Amazon Redshift と Amazon Aurora MySQL のゼロ ETL 統合の検証記録
2025.7.9

概要
Amazon Redshift と Amazon Aurora MySQL のゼロ ETL 統合機能について、検証を行った記録をまとめました。
ゼロ ETL 統合とは、Aurora に蓄積されたデータを ETL パイプラインなしにニアリアルタイムで Redshift に連携する機能になっています。
詳細な解説は以下を参照してください。
ゼロ ETL とは何ですか? – ゼロ ETL の説明 – AWS
その ETL パイプラインもういらないかも︖zero-ETL 総まとめ︕
検証記録
今回は、以下の構成でゼロ ETL を使用します。
- ソース:Aurora Serverless (MySQL)
- ターゲット:Redshift プロビジョニング
検証の流れは以下の通りです。
- 制限の確認
- Aurora と Redshift の環境構築
- ゼロ ETL の設定
- Redshift データベースの初期設定
- 動作確認
1. 制限の確認
ゼロ ETL には、複数の制限が存在するので、まずは制限の確認が必要です。
Aurora と Redshift 側のドキュメントで、それぞれ異なる制限が記載されているため、双方のドキュメントを確認してください。
量が多いためポイントをいくつかピックアップしてまとめます。
Amazon Redshift でゼロ ETL 統合を使用する際の考慮事項 – Amazon Redshift
Amazon Redshift との Aurora ゼロ ETL 統合 – Amazon Aurora
ピックアップしたポイント
- クラスタがブルー/グリーンのデプロイのソースである場合、ブルー環境とグリーン環境は切り替え時に既存のゼロ ETL 統合を持つことはできません
- 最初に統合を削除して切り替えを行い、その後再作成する必要があります
- 初めて統合を作成するとき、またはテーブルを再同期するとき、ソースデータベースのサイズによっては、ソースからターゲットへのデータシードに 20 ~ 25 分以上かかる場合があります
- ソース DB クラスターは、サポートされているバージョンの Aurora MySQL を実行している必要があります
- 東京リージョン:バージョン 3.05.2 以上
- Amazon Redshift とのゼロ ETL 統合でサポートされているリージョンと Aurora DB エンジン – Amazon Aurora
