【生成AI】Gemini 1.5 FlashがVertex AIで利用可能になりました!
2024.5.20

はじめに
こんにちは、Shunです!
「Gemini 1.5 Flash」が Vertex AIで利用可能となりました!!
本記事では、Gemini 1.5 Flashの使用方法や使用感について、ご紹介出来ればと思います!
Gemini 1.5 Pro updates, 1.5 Flash debut and 2 new Gemma models
Gemini?Vertex AIとGeminiって何が違うの?って方は、以下の記事を先に読むことをおすすめします!

Gemini 1.5 Flashとは
Gemini 1.5 Flashは、100 万トークンのコンテキスト ウィンドウが付属しており、テキスト、画像、オーディオ、ビデオの入力に対して応答可能なモデルです。
また、従来のモデルに比べて、応答速度が速く、特定のタスクや高頻度のタスクに最適化がされております。
料金
「Gemini 1.5 Flash」は、「Gemini 1.5 Pro」に比べ、10分の1の料金で利用可能です。
| 基盤モデル | インプット料金/100万トークン | アウトプット料金/100万トークン |
|---|---|---|
| Gemini 1.5 Flash | $0.35(最大128,000トークンまでのプロンプト) | $0.53(最大128,000トークンまでのプロンプト) |
| Gemini 1.5 Pro | $3.50(最大128,000トークンまでのプロンプト) | $10.50(最大128,000トークンまでのプロンプト) |
Priced to help you bring your app to the world
Gemini 1.5 Flashを使ってみた
Google Cloudコンソールから、 [Vertex AI] > [言語] の順で選択をします。
次に、[テキストプロンプト] を選択します。
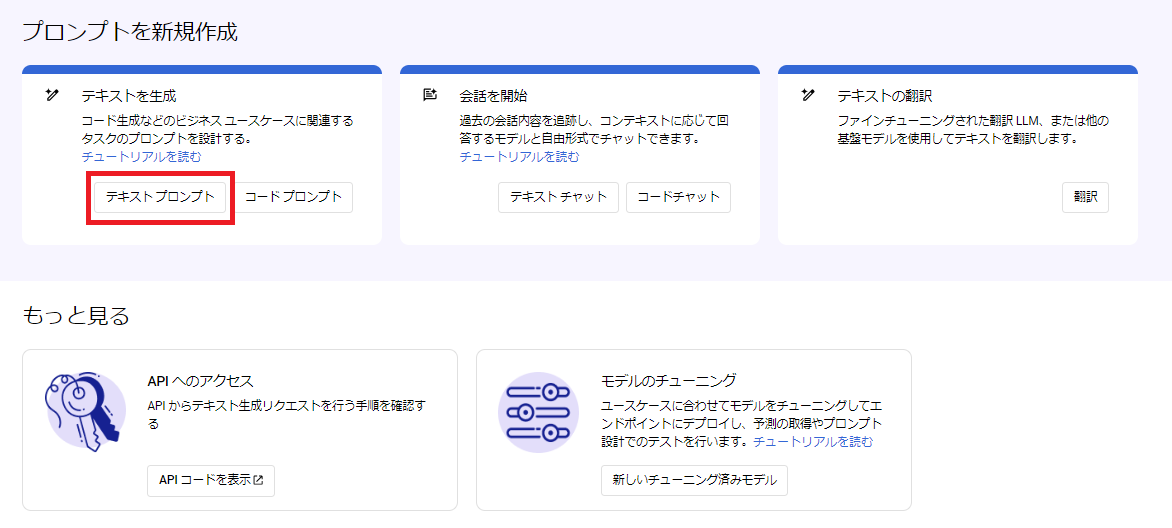
画面右側のモデル選択箇所から、[gemini-1.5-flash-preview-0514]を選択します。
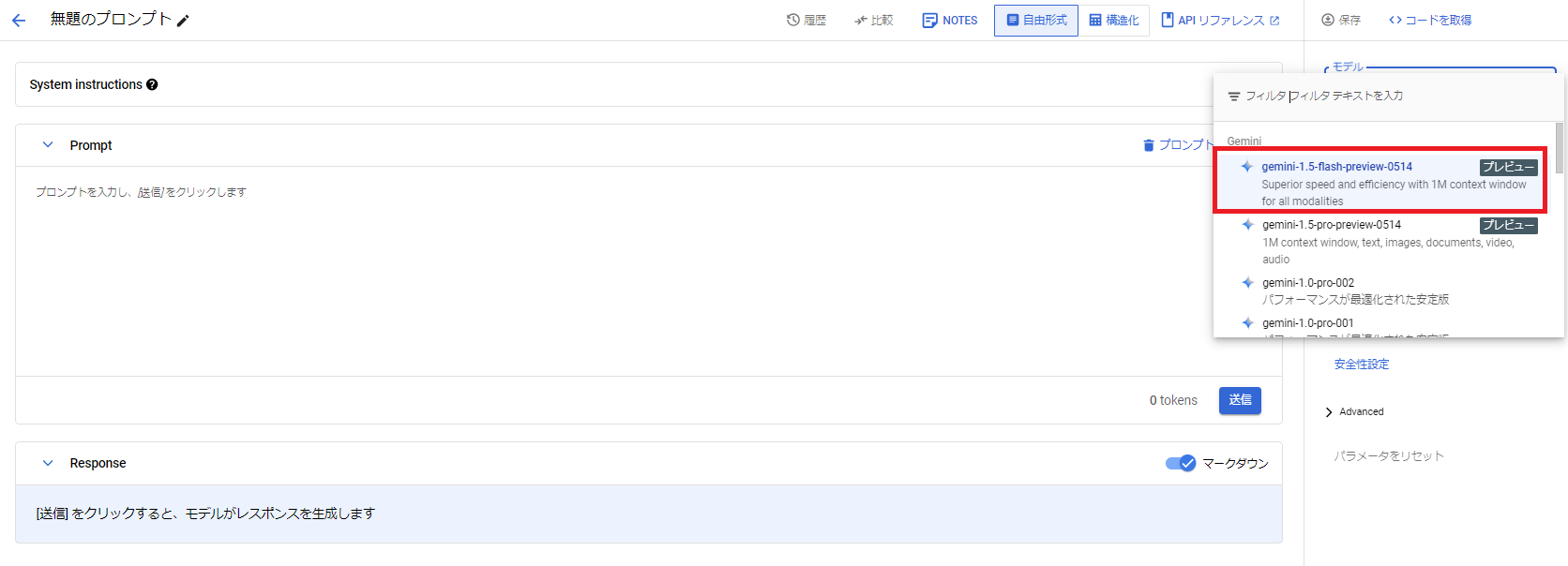
プロンプトへ以下を入力し、実行してみます。
Vertex AIについて教えてください。
出力結果は以下です。約5秒ほどで出力がされました。

