Performance Insightsを使ったAmazon Aurora MySQL のデータベースパフォーマンス分析
2023.3.1

はじめに
本記事では Aurora MySQL 使用時の Performance Insights を使った DB パフォーマンス分析について記述します。
データベースを日々運用していると、データベースの処理が遅いなんてことがあるかと思います。他にも、CPU 使用率やメモリ使用率などがだんだん高くなっているが原因がわからないという課題を抱えている方必見の RDS 機能についてご紹介します。
なお、本分析内容は Aurora MySQL5.7 互換が対象となっております。他エンジンやバージョンでも Performance Insights の使い方については変わりないですが、パフォーマンス分析をする際に見ていく項目が異なるためご注意ください。例えば、待機イベントの内容については、各 DB エンジンやバージョンによって大きく異なります。
また、本環境では、MySQL のパフォーマンススキーマは有効化している状態です。
パフォーマンススキーマの有効・無効については以下記事を御覧ください。

Performance Insights について
データベース内のパフォーマンスデータを蓄積してボトルネックを特定できます。

Amazon RDS Performance Insights はデータベースパフォーマンスのチューニングとモニタリングを行う機能で、データベースの負荷をすばやく評価し、いつどこに措置を講じたらよいかを判断するのに役立ちます。Performance Insights のダッシュボードはわかりやすく、データベースの負荷が可視化されるため、専門的知識のないユーザーでもパフォーマンスの問題を検出できます。
Performance Insights(RDS のパフォーマンスを分析、チューニング)| AWS
利点
- 無料で 7 日間のパフォーマンス履歴を保存可能
- グラフで可視化されているため使いやすく&見やすい
- 設定もメンテナンスも不要で簡単に有効化可能
要件
エンジンやインスタンスタイプによっては本機能を使用できない制限があります。
既存であるインスタンスで、変更画面に Performance Insights がない場合は対応していない証拠です。
詳細は以下ドキュメントをご覧ください。
- Amazon RDS サポート対象:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_PerfInsights.Overview.Engines.html
- Amazon Aurora サポート対象:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/USER_PerfInsights.Overview.Engines.html