- ゼロ ETL 統合では、MySQL バイナリロギング (binlog) を利用して継続的なデータ変更をキャプチャします
- 詳細は後述しますが、複数のパラメータの設定が必要です
- ターゲットの Redshift クラスター設定は、次の前提条件を満たしている必要があります
- Redshift Serverless または RA3 ノードタイプ
- 暗号化 (プロビジョニングされたクラスターを使用している場合)
- 大文字と小文字の区別が有効(enable_case_sensitive_identifier)
- 統合ソースのテーブルには主キーが必要です
- Redshift の VARCHAR データ型の最大長は 65,535 バイトです
2. Aurora と Redshift の環境構築
クラスター作成時に注意が必要な設定だけを抜粋して記載いたします。
構築の詳細な手順は、以下を参照していただくとわかりやすいと思います。
Amazon Aurora と Amazon Redshift のゼロ ETL 統合を使用したニアリアルタイム運用分析のためのスタートガイド | Amazon Web Services ブログ
Amazon Redshift との Aurora ゼロ ETL 統合の開始方法 – Amazon Aurora
Aurora クラスターの作成の注意点
MySQL バイナリロギング (binlog)を有効にするため、カスタムパラメータで以下を設定します。
- aurora_enhanced_binlog=1
- 拡張バイナリログの有効化設定
- Aurora MySQL の拡張バイナリログの設定 – Amazon Aurora
- binlog_backup=0
- 拡張バイナリログを使用する場合にのみオフ
- binlog_replication_globaldb=0
- 拡張バイナリログを使用する場合にのみオフ
- binlog_format=ROW
- binlog_row_metadata=full
- 行ベースロギングの使用時にバイナリログに追加されるテーブルメタデータの量を構成
- FULL (すべてのメタデータが含まれます)
- MySQL :: MySQL 8.0 リファレンスマニュアル :: 17.1.6.4 バイナリロギングのオプションと変数
- binlog_row_image=full
- 行イメージをバイナリログに書き込む方法
- full (すべてのカラムをログに記録)
- MySQL :: MySQL 8.0 リファレンスマニュアル :: 17.1.6.4 バイナリロギングのオプションと変数
