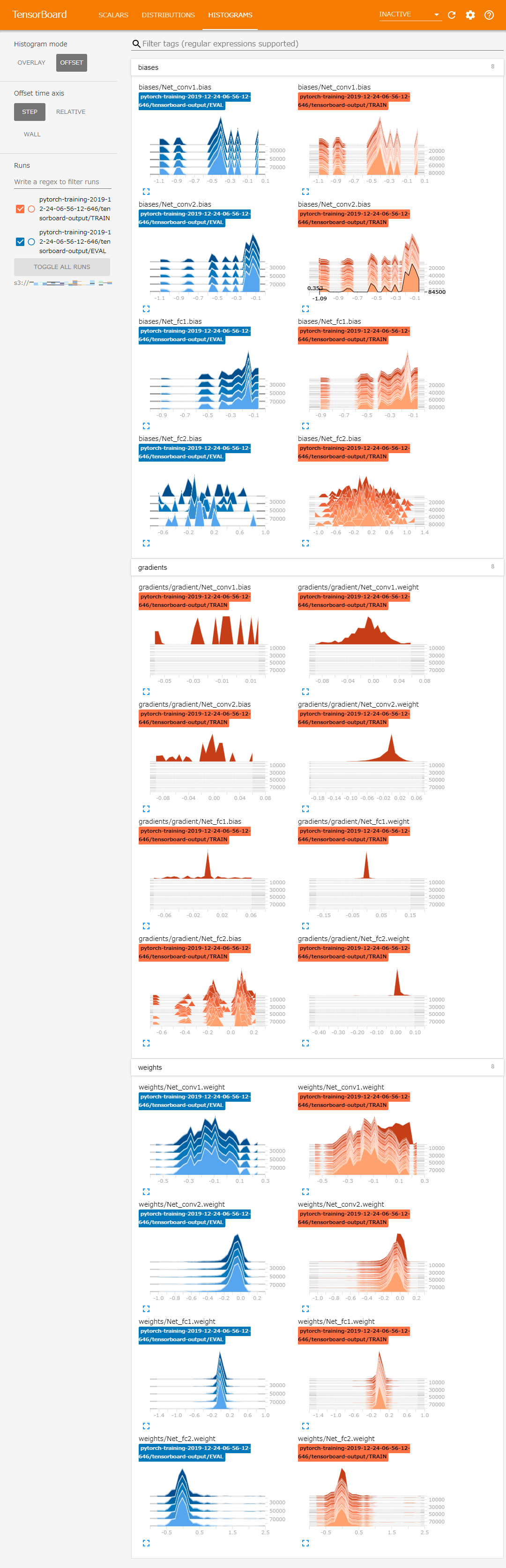
0~500ステップの間で勾配が0になり、パラメータの更新が行われず、lossが減少していないことが確認できます。
このように、Debugging Ruleでトレーニングの問題を検知し、S3に出力されたTensorを取得・可視化し、原因を調査することで、機械学習モデルの検証サイクルの効率化が期待できます。
まとめ
この記事では、PyTorchのモデルトレーニングで、SageMaker Debuggerを使う方法をご紹介しました。
SageMaker python SDKのEstimatorの引数で、Debug Hookの設定を指定できます。
SageMakerの対応するバージョンのDeep Learningコンテナを使えば、Debug Hookのセットアップはコンテナ側で自動で行われるため、スクリプト側の修正なしで使用できます。
Built in Collectionsを使うことで、取得したいモデル内部の値(Tensors)を簡単に指定でき、Built-in Rulesを使うことで、モデルの問題を簡単に自動で検知できます。
モデル内部の値はTensorBoard用のログとして出力できるため、
PyTorchなど、TensorFlow以外のフレームワークでも、TensorBoardの強力な可視化機能を簡単に使うことが出来ます。
このように、SageMaker Debuggerを使うことで、機械学習モデルの検証サイクルの効率化が期待できます。
記事の内容が少しでも参考になれば幸いです。
参考
- GitHub: awslabs/amazon-sagemaker-examples: amazon-sagemaker-examples/sagemaker-debugger/pytorch_custom_container/pytorch_byoc_smdebug.ipynb
- GitHub: awslabs/sagemaker-debugger: sagemaker-debugger/docs/pytorch.md
- Using PyTorch with the SageMaker Python SDK
- TensorFlow on S3
- Amazon SageMaker Debugger – Reacting to Cloudwatch Events from Rules

2017年4月、NHNテコラスに新卒入社。データサイエンスチームに所属し、AWSを活用したデータ分析サービスの設計開発を担当。


Recommends
こちらもおすすめ
-

Amazon S3とローカルPCをWinSCPでシンプルにファイル共有してみた
2024.4.30
-
【WinSCP】MFA環境でAmazon S3にアクセスするための手順まとめ
2025.1.27
-

[AWS re:Invent 2018]認定者ラウンジはすごかった #reinvent
2018.11.27

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16