- Aurora MySQL バージョン対象:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Concepts.Aurora_Fea_Regions_DB-eng.Feature.PerfInsights.html#Concepts.Aurora_Fea_Regions_DB-eng.Feature.PerfInsights.amy
- Aurora PostgreSQL バージョン対象:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Concepts.Aurora_Fea_Regions_DB-eng.Feature.PerfInsights.html#Concepts.Aurora_Fea_Regions_DB-eng.Feature.PerfInsights.apg
ダッシュボード概要
Performance Insights では、3 つのセッションで用途別に分かれたダッシュボードがあります。
上から順番に見ていきパフォーマンスについて分析し、対策について検討します。
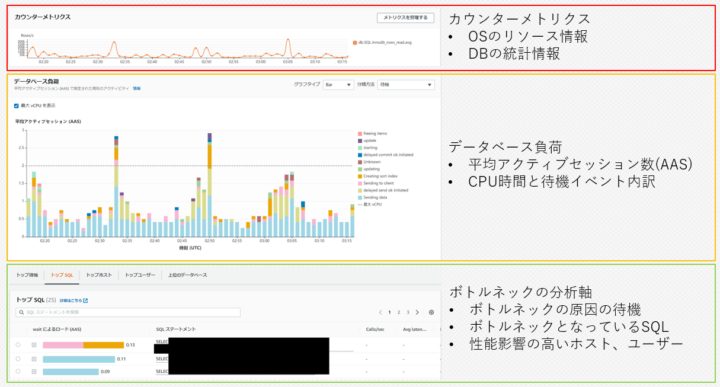
- カウンターメトリクス
- データベース負荷
- ボトルネックの分析軸
ダッシュボードで注意事項が一つあります。
CloudWatch のように期間を指定して分析ができるのですが、期間によって Performance Insights 側で自動的に特定の時間で平均化されます。そのため、一週間の期間で平均化するとパフォーマンスは悪くないように見えるかもしれません。
しかし、時間軸をドリルダウンすると CPU 使用率が 100%張り付いている時間帯があったり、かなりテーブルを読み取っている時間帯があります。そのため、ある程度短い期間の 24 時間程度に、期間を絞って見ていくことを推奨します。
それぞれのセクションについて詳細を見ていきます。
カウンターメトリクス
「OS メトリクス」と「データベースメトリクス」が確認できます。
OS メトリクスは CPU やメモリの情報です。
データベースメトリクスは各エンジンによって収集される統計情報です。
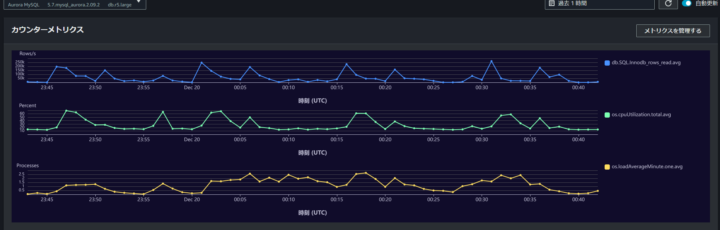
メトリクスは最大で同時に 15 個設定して確認することができます。
各メトリクスを軸にどの時間帯でパフォーマンスが悪いかを判断して次のセクションでクエリや待機イベントで詳細を見ていく流れになります。
Aurora MySQL の場合で、私がよく見るメトリクスについて記述します。
これらのメトリクスで値が大きいところでボトルネックがある箇所が多いです。
- データベースメトリクス
- Innodb_rows_read:InnoDB テーブルから読み取られた行数
