Apache Sparkのパーティション分割について


はじめに
こんにちは。
この記事ではAmazon EMRサービスでApache Sparkアプリケーションを作りながらSparkのDataFrameのパーティション分割について調べた内容と分かったことについて説明します。
サンプルコードはJava言語になっています。
DataFrameのパーティション分割
Apache Spark上のデータはパーティション単位に分割され、分散処理されます。
ここではDataFrameのパーティション分割を中心に説明していきます。
初期パーティション分割
例えば、以下のようにDataFrameを生成する場合、生成されたDataFrameはSparkSessionを開始するときに指定したCPUコア数の3つのパーティションに分割されたDataFrameになります。
// 使用するCPUコア数を3個に指定したLocal modeでSparkSessionを開始する
SparkSession sparkSession = SparkSession.builder().master("local[3]").getOrCreate();
// idカラムに1~5の値の5個のレコードを持つDataFrameを生成する
Dataset df = sparkSession.range(1, 6).toDF("id");
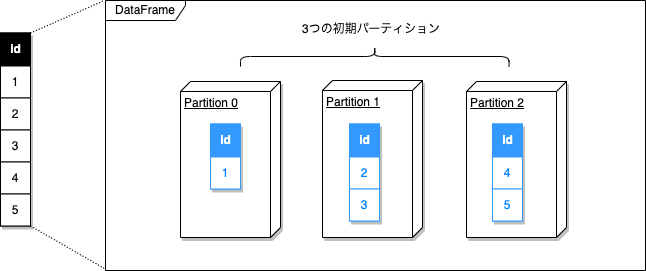
DataFrameの作成時に自動で分割されるパーティション数はDataFrame作成元のデータ(インライン/RDD/ファイル/DataFrame)によって異なります。
| 分類 | DataFrame作成時の初期パーティション数 | デフォルト値 | 例 |
|---|---|---|---|
| インラインコレクション | spark.default.parallelism |
|
sparkSession.range(1, 6).toDF(“id”) |
| RDD | RDDのパーティション数 | ― | sparkSession.createDataFrame(rdd, df.schema()) |
| ファイル | (ファイルサイズ / spark.sql.files.maxPartitionBytes) + 1 | spark.sql.files.maxPartitionBytesのデフォルト値は128MB | sparkSession.read().parquet(“…”) |
| Shuffleを伴うDataFrameの変換 | spark.sql.shuffle.partitions | 200 | df.join(…) |
パーティションの確認
分割されたパーティションの数やパーティションの状態(空きパーティションスロットの有無など)、実際に付与されたパーティション番号を確認することも可能です。
// パーティション数の確認 ①
System.out.println("numOfPartitions=" + df.toJavaRDD().getNumPartitions());
// パーティション状態の確認 ②
System.out.println("partitions=" + df.toJavaRDD().glom().collect());
// 付与されているパーティション番号の確認 ③
df.withColumn("partition_id", spark_partition_id()).show();
実行結果
// ①
numOfPartitions()=3
// ②
partitions=[[ [1] ],
[ [2], [3] ],
[ [4], [5] ]]
// ③
+---+------------+
| id|partition_id|
+---+------------+
| 1| 0|
| 2| 1|
| 3| 1|
| 4| 2|
| 5| 2|
+---+------------+
パーティションの分散処理
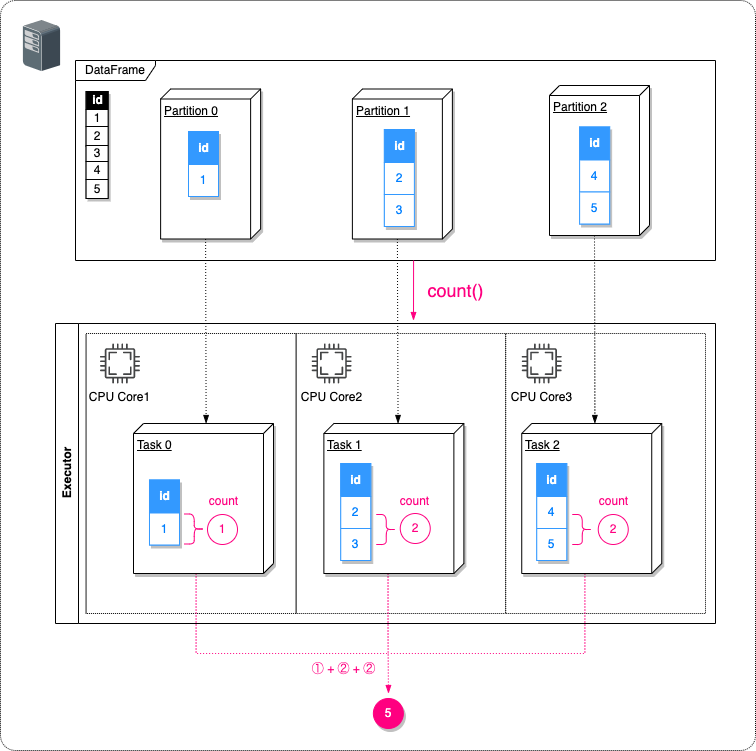
作成したDataFrameのレコード件数を求める場合、レコード件数を求める処理はそのパーティションの数と同じ数のCPU上にTaskとして分散されて並列処理されます。
// 生成したDataFrameのレコード件数を求める ①
int count = df.count();
// レコード件数を表示する ②
System.out.println("count=" + count);
実行結果
