Airflowのクラス設計のTips

Airflowのクラス設計のTips
はじめに
こんにちは。データサイエンスチームのmotchieです。
弊社では C-Chorus というブランドでクラウドのリセールサービスをご提供しています。リセールサービスの裏側では、クラウド利用料金の計算や、そのために必要なデータの整備など、各種のワークフローが実行されています。
先日、クラウド利用料金の計算パイプラインのリプレイスを実施しました。新しいパイプラインでは、ワークフローの複雑さや、実行状況のモニタリングのしやすさなどの観点から、ワークフロー管理では Apache Airflow を採用することになりました。
この記事では、Airflowでワークフローを実装していく中で直面したコードの保守性の課題と、それを解決するために行なったクラス設計をご紹介します。なお、Airflowとは何かといった基本的な情報は省きますので、こちらを知りたい場合は公式サイトなどをご参照ください。
c.f. Apache Airflow
この記事で紹介するTips
| 番号 | 課題 | 例 | 解決策(Tips) |
|---|---|---|---|
| 1 | DAGが肥大化してタスクの修正がしづらい | 「実行するタスクの設定に変更が必要だが、どこを修正すれば良いのか分かりづらい。ワークフローの実装が長すぎて何が何だか…」 | タスクの生成機能の分離 |
| 2 | タスクを跨いだ値の参照で静的解析や補完が効かない | 「他のタスクが出力した値を読み込みたいが、どのような値が取得できるのかわからない。IDEで属性名を補完したり、linterでデータ型の問題を検知できれば…」 | タスク出力のデータ構造をクラス化 |
| 3 | 共通のタスク群を実行するDAG間で実装が重複 | 「同じタスク群を実行するワークフローが複数あり、ワークフローごとに同じ実装をしている。変更があったときに修正が大変…」 | Builderパターンによる段階的なタスク追加 |
1. [課題] DAGが肥大化してタスクの修正がしづらい
Airflowのワークフロー(DAG)の構築は以下の流れで行われます。
- DAGインスタンスを生成
- タスクを生成
- タスク間の依存関係を定義
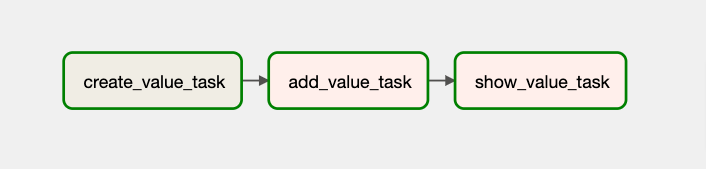
例えば、以下のコード例は3つのタスクから構成されるDAGを構築しています。まず、create_value_task タスクで初期値(10)を出力し 次に add_value_task タスクで出力値を読み込んで100を加算し、最後に show_value_task タスクで加算後の値を表示しています。
from airflow.models.taskinstance import TaskInstance
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from typing import Dict
from airflow.models.dag import DAG
import pendulum
# --- 1. DAGインスタンスを生成 ---
dag = DAG("bad_dag_example", start_date=pendulum.datetime(
2021, 1, 1, tz="UTC"), schedule_interval=None, catchup=False, tags=["blog"])
# --- 2. タスクを生成 ---
# 初期値を生成するタスク
create_value_task = BashOperator(
task_id="create_value_task",
bash_command="echo 10",
dag=dag,
)
# 加算処理を行うタスク
def add_value(ti: TaskInstance) -> Dict[str, int]:
task_output_value = int(ti.xcom_pull(task_ids="create_value_task"))
new_value = task_output_value + 100
return {"new_value": new_value}
add_value_task = PythonOperator(
task_id="add_value_task",
python_callable=add_value,
dag=dag,
)
# 最終的な値を表示するタスク
def show_value(ti: TaskInstance) -> None:
task_output_dict = ti.xcom_pull(task_ids="add_value_task")
new_value = task_output_dict["new_value"]
print(f"final value is {new_value}")
show_value_task = PythonOperator(
task_id="show_value_task",
python_callable=show_value,
dag=dag,
)
# --- 3. タスク間の依存関係を定義 ---
create_value_task >> add_value_task >> show_value_task
2. タスクを生成 の部分では、各タスクがどのようなOperator/パラメータ/設定で処理を実行するのか記述する必要があり、コード量が多めです。ワークフローが複雑になるにつれ、DAG構築処理は数百行に及ぶ長大なコードになり、可読性と保守性の課題に直面していくことになりました。
1. [解決策] タスクの生成機能の分離
オブジェクト指向プログラミングでは、可読性/柔軟性/保守性の高い設計を実現するためのSOLIDと呼ばれる5つの原則が知られています。SOLID原則のうちの1つ、単一責任の原則は、1つのクラスは1つの責任(機能)のみを持つべきという原則です。
前述のサンプルコードでは、DAG構築の中でタスクの実行方法や設定を記述していましたが、タスクの生成方法については、別のクラスに機能を切り出すことが可能です。
それにより、DAGの構築処理では、タスク間の依存関係の記述に焦点を絞ることができ、DAG構築のコードがコンパクトになります。加えて、タスクの実行方法や設定を各タスクの生成クラスで定義することで、タスクに変更が発生した際に修正範囲が明確になるメリットがあります。
具体的な実装例としては、以下のように、タスク生成機能の抽象クラス AbstractTaskFactory を作成し、 ファクトリーメソッド create がOperatorクラスのインスタンスを返すように定義できます。タスクごとに AbstractTaskFactory を継承して子クラスを作成し、Operator/パラメータ/設定を記述し、create メソッドで生成したOperatorを返します。DAG構築処理では、AbstractTaskFactory の子クラスを使ってタスクを生成します。
# 本実装は、タスク生成機能の呼び出し方のイメージを伝えるためのサンプルで、
# 本記事でご紹介する最終的な実装方法/呼び出し方と異なる点にご注意ください
# 最終的な実装は「クラス図とコード」の章をご確認ください
# Tips.1 タスクの生成機能の分離
class AbstractTaskFactory(ABC):
"""タスクの生成機能の抽象クラス"""
def __init__(self, dag: DAG, task_id: str) -> None:
self.dag = dag
self.task_id = task_id
@abstractmethod
def create(self) -> BaseOperator:
pass
class CreateValueTaskFactory(AbstractTaskFactory):
"""初期値を作成するタスクを生成する"""
def __init__(self, dag: DAG, task_id: str) -> None:
super().__init__(dag=dag, task_id=task_id)
@property
def bash_command(self) -> str:
return "echo 10"
def create(self) -> BashOperator:
return BashOperator(
task_id=self.task_id,
dag=self.dag,
bash_command=self.bash_command,
)
class AddValueTaskFactory(AbstractTaskFactory):
""" 加算処理を行うタスクを生成する"""
def __init__(self, dag: DAG, task_id: str, created_value: str) -> None:
super().__init__(dag=dag, task_id=task_id)
self.created_value = created_value
def python_callable(self, ti: TaskInstance, templates_dict: Dict[str, int]) -> Dict[str, Any]:
created_value = int(templates_dict["created_value"])
new_value = created_value + 100
return {"new_value": new_value}
def create(self) -> PythonOperator:
return PythonOperator(
task_id=self.task_id,
dag=self.dag,
python_callable=self.python_callable,
templates_dict={"created_value": self.created_value},
)
class ShowValueTaskFactory(AbstractTaskFactory):