- innodb_rows_changed:InnoDB の行オペレーションの合計数
- innodb_deadlocks:デッドロックの合計数
- Innodb_row_lock_time:InnoDB テーブルの行ロックの取得に要した合計時間
- innodb_lock_timeouts:タイムアウトしたデッドロックの合計数
- OS メトリクス
- cpuUtilization total:CPU の合計使用率
- loadAverageMinute:過去 1,5,15 分間に CPU 時間をリクエストしたプロセスの数
各メトリクスの詳細は以下をご覧ください。
MySQL :: MySQL 5.7 Reference Manual :: 5.1.9 Server Status Variables
拡張モニタリングの OS メトリクス – Amazon Relational Database Service
Performance Insights カウンターメトリクス – Amazon Aurora
注意事項としては、メトリクスを検索する場合は文字列完全一致なので「Com_analyze」を探すために、「com_analyze」を入力してもヒットしません。
データベース負荷
データベースロードと DB インスタンス容量の比較結果が 最大 vCPU ラインで表示されます。
データベースロードは、平均アクティブセッション (AAS) で計算されます。
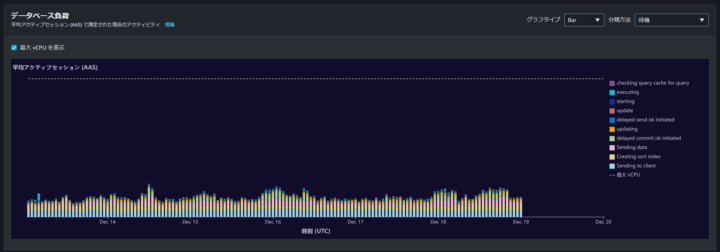
デフォルトでは、負荷が待機状態ごとに分類された平均アクティブセッションとして棒グラフに表示されています。待機、SQL、ホスト、ユーザー、データベースごとに分類して、アクティブなセッションとして負荷を表示するよう選択できます。
ここでは、平均アクティブセッション(以下、AAS と呼ぶ)について理解しておくことが大事なので解説します。
AAS はデータベースのパフォーマンスを評価するための指標になってます。
「AAS >= vCPUs」の場合はパフォーマンス問題の可能性があります。
「AAS >> vCPUs」の場合はパフォーマンス問題があります。
AAS が最大 vCPU を超えているかどうかがパフォーマンス分析の判断基準となっています。
基本的に、AAS が高い時間帯でクエリ、待機イベントをドリルダウンしていくとボトルネックが見えてきます。
このとき、冒頭で少し触れましたが、長い期間を指定して見ていると AAS が vCPU を超えていないことがあります。しかし、時間をよりドリルダウンすると vCPU を超えていることが多々あります。
例として以下グラフをご覧ください。
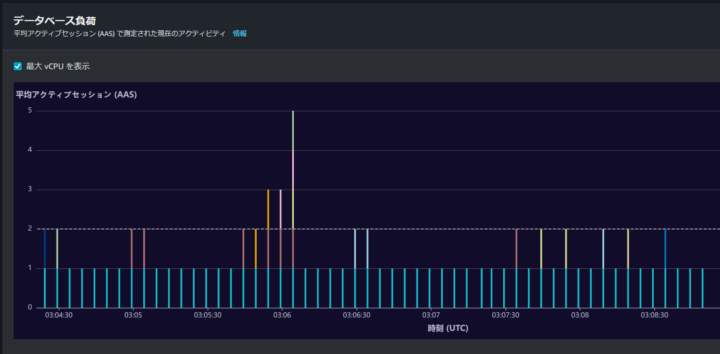
このインスタンスの最大 vCPU は 2 です。