なお、以下のパラメータは Static なため、設定を反映するにはクラスターの再起動が必要となりますのでご注意ください。
- aurora_enhanced_binlog
- binlog_backup
- binlog_replication_globaldb
- binlog_format
また、以下のパラメータはデフォルト値であれば問題ありませんが、もしデフォルトから変更されている場合は、以下の値に設定されていないことを確認してください。
- binlog_transaction_compression が 「ON」 ではないこと
- バイナリログトランザクション圧縮の設定
- MySQL :: MySQL 8.0 リファレンスマニュアル :: 5.4.4.5 バイナリログトランザクション圧縮
- binlog_row_value_options が 「PARTIAL_JSON」 ではないこと
- PARTIAL_JSON に設定すると、JSON ドキュメントの小さい部分のみを変更する更新に領域効率のよいバイナリログ形式を使用できるようになります
- MySQL :: MySQL 8.0 リファレンスマニュアル :: 17.1.6.4 バイナリロギングのオプションと変数
Amazon Redshift と Aurora のゼロ ETL 統合を始める – Amazon Aurora
Redshift クラスターの作成の注意点
Redshift 側では以下の 2 つの対応が必要になります。
- データウェアハウスで大文字と小文字の区別を有効にする
- パラメータグループで「enable_case_sensitive_identifier」を有効化するだけです
- データウェアハウスで大文字と小文字の区別を有効にする – Amazon Redshift
- データウェアハウスを承認する
プロビジョニングされたクラスターへのゼロ ETL 統合を作成するには、関連付けられた名前空間またはプロビジョニングされたクラスターへのアクセスの承認が必要になります。
自身の AWS アカウントの ID を承認されたプリンシパルとして追加します。
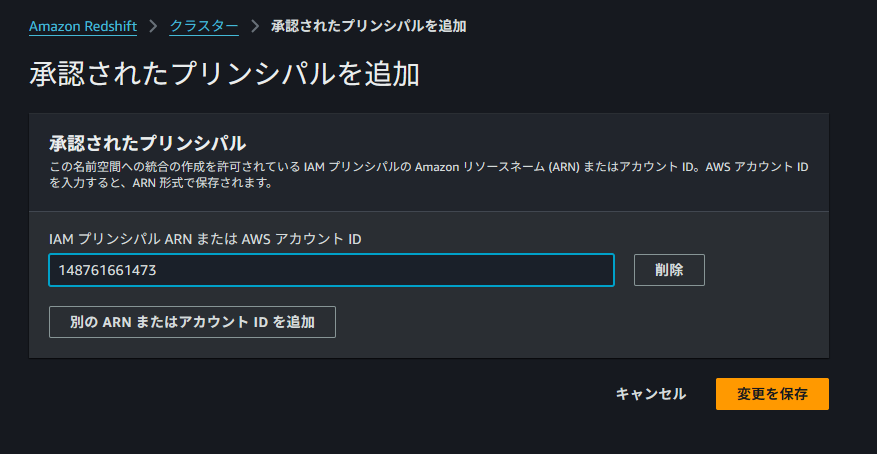
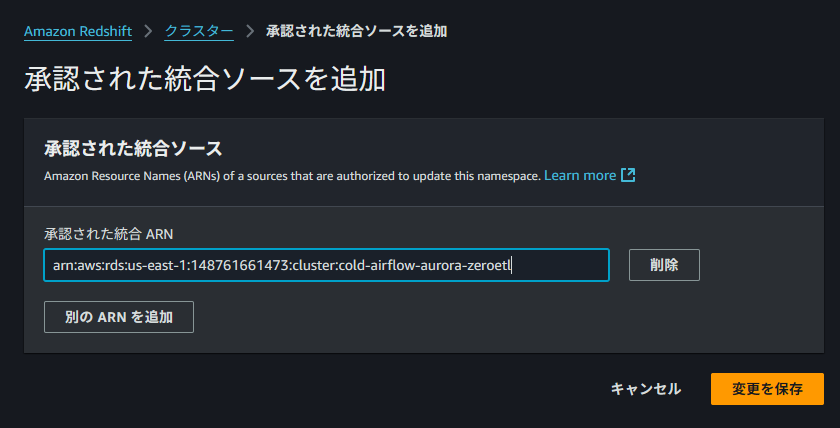
続いては、ソースが Redshift のデータを更新できるようにするために、ソースを承認済み統合ソースとして名前空間に追加する必要があります。