"""最終的な値を表示するタスクを生成するクラス"""
def __init__(self, dag: DAG, task_id: str, value_to_show: str) -> None:
super().__init__(dag=dag, task_id=task_id)
self.value_to_show = value_to_show
def python_callable(self, ti: TaskInstance, templates_dict: Dict[str, int]) -> None:
value_to_show = int(templates_dict["value_to_show"])
print(f"final value is {value_to_show}")
def create(self) -> PythonOperator:
return PythonOperator(
task_id=self.task_id,
dag=self.dag,
python_callable=self.python_callable,
templates_dict={"value_to_show": self.value_to_show},
)
# DAGの構築
# --- 1. DAGインスタンスを生成 ---
dag = DAG("bad_dag_example", start_date=pendulum.datetime(
2021, 1, 1, tz="UTC"), schedule_interval=None, catchup=False, tags=["blog"])
# --- 2. タスクを生成 ---
create_value_task = CreateValueTaskFactory(task_id="create_value_task", dag=dag)
add_value_task = AddValueTaskFactory(task_id="add_value_task", dag=dag, created_value="{{ ti.xcom_pull(task_ids='create_value_task') }}")
show_value_task= ShowValueTaskFactory(task_id="show_value_task", dag=dag, value_to_show="{{ ti.xcom_pull(task_ids='add_value_task')['new_value'] }}")
# --- 3. タスク間の依存関係を定義 ---
create_value_task >> add_value_task >> show_value_task
Tips.1 の内容をまとめると、以下のようになります。
- 課題
- DAGが肥大化してタスクの修正がしづらい
- 解決策
- タスクの生成機能の分離
- 具体的な実装例
- タスク生成機能の抽象クラス
AbstractTaskFactoryを定義 - タスクごとに
AbstractTaskFactoryクラスを継承し、Operatorの生成方法を実装 - DAG構築処理では、
AbstractTaskFactoryの子クラスを使ってタスクを生成
- タスク生成機能の抽象クラス
- 効果
- DAGの構築処理では、タスク間の依存関係の記述に焦点を絞ることができ、DAG構築のコードがコンパクトに
- タスクの実行方法や設定を各タスクの生成クラスで定義することで、タスクに変更が発生した際に修正しやすい
2. [課題] タスクを跨いだ値の参照で静的解析や補完が効かない
Airflowでは、あるタスクが出力した値を後続のタスクから読み込む場合 XComs という仕組みを使い、AirflowのメタデータDBを介して値のやりとりができます。
XComs では、各タスクは key を指定して値を出力(push)し、後続のタスクでは、dag_id , task_id, key を指定して、指定のDAG/タスクの出力値を取得(pull)します。以下はXComsに値を保存する例です。
# XComsで値を出力する例
def export_value_to_xcoms(ti: TaskInstance, **kwargs: Dict[str, Any]) -> Dict[str, Any]:
# TaskInstanceを使ってXComsに値をpushする
ti.xcom_push(key="my_key", value={"hoge": 1})
# key="return_value" でXComsに自動でpushされる(do_xcom_push=Trueの場合(デフォルトでTrue))
return {"fuga": 2}
op_1 = PythonOperator(
task_id="task_1",
python_callable=export_value_to_xcoms,
)
XComsに出力された値の取得では、AirflowのJinja Templatingの仕組みが活用できます。XComsから値を取得する処理をテンプレート文字列として記述し、テンプレート文字列をタスクのパラメータに設定することが可能です。
DAGを構築するタイミングでは、まだ実際のタスクは実行されていないため、XComsから実際の値を取得することはできません。そこで、テンプレート文字列として値の取得処理を記述し、タスク実行時にJinjaテンプレートを評価、XComsの値に置換することで、タスクを跨いだ値のやりとりが可能です(TaskInstanceを使って、タスク実行時にXComsから値を取得することも可能です)。
# XComsで値を取得する例
def read_value_from_xcoms(ti: TaskInstance, templates_dict: Dict[str, int]) -> None:
# PythonOperatorの場合、templates_dictとして入力されたJinjaテンプレート文字列は
# タスクの実行時に評価/置換された値として取得できます
hoge_value = templates_dict["hoge"]
# TaskInstanceを使って、XComsから値を取得できます
fuga_value = ti.xcom_pull(task_ids="task_1", key="return_value")
op_2 = PythonOperator(
task_id="task_2",
python_callable=read_value_from_xcoms,
# Jinjaテンプレート文字列でXComsからの値の取得を記述できます(タスク実行時に実際の値に置換が行われます)
templates_dict={"hoge": "{{ ti.xcom_pull(task_ids='task_1', key='my_key')['hoge'] }}",
)
Airflow内のPythonタスクについては task decoratorを使い、関数の戻り値に型ヒントを付与することで、linterでデータ型のチェックが可能です。
しかし、それ以外のケースでは、ti.xcom_pull で取得された値のデータ型や含まれるKey(辞書型の値の場合)は明らかではなく、linterによるデータ型や属性のチェックや、IDEによる補完が効かない課題があります。
実際、クラウド利用料金の計算パイプラインには、タスクで外部リソース(e.g. AWS Lambda)を実行し、出力値をタスクを跨いで参照するケースが複数ありました。外部リソースの出力する値に仕様変更があった際、修正範囲の洗い出しに苦労し、静的解析やコード補完の機能の必要性を感じました。
2. [解決策] タスク出力のデータ構造をクラス化
上記の課題の解決策として、タスク出力のデータ構造をクラスとして定義し、クラスの属性を介して値を参照する設計が可能です。
前述の通り、XComsから値を取得する場合、Jinjaテンプレート文字列(str)として表現する方法と、TaskInstanceを使ってXComsから実際の値を取得する方法がありました。
そのため、タスクの出力値のデータ構造を定義していく際、これら2つの表現をそのまま1つのクラスにまとめようとすると、各属性のデータ型が Union[str, int] (例えば実際の値はint型の場合)となり、データ型の不一致の検出が難しくなります。
この課題を解決するために、まず、XComsから取得した値を表現するクラスを作成しています(XComsValue)。これにより、XComsから実際に取得した値を持クラスと、XComsから値を取得するためのテンプレート文字列の表現を持つクラスを、それぞれ別クラスに定義する必要がなくなります。
各タスク出力値のデータ構造はそれぞれ1つのクラスとして定義し、DAGの生成時かタスクの実行時かによって、テンプレート文字列(str型のtemplate属性)と実際の値(データ型をジェネリクスで指定したvalue属性)の間で表現を切り替えつつ、出力値へのアクセスが可能になります。
T = TypeVar("T")
class XComsValue(Generic[T]):
"""XComsから取得した値
実際に取得した値(value)とJinjaテンプレート文字列(template)の両方の表現を兼ね備える
"""
def __init__(
self, task_id: str, xcoms_key: str, ti: Optional[TaskInstance] = None
) -> None:
self.task_id = task_id
self.xcoms_key = xcoms_key
self.ti = ti
@property
def value(self) -> T:
"""XComsから取得したタスク出力の値"""
if self.ti is None:
raise ValueError(
"Instance variable 'ti' must not be None to pull value from TaskInstance."
