可分な畳み込みカーネルと計算量の話

こんにちは。データサイエンスチームのtmtkです。
この記事では、可分なカーネルによる畳み込みと計算量の説明をします。
畳み込みとは
はじめに畳み込みを復習します。
機械学習において、畳み込みとは以下のような処理です。いま、入力が2次元の場合を考えることにします。畳み込みカーネルを
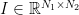

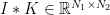

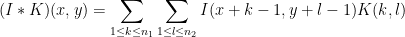
で定義されます。
畳み込みは、古典的な画像処理や最近流行りのディープラーニングでも用いられています。画像認識の本やディープラーニングの本に詳しいことが書かれています。
Pythonで書く畳み込み処理
Pythonで実際に畳み込み処理を書いてみます。コンピュータで処理するため、入力

となります。
いま、入力のサイズを
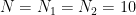 、カーネルのサイズを
、カーネルのサイズを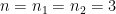 、入力データを
、入力データを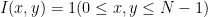 、カーネルを
、カーネルを とします。
とします。
N = 10 n = 3 image = [[1] * N for _ in range(N)] kernel = [[1] * n for _ in range(n)]
すると、畳み込み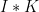
def convolution(image, kernel):
N1 = len(image)
N2 = len(image[0])
n1 = len(kernel)
n2 = len(kernel[0])
res = [[0] * N2 for _ in range(N1)]
for i in range(N1):
for j in range(N2):
for k in range(min(n1, N1 - i)):
for l in range(min(n2, N2 - j)):
res[i][j] += image[i+k][j+l] * kernel[k][l]
return res
実際に計算してみると、
convolution(image, kernel)
以下のような畳み込み
[[9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [6, 6, 6, 6, 6, 6, 6, 6, 4, 2], [3, 3, 3, 3, 3, 3, 3, 3, 2, 1]]
可分な畳み込みカーネル
ところで、いま与えた畳み込みカーネル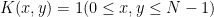
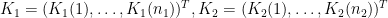


(ただし
 )と書けるので、実際に可分なカーネルになっています。
)と書けるので、実際に可分なカーネルになっています。可分なカーネルの例としては、他にも平均値をとるカーネル

や、ガウス関数から作られるカーネル

などがあります。
可分なカーネル
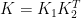 に対しては、以下の等式が成り立ちます。
に対しては、以下の等式が成り立ちます。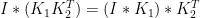
証明は簡単なので省略します。
それでは、この性質を使って先ほどの畳み込みを計算してみましょう。関数
convolution_separableは可分なカーネル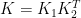 での畳み込み
での畳み込み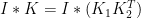 を
を で計算する関数です。
で計算する関数です。
kernel1 = [1]*n
kernel2 = [1]*n
def convolution_separable(image, kernel1, kernel2):
N1 = len(image)
N2 = len(image[0])
n1 = len(kernel1)
n2 = len(kernel2)
res = [[0] * N2 for _ in range(N1)]
tmp = [[0] * N2 for _ in range(N1)]
for i in range(N1):
for j in range(N2):
for k in range(min(n1, N1 - i)):
tmp[i][j] += image[i+k][j] * kernel1[k]
for i in range(N1):
for j in range(N2):
for l in range(min(n2, N2 - j)):
res[i][j] += tmp[i][j+l] * kernel2[l]
return res
convolution_separable(image, kernel1, kernel2)
[[9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [9, 9, 9, 9, 9, 9, 9, 9, 6, 3], [6, 6, 6, 6, 6, 6, 6, 6, 4, 2], [3, 3, 3, 3, 3, 3, 3, 3, 2, 1]]
先ほどの計算方法と同じ結果を得ることができます。
それぞれの方法の計算量
それぞれの計算方法について、処理時間を見積もってみましょう。
最初の方法では、関数convolutionに四重ループ
for i in range(N1):
for j in range(N2):
for k in range(min(n1, N1 - i)):
for l in range(min(n2, N2 - j)):
があり、ループが約


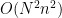
それに対して、可分なカーネルに対する畳み込みでは、関数convolution_separableに以下の2つの三重ループがあります。
for i in range(N1):
for j in range(N2):
for k in range(min(n1, N1 - i)):
for i in range(N1):
for j in range(N2):
for l in range(min(n2, N2 - j)):
そのため、このconvolution_separableの処理時間は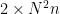


したがって、計算量がそれぞれ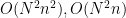

convolutionよりconvolution_separableのほうが計算時間が短くなることが予想できます。
実際の計算時間
それでは、時間計算量が実際の計算時間に及ぼす影響を観察するため、どれくらいの処理時間がかかるのか計測してみます。
計算環境はCore i7が載っている普通のパソコン上の仮想マシンです。
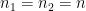
%timeで計測します。
N = 1000 image = [[1] * N for _ in range(N)]
たとえば、
n = 10 %time convolution(image, [[1] * n for _ in range(n)]) %time convolution_separable(image, [1]*n, [1]*n)
結果は以下のようになります。関数convolutionの処理時間が
convolution_separableの処理時間が
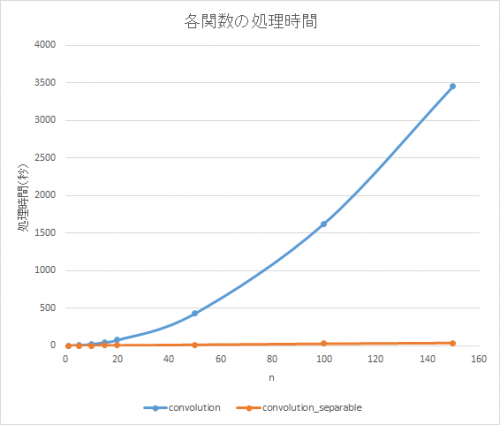
ここから推定すると、
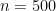 のとき、
のとき、convolutionの処理時間はおよそ10時間程度かかってしまうのにたいして、convolution_separableの処理時間はたったの2分程度になります。時間計算量がと異なるため、が大きくなると処理時間の差も大きくなっていきます。このように、大きいデータを処理するとき、時間計算量を考慮することは重要です。
まとめ
この記事では、可分なカーネルでの畳み込みの効率的な計算方法と、それによる時間計算量の差について説明しました。可分なカーネルでの畳み込みは、通常の畳み込みよりも高速に計算することができます。時間計算量の差は大きなデータになると実際の処理時間の差に如実に現れてくるので、時間計算量を考慮したアルゴリズムを設計することが大切です。
参考文献
- 原田達也『画像認識』
- Ian Goodfellow他『深層学習』
- Separable convolution » Steve on Image Processing – MATLAB & Simulink
- ランダウの記号 – Wikipedia
- 8.2. コンボリューション行列…
- 畳み込みを画像処理に適用した例が載っています。

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

Apache Sparkとpandasでデータ処理の時間を短縮する方法
2017.12.21
-

VAEを用いたUNIXセッションのなりすまし検出
2018.12.17
-

Pythonで時系列データをクラスタリングする方法
2017.12.12
-

畳み込みニューラルネットワークの畳み込み層の重みを可視化する方法
2018.7.10
-

Airflowのクラス設計のTips
2023.2.3

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16