【やってみた】Cloud SQL for MySQLとLangChainを活用した Retrieval Augmented Generation を使用して生成 AI アプリケーションを作成する方法を学ぶ
2024.8.9

本記事は、こちらで紹介されている内容をもとに解説を加えたものです。
概要
Cloud SQL for MySQLとLangChainを活用した Retrieval Augmented Generation を使用して、強力でインタラクティブな生成 AI アプリケーションを作成する方法を学びます。Netflix映画データセットに基づいたアプリケーションを作成し、新しいエキサイティングな方法で映画データを操作できるようにします。
前提条件
- Google Cloud Console の基本的な理解
- コマンドライン インターフェースと Google Cloud Shell の基本スキル
- Pythonの基礎知識
- ここでは、google Colaboratoryを使ってPython コードを作成します。
学ぶ内容
- Cloud SQL for MySQL インスタンスをデプロイする方法
- Cloud SQL for MySQL を DocumentLoader として使用する方法
- Cloud SQL for MySQL を VectorStore として使用する方法
- ChatMessageHistory ストレージに Cloud SQL for MySQL を使用する方法
セットアップと要件
- 依存関係をインストールする
- Colab 内で Google Cloud に認証する
- Google Cloud プロジェクトを接続する
- Google Cloud プロジェクトを構成する
- Cloud SQL を設定する
- MySQLインスタンスを作成する
- データベースにデータをインポートする
1. 依存関係をインストールする
%pip install --upgrade --quiet langchain-google-cloud-sql-mysql langchain-google-vertexai langchain
2. Colab 内で Google Cloud に認証する
このノートブックから Google Cloud プロジェクトにアクセスするには、IAM ユーザーとして認証する必要があります。
from google.colab import auth auth.authenticate_user()
3. Google Cloud プロジェクトを接続する
Colab 内から Google Cloud を活用できるように、Google Cloud プロジェクトをこのノートブックに接続します。
# @markdown Please fill in the value below with your GCP project ID and then run the cell.
# Please fill in these values.
PROJECT_ID = ""
# Quick input validations.
assert PROJECT_ID, "Please provide a Google Cloud project ID"
# Configure gcloud.
!gcloud config set project {PROJECT_ID}
4. Google Cloud プロジェクトを構成する
Google Cloud プロジェクトで以下を構成します。
1) Cloud SQL クライアントロールを持つ IAM プリンシパル (ユーザー、サービス アカウントなど) 。このノートブックにログインしているユーザーは IAM プリンシパルとして使用され、Cloud SQL クライアント ロールが付与されます。
current_user = !gcloud auth list --filter=status:ACTIVE --format="value(account)"
!gcloud projects add-iam-policy-binding {PROJECT_ID} \
--member=user:{current_user[0]} \
--role="roles/cloudsql.client"
2) プロジェクト内で Cloud SQL と Vertex AI の API を有効にします。
# Enable GCP services !gcloud services enable sqladmin.googleapis.com aiplatform.googleapis.com
5. Cloud SQL を設定する
このノートブックの次の段階では、MySQL Cloud SQL インスタンスが必要になります。
6. MySQLインスタンスを作成する
以下のセルを実行すると、Cloud SQL インスタンスの存在が確認され、存在しない場合は新しいインスタンスが作成されます。という名前のデータベースlangchain_dbが作成され、クイックスタートの残りの部分で使用されます。
注意: MySQL ベクトル サポートは、バージョン8.0.36 以降の MySQL インスタンスでのみ利用できます。
既存のインスタンスの場合、セルフサービス メンテナンス アップデートを実行して、メンテナンス バージョンをMYSQL_8_0_36.R20240401.03_00以上に更新する必要がある場合があります。更新したら、データベース フラグを構成して、新しいcloudsql_vectorフラグを「オン」にします。
⏳ – Cloud SQL インスタンスの作成には数分かかる場合があります。
# Please fill in these values.
REGION = "us-central1" #@param {type:"string"}
INSTANCE_NAME = "langchain-quickstart-instance" #@param {type:"string"}
DATABASE_NAME = "langchain_db"
PASSWORD = input("Please provide a password to be used for 'root' database user: ")
# Quick input validations.
assert REGION,
assert INSTANCE_NAME,
assert DATABASE_NAME,
# check if Cloud SQL instance exists in the provided region
database_version = !gcloud sql instances describe {INSTANCE_NAME} --format="value(databaseVersion)"
if database_version[0].startswith("MYSQL"):
print("Found existing MySQL Cloud SQL Instance!")
else:
print("Creating new Cloud SQL instance...")
!gcloud sql instances create {INSTANCE_NAME} --database-version=MYSQL_8_0_36 \
--region={REGION} --cpu=1 --memory=4GB --root-password={PASSWORD} \
--database-flags=cloudsql_iam_authentication=On,cloudsql_vector=On
databases = !gcloud sql databases list --instance={INSTANCE_NAME} --format="value(name)"
if DATABASE_NAME not in databases:
print("Creating 'langchain_db' database for the quickstart...")