)
xcoms_pulled_value: Optional[T] = self.ti.xcom_pull(
task_ids=self.task_id, key=self.xcoms_key
)
if xcoms_pulled_value is None:
raise ValueError(
f"Value not found in XComs. task_ids={self.task_id}, key={self.xcoms_key}"
)
return xcoms_pulled_value
@property
def template(self) -> str:
"""XComsから値を取得するJinjaテンプレート文字列"""
return (
f"{{{{ ti.xcom_pull(task_ids='{self.task_id}', key='{self.xcoms_key}')}}}}"
)
class XComsValueInDict(XComsValue[T]):
"""XComsから取得した辞書型の値に含まれる特定のkeyの値"""
def __init__(
self,
task_id: str,
xcoms_key: str,
dict_key: str,
ti: Optional[TaskInstance] = None,
) -> None:
super().__init__(task_id=task_id, xcoms_key=xcoms_key, ti=ti)
self.dict_key = dict_key
@property
def value(self) -> T:
"""XComsから取得した辞書からkeyを指定して抽出した値"""
if self.ti is None:
raise ValueError(
"Instance variable 'ti' must not be None to pull value from TaskInstance."
)
xcoms_pulled_value: Optional[Dict[str, T]] = self.ti.xcom_pull(
task_ids=self.task_id, key=self.xcoms_key
)
if xcoms_pulled_value is None:
raise ValueError(
f"Value not found in XComs. task_ids={self.task_id}, key={self.xcoms_key}"
)
if not isinstance(xcoms_pulled_value, dict):
raise ValueError("Output value is not in dict type")
return xcoms_pulled_value[self.dict_key]
@property
def template(self) -> str:
"""XComsから辞書型の値を取得し、keyを指定して中身を取り出すJinjaテンプレート文字列"""
return f"{{{{ ti.xcom_pull(task_ids='{self.task_id}', key='{self.xcoms_key}')['{self.dict_key}']}}}}"
# XComsValueクラスの使い方のイメージ
# ti: TaskInstance
new_value = XComsValueInDict[int](
task_id="add_value_task",
xcoms_key="return_value",
dict_key="new_value",
ti=ti,
)
# Jinjaテンプレート文字列(str)を取得
new_value.template # = "{{ ti.xcom_pull(task_ids='add_value_task', key='return_value')['new_value'] }}"
# XComsから実際の値(int型)を取得(タスク実行時)
new_value.value # = 110
次に、XComsValueを使って、タスクごとに出力のデータ構造を定義していきます。親クラスとして TaskOutput を定義し、テンプレート文字列の生成やXComsからの値の取得で必要な属性をインスタンス変数として定義しています。
子クラスでは、タスクごとに、出力値に含まれる値(key)やデータ型を定義していきます。辞書型の場合は、XComsValueInDictクラスを使って、辞書の中に含まれるキーと値のデータ型を記述します。
タスクの出力値のデータ構造をクラス化することで、各タスクの出力値の属性名をIDEで補完したり、存在しない属性値へのアクセスや、データ型の問題(value属性で値を取得している場合のみ)をlinterでチェックできるようになります。
なお、TaskInstanceは、タスクの実行時に取得できる値のため、DAG生成時はNoneを与えることで、テンプレート文字列としての表現を介して他タスクの出力値を入力パラメータに指定することを想定しています。
@dataclass
class TaskOutput:
"""タスクの出力値のデータ構造の定義
Args:
task_id: AirflowタスクID
xcoms_key: XComsに値をpushする際に使用したkeyの値。デフォルトは `return_key`
ti: 出力値を直接XComsから取得する場合
(i.e.XComsValueのvalue属性にアクセスする場合)は
TaskInstanceを引数で与える必要がある。
Jinjaテンプレート文字列の生成のみの場合
(i.e. XComsValueのtemplate属性へのアクセスのみ場合)は
引数 ti は None (デフォルト値) のままで問題ない
"""
task_id: str
xcoms_key: str = "return_value"
ti: Optional[TaskInstance] = None
@dataclass
class ValueCreationTaskOutput(TaskOutput):
"""初期値を生成するタスクの出力値のデータ構造"""
created_value: XComsValue[str] = field(init=False)
def __post_init__(self) -> None:
self.created_value = XComsValue[str](
task_id=self.task_id, xcoms_key=self.xcoms_key, ti=self.ti)
@dataclass
class ValueAdditionTaskOutput(TaskOutput):
"""加算処理を行うタスクの出力値のデータ構造"""
new_value: XComsValueInDict[int] = field(init=False)
def __post_init__(self) -> None:
self.new_value = XComsValueInDict[int](
task_id=self.task_id, xcoms_key=self.xcoms_key, dict_key="new_value", ti=self.ti)
# TaskOutputクラスの使い方の例
# ti: TaskInstance
value_addition_task_output = ValueAdditionTaskOutput(task_id="add_value_task", xcoms_key="return_value", ti=ti)
# Jinjaテンプレート文字列(str)を取得(ti=None)
value_addition_task_output.new_value.template # = "{{ ti.xcom_pull(task_ids='add_value_task', key='return_value')['new_value'] }}"