データベース負荷のグラフで左上のチェックボックスから vCPU の表示時が可能です。(あまり期間が広いと正しく表示されません)
本画像では、03:06 付近で AAS が 5 に到達している場所があります。
これは、vCPU5 に相当する要求があったことを指します。しかし、このインスタンスの vCPU は 2 なので十分なパフォーマンスが発揮されていません。こういった部分にフォーカスを当てて DB パフォーマンス分析を行っていきます。
(より詳細は分析方法は後述します)
AAS の求め方などの詳細はドキュメントをご覧ください。
データベース負荷 – Amazon Relational Database Service
データベース負荷では、グラフタイプと分類方法を変更することができます。
- グラフタイプ
- Bar
- Line
- 分類方法
- 待機
- SQL
- ホスト
- ユーザー
- データベース
グラフタイプは好みかなと思いますが、分類方法は使い分けてみるとかなり便利です。
SQL や待機で見ていくことが多いかなと思います。
ボトルネックの分析軸
項目ごとにどれぐらいの AAS が発生したのかを確認できます。
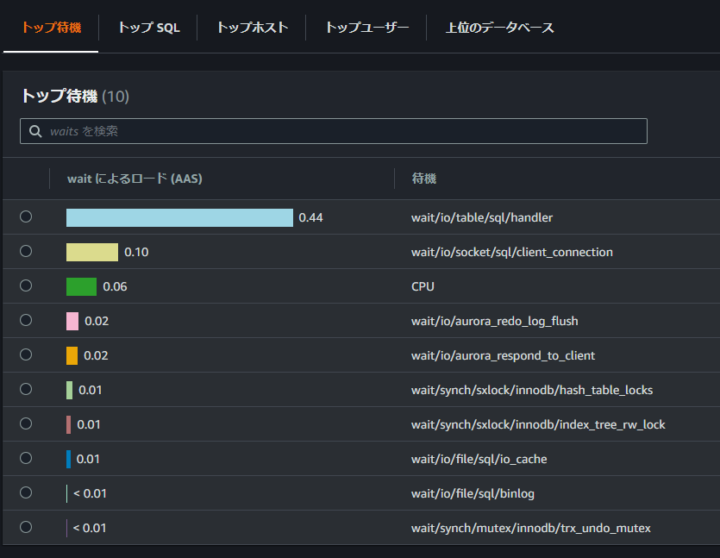
項目については以下の 5 つとなっています。
- トップ待機
- トップ SQL
- トップホスト
- トップユーザー
- 上位のデータベース
データベース負荷で発見した AAS の負荷が高い時間帯で、どういった処理が行われていたのかをここでは見ていきます。
例えば、先程の負荷があった時間帯の待機イベントを見ると以下のようになっています。
ここでは、「wait/io/table/sql/handler」というイベントがかなりの負荷になっていることが読み取れます。
- wait/io/table/sql/handler
- wait/io/socket/sql/client_connection
- CPU
また、SQL で見ると、一番負荷の高い SQL では、「wait/io/socket/sql/client_connection」が一番高い割合を占めていることがわかります。
(SQL ステートメント列は非表示にしてます)
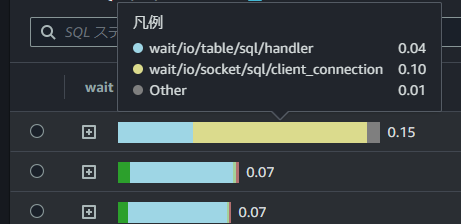
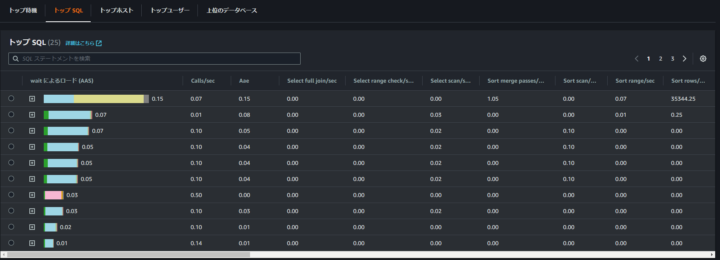
この待機イベントを見てボトルネックかどうかを判断して、ボトルネックの SQL を改善するか判断します。
[トップ SQL] タブの概要 – Amazon Relational Database Service
DB パフォーマンス分析のポイント
Performance Insights の各ダッシュボードについて解説したので、ここからは実際に各ダッシュボードを使って DB パフォーマンス分析をしていきます。