!gcloud sql databases create {DATABASE_NAME} --instance={INSTANCE_NAME}
google cloudコンソールにログインし、Cloud SQL for MySQL インスタンスを作成する方法もあります。
【インスタンスを作成】クリック
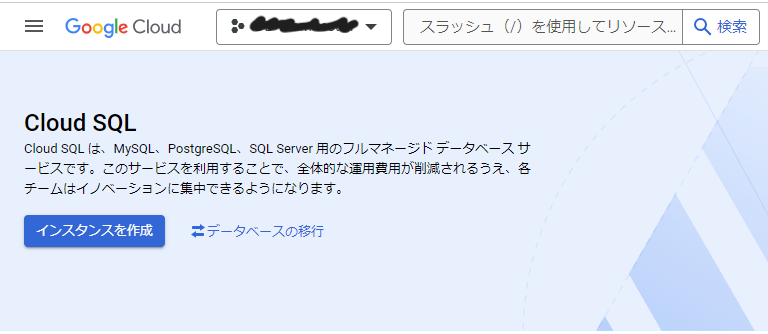
【MySQLを選択】クリック
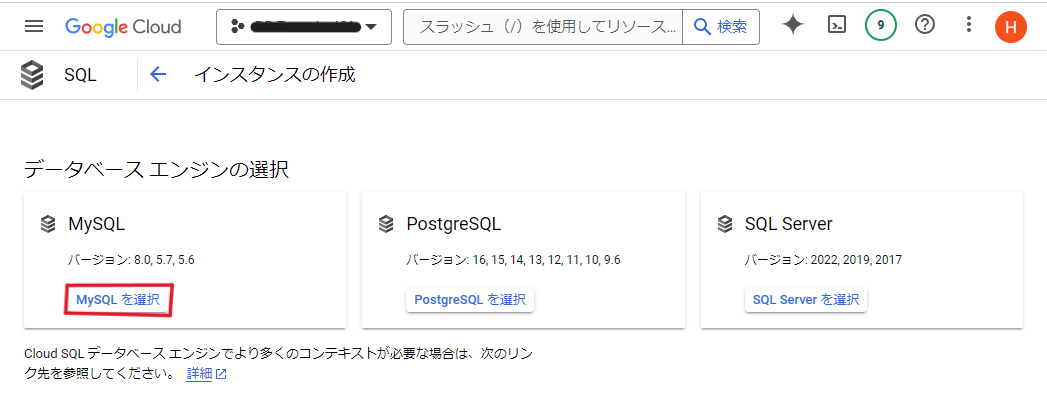
【APIを有効にする】クリック

【Enterprise】選択

【サンドボックス】【MySQL 8.0】【MySQL 8.0.36】選択(MySQL ベクトル サポートは、バージョン8.0.36 以降の MySQL インスタンスでのみ利用できます。)
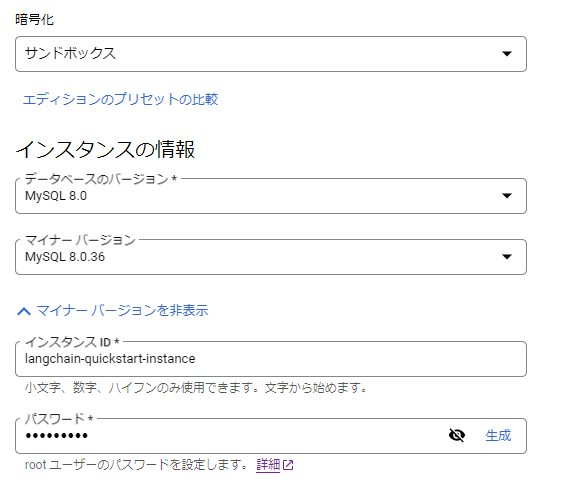
【シングルゾーン】選択
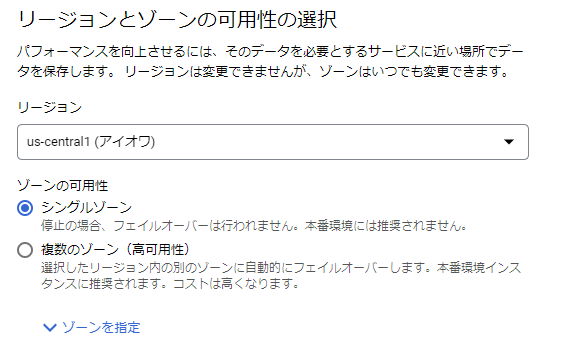