次に、他のモデルとの比較をしてみます。
画面右上の[保存]を選択します。
保存が完了すると、[比較]を選択できるようになります。
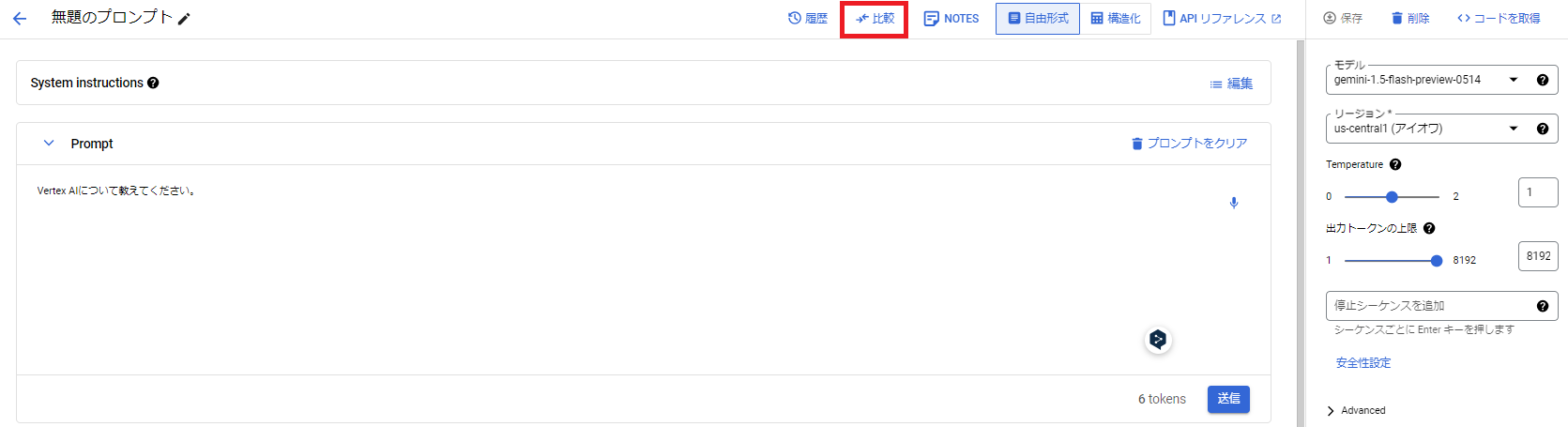
[比較を追加]から比較したい基盤モデルを追加します。
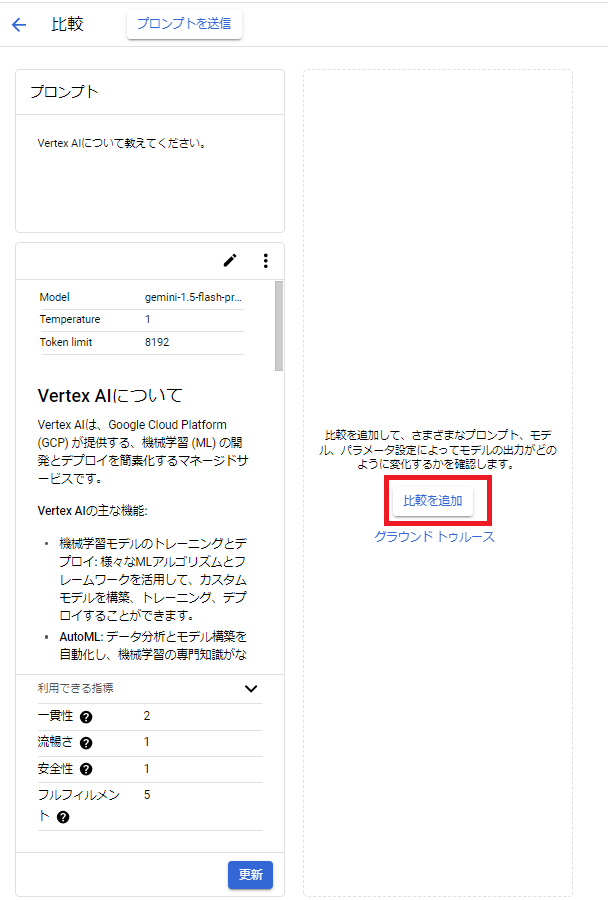
今回比較するのは、「Gemini 1.5 Flash」、「Gemini 1.5 Pro」、「Gemini 1.0 Pro」(左から順)とします。
基盤モデルの追加が完了すれば、[プロンプトを送信]をクリックします。
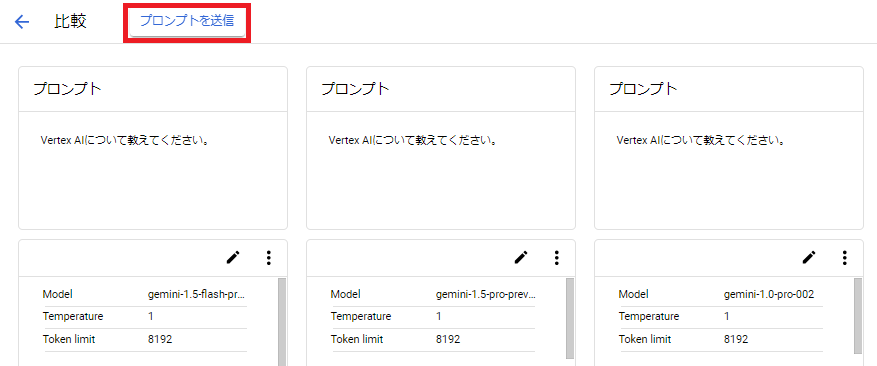
やはり、最新の軽量モデルなこともあり、「Gemini 1.5 Flash」の出力が一番早いです。
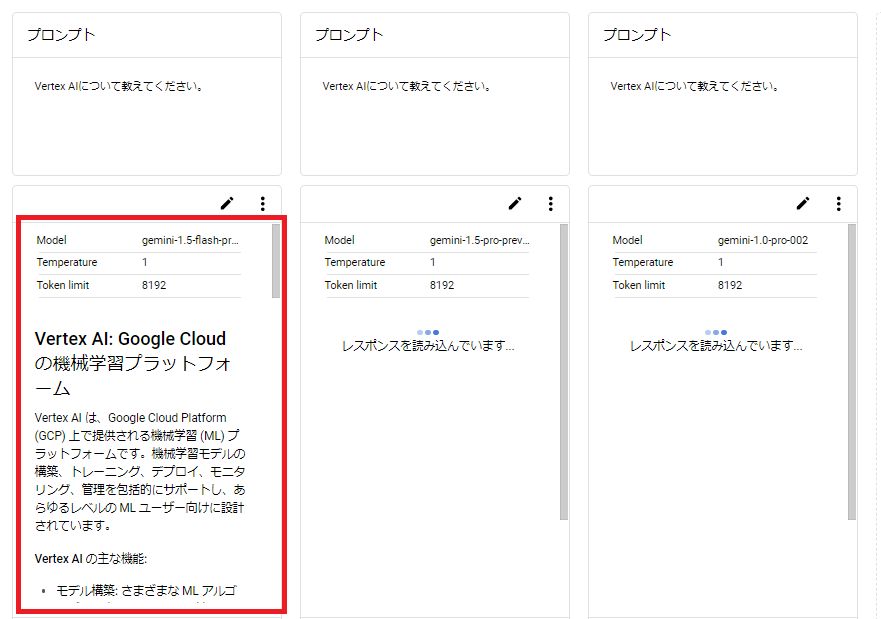
次に、「Gemini 1.0 Pro」の出力がされました。
そして最後に、「Gemini 1.5 Pro」の出力がされます。
各モデルの出力内容を確認しましたが、それほどの差はないように感じました。