DB 分析の流れ
基本的にダッシュボードの上から見ていきます。
カウンターメトリクス分析
基本的には以下の 4 つを見ていきます。
- CPU 使用率が高い
- cpuUtilization total
- ロードアベレージが高い
- loadAverageMinute
- ロック待ち時間が長い
- Innodb_row_lock_time
- デッドロックの発生
- innodb_deadlocks
必要に応じて、以下の項目もみると値が高い箇所にボトルネックがある可能性もあります。
- Innodb_rows_read
- innodb_rows_changed
- Select_full_join
- Select_scan
「Innodb_rows_read」と「innodb_rows_changed」は、行操作が多い箇所なので、ボトルネックになっていなくても少し改善することで効果が得やすい可能性があります。
「Select_full_join」と「Select_scan」はフルスキャンを行っているクエリが多い箇所なので、適切な INDEX が貼られていない可能性があります。
クエリのフォーカスをする場合、「Innodb_buffer_pool」系のメトリクスも見ると良いです。
では、直近一週間でダッシュボードを見ていきます。
「cpuUtilization」で見ると、2/17 の 19 時台が怪しいです。
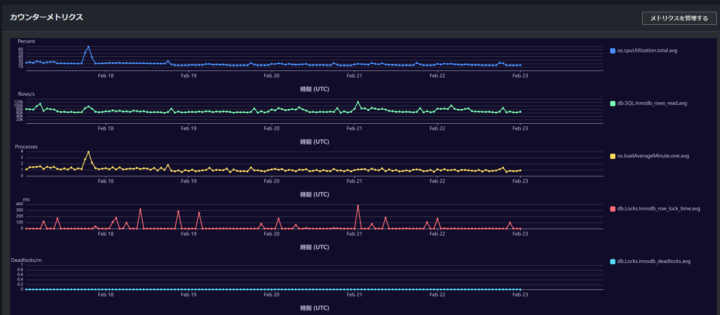
さらに、「innodb_rows_changed」や「loadAverageMinute」で見ても値が高くなっていることがわかります。
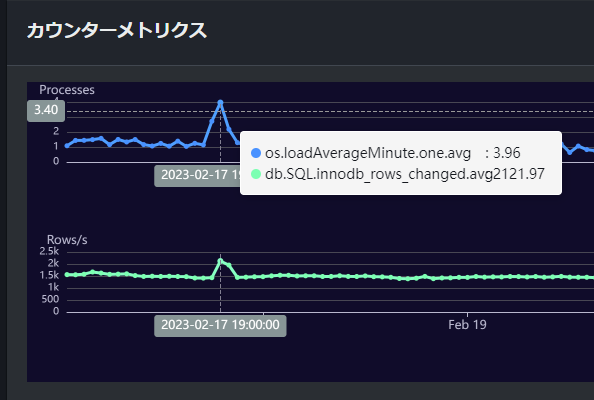
次はデータベース負荷分析でこの時間帯の負荷についてより詳細に見ていきます。
データベース負荷分析
まずは、カウンターメトリクスと同じ 1 週間で見ていきます。
分かりづらいですが、上の点線が最大 vCPU のラインを表しています。そのため、カウンターメトリクスで目星をつけた 2/17 の 19 時台は負荷がほかと比べて高いですが問題はなさそうに見えます。
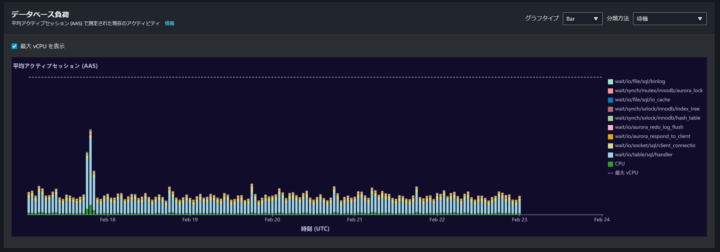
しかしこれが注意です。
少しずつ負荷の高い部分だけを表示してみます。
目星をつけた時間の前後 10 時間程度を表示。
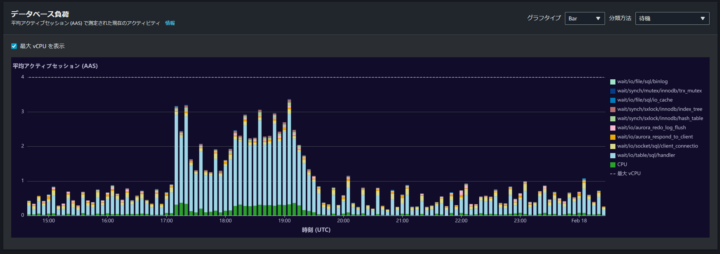
更に、時間をドリルダウンして目星をつけた時間の前後 1,2 時間程度を表示します。
すると、最大 vCPU の点線を超えたことがわかります。
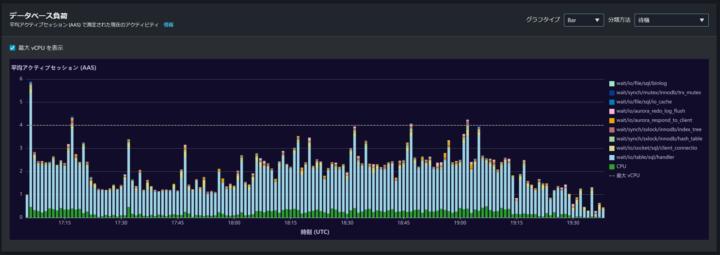
さらに、10 分程度まで絞って表示します。