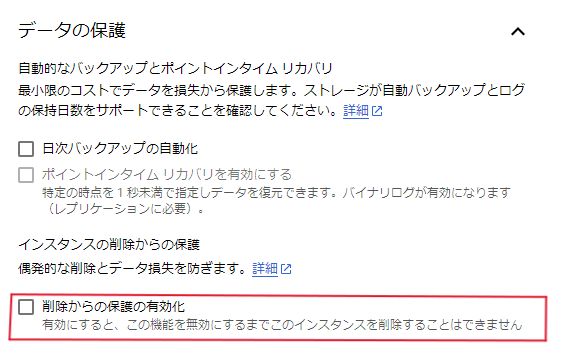
【削除からの保護の有効化】チェックしない
【インスタンスを作成】クリック

【料金の見積もり】の結果表示

【インスタンス】の作成の確認

【データベース】の作成
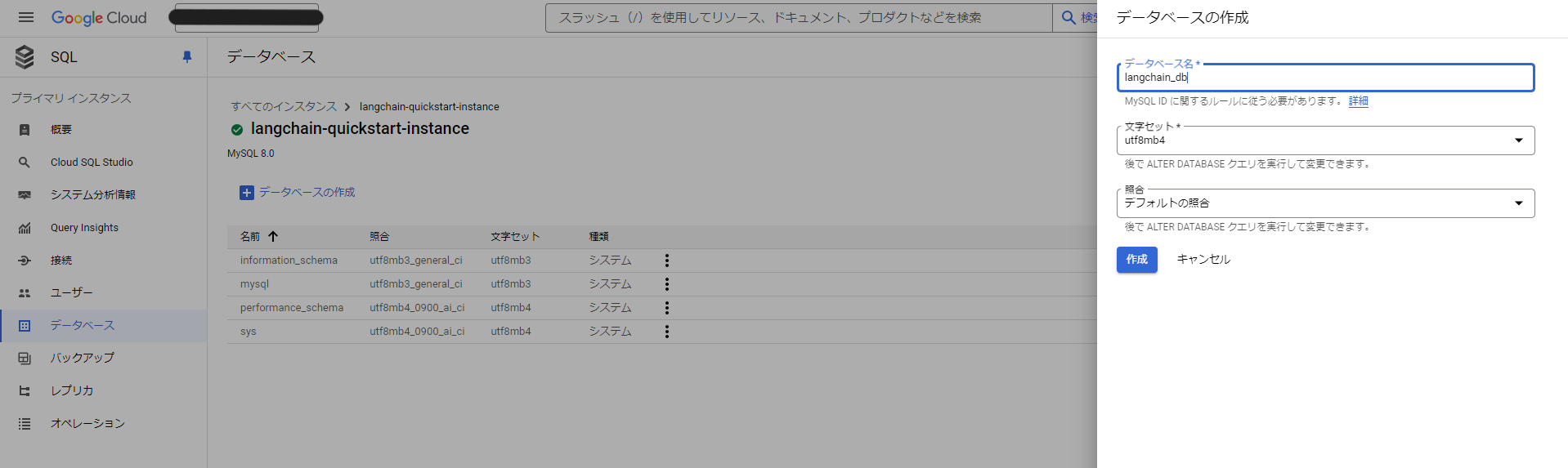
【データベース】の作成の確認
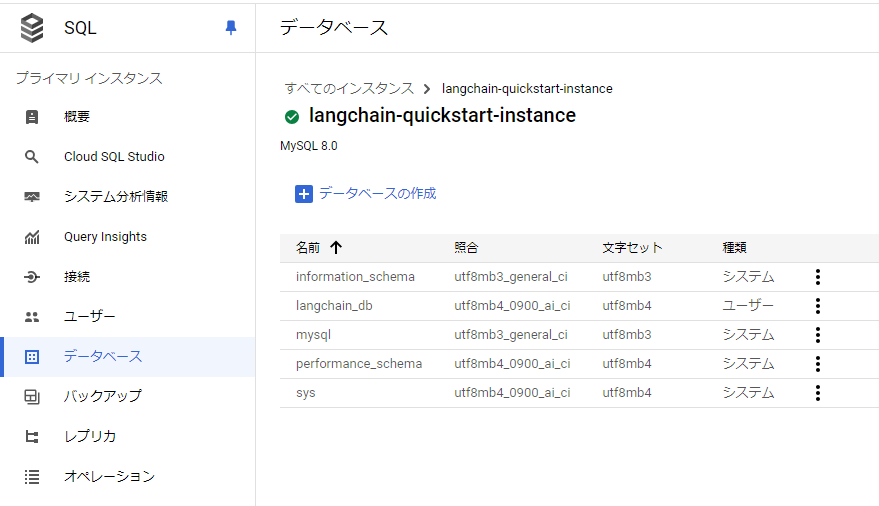
【フラグ】の選択(cloudsql_iam_authentication、cloudsql_vectorのオン)
7. データベースにデータをインポートする
データベースができたので、データをインポートする必要があります。Kaggleの Netflix Datasetを使用します。データは次のようになります。
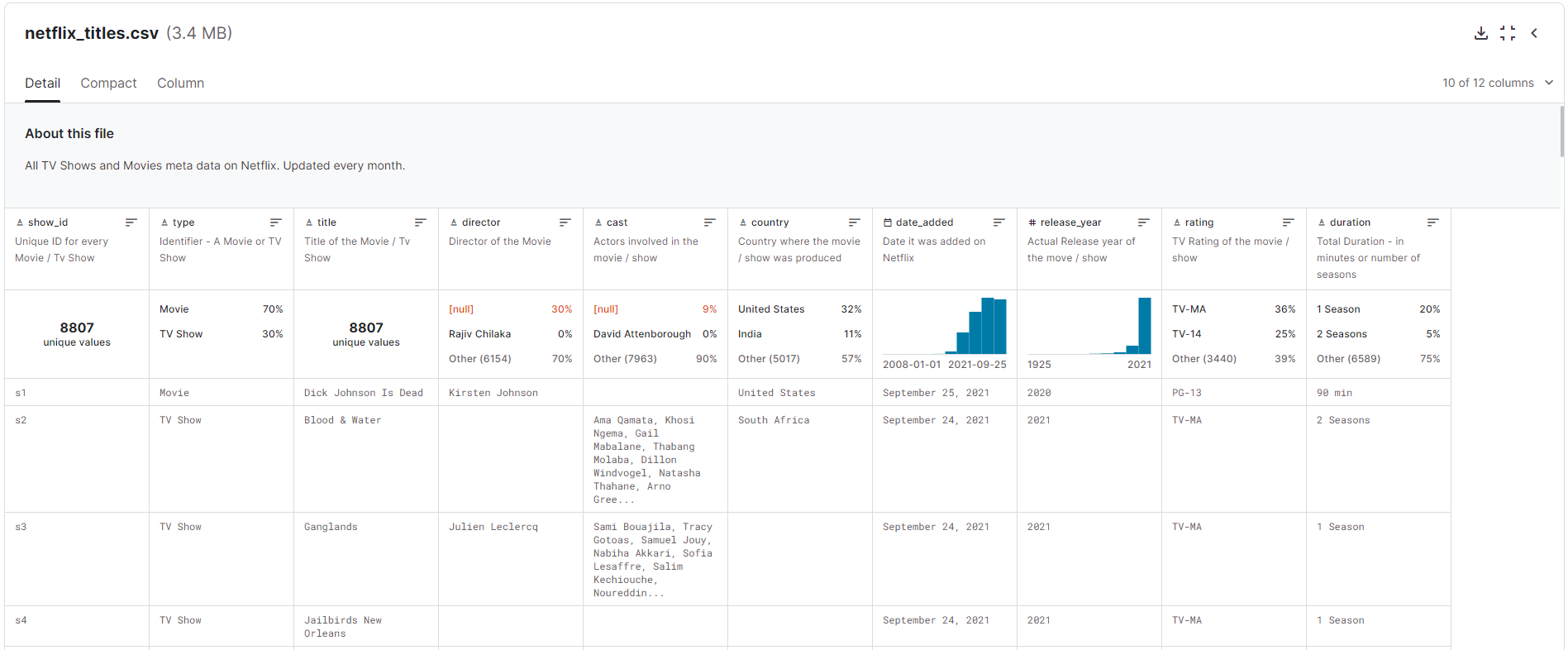
CSV データをデータベースに直接ロードする必要はありません。代わりに、MySQL 用の.sqlファイル形式のテーブル「netflix_titles」を用意しました。1 つのgcloudコマンドを使用すると、簡単にテーブルをデータベースにインポートできます。
# Import the Netflix titles table using gcloud command
import_command_output = !gcloud sql import sql {INSTANCE_NAME} gs://[CSVデータを配置したCloud Storageのパスを記載]/netflix_titles.sql --database={DATABASE_NAME} --quiet
if "Imported data" in str(import_command_output):
print(import_command_output)
elif "already exists" in str(import_command_output):
print("Did not import because the table already existed.")