# XComsから実際の値(int型)を取得(タスク実行時/tiにTaskInstanceが必要)
value_addition_task_output.new_value.value # = 110
Tips.2 の内容をまとめると、以下のようになります。
- 課題
- タスクを跨いだ値の参照で静的解析や補完が効かない
- 解決策
- タスク出力のデータ構造をクラス化
- 具体的な実装例
- XComsから取得した値(value/template)を表現するクラスを実装(
XComsValue) TaskOutputクラスを定義し、共通で必要なパラメータ/実装を記述- タスクごとに
TaskOutputクラスを継承し、子クラスでタスク出力に含まれる値とそのデータ型を定義
- XComsから取得した値(value/template)を表現するクラスを実装(
- 効果
- 各タスクの出力値の属性名をIDEでコード補完可能に
- 存在しない属性値へのアクセスやデータ型の問題を静的解析で検出可能に
3. [課題] 同じタスク群を実行するDAG間で実装が重複
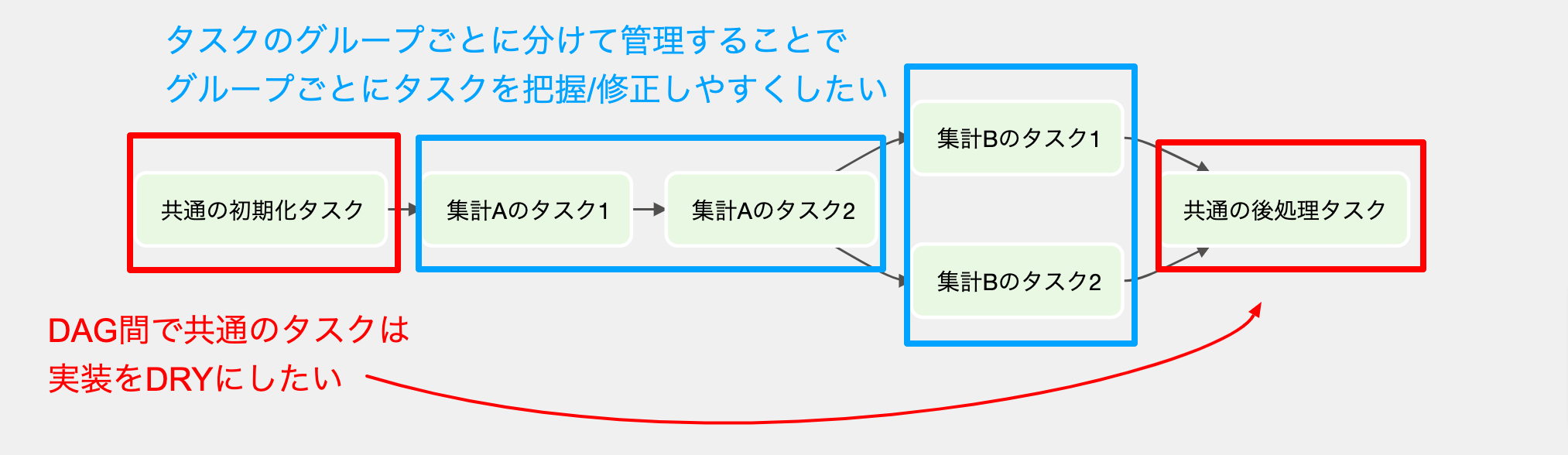
ワークフローごとに完全に別のpythonファイルとしてDAGを記述していくと、一部のタスクが共通するワークフロー間で、タスクの生成や依存関係の定義を行うコードに重複が発生していきます。
共通のタスク群に関する修正が必要になると、DAGごとに同じ修正を行う必要があります。一部のタスクが共通するワークフローが増え、修正コストを削減したいと感じる場面が増えていきました。
3. [解決策] Builderパターンで段階的にタスクを追加
前述のサンプルコードでは、DAG構築処理の中で、全てのタスクの生成と依存関係の定義を行なっていました。ワークフロー間で共通の処理(e.g.初期化/通知/etc)を行うケースでは、DAGごとに同じタスク群を追加していくことになり、実装が重複します。このタスク群で修正が必要になった場合、DAGごとに修正を行う必要があり、修正コストが高いです。
そこで、複雑なオブジェクトを段階的に構築する際に活用できるBuilder パターンを参考に、タスクをグループごとに別メソッドに分け、順番にメソッドを実行することでタスク群を段階的に追加できる設計にしています。
ワークフロー間で共通の処理については、共通の親DagBuilderでDRYに実装を行うことができ、子DagBuilderでは、関連するDAGに特化したタスク郡を追加する形になります。
class AbstractDagBuilder(ABC):
"""DagBuilderの抽象クラス"""
def __init__(self) -> None:
self._dag = self._init_dag()
self._output_handler = OutputHandler()
self._first_tasks: List[Chainable] = []
self._last_tasks: List[Chainable] = []
@abstractmethod
def _init_dag(self) -> DAG:
"""DAGインスタンスの生成方法を各子クラスで定義する必要がる"""
pass
def build(self) -> DAG:
return self._dag
def _add_tasks(self, tasks: Union[List[Chainable], Chainable]) -> None:
"""DAGに新しいタスク(群)への依存関係を追加する
DAGの末尾のタスク(群)はインスタンス変数 _last_tasks として保持しており
新しいタスク(群)を末尾のタスク(群)に繋げていくことで、依存関係を更新する
"""
if not isinstance(tasks, List):
tasks = [tasks]
if len(self._first_tasks) == 0:
self._first_tasks = tasks
self._last_tasks = tasks
return
for previous_task in self._last_tasks:
for new_task in tasks:
previous_task.set_downstream(new_task)
self._last_tasks = tasks
class CommonDagBuilder(AbstractDagBuilder):
"""子DAG間で共通するタスクの追加機能を持ったDagBuilder"""
def __init__(self) -> None:
super().__init__()
def add_preprocess_tasks(self) -> None:
"""共通の前処理(e.g.初期値の生成)を行うタスク群を追加する"""
with TaskGroup("preprocess_tasks", dag=self._dag):
task_factory = CreateValueTaskFactory(
dag=self._dag, task_id="create_value_task")
task = task_factory.create()
self._add_tasks(task)
self._output_handler.register_task_context(
key=OutputHandlerKeyEnum.CREATE_VALUE, task_id=task.task_id)
class TechBlogDagBuilder(CommonDagBuilder):
"""実際にDAGを生成する際に使用するDagBuilder"""
def __init__(self, dag_id: str) -> None:
self.dag_id = dag_id
super().__init__()
def _init_dag(self) -> DAG:
# DAGインスタンスを生成
dag = DAG(
dag_id=self.dag_id,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule_interval=None,
catchup=False,
tags=["blog"],
)
return dag
def add_main_calculation_tasks(self) -> None:
"""加算処理を行うタスク群を追加する"""
with TaskGroup("main_calculation_tasks", dag=self._dag):
value_creation_task_output: ValueCreationTaskOutput = self._output_handler.get_task_output(
key=OutputHandlerKeyEnum.CREATE_VALUE, task_output_cls=ValueCreationTaskOutput)
# タスクを生成
task_factory = AddValueTaskFactory(
dag=self._dag,
task_id="add_value_task",
created_value=value_creation_task_output.created_value,
)
task = task_factory.create()
# タスク間の依存関係を定義
self._add_tasks(task)
self._output_handler.register_task_context(
key=OutputHandlerKeyEnum.ADD_VALUE, task_id=task.task_id)
def add_postprocess_tasks(self) -> None:
"""後処理(e.g.最終的な値の表示)を行うタスク群を追加する"""
with TaskGroup("postprocess_tasks", dag=self._dag):
value_addition_task_output = self._output_handler.get_task_output(
key=OutputHandlerKeyEnum.ADD_VALUE, task_output_cls=ValueAdditionTaskOutput)
task_factory = ShowValueTaskFactory(
dag=self._dag, task_id="show_value_task", value_to_show=value_addition_task_output.new_value)
task = task_factory.create()
self._add_tasks(task)
dag_builder = TechBlogDagBuilder(dag_id="good_dag_example")
dag_builder.add_preprocess_tasks()
dag_builder.add_main_calculation_tasks()
dag_builder.add_postprocess_tasks()
dag = dag_builder.build()
上記の設計により、以下のようなメリットがあります。
- DAG間で共通するタスクのグループがある場合、DagのBuilderで実装を共通化することができる
- 各タスクの実行順の変更では、修正範囲がDagBuilderの該当するタスク郡の追加メソッド内に閉じており、他のタスクに影響を少なくできる(メソッドを跨いでタスクの出力値をやりとりしている場合については後述)
- DAGの構築では、DagBuilderのメソッドを適切な順番に実行していく実装となり、機能や役割で分けられたタスク群がどのような順番で実行されるのかなど、ワークフローの流れが捉えやすい
DagBuilder内のメソッドを跨いでタスクの出力値をやりとりする際には、XComsへの出力に使用した task_id や key の値、出力値のデータ構造など、タスク出力に関するコンテキスト情報をメソッドを跨いで受け渡す必要があります。
各メソッドで task_id や key の値を文字列でハードコーディングすることも可能ですが、これらの値に変更が発生した際には、修正漏れを防ぐのが大変になります。
そこで本実装では、タスクのコンテキスト情報を TaskOutputContext として定義し、各タスクのコンテキスト情報を識別する定数 OutputHandlerKeyEnum 、タスクのコンテキスト情報の登録/取得を行う OutputHandler クラスを追加しています。
タスク生成時は、コンテキスト情報を OutputHandler に登録しておきます。別のメソッドのタスクでこの出力値を参照する際には、 OutputHandler からコンテキスト情報を取得し、この情報を使ってタスクの出力値クラスを生成し、値を参照する形になります。
class OutputHandlerKeyEnum(Enum):
"""タスクが実行されたコンテクストに関する値の定数クラス
OutputHandlerで各タスクの出力を区別して扱うために使用
"""
CREATE_VALUE = auto()
ADD_VALUE = auto()
@dataclass
class TaskOutputContext:
"""タスクの出力値と実行の文脈に関する情報
Args:
output_handler_key: タスクが実行されたコンテクストに関する値の定数
異なるタスクの出力を区別して値を扱うために使用
(e.g.異なるタスク/集計対象ごとにforループで生成した同種のタスク/etc)
task_id: AirflowタスクのID
xcoms_key: XComsでpushした値のkey
task_output_cls: タスク出力のデータ構造クラス
"""
output_handler_key: OutputHandlerKeyEnum
task_id: str
xcoms_key: str
task_output_cls: Type[TaskOutput]
TASK_OUTPUT = TypeVar("TASK_OUTPUT", bound=TaskOutput)
class OutputHandler:
"""タスの出力値の登録/取得を行う
あるタスクの出力値を後続のタスクで参照する場合、以下の流れで登録/取得を行う
1. register_task_context メソッドを実行し、タスクの文脈情報とXComsへの出力に使用した情報を登録する
2. get_task_output メソッドを実行し、タスクの出力値を取得する
"""
def __init__(self) -> None:
self._handler_key_to_task_id_and_xcoms_key: Dict[OutputHandlerKeyEnum, Tuple[str, str]] = {
}
def register_task_context(self, key: OutputHandlerKeyEnum, task_id: str, xcoms_key: str = "return_value") -> None:
"""タスクの文脈情報とXComsへの出力に使用した値を紐づけて登録する
Args:
key: タスクが実行されたコンテクストに関する値の定数値
同様の出力を行う同種のタスクを区別するために使用
task_id: AirflowのタスクID
xcoms_key: XComsの出力で使用したKey。デフォルトは`return_value`
"""
self._handler_key_to_task_id_and_xcoms_key[key] = (task_id, xcoms_key)
def get_task_output(self, key: OutputHandlerKeyEnum, task_output_cls: Type[TASK_OUTPUT], ti: Optional[TaskInstance] = None) -> TASK_OUTPUT:
"""タスクの文脈情報から登録されたタスク出力値を取得する
Args:
key: タスクが実行されたコンテクストに関する値の定数値
同様の出力を行う同種のタスクを区別するために使用
task_output_cls: タスク出力値のデータ構造のクラス
ti: 出力値を直接XComsから取得する場合
(i.e.XComsValueのvalue属性にアクセスする場合)は
TaskInstanceを引数で与える必要がある。
Jinjaテンプレート文字列の生成のみの場合
(i.e. XComsValueのtemplate属性へのアクセスのみ場)は
引数 ti は None (デフォルト値) のままで問題ない
Returns:
TASK_OUTPUT: タスクの出力値。引数 task_output_cls で指定したクラスのインスタンスを返す
"""
task_id, xcoms_key = self._handler_key_to_task_id_and_xcoms_key[key]
task_output = task_output_cls(
task_id=task_id, xcoms_key=xcoms_key, ti=ti)
return task_output
# OutputHandlerでタスクのコンテキスト情報を登録/取得する流れのイメージ
output_handler = OutputHandler()
# コンテキストを識別する定数に紐づけて
# タスクのコンテキスト情報を保存
# create_value_task: BashOperator
output_handler.register_task_context(