ソースとなる Aurora の ARN を承認された統合ソースとして追加します。
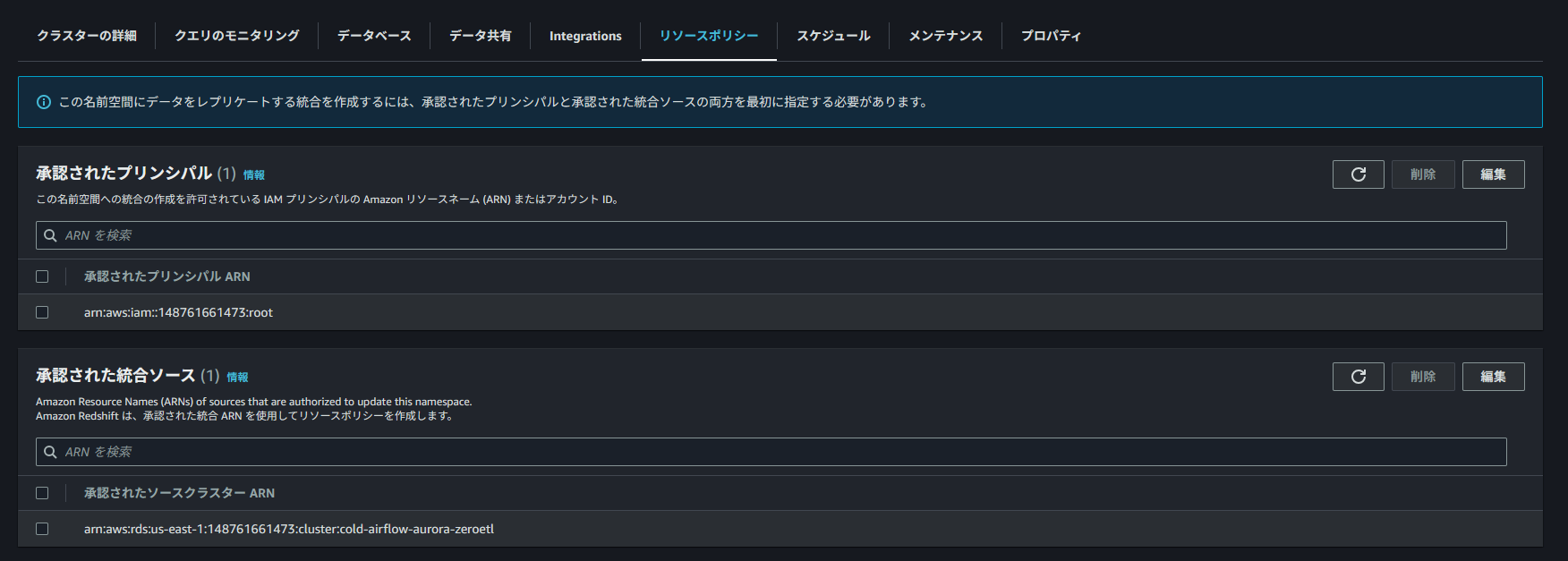
どちらも追加が完了すると以下の状態になります。
サンプルデータベースのインポート
ゼロ ETL では、統合を開始すると Aurora のデータが Redshift 側へ自動的に連携されます。
そのため、Aurora には初期データとして MySQL のサンプルデータベースの「world_x」をインポートしておきます。
MySQL :: MySQL 8.0 リファレンスマニュアル :: 20.3.2 world_x データベースのダウンロードおよびインポート
Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 58 Server version: 8.0.39 2f855dc7 Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | world_x | +--------------------+ 5 rows in set (0.00 sec) MySQL [(none)]> use world_x Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed MySQL [world_x]> show tables; +-------------------+ | Tables_in_world_x | +-------------------+ | city | | country | | countryinfo | | countrylanguage | +-------------------+ 4 rows in set (0.00 sec)
3. ゼロ ETL の設定
Aurora と Redshift の設定が整ったので、次はゼロ ETL の設定を行います。
Aurora クラスター設定画面から実施します。
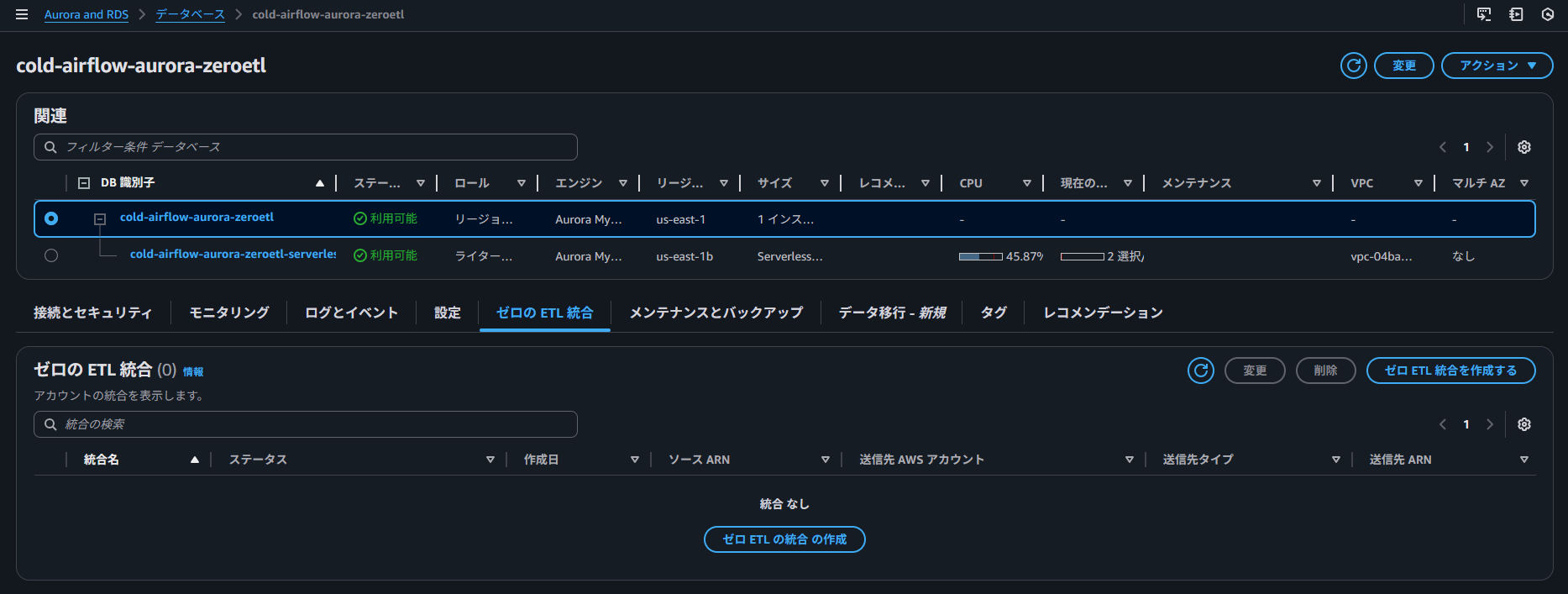
まずは、ソースを選択します。
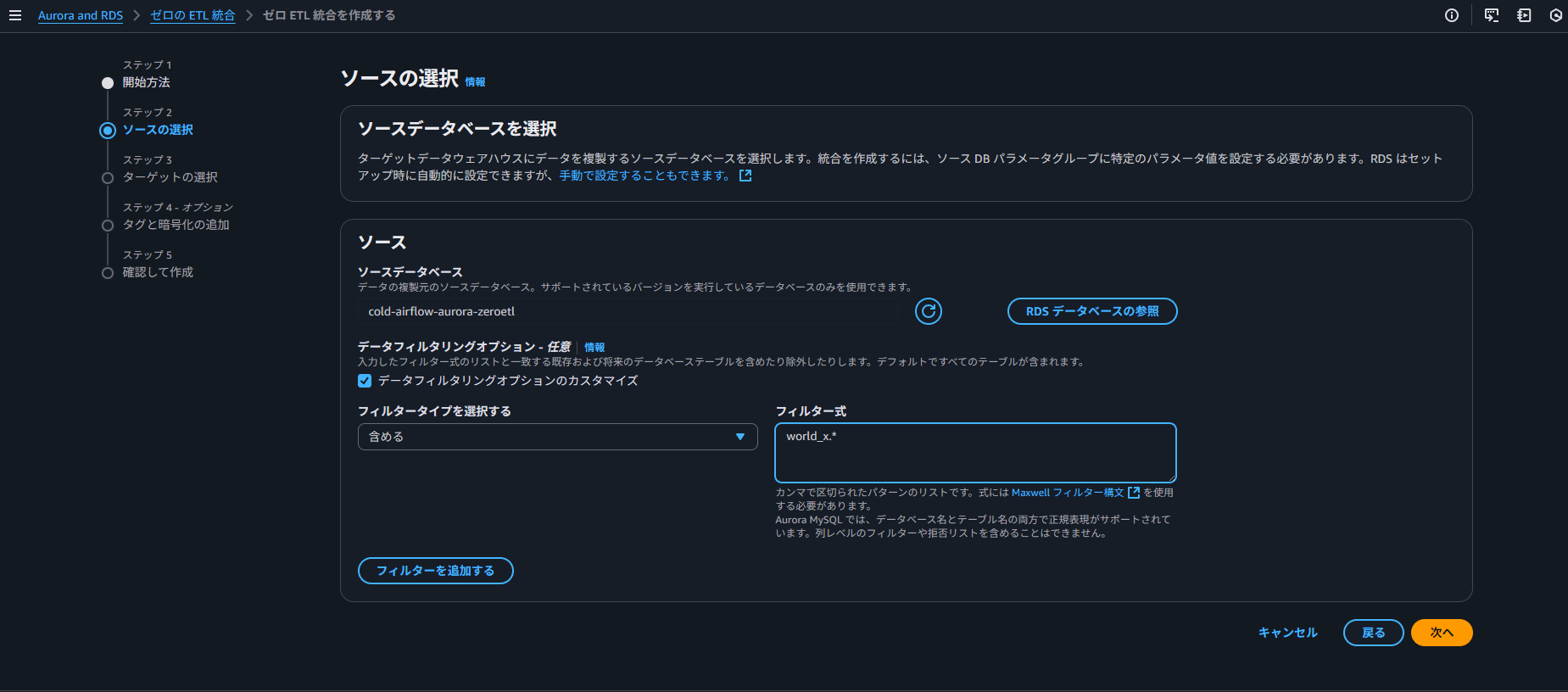
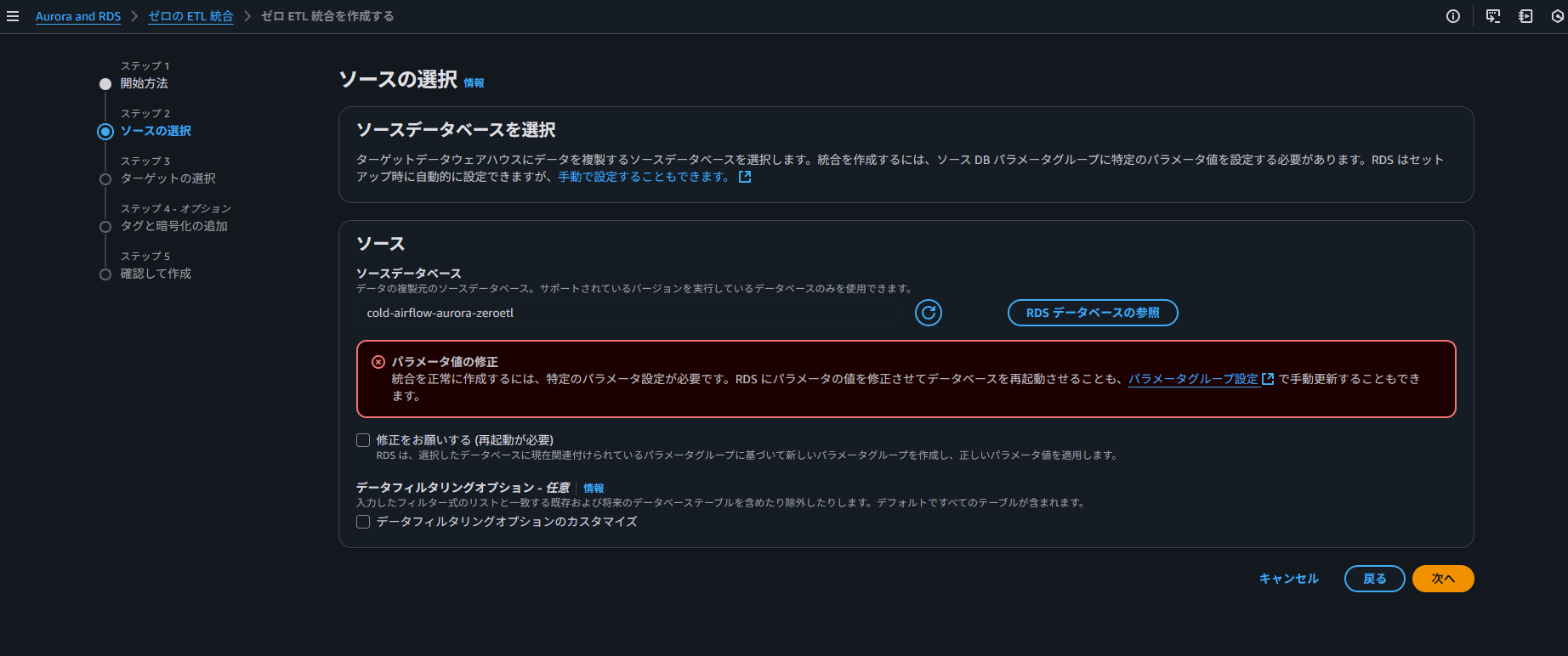
なお、この時点で Aurora の設定ができていない場合はエラーが表示されます。
続いて、ターゲットを選択します。
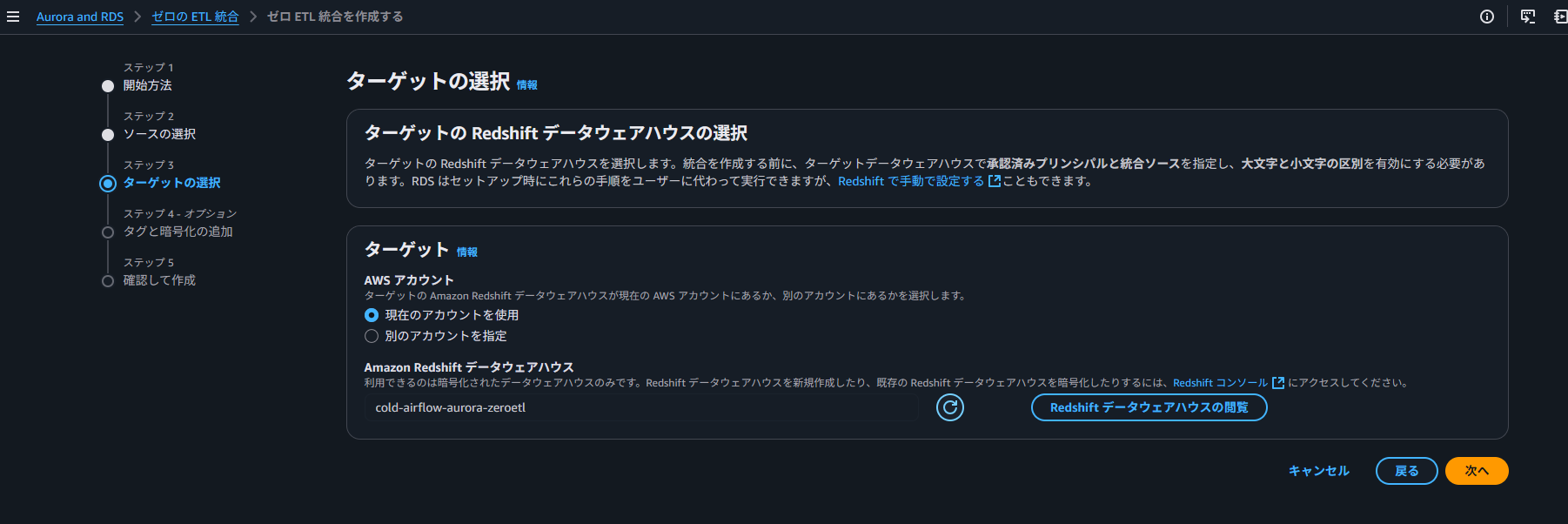
