Terraform で Amazon EC2 を複数台作成する
2022.4.7

はじめに
はじめまして。CloudLead チームの Cold-Airflow です。
Terraform でリソースを複数構築する場合、一つ一つresourceを追加する方法でもできますが、countを使えばよりコードが簡潔に構築ができます。
countを使った EC2 インスタンスを複数台構築する方法についてご紹介します。
開発環境
Terraform のバージョンは下記のとおりです。
C:\Users>terraform --version Terraform v1.1.6 on windows_amd64 + provider registry.terraform.io/hashicorp/aws v4.8.0
階層構図
ディレクトリに依存するコードは使用していないため一つのファイルに記述しても問題ないです。
本記事は下記ディレクトリ構成で作成しています。
C:. │ EC2.tf │ main.tf │ variables.tf └─ VPC.tf
EC2 構築
EC2 を複数台構築するにあたって下記内容を前提としています。
- EC2 を変数設定した数作成
- EC2 インスタンスに EIP を付与
- EC2 インスタンスに識別子を追加
- 異なる AZ に展開
- パブリックサブネットに配置
作成するリソースの構成図は下記のとおりです。
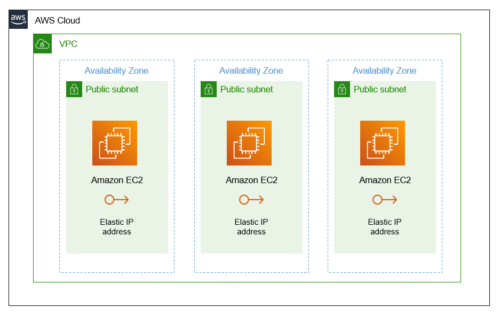
main
AWS のプロバイダーを定義しています。
リージョンはお好きなところで大丈夫です。
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
provider "aws" {
region = "us-east-1"
profile = "default"
}
variables
作成する台数やインスタンス名を変数を使って記述するため定義しています。
[]の値は各自で変更してください。
- Required
- instance_name → EC2 インスタンスを識別する際に利用
- count_instance → EC2 インスタンス台数を指定
- Option
- user_data
- sg_cidr_block
variable "instance_name" {
default = "[EC2の名前を指定]"
type = string
}
variable "count_instance" {
default = [EC2台数]
type = number
}
variable "user_data" {
default = <<-EOF
#!/bin/bash
yum update -y
EOF
}
variable "sg_cidr_block" {
default = "[接続元IPアドレスを指定]"
type = string
}
VPC の設定
下記リソースを作成します。
- VPC
- サブネット
- インターネットゲートウェイ
- ルートテーブル
data "aws_availability_zones" "available" {
state = "available"
}
resource "aws_vpc" "vpc" {
cidr_block = "10.0.0.0/16"
}
resource "aws_subnet" "public" {
count = var.count_instance
availability_zone = data.aws_availability_zones.available.names[count.index % length(data.aws_availability_zones.available.names)]
cidr_block = cidrsubnet(aws_vpc.vpc.cidr_block, 8, count.index + 1)
vpc_id = aws_vpc.vpc.id
}
resource "aws_internet_gateway" "main" {
vpc_id = aws_vpc.vpc.id
}
resource "aws_route_table" "public" {
vpc_id = aws_vpc.vpc.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.main.id
}
}
resource "aws_route_table_association" "public_association" {
count = var.count_instance
subnet_id = aws_subnet.public[count.index].id
route_table_id = aws_route_table.public.id
}
Point 1:AZ を Data Sources で取得
Data Source : aws_availability_zonesを使うことで、プロバイダーで設定されたリージョン内の AZ のリストを取得できます。
aws_availability_zones | Data Sources | hashicorp/aws | Terraform Registry
data "aws_availability_zones" "available" {
state = "available"
}
AZ を参照する場合は、数値で指定します。
インデックスの値は 0 から始まるので注意です。
availability_zone = data.aws_availability_zones.available.names[0]
aws_availability_zonesを参照する場合は、count_instanceで設定した数が AZ の個数を上回らないように工夫しています。
availability_zone = data.aws_availability_zones.available.names[count.index % length(data.aws_availability_zones.available.names)]
Point 2:count を指定してリソースを作成
count を指定してリソースの作成を行います。
サブネットや EC2 など複数リソースを作成するものがあるため、変数count_instanceを定義して同一の値を参照するようにしています。
メタ count 引数は整数を受け入れ、リソースまたはモジュールのその数のインスタンスを作成します。各インスタンスには個別のインフラストラクチャオブジェクトが関連付けられており、構成が適用されると、それぞれが個別に作成、更新、または破棄されます。
The count Meta-Argument – Configuration Language | Terraform by HashiCorp
count.indexで現在参照している値を取得できます。
subnet_id = aws_subnet.public[count.index].id
Point 3:複数 subnet の作成
異なる AZ のサブネットを作成しています。
resource "aws_subnet" "public" {
count = var.count_instance