key=OutputHandlerKeyEnum.CREATE_VALUE,
task_id=create_value_task.task_id
)
# コンテキストを識別する定数を使って
# タスクの出力値クラスを取得
value_creation_task_output = output_handler.get_task_output(
key=OutputHandlerKeyEnum.CREATE_VALUE,
task_output_cls=ValueCreationTaskOutput
)
# タスクの出力値を参照
value_creation_task_output.created_value.template # = "{{ ti.xcom_pull(task_ids='create_value_task', key='return_value') }}"
タスクのコンテキスト情報が OutputHandler に登録されていない場合、未登録のタスク出力を取得しようとしたタイミング(get_task_output)でエラーが発生し、DAGの構築に失敗します。そのため、ユニットテストなどを活用し、DAGの構築が成功することをチェックすることで、DAGを実際に実行するよりも前の段階で、DAGで実行されていないタスクの出力を参照しようとしているバグに気づき、素早く対処ができるメリットがあります。
DAGの構築の成功を確認するユニットテストについては、公式ドキュメントが参考になります。
c.f. Best Practices – Apache Airflow: Unit tests
Tips.3 の内容をまとめると、以下のようになります。
- 課題
- 同じタスク群を実行するDAG間で実装が重複
- 解決策
- Builderパターンで段階的にタスクを追加
- 具体的な実装例
- タスクをグループごとに別メソッドに分け、順番にメソッドを実行することで段階的にタスクを追加する
DagBuilderクラスを定義 - 共通するタスク群の追加メソッドは親DagBuilderで実装し、子DagBuilderでは、関連するDAGに特化したタスク郡の追加メソッドを実装
- メソッドを跨いでタスク出力を参照する場合、タスク生成時にコンテキスト情報を
OutputHandlerに登録しておき、後続のメソッドではOutputHandlerを介してタスク出力のクラスインスタンスを取得
- タスクをグループごとに別メソッドに分け、順番にメソッドを実行することで段階的にタスクを追加する
- 効果
- DAG間で共通するタスクのグループがある場合、DagのBuilderで実装を共通化することができる
- 各タスクの実行順の変更では、修正範囲がDagBuilderの該当するタスク郡の追加メソッド内に閉じており、他のタスクに影響を少なくできる
- DAGの構築では、DagBuilderのメソッドを適切な順番に実行していく実装となり、機能や役割で分けられたタスク群がどのような順番で実行されるのかなど、ワークフローの流れが捉えやすい
- ユニットテストなどを活用し、DAG構築の成功をチェックすることで、実際にDAGを実行するよりも前の段階で、DAGに追加されていないタスクの出力値を参照しようとしているバグに気づき、素早く対処ができる
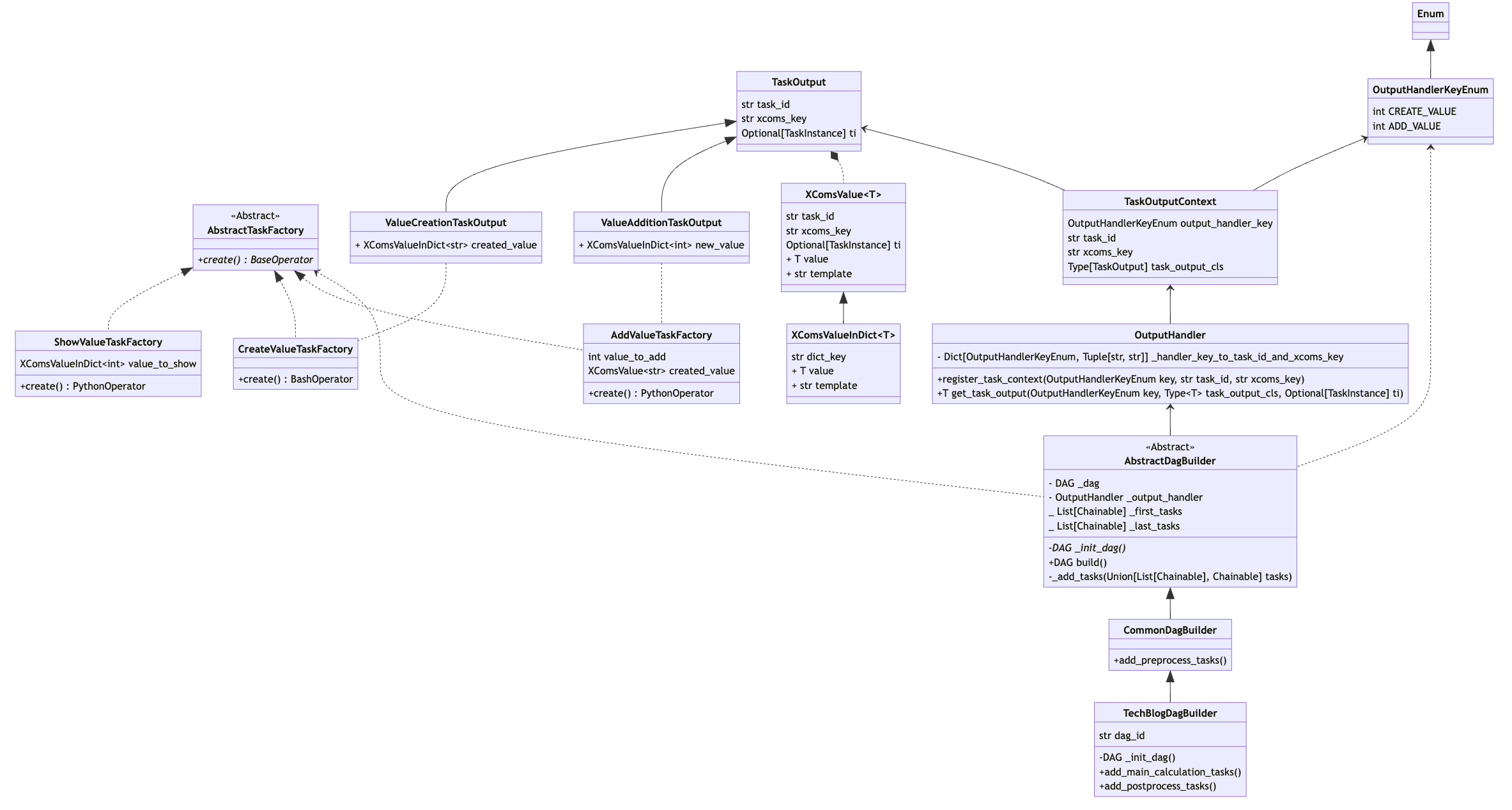
クラス図とコード
本記事で紹介したコードの全体像とクラス図になります。
from abc import ABC, abstractmethod
from enum import auto
from airflow.models.taskinstance import TaskInstance
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import BranchPythonOperator
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.models.baseoperator import BaseOperator
from airflow.utils.task_group import TaskGroup
from dataclasses import dataclass, field
from typing import (
Any,
Dict,
Generic,
Optional,
Tuple,
Type,
TypeVar,
Union,
List,
)
from airflow.models.dag import DAG
import pendulum
from enum import Enum
Chainable = Union[BaseOperator, DummyOperator, BranchPythonOperator]
# Tips2. タスクの出力のデータ構造をクラス化
T = TypeVar("T")
class XComsValue(Generic[T]):
"""XComsから取得した値
実際に取得した値(value)とJinjaテンプレート文字列(template)の両方の表現を兼ね備える
"""
def __init__(
self, task_id: str, xcoms_key: str, ti: Optional[TaskInstance] = None
) -> None:
self.task_id = task_id
self.xcoms_key = xcoms_key
self.ti = ti
@property
def value(self) -> T:
"""XComsから取得したタスク出力の値"""
if self.ti is None:
raise ValueError(
"Instance variable 'ti' must not be None to pull value from TaskInstance."
)
xcoms_pulled_value: Optional[T] = self.ti.xcom_pull(
task_ids=self.task_id, key=self.xcoms_key
)
if xcoms_pulled_value is None:
raise ValueError(
f"Value not found in XComs. task_ids={self.task_id}, key={self.xcoms_key}"
)
return xcoms_pulled_value
@property
def template(self) -> str:
"""XComsから値を取得するJinjaテンプレート文字列"""
return (
f"{{{{ ti.xcom_pull(task_ids='{self.task_id}', key='{self.xcoms_key}')}}}}"
)
class XComsValueInDict(XComsValue[T]):
"""XComsから取得した辞書型の値に含まれる特定のkeyの"""
def __init__(
self,
task_id: str,
xcoms_key: str,
dict_key: str,
ti: Optional[TaskInstance] = None,
) -> None:
super().__init__(task_id=task_id, xcoms_key=xcoms_key, ti=ti)
self.dict_key = dict_key
@property
def value(self) -> T:
"""XComsから取得した辞書からkeyを指定して抽出した値"""
if self.ti is None:
raise ValueError(
"Instance variable 'ti' must not be None to pull value from TaskInstance."