else:
raise Exception(f"The import seems to have failed:\n{import_command_output}")
cloud shellを接続してimportされたが確認します。
$ gcloud sql connect langchain-quickstart-instance --user=root
mysql> show create table langchain_db.netflix_titles \G *************************** 1. row *************************** Table: netflix_titles Create Table: CREATE TABLE `netflix_titles` ( `show_id` varchar(50) NOT NULL, `type` varchar(50) DEFAULT NULL, `title` varchar(50) DEFAULT NULL, `director` varchar(50) DEFAULT NULL, `cast` text, `country` varchar(50) DEFAULT NULL, `date_added` varchar(50) DEFAULT NULL, `release_year` int DEFAULT NULL, `rating` varchar(50) DEFAULT NULL, `duration` varchar(50) DEFAULT NULL, `listed_in` varchar(50) DEFAULT NULL, `description` text ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 1 row in set (0.16 sec) mysql> select count(*) from langchain_db.netflix_titles; +----------+ | count(*) | +----------+ | 8807 | +----------+ 1 row in set (0.16 sec)
ユースケース 1: Document Loaderとしての Cloud SQL for MySQL
データベースにデータがあるので、MySQL用のCloud SQLをドキュメントローダとして使用する準備ができました。 これは、データベースからデータを取り出し、ドキュメントとしてメモリにロードすることを意味します。 その後、これらの文書をベクトルストアに送ることができます。
次に、langchain-google-cloud-sql-mysql パッケージから MySQL Engine クラスを使用して Cloud SQL MySQL インスタンスに接続します。
from langchain_google_cloud_sql_mysql import MySQLEngine
mysql_engine = MySQLEngine.from_instance(
project_id=PROJECT_ID,
instance=INSTANCE_NAME,
region=REGION,
database=DATABASE_NAME,
user="root",
password=PASSWORD,
)
MySQL Engine オブジェクトを初期化すると、それを MySQL Loader に渡して特定のデータベースに接続できます。 ご覧のように、クエリ、table_name、カラムのリストも渡します。 クエリーは、データをプルするために使用するクエリーをローダーに伝えます。 「content_columns」引数は、構築するドキュメントオブジェクトで 「content」 として使用されるカラムを指します。 そのテーブル内の残りの列は、ドキュメントに関連付けられた「metadata」になります。
from langchain_google_cloud_sql_mysql import MySQLLoader
table_name = "netflix_titles"
content_columns = ["title", "director", "cast", "description"]
loader = MySQLLoader(
engine=mysql_engine,
query=f"SELECT * FROM `{table_name}`;",
content_columns=content_columns,
)
次に、ドキュメント ローダーを使用してデータベースからドキュメントをロードします。ここで、データベースの最初の 5 つのドキュメントを確認できます。これで、Cloud SQL for MySQL を LangChain ドキュメント ローダーとして使用できました。
documents = loader.load()
print(f"Loaded {len(documents)} documents from the database. \n5 Examples:")
for doc in documents[:5]:
print(doc)
上記の回答です!
Loaded 8807 documents from the database.
5 Examples:
page_content='Dick Johnson Is Dead Kirsten Johnson As her father nears the end of his life, filmmaker Kirsten Johnson stages his death in inventive and comical ways to help them both face the inevitable.' metadata={'show_id': 's1', 'type': 'Movie', 'country': 'United States', 'date_added': 'September 25, 2021', 'release_year': 2020, 'rating': 'PG-13', 'duration': '90 min', 'listed_in': 'Documentaries'}
page_content='Blood & Water Ama Qamata, Khosi Ngema, Gail Mabalane, Thabang Molaba, Dillon Windvogel, Natasha Thahane, Arno Greeff, Xolile Tshabalala, Getmore Sithole, Cindy Mahlangu, Ryle De Morny, Greteli Fincham, Sello Maake Ka-Ncube, Odwa Gwanya, Mekaila Mathys, Sandi Schultz, Duane Williams, Shamilla Miller, Patrick Mofokeng After crossing paths at a party, a Cape Town teen sets out to prove whether a private-school swimming star is her sister who was abducted at birth.' metadata={'show_id': 's2', 'type': 'TV Show', 'country': 'South Africa', 'date_added': 'September 24, 2021', 'release_year': 2021, 'rating': 'TV-MA', 'duration': '2 Seasons', 'listed_in': 'International TV Shows, TV Dramas, TV Mysteries'}
page_content='Ganglands Julien Leclercq Sami Bouajila, Tracy Gotoas, Samuel Jouy, Nabiha Akkari, Sofia Lesaffre, Salim Kechiouche, Noureddine Farihi, Geert Van Rampelberg, Bakary Diombera To protect his family from a powerful drug lord, skilled thief Mehdi and his expert team of robbers are pulled into a violent and deadly turf war.' metadata={'show_id': 's3', 'type': 'TV Show', 'country': '', 'date_added': 'September 24, 2021', 'release_year': 2021, 'rating': 'TV-MA', 'duration': '1 Season', 'listed_in': 'Crime TV Shows, International TV Shows, TV Action '}
page_content='Jailbirds New Orleans Feuds, flirtations and toilet talk go down among the incarcerated women at the Orleans Justice Center in New Orleans on this gritty reality series.' metadata={'show_id': 's4', 'type': 'TV Show', 'country': '', 'date_added': 'September 24, 2021', 'release_year': 2021, 'rating': 'TV-MA', 'duration': '1 Season', 'listed_in': 'Docuseries, Reality TV'}