availability_zone = data.aws_availability_zones.available.names[count.index % length(data.aws_availability_zones.available.names)]
cidr_block = cidrsubnet(aws_vpc.vpc.cidr_block, 8, count.index + 1)
vpc_id = aws_vpc.vpc.id
}
cidr_block は、cidrsubnet関数を使って CIDR が重複しないように定義しています。
cidrsubnet 指定された IP ネットワークアドレスプレフィックス内のサブネットアドレスを計算します。
cidrsubnet – Functions – Configuration Language | Terraform by HashiCorp
cidrsubnet関数の動作は下記のとおりです。
C:\Users>terraform console
> cidrsubnet("10.0.0.0/16", 8, 1)
"10.0.1.0/24"
> cidrsubnet("10.0.0.0/16", 8, 2)
"10.0.2.0/24"
> cidrsubnet("10.0.0.0/16", 8, 3)
"10.0.3.0/24"
EC2 の設定
下記リソースを作成します。
- EC2
- セキュリティグループ
- EIP
AMI や キーペアなどはお好きに設定してください。
今回の AMI は Amazon Linux2 で作成しています。
data "aws_ami" "amazon_linux2" {
most_recent = true
owners = ["amazon"]
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "root-device-type"
values = ["ebs"]
}
filter {
name = "name"
values = ["amzn2-ami-hvm-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
filter {
name = "block-device-mapping.volume-type"
values = ["gp2"]
}
}
data "aws_iam_policy_document" "assume_role" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["ec2.amazonaws.com"]
}
}
}
resource "aws_security_group" "instance" {
name = "ssh"
vpc_id = aws_vpc.vpc.id
}
resource "aws_security_group_rule" "instance_egress_all" {
security_group_id = aws_security_group.instance.id
type = "egress"
cidr_blocks = ["0.0.0.0/0"]
from_port = 0
to_port = 0
protocol = "all"
}
resource "aws_security_group_rule" "ssh_ingress" {
security_group_id = aws_security_group.instance.id
type = "ingress"
cidr_blocks = [var.sg_cidr_block]
from_port = 22
to_port = 22
protocol = "tcp"
}
resource "aws_instance" "example" {
count = var.count_instance
ami = data.aws_ami.amazon_linux2.id
instance_type = "t2.micro"
vpc_security_group_ids = [aws_security_group.instance.id]
subnet_id = aws_subnet.public[count.index % length(data.aws_availability_zones.available.names)].id
user_data = var.user_data
lifecycle {
ignore_changes = [
"ami", "user_data"
]
}
tags = {
"Name" = "${var.instance_name}-${count.index}"
}
}
resource "aws_eip" "example" {
count = var.count_instance
instance = aws_instance.example[count.index].id
vpc = true
}
Point 1:EC2 インスタンスに識別子を追加
タグを指定しないとどのインスタンスか判別できないため、count.indexを利用して各インスタンスごとに固有のタグを命名します。
tags = {
"Name" = "${var.project_name}-${count.index}"
}
リソース確認
下記のように変数を定義して実行してみます。
variable "instance_name" {
default = "cold-Airflow-ec2-multiple"
type = string
}
variable "count_instance" {
default = 2
type = number
}
Name タグはそれぞれで連番になっています。
C:\Users>aws ec2 describe-instances --filters "Name=instance-state-name,Values=running" --region us-east-1 --query "Reservations[].Instances[].{InstanceId:InstanceId,PrivateIpAddress:PrivateIpAddress,Name: Tags[?Key==`Name`].Value|[0]}"
[
{
"InstanceId": "i-02c1a4a4cdf84ba5c",
"PrivateIpAddress": "10.0.1.221",
"Name": "cold-Airflow-ec2-multiple-0"
},
{
"InstanceId": "i-00443c128317b66d7",
"PrivateIpAddress": "10.0.2.203",
"Name": "cold-Airflow-ec2-multiple-1"
}
]
まとめ
簡単に複数台を構築できるのは Terraform のいいところですね。
また、今回はパブリックサブネットだけでしたが、偶数番目はパブリック、奇数番目はプライベートに配置することも演算子を使えばできます。

2021年新卒入社。インフラエンジニアです。RDBが三度の飯より好きです。 主にデータベースやAWSのサーバレスについて書く予定です。あと寒いのは苦手です。


Recommends
こちらもおすすめ
-

Terraform AWS Moduleのすすめ
2022.5.25





Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16