こちらも、Redshift の設定ができていない場合はエラーが表示されます。
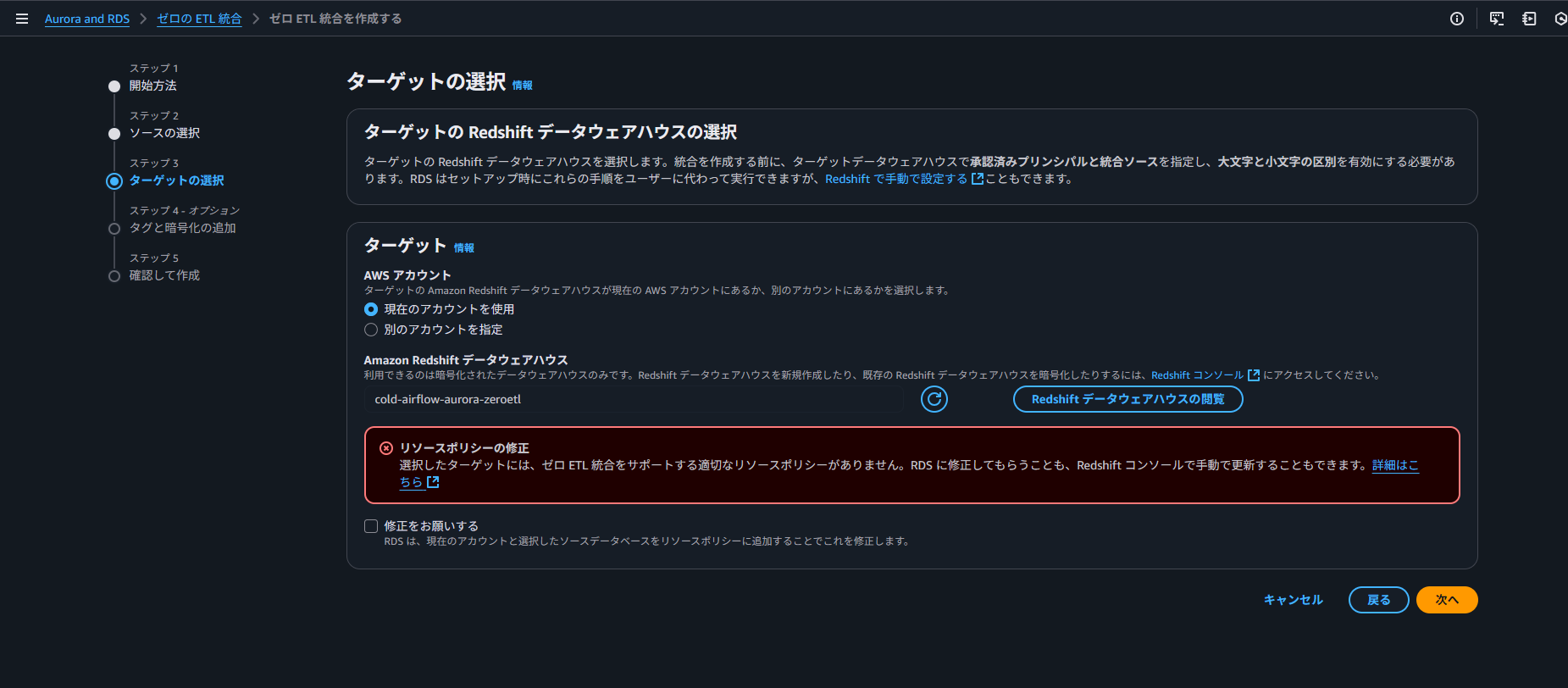
設定はこれで完了ですが、データ同期が完了するまで暫くの間待機します。
検証の時は 20 分ほど待機しました。
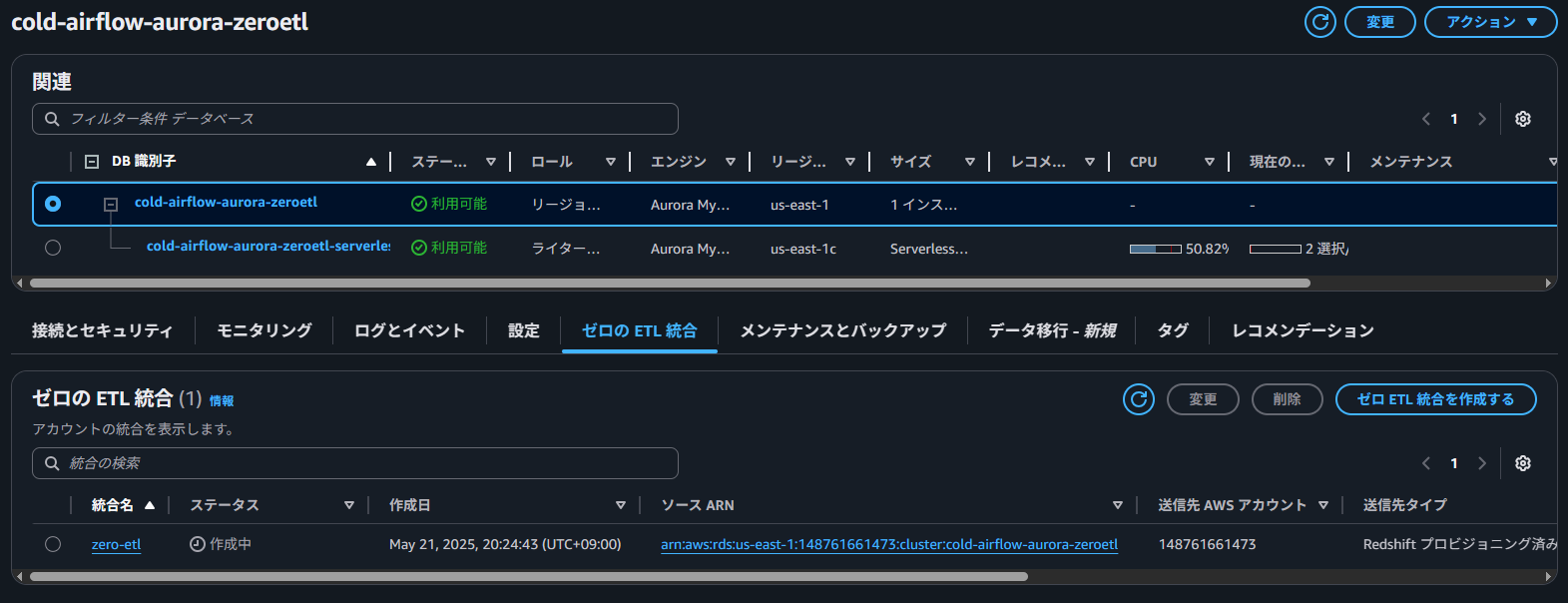
暫く待つとステータスがアクティブに変わります。
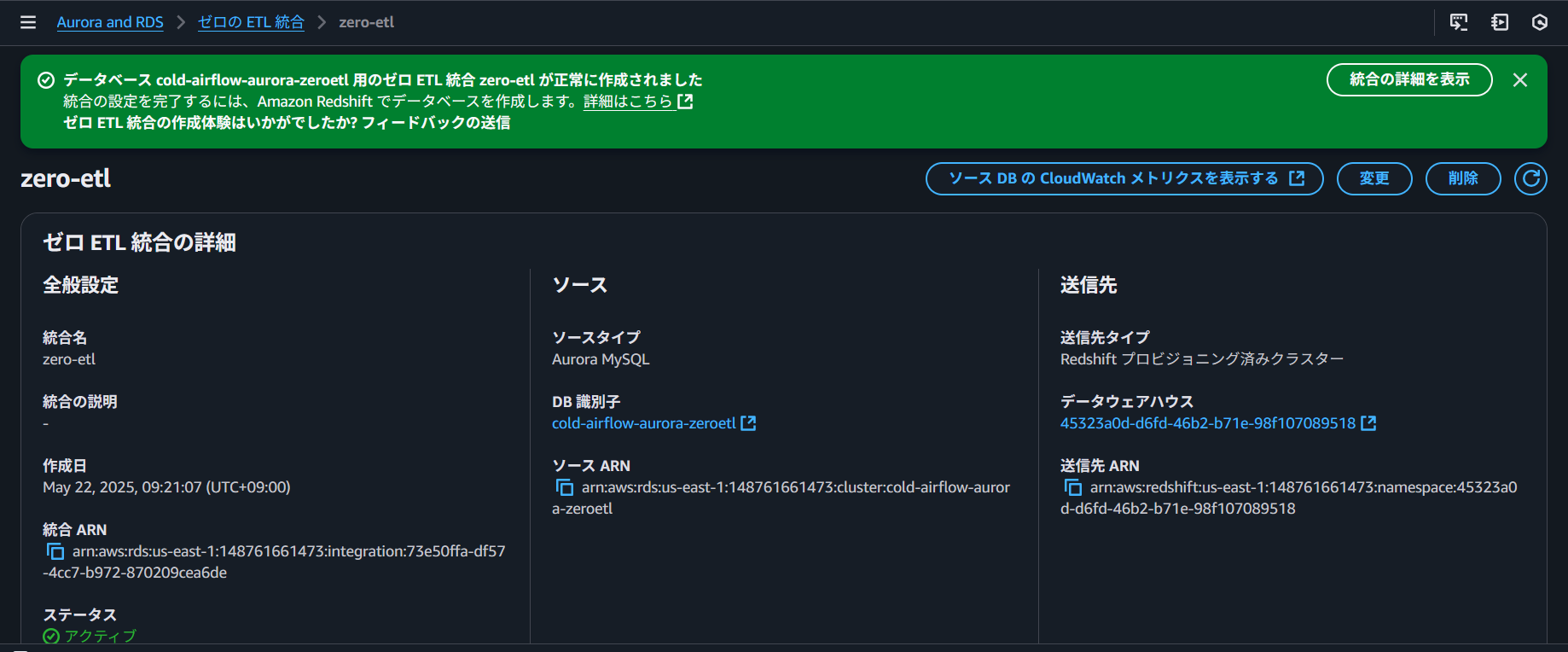
4. Redshift データベースの初期設定
最後に、Redshift 側で連携するデータベースの設定を行います。
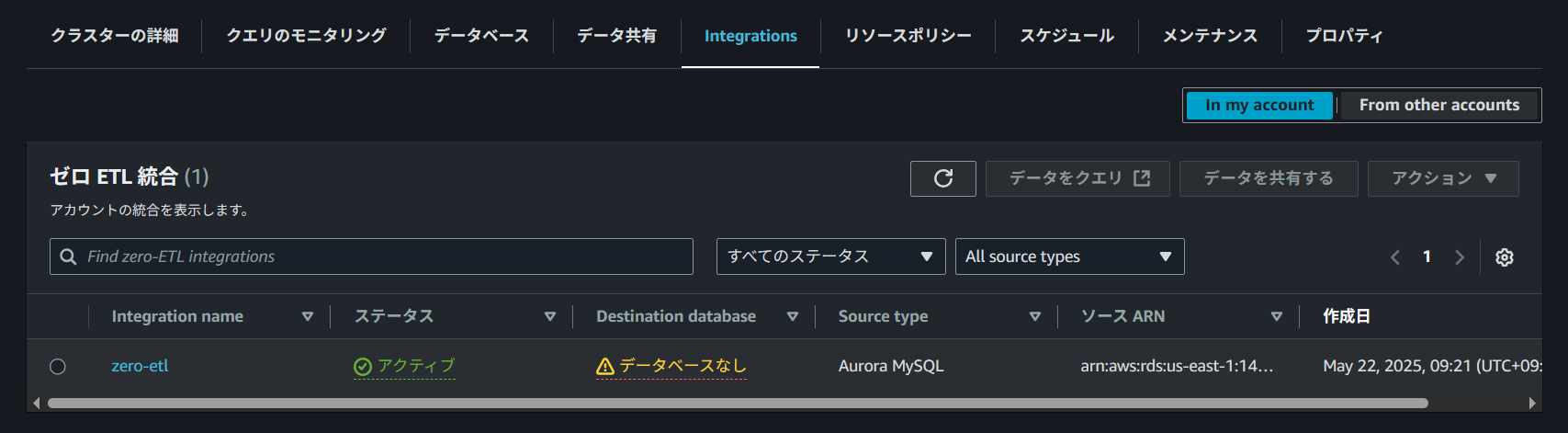
データベースの設定を行う前だと以下のように「データベースなし」と表記されています。
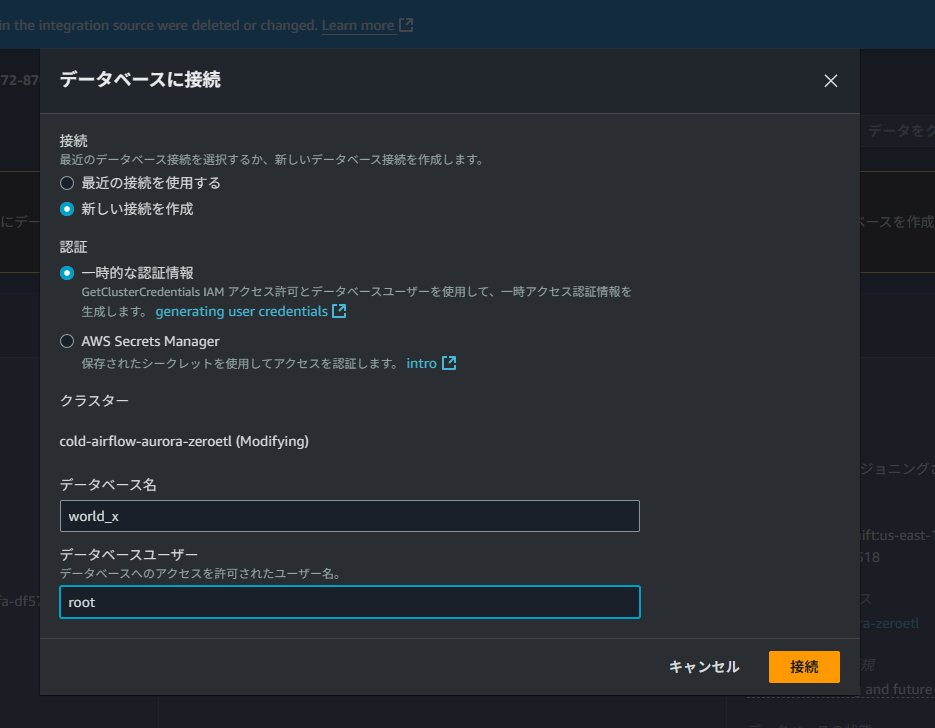
この作業は、SQL を実行するためクエリエディタで Redshift に接続します。
今回は、作成したユーザー名とパスワードで接続します。
そして以下の SQL を実行します。
select integration_id from svv_integration;
取得した「integration_id」の結果を、以下の SQL に書き換えてデータベースを作成します。
※データベース名は任意の名前を指定
CREATE DATABASE aurora_zeroetl FROM INTEGRATION '<result from above>';
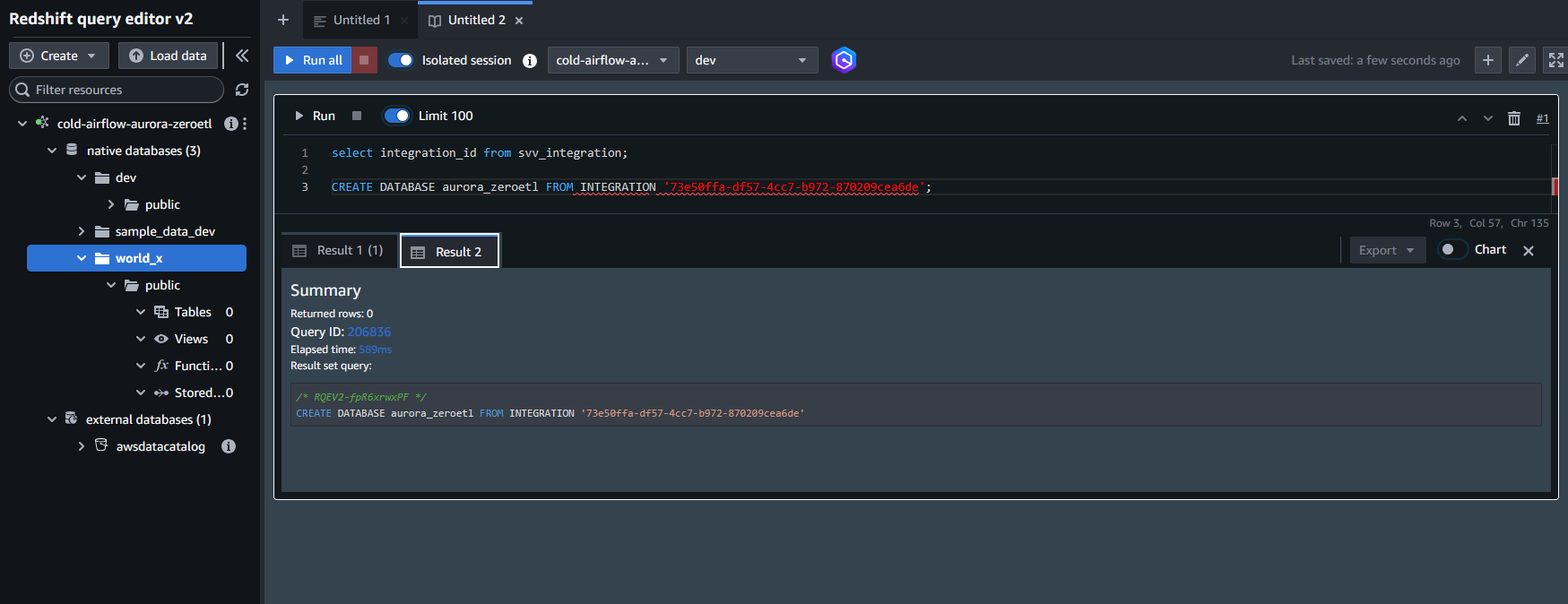
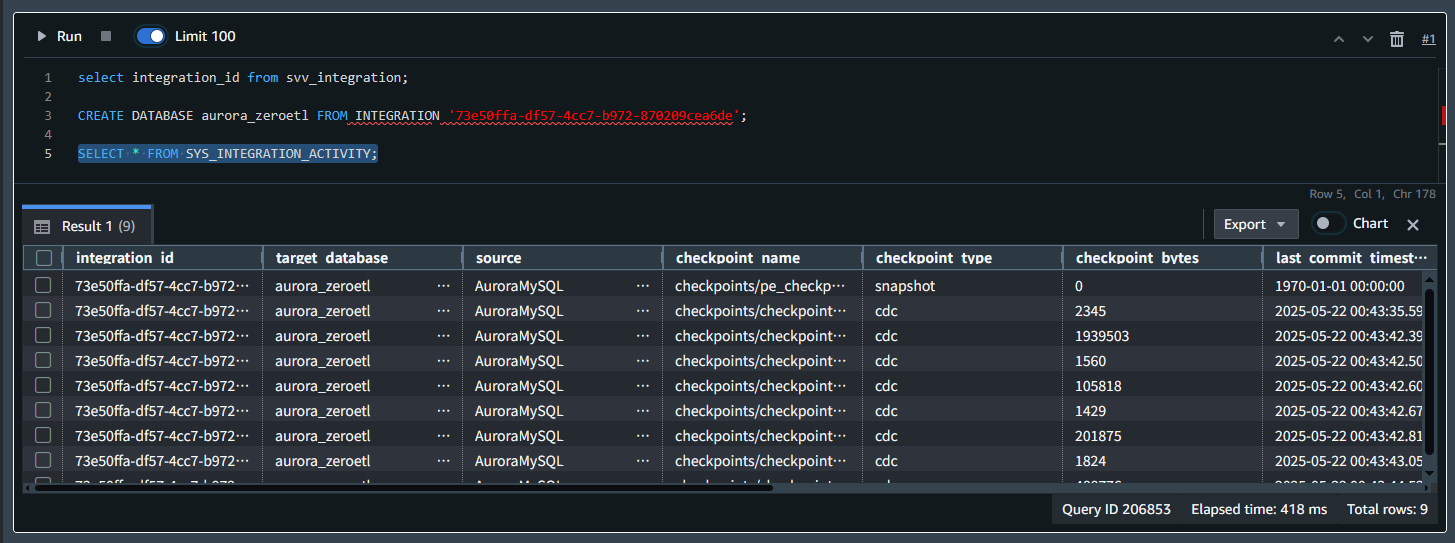
以下の SQL を実行することで統合のログを確認ができます。
SELECT * FROM SYS_INTEGRATION_ACTIVITY;
また、先ほど作成した新しいデータベースに対して SELECT を行うと Aurora と同じデータが格納されていることが確認できます。
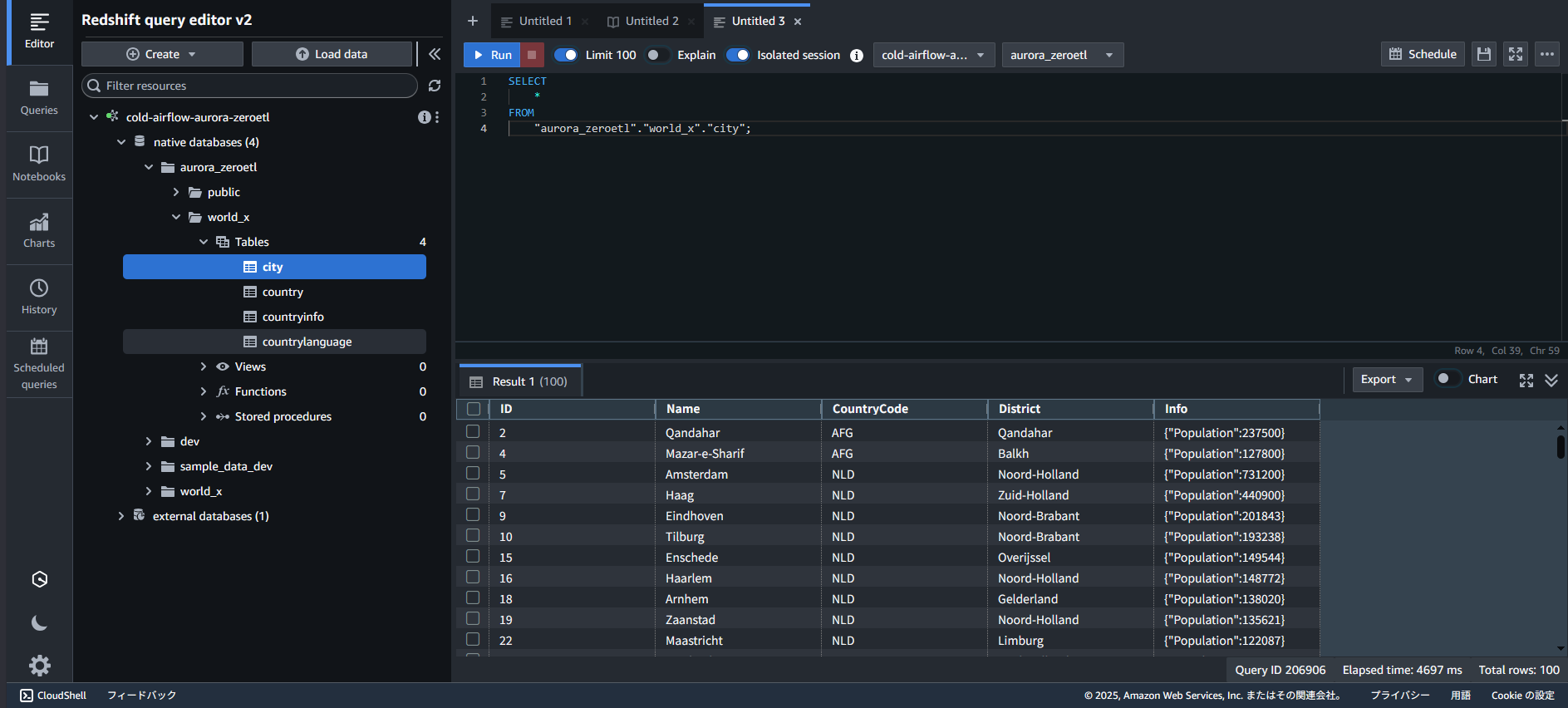
これでゼロ ETL の接続設定が完了しました。
次は、Aurora 側でデータを追加・更新して Redshift 側でどう変化するかを確認します。
5. 動作確認
今回は、以下 2 つの動作を確認します。
- 新規データを追加したときの動作
- 既存データを更新したときの動作
新規データを追加したときの動作