page_content='Kota Factory Mayur More, Jitendra Kumar, Ranjan Raj, Alam Khan, Ahsaas Channa, Revathi Pillai, Urvi Singh, Arun Kumar In a city of coaching centers known to train India’s finest collegiate minds, an earnest but unexceptional student and his friends navigate campus life.' metadata={'show_id': 's5', 'type': 'TV Show', 'country': 'India', 'date_added': 'September 24, 2021', 'release_year': 2021, 'rating': 'TV-MA', 'duration': '2 Seasons', 'listed_in': 'International TV Shows, Romantic TV Shows, TV Come'}

ユースケース 2: Vector Storeとしての Cloud SQL for MySQL
ここで、ベクトル検索を使用してユーザーの質問に答えることができるように、ロードしたすべてのドキュメントをベクトル ストアに配置する方法を学びましょう。
ベクトルストアテーブルを作成する
前にロードしたドキュメントに基づいて、ベクトル ストアとしてベクトル列を持つテーブルを作成します。engineからinit_vectorstore_table関数を呼び出してベクトル テーブルを初期化することから始めます。ご覧のとおり、メタデータのすべての列をリストします。また、埋め込みサービスが使用するモデルである Vertex AI の textembedding-gecko によって計算されたベクトルの長さに対応するベクトル サイズ 768 を指定します。
from langchain_google_cloud_sql_mysql import Column
vector_table_name = "vector_netflix_titles"
mysql_engine.init_vectorstore_table(
table_name=vector_table_name,
vector_size=768,
metadata_columns=[
Column("show_id", "VARCHAR(50)", nullable=True),
Column("type", "VARCHAR(50)", nullable=True),
Column("country", "VARCHAR(50)", nullable=True),
Column("date_added", "VARCHAR(50)", nullable=True),
Column("release_year", "INTEGER", nullable=True),
Column("rating", "VARCHAR(50)", nullable=True),
Column("duration", "VARCHAR(50)", nullable=True),
Column("listed_in", "VARCHAR(50)", nullable=True),
],
overwrite_existing=True, # Enabling this will recreate the table if exists.
)
ベクトルストアテーブルを作成になりました。
mysql> show create table vector_netflix_titles \G *************************** 1. row *************************** Table: vector_netflix_titles Create Table: CREATE TABLE `vector_netflix_titles` ( `langchain_id` char(36) NOT NULL, `content` text NOT NULL, `embedding` varbinary(3072) NOT NULL COMMENT 'GCP MySQL Vector Column V1, dimension=768', `show_id` varchar(50) DEFAULT NULL, `type` varchar(50) DEFAULT NULL, `country` varchar(50) DEFAULT NULL, `date_added` varchar(50) DEFAULT NULL, `release_year` int DEFAULT NULL, `rating` varchar(50) DEFAULT NULL, `duration` varchar(50) DEFAULT NULL, `listed_in` varchar(50) DEFAULT NULL, `langchain_metadata` json DEFAULT NULL, PRIMARY KEY (`langchain_id`), CONSTRAINT `vector_dimensions_chk_1722414527415686000` CHECK (((`embedding` is null) or (length(`embedding`) <=> 3072))) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.17 sec)
ドキュメントをベクトルテーブルに挿入してみてください
ここで、Cloud SQL データベースのベクトル テーブルを基にした vector_store オブジェクトを作成します。ドキュメントからベクトル テーブルにデータを読み込みます。各行について、埋め込みサービスが呼び出され、ベクトル テーブルに保存する埋め込みが計算されることに注意してください。
価格の詳細はこちらをご覧ください。
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_cloud_sql_mysql import MySQLVectorStore
# Initialize the embedding service. In this case we are using version 003 of Vertex AI's textembedding-gecko model.
# In general, it is good practice to specify the model version used.
embeddings_service = VertexAIEmbeddings(
model_name="textembedding-gecko@003", project=[プロジェクトID]
)
vector_store = MySQLVectorStore(
engine=mysql_engine,
embedding_service=embeddings_service,
table_name=vector_table_name,
metadata_columns=[
"show_id",
"type",
"country",
"date_added",
"release_year",
"duration",
"listed_in",
],
)
次に、ドキュメント データをベクトル テーブルに格納してみましょう。リストの最初の 5 つのドキュメントをロードするコード例を次に示します。
import uuid docs_to_load = documents[:5] # ! Uncomment the following line to load all 8,800+ documents to the database vector table with calling the embedding service. # docs_to_load = documents ids = [str(uuid.uuid4()) for i in range(len(docs_to_load))] vector_store.add_documents(docs_to_load, ids)
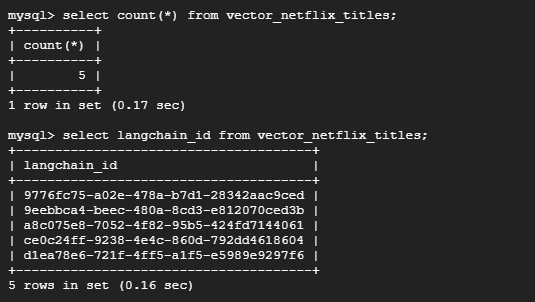
MySQL接続して実際テーブルにデータが挿入されたか確認してみました。
残りのデータをベクトルテーブルにインポートします
デモ用のすべてのドキュメントをロードするために、埋め込みサービスに 8,800 回呼び出す必要はありません。 代わりに、.sqlファイルにあらかじめ計算された埋め込みを含む8,800行以上のテーブルを用意しました。 もう一度、gcloudコマンドを使ってDBにインポートしましょう。
.sqlファイルは、vector_netflix_titlesというベクトルを持つテーブルに復元されます。
# Import the netflix titles with vector table using gcloud command
import_command_output = !gcloud sql import sql {INSTANCE_NAME} gs://[CSVデータを配置したCloud Storageのパスを記載]/netflix_titles.sql --database={DATABASE_NAME} --quiet
if "Imported data" in str(import_command_output):
print(import_command_output)
elif "already exists" in str(import_command_output):
print("Did not import because the table already existed.")