ここまで細かい時間で見ると負荷としてはかなり高く、要求された vCPU 処理量は最大 vCPU を遥かに超え、13vCPU の処理を要求していたことがわかります。
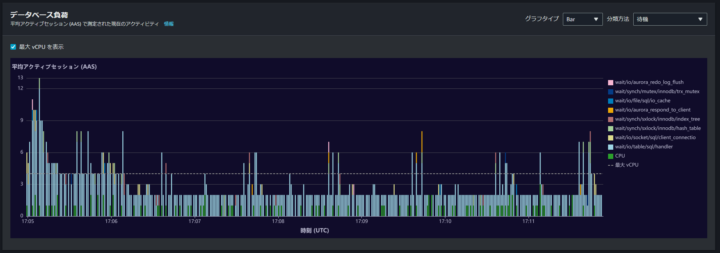
該当時間にカーソルを合わせると待機イベントの割合が見れます。
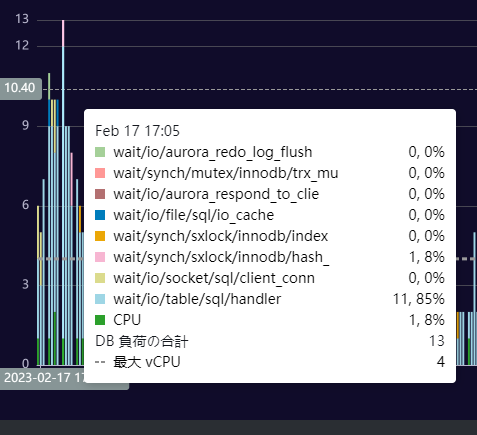
「wait/io/table/sql/handler」が 85%と高い割合を占めています。
この項目を次のボトルネックの分析でより詳細に見て行きます。
ボトルネックの分析
17:05~17:12 の間に絞って見てみます。
(ホスト、ユーザー、データベースについては環境に依存するため割愛します)
該当時間で起きていたトップ待機イベント一覧は以下のような結果となってます。
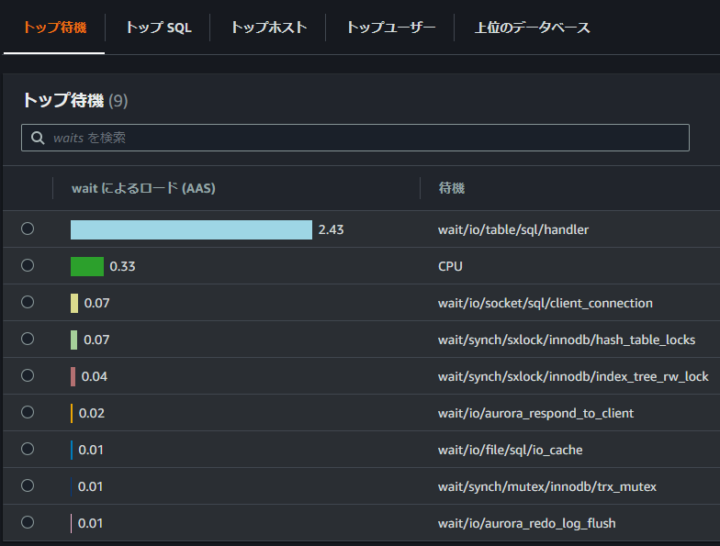
先程のデータベース負荷分析で見たように「wait/io/table/sql/handler」が AAS 2.43と一番高い値を記録しています。
次に高いのが「CPU」になっています。
また次に、トップ SQL で見るとこのような結果となってます。
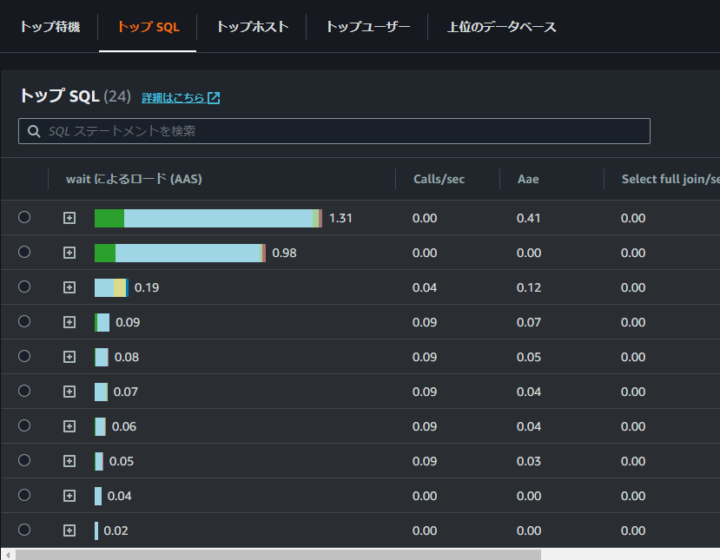
SQLステートメントの詳細は見せれませんが、一番AASが高いSQLはINSERT 文の処理で「wait/io/table/sql/handler」が一番負荷の割合を占めていることがわかります。
この「wait/io/table/sql/handler」という待機イベントについてもう少し解説します。
wait/io/table/sql/handler 待機イベント状態
io/table/sql/handler イベントは、作業がストレージエンジンに委任されたときに発生します。
io/table/sql/handler – Amazon Aurora
この待機イベントの増加は、I/O が増加していることを意味します。
そのため、INSERT 文のときにはこのイベントが、多く負荷を占めていることがあります。
この待機イベントを改善するアクションとしては以下が考えられます。
- イベントの原因となるセッションとクエリを特定する
- Performance Insights カウンター指標との相関関係をチェックする
- 他の相関待ちイベントがないかチェックする
詳細は以下ドキュメントを御覧ください。
アクション
待機イベントを使用した Aurora MySQL のチューニング
Aurora の場合は、頻出する待機イベントのチューニングに関するドキュメントがあります。
MySQL
待機イベントを使用した Aurora MySQL のチューニング – Amazon Aurora