// ① (3つのTaskで分散処理される) [Executor task launch worker for task 0.0 in stage 0.0 (TID 0)] INFO org.apache.spark.executor.Executor - Running task 0.0 in stage 0.0 (TID 0) [Executor task launch worker for task 1.0 in stage 0.0 (TID 1)] INFO org.apache.spark.executor.Executor - Running task 1.0 in stage 0.0 (TID 1) [Executor task launch worker for task 2.0 in stage 0.0 (TID 2)] INFO org.apache.spark.executor.Executor - Running task 2.0 in stage 0.0 (TID 2) // ② count=5
パーティションの再分割(repartition)
DataFrame作成時の初期パーティション数をあとで変更することが可能です。
repartition、repartitionByRangeメソッドでパーティション数を変更したり、coalesce(int numPartitions)メソッドでパーティション数を減らせます。
SparkSession sparkSession = SparkSession.builder().master("local[3]").getOrCreate();
Dataset dfBefore = sparkSession.range(1, 6).toDF("id");
System.out.println("変更前: numOfPartitions=" + dfBefore.toJavaRDD().getNumPartitions());
// パーティションを再分割する。
Dataset dfAfter = dfBefore.repartition(5);
System.out.println("変更後: numOfPartitions=" + dfAfter.toJavaRDD().getNumPartitions());
実行結果
変更前: numOfPartitions=3 変更後: numOfPartitions=5
パーティションの再分割はいつ行うのか
1.特定のカラムの値の種類ごとにまとめて処理が必要な場合
StructType schema = DataTypes.createStructType(
new StructField[]{
createStructField("id", IntegerType, false),
createStructField("year", IntegerType, false),
});
List<Row> rows = List.of(
RowFactory.create(1, 2020),
RowFactory.create(2, 2020),
RowFactory.create(3, 2021),
RowFactory.create(4, 2021),
RowFactory.create(5, 2022)
);
SparkSession sparkSession = SparkSession.builder().master("local[3]").getOrCreate();
Dataset df = sparkSession.createDataFrame(rows, schema);
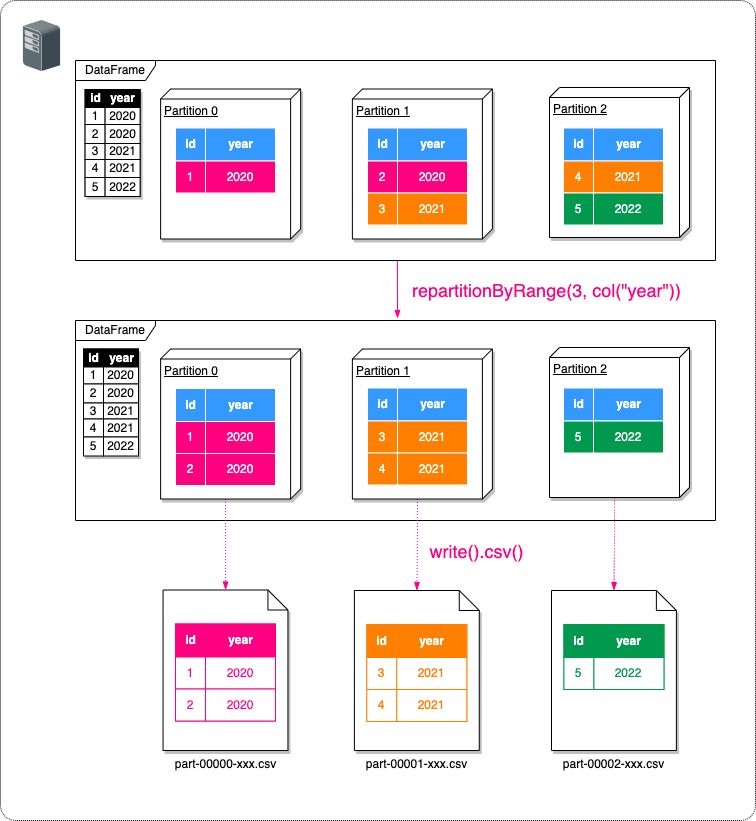
// yearカラムの同じ値ごとにまとめてCSVファイルに出力するためにパーティションの再分割を行う
Dataset dfByYear = df.repartitionByRange(3, col("year"));
// CSVファイルとして出力する
dfByYear.write().mode(SaveMode.Overwrite).option("header", "true").csv("/tmp");
2.出力ファイル数を変更したい場合
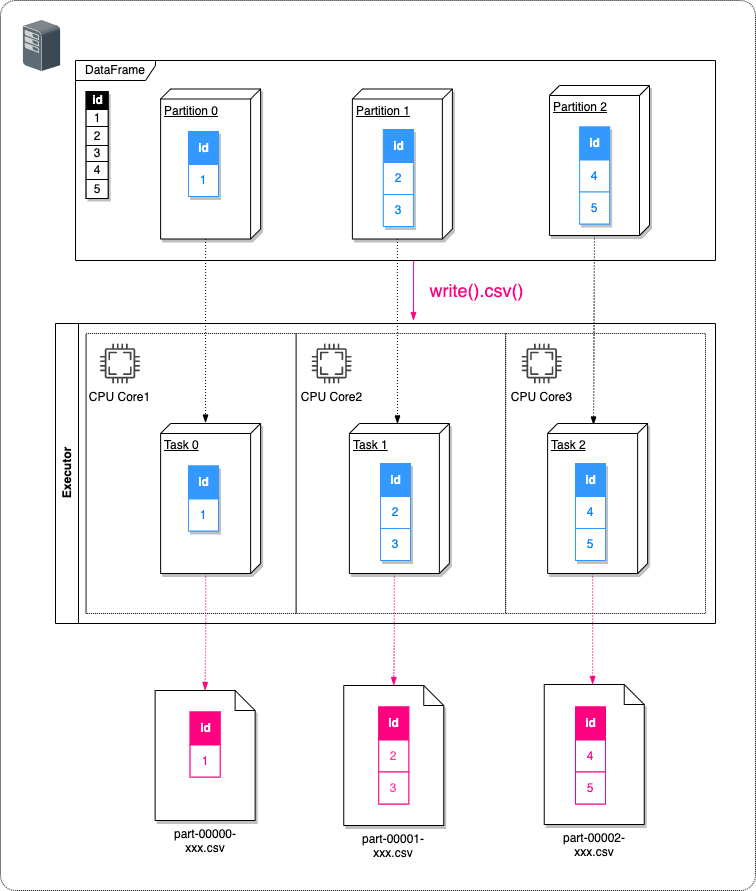
DataFrameをファイルとして出力する場合、出力ファイルはDataFrameのパーティションごとに分割されて出力されます。
SparkSession sparkSession = SparkSession.builder().master("local[3]").getOrCreate();