else:
raise Exception(f"The import seems failed:\n{import_command_output}")
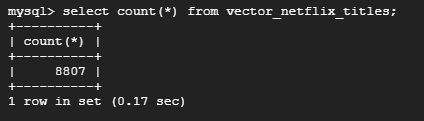
MySQL接続して「vector_netflix_titles」テーブルのカウンターを確認してみました。
ユースケース 3: Chat Memoryとしての Cloud SQL for MySQL
チャット履歴(LangChain のコンテキストで「メモリ」と呼ばれる)をアプリケーションに追加します。これにより、LLM は複数の対話を通じてコンテキストと情報を保持できるようになり、より一貫性のある高度な会話やテキスト生成につながります。 Cloud SQL for MySQL をアプリケーションの「メモリ」ストレージとして使用することで、LLM は以前の会話のコンテキストを使用して、ユーザのプロンプトによりよく応答できるようになります。 まず、MySQL用のCloud SQLをメモリストレージとして初期化しましょう。
from langchain_google_cloud_sql_mysql import MySQLChatMessageHistory
message_table_name = "message_store"
mysql_engine.init_chat_history_table(table_name=message_table_name)
chat_history = MySQLChatMessageHistory(
mysql_engine,
session_id="my-test-session",
table_name=message_table_name,
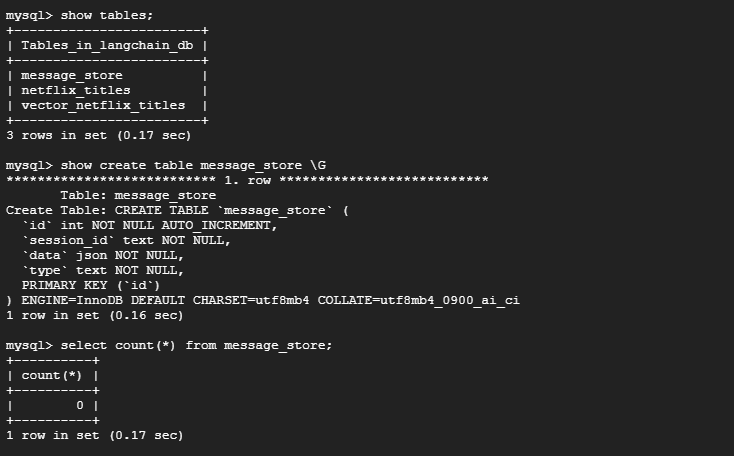
MySQL接続して「message_store」が作成されたか確認してみました。
ここでは、ユーザ メッセージを追加する方法と、ai メッセージを追加する方法の例を示します。
chat_history.add_user_message("Hi!")
chat_history.add_ai_message("Hello there. I'm a model and am happy to help!")
chat_history.messages
上記の回答です!
[HumanMessage(content='Hi!'), AIMessage(content="Hello there. I'm a model and am happy to help!")]

Cloud SQL for MySQL を基盤とする会話型 RAG チェーン
これまで、Document Loader、Vector Store、Chat Memoryとして Cloud SQL for MySQL を使用してテストしてきました。それでは、これらをすべてConversationalRetrievalChainにまとめましょう。
ベクトル検索結果に基づいて映画関連の質問に答えることができるチャットボットを構築します。
まず、ベクトル ストアと chat_history での接続として使用するために、すべての MySQL エンジン オブジェクトを初期化します。
from langchain_google_vertexai import VertexAIEmbeddings, VertexAI
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain_core.prompts import PromptTemplate
from langchain_google_cloud_sql_mysql import (
MySQLChatMessageHistory,
MySQLEngine,
MySQLVectorStore,
)
# Initialize the embedding service
embeddings_service = VertexAIEmbeddings(
model_name="textembedding-gecko@latest", project=[プロジェクトID]
)
# Initialize the engine
mysql_engine = MySQLEngine.from_instance(
project_id=PROJECT_ID,
instance=INSTANCE_NAME,
region=REGION,
database=DATABASE_NAME,
user="root",
password=PASSWORD,
)
# Initialize the Vector Store
vector_table_name = "vector_netflix_titles"
vector_store = MySQLVectorStore(
engine=mysql_engine,
embedding_service=embeddings_service,
table_name=vector_table_name,
metadata_columns=[
"show_id",
"type",
"country",
"date_added",
"release_year",
"duration",
"listed_in",
],
)
# Initialize the MySQLChatMessageHistory
chat_history = MySQLChatMessageHistory(
mysql_engine,
session_id="my-test-session",
table_name="message_store",
)
LLM のプロンプトを作成しました。テンプレート適用が可能です。アプリケーションに固有の指示追加できます。
# Prepare some prompt templates for the ConversationalRetrievalChain
prompt = PromptTemplate(
template="""Use all the information from the context and the conversation history to answer new question. If you see the answer in previous conversation history or the context. \
Answer it with clarifying the source information. If you don't see it in the context or the chat history, just say you \
didn't find the answer in the given data. Don't make things up.