)
xcoms_pulled_value: Optional[Dict[str, T]] = self.ti.xcom_pull(
task_ids=self.task_id, key=self.xcoms_key
)
if xcoms_pulled_value is None:
raise ValueError(
f"Value not found in XComs. task_ids={self.task_id}, key={self.xcoms_key}"
)
if not isinstance(xcoms_pulled_value, dict):
raise ValueError("Output value is not in dict type")
return xcoms_pulled_value[self.dict_key]
@property
def template(self) -> str:
"""XComsから辞書型の値を取得し、keyを指定して中身を取り出すJinjaテンプレート文字列"""
return f"{{{{ ti.xcom_pull(task_ids='{self.task_id}', key='{self.xcoms_key}')['{self.dict_key}']}}}}"
@dataclass
class TaskOutput:
"""タスクの出力値のデータ構造の定義
Args:
task_id: AirflowタスクID
xcoms_key: XComsに値をpushする際に使用したkeyの値。デフォルトは `return_key`
ti: 出力値を直接XComsから取得する場合
(i.e.XComsValueのvalue属性にアクセスする場合)は
TaskInstanceを引数で与える必要がある。
Jinjaテンプレート文字列の生成のみの場合
(i.e. XComsValueのtemplate属性へのアクセスのみ場合)は
引数 ti は None (デフォルト値) のままで問題ない
"""
task_id: str
xcoms_key: str = "return_value"
ti: Optional[TaskInstance] = None
@dataclass
class ValueCreationTaskOutput(TaskOutput):
"""初期値を生成するタスクの出力値のデータ構造"""
created_value: XComsValue[str] = field(init=False)
def __post_init__(self) -> None:
self.created_value = XComsValue[str](
task_id=self.task_id, xcoms_key=self.xcoms_key, ti=self.ti
)
@dataclass
class ValueAdditionTaskOutput(TaskOutput):
"""加算処理を行うタスクの出力値のデータ構造"""
new_value: XComsValueInDict[int] = field(init=False)
def __post_init__(self) -> None:
self.new_value = XComsValueInDict[int](
task_id=self.task_id,
xcoms_key=self.xcoms_key,
dict_key="new_value",
ti=self.ti,
)
# Tips.1 タスクの生成機能の分離
class AbstractTaskFactory(ABC):
"""タスクの生成機能の抽象クラス"""
def __init__(self, dag: DAG, task_id: str) -> None:
self.dag = dag
self.task_id = task_id
@abstractmethod
def create(self) -> BaseOperator:
pass
class CreateValueTaskFactory(AbstractTaskFactory):
"""初期値を作成するタスクを生成する"""
def __init__(self, dag: DAG, task_id: str) -> None:
super().__init__(dag=dag, task_id=task_id)
@property
def bash_command(self) -> str:
return "echo 10"
def create(self) -> BashOperator:
return BashOperator(
task_id=self.task_id,
dag=self.dag,
bash_command=self.bash_command,
)
class AddValueTaskFactory(AbstractTaskFactory):
"""加算処理を行うタスクを生成する"""
def __init__(self, dag: DAG, task_id: str, created_value: XComsValue[str]) -> None:
super().__init__(dag=dag, task_id=task_id)
self.created_value = created_value
def python_callable(
self, ti: TaskInstance, templates_dict: Dict[str, int]
) -> Dict[str, Any]:
created_value = templates_dict["created_value"]
# or get value using TaskInstance
# created_value = ValueCreationTaskOutput(task_id="preprocess_tasks.create_value_task", ti=ti).created_value.value
new_value = int(created_value) + 100
return {"new_value": new_value}
def create(self) -> PythonOperator:
return PythonOperator(
task_id=self.task_id,
dag=self.dag,
python_callable=self.python_callable,
# templates_dictで指定した値は、Jinja templatingで各値が置換され
# python_callableの引数としてアクセスできる
templates_dict={"created_value": self.created_value.template},
)
class ShowValueTaskFactory(AbstractTaskFactory):
"""最終的な値を表示するタスクを生成するクラス"""
def __init__(
self, dag: DAG, task_id: str, value_to_show: XComsValueInDict[int]
) -> None:
super().__init__(dag=dag, task_id=task_id)
self.value_to_show = value_to_show
def python_callable(self, ti: TaskInstance, templates_dict: Dict[str, int]) -> None:
value_to_show = int(templates_dict["value_to_show"])
# or get value using TaskInstance
# value_to_show = ValueAdditionTaskOutput(task_id="main_calculation_tasks.add_value_task", ti=ti).new_value.value
print(f"final value is {value_to_show}")
def create(self) -> PythonOperator:
return PythonOperator(
task_id=self.task_id,
dag=self.dag,
python_callable=self.python_callable,
templates_dict={"value_to_show": self.value_to_show.template},
)
# Tips.3 Builderパターンで段階的にタスクを追加
class OutputHandlerKeyEnum(Enum):
"""タスクが実行されたコンテクストに関する値の定数クラス
OutputHandlerで各タスクの出力を区別して扱うために使用
"""
CREATE_VALUE = auto()
ADD_VALUE = auto()
@dataclass
class TaskOutputContext:
"""タスクの出力値と実行の文脈に関する情報
Args:
output_handler_key: タスクが実行されたコンテクストに関する値の定数
異なるタスクの出力を区別して値を扱うために使用
(e.g.異なるタスク/集計対象ごとにforループで生成した同種のタスク/etc)
task_id: AirflowタスクのID
xcoms_key: XComsでpushした値のkey
task_output_cls: タスク出力のデータ構造クラス
"""
output_handler_key: OutputHandlerKeyEnum
task_id: str
xcoms_key: str
task_output_cls: Type[TaskOutput]
TASK_OUTPUT = TypeVar("TASK_OUTPUT", bound=TaskOutput)
class OutputHandler:
"""タスクの出力値の登録/取得を行う
あるタスクの出力値を後続のタスクで参照する場合、以下の流れで登録/取得を行う
1. register_task_context メソッドを実行し、タスクの文脈情報とXComsへの出力に使用した情報を登録する
2. get_task_output メソッを実行し、タスクの出力値を取得する
"""
def __init__(self) -> None:
self._handler_key_to_task_id_and_xcoms_key: Dict[
OutputHandlerKeyEnum, Tuple[str, str]
] = {}
def register_task_context(
self, key: OutputHandlerKeyEnum, task_id: str, xcoms_key: str = "return_value"
) -> None:
"""タスクの文脈情報とXComsへの出力に使用した値を紐づけて登録する
Args:
key: タスクが実行されたコンテクストに関する値の定数値
同様の出力を行う同種のタスクを区別するために使用