[利用できる指標]からは、Google Cloudが定めた評価を確認することができます。
[流暢さ]は、最も出力に時間のかかっていた「Gemini 1.5 Pro」が最も高い数値となっていました。
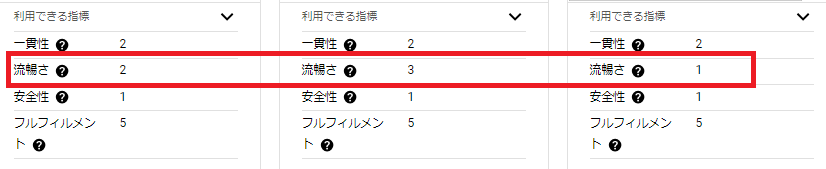
この比較機能は、実際に行いたいタスクを実行し、各モデルを評価するのに非常に便利な機能です。
さいごに
今回の記事では、新たにVertex AIで利用可能となった「Gemini 1.5 Flash」をご紹介しました!
「Gemini 1.5 Flash」の出力がかなり早かったことが印象的でした!
また、「Gemini 1.5 Pro」の1/10の料金で「Gemini 1.5 Flash」を利用できることも非常に魅力的です!
新しいモデルが出た際は、またご紹介出来ればと思います!
最後まで読んでいただきありがとうございます!

Google Cloud Partner Top Engineer 2025、2024 AWS All Cert、ビール検定1冠


Recommends
こちらもおすすめ




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16