Aurora 側に新規データを追加した際の動作について検証を行います。
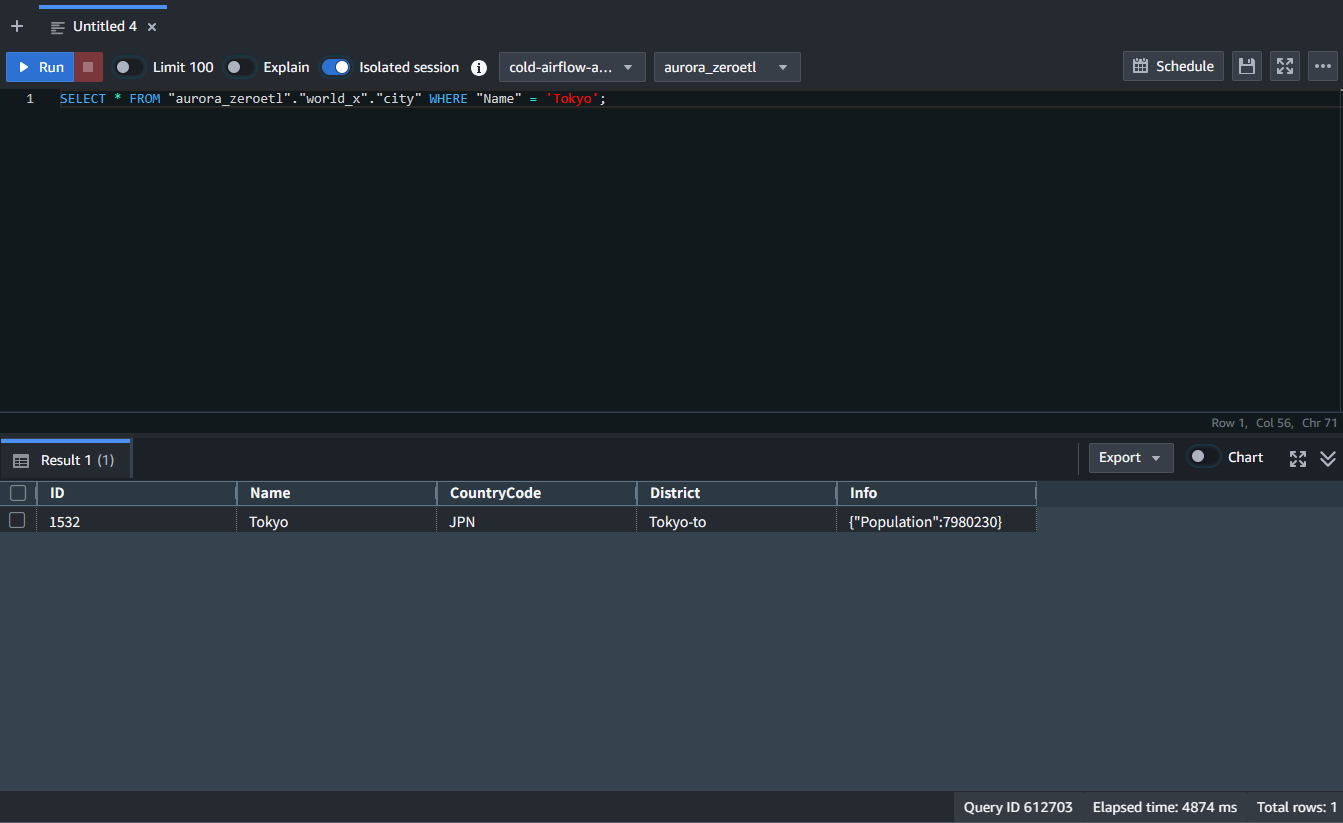
まずは、既存のデータを確認するため Redshift 側で、以下条件で SELECT します。
- テーブル名:
City - カラム名:
Name - 値:
Tokyo
結果としては一行のみとなっています。
では、Aurora 側に接続してTokyoのデータを一行追加します。
MySQL [world_x]> SELECT * FROM city WHERE Name = 'Tokyo';
+------+-------+-------------+----------+-------------------------+
| ID | Name | CountryCode | District | Info |
+------+-------+-------------+----------+-------------------------+
| 1532 | Tokyo | JPN | Tokyo-to | {"Population": 7980230} |
+------+-------+-------------+----------+-------------------------+
1 row in set (0.06 sec)
MySQL [world_x]> INSERT INTO city ( Name, CountryCode, District, Info) VALUES ( 'Tokyo', 'JPN', 'Tokyo', '{"Population":13960000}');
Query OK, 1 row affected (0.01 sec)
MySQL [world_x]> SELECT * FROM city WHERE Name = 'Tokyo';
+------+-------+-------------+----------+--------------------------+
| ID | Name | CountryCode | District | Info |
+------+-------+-------------+----------+--------------------------+
| 1532 | Tokyo | JPN | Tokyo-to | {"Population": 7980230} |
| 4080 | Tokyo | JPN | Tokyo | {"Population": 13960000} |