Dataset df = sparkSession.range(1, 6).toDF("id");
// 初期パーティションのままCSVファイルに出力する。
df.write().mode(SaveMode.Overwrite).option("header", "true").csv("/tmp");
| /tmp/part-00000-bba3c5dc-a262-4774-b130-3934c2fdad84-c000.csv |
|---|
| id 1 |
| /tmp/part-00001-bba3c5dc-a262-4774-b130-3934c2fdad84-c000.csv |
|---|
| id 2 3 |
| /tmp/part-00002-bba3c5dc-a262-4774-b130-3934c2fdad84-c000.csv |
|---|
| id 4 5 |
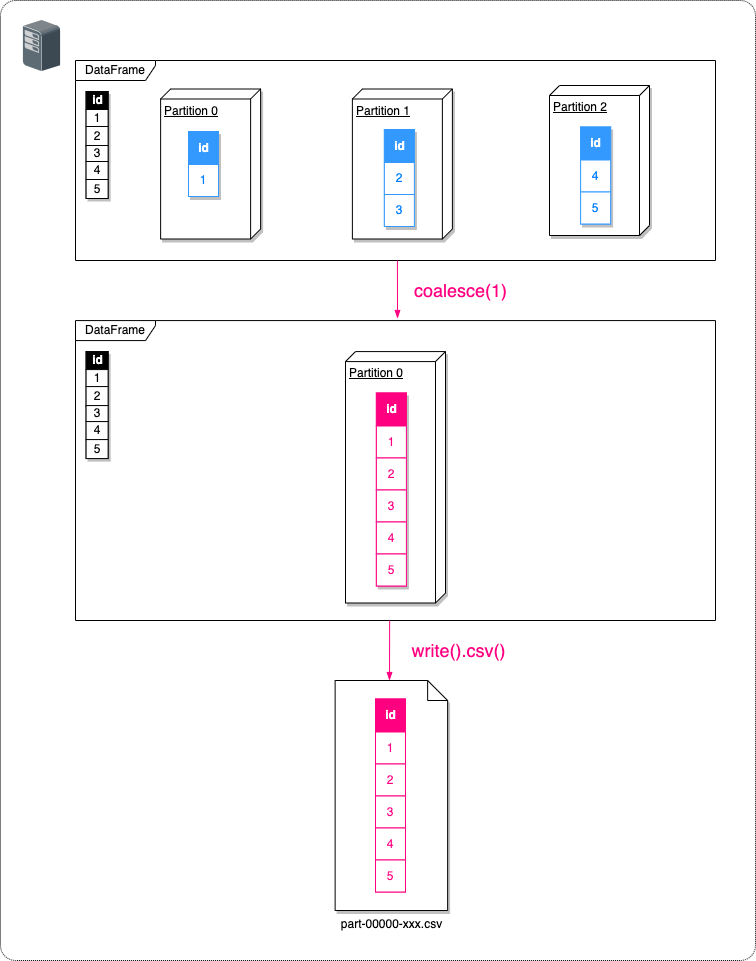
DataFrameのパーティションを再分割して出力されるファイル数を変更できます。
SparkSession sparkSession = SparkSession.builder().master("local[3]").getOrCreate();
Dataset df = sparkSession.range(1, 6).toDF("id");
// 出力ファイル数を1個にするために、パーティション数を1に変更する
Dataset dfWithSinglePartition = df.coalesce(1);
// CSVファイルに出力する
dfWithSinglePartition.write().mode(SaveMode.Overwrite).option("header", "true").csv("/tmp");
| /tmp/part-00000-bba3c5dc-a262-4774-b130-3934c2fdad84-c000.csv |
|---|
| id 1 2 3 4 5 |
パーティションを再分割するときの注意点
repartition系のメソッドを使ってパーティション数を変更可能ですが、注意が必要です。
1.引数numPartitionsの意味
repartition系のメソッドの引数で指定するint numPartitionsはデータが入られるパーティションのスロット総数ですのでパーティションの再分割後にデータが入ってない空きパーティションになる場合があります。
この空きパーティションは出力ファイルとしては出力されません。
SparkSession sparkSession = SparkSession.builder().master("local[3]").getOrCreate();
Dataset dfBefore = sparkSession.range(1, 6).toDF("id");
System.out.println("変更前: numOfPartitions=" + dfBefore.toJavaRDD().getNumPartitions());
// パーティションを再分割する。
int numPartitions = 10
Dataset dfAfter = dfBefore.repartition(numPartitions);
System.out.println("変更後: numOfPartitions=" + dfAfter.toJavaRDD().getNumPartitions());
System.out.println("partitions=" + dfAfter.toJavaRDD().glom().collect());
dfAfter.write().mode(SaveMode.Overwrite).option("header", "true").csv("/tmp");
変更前: numOfPartitions=3
partitions=[[ [1] ],
[ [2], [3] ],
[ [4], [5] ]]
// numOfPartitionsは10だが、実際データが入っているパーティションは5個
変更後: numOfPartitions=10
partitions=[[ [4] ],
[ [1] ],
[],
[],
[],
[],
[ [3] ],
[ [2] ],
[],
[ [5] ]]
| /tmp/part-00000-b96beacc-5805-42c0-9fb5-a42fc91bc2c8-c000.csv |