task_id: AirflowのタスクID
xcoms_key: XComsの出力で使用したKey。デフォルトは`return_value`
"""
self._handler_key_to_task_id_and_xcoms_key[key] = (task_id, xcoms_key)
def get_task_output(
self,
key: OutputHandlerKeyEnum,
task_output_cls: Type[TASK_OUTPUT],
ti: Optional[TaskInstance] = None,
) -> TASK_OUTPUT:
"""タスクの文脈情報から登録されたタスク出力値を取得する
Args:
key: タスクが実行されたコンテクストに関する値の定数値
同様の出力を行う同種のタスクを区別するために使用
task_output_cls: タスク出力値のデータ構造のクラス
ti: 出力値を直接XComsから取得する場合
(i.e.XComsValueのvalue属性にアクセスする場合)は
TaskInstanceを引数で与える必要がある。
Jinjaテンプレート文字列の生成のみの場合
(i.e. XComsValueのtemplate属性へのアクセスのみ場合)は
引数 ti は None (デフォルト値) のままで問題ない
Returns:
TASK_OUTPUT: タスクの出力値。引数 task_output_cls で指定したクラスのインスタンスを返す
"""
task_id, xcoms_key = self._handler_key_to_task_id_and_xcoms_key[key]
task_output = task_output_cls(
task_id=task_id, xcoms_key=xcoms_key, ti=ti)
return task_output
class AbstractDagBuilder(ABC):
"""DagBuilderの抽象クラス"""
def __init__(self) -> None:
self._dag = self._init_dag()
self._output_handler = OutputHandler()
self._first_tasks: List[Chainable] = []
self._last_tasks: List[Chainable] = []
@abstractmethod
def _init_dag(self) -> DAG:
"""DAGインスタンスの生成方法を各子クラスで定義する必要がある"""
pass
def build(self) -> DAG:
return self._dag
def _add_tasks(self, tasks: Union[List[Chainable], Chainable]) -> None:
"""DAGに新しいタスク(群)への依存関係を追加する
DAGの末尾のタスク(群)はインスタンス変数 _last_tasks として保持しており
新しいタスク(群)を末尾のタスク(群)に繋げていくことで依存関係を更新する
"""
if not isinstance(tasks, List):
tasks = [tasks]
if len(self._first_tasks) == 0:
self._first_tasks = tasks
self._last_tasks = tasks
return
for previous_task in self._last_tasks:
for new_task in tasks:
previous_task.set_downstream(new_task)
self._last_tasks = tasks
class CommonDagBuilder(AbstractDagBuilder):
"""子DAG間で共通するタスクの追加機能を持ったDagBuilder"""
def __init__(self) -> None:
super().__init__()
def add_preprocess_tasks(self) -> None:
"""共通の前処理(e.g.初期値の生成)を行うタスク群を追加する"""
with TaskGroup("preprocess_tasks", dag=self._dag):
task_factory = CreateValueTaskFactory(
dag=self._dag, task_id="create_value_task"
)
task = task_factory.create()
self._add_tasks(task)
self._output_handler.register_task_context(
key=OutputHandlerKeyEnum.CREATE_VALUE, task_id=task.task_id
)
class TechBlogDagBuilder(CommonDagBuilder):
"""実際にDAGを生成する際に使用するDagBuilder"""
def __init__(self, dag_id: str) -> None:
self.dag_id = dag_id
super().__init__()
def _init_dag(self) -> DAG:
# DAGインスタンスを生成
dag = DAG(
dag_id=self.dag_id,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule_interval=None,
catchup=False,
tags=["blog"],
)
return dag
def add_main_calculation_tasks(self) -> None:
"""メインの計算処理(e.g.加算処理)を行うタスクグループを追加する"""
with TaskGroup("main_calculation_tasks", dag=self._dag):
value_creation_task_output: ValueCreationTaskOutput = (
self._output_handler.get_task_output(
key=OutputHandlerKeyEnum.CREATE_VALUE,
task_output_cls=ValueCreationTaskOutput,
)
)
# タスクを生成
task_factory = AddValueTaskFactory(
dag=self._dag,
task_id="add_value_task",
created_value=value_creation_task_output.created_value,
)
task = task_factory.create()
# タスク間の依存関係を定義
self._add_tasks(task)
self._output_handler.register_task_context(
key=OutputHandlerKeyEnum.ADD_VALUE, task_id=task.task_id
)
def add_postprocess_tasks(self) -> None:
"""後処理(e.g.最終的な値の表示)を行うタスク群を追加する"""
with TaskGroup("postprocess_tasks", dag=self._dag):
value_addition_task_output = self._output_handler.get_task_output(
key=OutputHandlerKeyEnum.ADD_VALUE,
task_output_cls=ValueAdditionTaskOutput,
)
task_factory = ShowValueTaskFactory(
dag=self._dag,
task_id="show_value_task",
value_to_show=value_addition_task_output.new_value,
)
task = task_factory.create()
self._add_tasks(task)
dag_builder = TechBlogDagBuilder(dag_id="good_dag_example")
dag_builder.add_preprocess_tasks()
dag_builder.add_main_calculation_tasks()
dag_builder.add_postprocess_tasks()
dag = dag_builder.build()
まとめ
この記事では、Apache Airflowでワークフローを実装していく中で直面したコードの保守性の課題と、それを解決するために行なったクラス設計をご紹介しました。
紹介した内容をまとめると、以下のようになります。
| 番号 | 課題 | 解決策(Tips) | 効果 |
|---|---|---|---|
| 1 | DAGが肥大化してタスクの修正がしづらい | タスクの生成機能の分離 | DAG構築処理では、タスク間の依存関係を定義する機能に焦点が絞られ、コンパクトで見通しが良いコードに。タスクの実行方法/設定に変更が発生した場合、タスク生成クラスを修正すれば良い形に。DAG構築処理へのコード修正を最小限に抑えられ、保守性が向上 |
| 2 | タスクを跨いだ値の参照で静的解析や補完が効かない | タスク出力のデータ構造をクラス化 | 各タスクの出力値の属性名をIDEでコード補完可能に。存在しない属性値へのアクセスやデータ型の問題を静的解析で検出可能に。 |
| 3 | 共通のタスク群を実行するDAG間で実装が重複 | Builderパターンによる段階的なタスク追加 | DAG間で共通のタスク群の実装を親クラスで共通化できるように。ワークフローの流れが捉えやすくなるとともに、実際にDAGを実行するよりも前の段階で、DAGに追加されていないタスクの出力値を参照しようとしているバグに気づき、素早く対処ができるように |
このように、クラス設計を工夫することで、コードの可読性/保守性を向上させることができます。
ただし、実装が必要なコード量が増えるデメリットはあるため、シンプルなワークフローの場合、上記の設計のメリットをデメリットが上回る状況も考えられます。
そのため、ワークフローがある複雑化し、DAGが肥大化して見通しが悪いようなケースにおいて、効果がある設計と言えるかと思います。
Airflowのクラス設計を考える際、本記事の内容が少しでも参考になれば幸いです。

2017年4月、NHNテコラスに新卒入社。データサイエンスチームに所属し、AWSを活用したデータ分析サービスの設計開発を担当。


Recommends
こちらもおすすめ
-

Pythonで実装する画像認識アルゴリズム SLIC 入門
2018.2.13
-

基礎からはじめる時系列解析入門
2019.2.22



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16