+------+-------+-------------+----------+--------------------------+
2 rows in set (0.00 sec)
Redshift 側で確認すると追加した行が増えています。
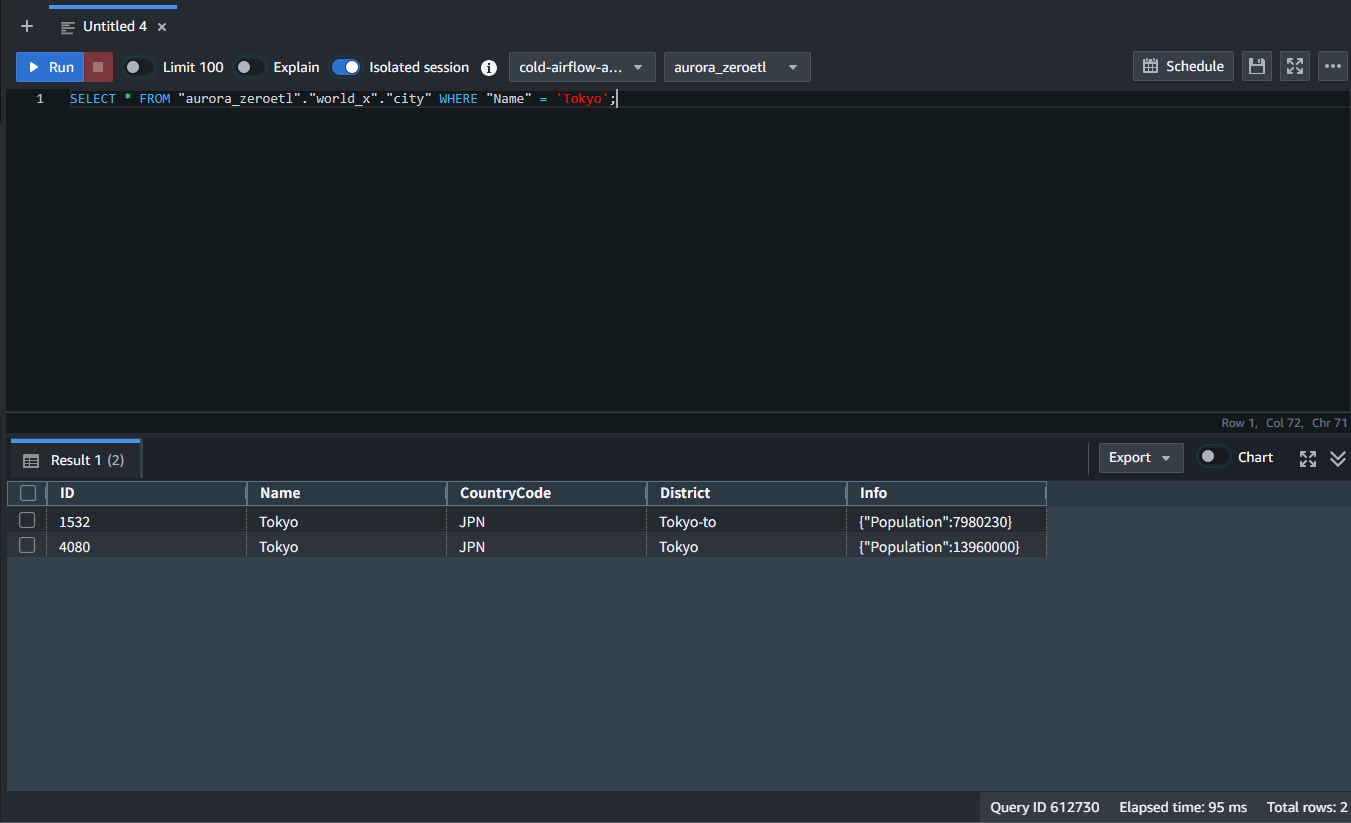
ゼロ ETL で自動的に連携されることを確認しました。
既存データを更新したときの動作
続いては、先程追加したデータを更新してみます。
- テーブル名:
City - カラム名:
District - 値:
Tokyo→Tokyou-toto
MySQL [world_x]> SELECT * FROM city WHERE Name = 'Tokyo';
+------+-------+-------------+----------+--------------------------+
| ID | Name | CountryCode | District | Info |
+------+-------+-------------+----------+--------------------------+
| 1532 | Tokyo | JPN | Tokyo-to | {"Population": 7980230} |
| 4080 | Tokyo | JPN | Tokyo | {"Population": 13960000} |
+------+-------+-------------+----------+--------------------------+
2 rows in set (0.00 sec)
MySQL [world_x]> update city set District = 'Tokyou-toto' where ID = 4080;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL [world_x]> SELECT * FROM city WHERE Name = 'Tokyo';
+------+-------+-------------+-------------+--------------------------+
| ID | Name | CountryCode | District | Info |
+------+-------+-------------+-------------+--------------------------+