|---|
| id 4 |
| /tmp/part-00000-b96beacc-5805-42c0-9fb5-a42fc91bc2c8-c000.csv |
|---|
| id 1 |
| /tmp/part-00000-b96beacc-5805-42c0-9fb5-a42fc91bc2c8-c000.csv |
|---|
| id 3 |
| /tmp/part-00000-b96beacc-5805-42c0-9fb5-a42fc91bc2c8-c000.csv |
|---|
| id 2 |
| /tmp/part-00000-b96beacc-5805-42c0-9fb5-a42fc91bc2c8-c000.csv |
|---|
| id 5 |
2.メソッドごとに適用されるパーティション再分割ロジックが異なる
repartition系のメソッドは種類によってパーティション分割手法が異なります。
| メソッド名 | パーティション分割手法 |
|---|---|
| repartition(int numPartitions, Column… partitionExprs) | HashPartitioning |
| repartition(int numPartitions) | RoundRobinPartitioning |
| repartitionByRange(int numPartitions, Column… partitionExprs) | RangePartitioning |
3.パーティション再分割メソッドの制約
例えば、特定カラムの値の種類ごとにパーティションの再分割を行いたいときにHashPartitioningベースのrepartition(int numPartitions, Column… partitionExprs)メソッドを利用したパーティション再分割の場合、対象カラムのカーディナリティと同じ個数のパーティションスロット数(numPartitions)を指定しても対象カラムのカーディナリティ数のパーティションに分割されない場合があります。
SparkSession sparkSession = SparkSession.builder().master("local[3]").getOrCreate();
// idカラムに1~5の値の5個のレコードを持つDataFrameを生成する
Dataset df = sparkSession.range(1, 6).toDF("id");
df.show();
// idカラムを対象にidカラムのカーディナリティと同じ値のパーティションスロット数で再分割を行う
Dataset dfById = df.repartition(5, col("id"));
System.out.println("numOfPartitions=" + dfById.toJavaRDD().getNumPartitions());
System.out.println("partitions=" + dfById.toJavaRDD().glom().collect());
// idカラムの値は1~5(カーディナリティは5)
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
| 5|
+---+
// idカラムのカーディナリティと同じ値を再分割するパーティションスロット数として指定しても
numOfPartitions=5
// idカラムの異なる値ごとに完全には分割されない
partitions=[[ [4] ],
[ [3] ],
[ [2], [5] ], // 2, 5が同じパーティションになっている
[ [1] ]]
repartition(int numPartitions, Column… partitionExprs)メソッドはパーティション分割手法としてHashPartitioningが使われています。
org.apache.spark.sql.catalyst.plans.physical.HashPartitioning
def partitionIdExpression: Expression = Pmod(new Murmur3Hash(expressions), Literal(numPartitions))
HashPartitioningの場合データが格納されるパーティション番号(PartitionId)は対象カラムの値のハッシュ値を指定のパーティションスロット数(numPartitions)で割ったときの余り値とするモジュロ演算によって計算されるので