PostgreSQL
Aurora PostgreSQL の待機イベントでのチューニング – Amazon Aurora
なお、バージョンによっても表示されるイベントが異なっておりますのでご注意ください。
こういったイベントの分析をする際は、DB エンジンごとに動作が異なるためエンジンのドキュメントも合わせてみることをおすすめします。
MySQL :: MySQL 8.0 リファレンスマニュアル :: 27.12.18.8 テーブル I/O およびロック待機サマリーテーブル
初めての Performance Insights 入門 | Amazon Web Services ブログ
パフォーマンス改善
負荷が高い SQL や待機イベントが判明したら、次はどう解決していくかを考えます。
大きく分けると以下 2 つになると思います。
- SQL チューニング
- インスタンスチューニング
INDEX が正しく使われていない場合は SQL チューニングをすることにより効果が得られます。しかし、適切な INDEX を利用しているが遅い場合は、そもそもインスタンスのリソースが低い可能性があります。その場合は、インスタンスチューニングでスケールアップ・スケールアウトをすることで効果が得られます。
もしくは、テーブルシャーディングでデータを分散させる方法もあります。
データ量が多かったり、DB エンジンが得意としていない型を利用している場合は、ほかの AWS のデータベースサービスへの乗り換えもご検討ください。
参考資料
突然データベースのパフォーマンスが悪化、あなたならどうする?
Amazon RDS におけるパフォーマンス最適化とパフォーマンス管理
Performance Insights を使用した Amazon RDS データベースの負荷分析 | Amazon Web Services ブログ
初めての Performance Insights 入門 | Amazon Web Services ブログ
Amazon RDS Performance Insights のカウンターメトリクスを Amazon CloudWatch にインポートする | Amazon Web Services ブログ
Performance Insights を使用して Amazon Aurora の MySQL のワークロードを分析する | Amazon Web Services ブログ

2021年新卒入社。インフラエンジニアです。RDBが三度の飯より好きです。 主にデータベースやAWSのサーバレスについて書く予定です。あと寒いのは苦手です。


Recommends
こちらもおすすめ
-

Amazon RDS のパラメータグループを比較する
2024.3.7



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16