| 1532 | Tokyo | JPN | Tokyo-to | {"Population": 7980230} |
| 4080 | Tokyo | JPN | Tokyou-toto | {"Population": 13960000} |
+------+-------+-------------+-------------+--------------------------+
2 rows in set (0.00 sec)
Redshift 側で確認すると更新されていることが確認できました。
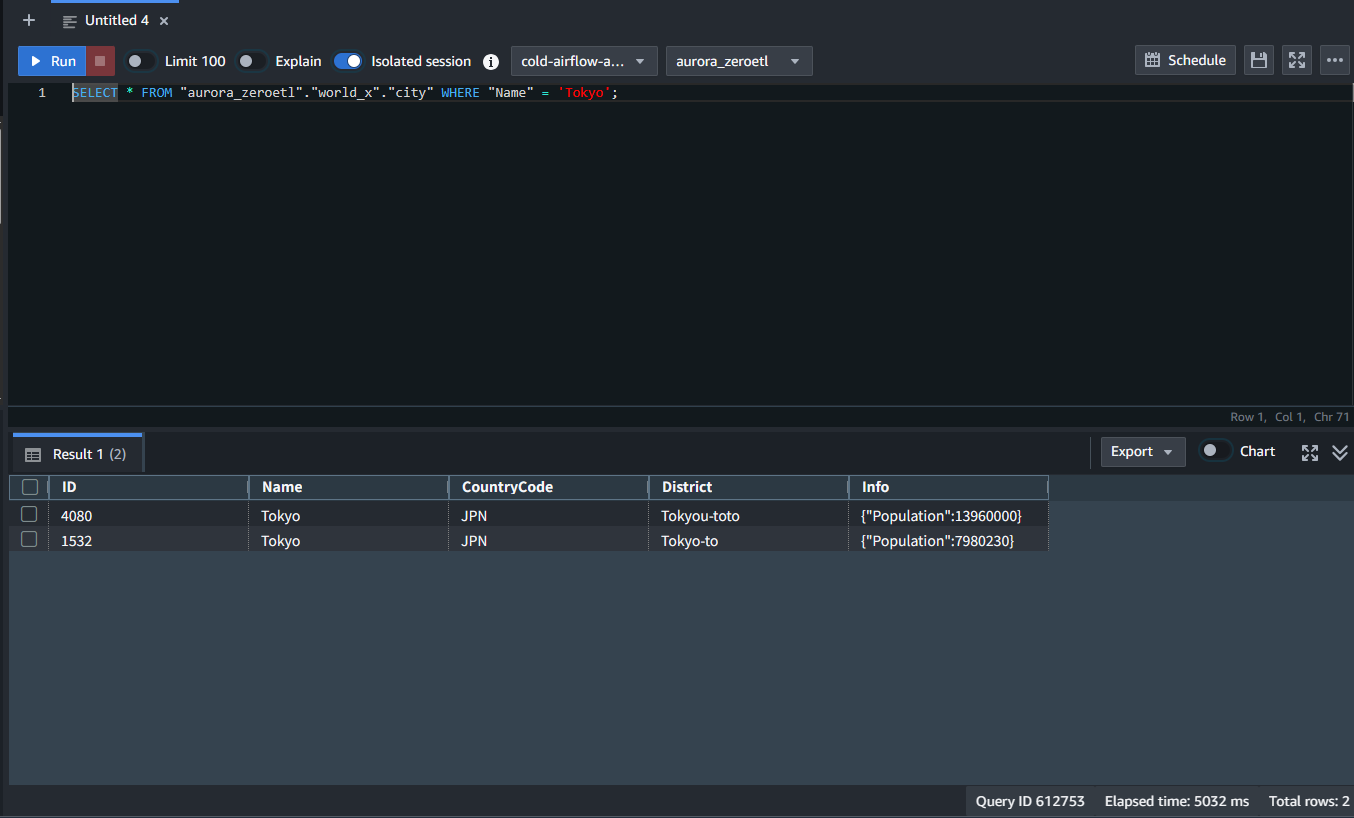
ソースに変更が発生しても、自動的に変更が行われることを確認しました。
まとめ
ゼロ ETL 統合を活用することで、手軽に Redshift へのデータ連携が実現できました。
現在、Aurora を使用してデータ分析系のクエリを実行しているが、クエリのパフォーマンスが悪い場合は、ゼロ ETL で Redshift を活用してみるのも一つの手かもしれません。
参考情報
プレビューの制限事項 – Amazon Redshift
Amazon Redshift との Aurora ゼロ ETL 統合 – Amazon Aurora
Amazon Redshift とのゼロ ETL 統合でサポートされているリージョンと Aurora DB エンジン – Amazon Aurora
PDF_AmazonAurora と AmazonRedshift の Zero-ETL 統合のご紹介.pdf
Zero-ETL 統合を活用した業務データベースのニアリアルタイム分析
Amazon Aurora と Amazon Redshift のゼロ ETL 統合を使用したニアリアルタイム運用分析のためのスタートガイド | Amazon Web Services ブログ

2021年新卒入社。インフラエンジニアです。RDBが三度の飯より好きです。 主にデータベースやAWSのサーバレスについて書く予定です。あと寒いのは苦手です。


Recommends
こちらもおすすめ
-

Amazon Aurora MySQL バージョンアップグレード覚書
2022.9.19
-

Google BigQueryからAmazon Redshiftにデータを移行してみる
2019.11.29




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16