パーティション番号(PartitionId) = 対象カラムの値のハッシュ値 % 指定のパーティションスロット数(numPartitions)
除数の指定のパーティションスロット数(numPartitions)が小さいとモジュロ演算結果が同じ値になってしまうケースが多くなるからです。
ソースコード内部のパーティション番号の計算処理を真似してカラムで表示してみたら以下のようにパーティション番号が決められて①と②のパーティション番号が同じ値になってしまうことが分かります。
int numOfPartitionSlots = 5;
Dataset<Row> dfWith5PartitionSlots = df
.withColumn("hash_id", hash(col("id")))
.withColumn("partition_id", pmod(hash(col("id")),
dfWith5PartitionSlots.show();
+---+-----------+------------+ | id| hash_id|partition_id| +---+-----------+------------+ | 1|-1712319331| 4| // -1712319331 % 5 = 4 | 2| -797927272| 3| // -797927272 % 5 = 3 (①) | 3| 519220707| 2| // 519220707 % 5 = 2 | 4| 1344313940| 0| // 1344313940 % 5 = 0 | 5| 1607884268| 3| // 1607884268 % 5 = 3 (②) +---+-----------+------------+
numPartitionsが大きいとモジュロ演算結果の範囲が広くなって同じ値になるケースが減り、
idカラムの値ごとに異なるパーティション番号が付与されることが分かります。
int numOfPartitionSlots = 100;
Dataset dfWith100PartitionSlots = df
.withColumn("hash_id", hash(col("id")))
.withColumn("partition_id", pmod(hash(col("id")),
dfWith100PartitionSlots.show();
+---+-----------+------------+ | id| hash_id|partition_id| +---+-----------+------------+ | 1|-1712319331| 69| // -1712319331 % 100 = 69 | 2| -797927272| 28| // -797927272 % 100 = 28 | 3| 519220707| 7| // 519220707 % 100 = 7 | 4| 1344313940| 40| // 1344313940 % 100 = 40 | 5| 1607884268| 68| // 1607884268 % 100 = 68 +---+-----------+------------+
特定カラムの値の種類ごとにパーティションの再分割を行いたい場合、HashPartitioningベースのパーティション再分割メソッドだとすべての種類の値に対してパーティション番号が同じ値にならない適切なパーティションスロット数(numPartitions)を決められない場合も考えられます。
上記の例の場合、RangePartitioningベースのrepartitionByRange(int numPartitions, Column… partitionExprs)メソッドを利用することでidカラムのカーディナリティと同じ値のパーティションスロット数を指定して要件通りのパーティションに分割することができます。
// idカラムを対象にidカラムのカーディナリティと同じ値のパーティションスロット数でパーティション再分割を行う
Dataset dfById = df.repartitionByRange(5, col("id"));
System.out.println("numOfPartitions=" + dfById.toJavaRDD().getNumPartitions());
System.out.println("partitions=" + dfById.toJavaRDD().glom().collect());
// idカラムのカーディナリティと同じ値のパーティションスロット数を指定
numOfPartitions=5
// idカラムの異なる値ごとに分割される
partitions=[[ [1] ],
[ [2] ],
[ [3] ],
[ [4] ],
[ [5] ]]
パーティション再分割の要件によって既存のrepartition系のメソッドをそのまま適用できない場合はカスタムパーティショナーを作成する方法があります。
カスタムパーティショナー
カスタムパーティショナーを作成してパーティション再分割時のパーティション番号を求めるロジックをカスタムすることができます。
例えば、idカラムでパーティションする場合はidカラムの値のハッシュ値ではなくカラムの値をもとに同じ値にならないようにパーティション番号を直接計算することも可能です。
org.apache.spark.Partitioner
abstract class Partitioner extends Serializable {
def numPartitions: Int
def getPartition(key: Any): Int
}
// カスタムパーティショナークラス
public class IdPartitioner extends Partitioner {
private final int numPartitions;
public IdPartitioner(int numPartitions) {
this.numPartitions = numPartitions;
}
@Override
public int numPartitions() {
return numPartitions;
}
@Override
public int getPartition(Object key) {
int partitionId = calcPartitionId(key);
return partitionId;
}
// パーティション番号を計算する。(パーティション番号 = idカラムの値 - 1)
private int calcPartitionId(Object id) {
return Math.toIntExact((long) id - 1);
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (!(o instanceof IdPartitioner)) {
return false;
}
IdPartitioner that = (IdPartitioner) o;
return new EqualsBuilder().append(numPartitions, that.numPartitions).isEquals();
}
@Override
public int hashCode() {
return new HashCodeBuilder().append(numPartitions).toHashCode();
}
}
Dataset<Row> df = sparkSession.range(1, 6).toDF("id");
// カスタムパーティショナーの生成、既存のDataFrameのRDDに適用
JavaRDD<Row> rdd = df.toJavaRDD()
.mapToPair((PairFunction<Row, Long, Row>) row -> new Tuple2<>(row.getAs("id"), row))
.partitionBy(new IdPartitioner(5)).map(x -> x._2);
// カスタムパーティショナーが適用されたDataFrameを生成
Dataset<Row> dfWithCustomPartitioner = sparkSession.createDataFrame(rdd, df.schema());
numOfPartitions=5
// idカラムの異なる値ごとに分割される
partitions=[[ [1] ],
[ [2] ],
[ [3] ],
[ [4] ],
[ [5] ]]
参考


Recommends
こちらもおすすめ
-

Google BigQueryからAmazon Redshiftにデータを移行してみる
2019.11.29
-

社内エンジニア読書会の進め方 ーAI・機械学習チーム編ー
2019.4.4
-

機械学習の受託案件を通じて気づいた5つのこと
2019.3.8

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16