Previous conversation history from the questioner. "Human" was the user who's asking the new question. "Assistant" was you as the assistant:
```{chat_history}
```
Vector search result of the new question:
```{context}
```
New Question:
```{question}```
Answer:""",
input_variables=["context", "question", "chat_history"],
)
condense_question_prompt_passthrough = PromptTemplate(
template="""Repeat the following question:
{question}
""",
input_variables=["question"],
)
それでは、ベクトル ストアをレトリバーとして使用してみましょう。 ラングチェーンのレトリバーを使用すると、文字通り文書を”検索”することができます。
# Initialize retriever, llm and memory for the chain
retriever = vector_store.as_retriever(
search_type="mmr", search_kwargs={"k": 5, "lambda_mult": 0.8}
)
それでは、LLM を初期化しましょう。この場合は、Vertex AI の「gemini-pro」を使用します。
llm = VertexAI(model_name="gemini-pro", project=[プロジェクトID])
チャット履歴をクリアすることにより、アプリケーションに関する他の会話の前のコンテキストなしでアプリケーションが起動します。
chat_history.clear()
memory = ConversationSummaryBufferMemory(
llm=llm,
chat_memory=chat_history,
output_key="answer",
memory_key="chat_history",
return_messages=True,
)
それでは会話型の検索チェーンを作ってみましょう。 これにより、LLM はチャット履歴をその応答に使用することができます。つまり、問い合わせのたびに最初から始めるのではなく、質問へのフォローアップ質問を行うことができます。
# create the ConversationalRetrievalChain
rag_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
verbose=False,
memory=memory,
condense_question_prompt=condense_question_prompt_passthrough,
combine_docs_chain_kwargs={"prompt": prompt},
)
# ask some questions
q = "What movie was Brad Pitt in?"
ans = rag_chain({"question": q, "chat_history": chat_history})["answer"]
print(f"Question: {q}\nAnswer: {ans}\n")
q = "How about Johnny Depp?"
ans = rag_chain({"question": q, "chat_history": chat_history})["answer"]
print(f"Question: {q}\nAnswer: {ans}\n")
q = "Are there movies about animals?"
ans = rag_chain({"question": q, "chat_history": chat_history})["answer"]
print(f"Question: {q}\nAnswer: {ans}\n")
# browser the chat history
chat_history.messages
上記の回答です!
Question: What movie was Brad Pitt in? Answer: Brad Pitt has been in many movies, but the movies you are referencing here include: * Inglourious Basterds (2009) * By the Sea (2015) * Killing Them Softly (2012) * Babel (2006) * War Machine (2017) Do you have any additional information about the movie you are looking for? Question: How about Johnny Depp? Answer: Here are some of the movies that Johnny Depp has been in: * **The Rum Diary (2011)**: This is an adaptation of Hunter S. Thompson's novel about a journalist who moves to Puerto Rico and falls for a taken woman. * **Charlie and the Chocolate Factory (2005)**: This is a remake of the 1971 film of the same name, about an eccentric candy maker who opens the doors of his factory to five lucky kids. * **The Tourist (2010)**: This is a thriller about an American tourist who gets caught up in a dangerous situation in Italy. * **The Imaginarium of Doctor Parnassus (2009)**: This is a fantasy film about a traveling theater troupe that is led by a mysterious doctor. * **What's Eating Gilbert Grape (1993)**: This is a drama about a young man who is taking care of his mentally disabled brother. I hope this information is helpful. Let me know if you have any other questions. Question: Are there movies about animals? Answer: It appears you're interested in movies about animals. Based on the information you've provided, I can recommend a few options: * **If you're interested in animated films:** * **Penguins of Madagascar: The Movie (2014):** This hilarious film follows the adventures of Skipper, Kowalski, Rico, and Private, the four penguins from the "Madagascar" franchise. They join forces with a secret organization of penguins to stop an evil octopus from taking over the world. * **The Lion King (1994):** This Disney classic tells the story of Simba, a young lion cub who must overcome tragedy and find his place in the world. It's a heartwarming and visually stunning film that's sure to appeal to all ages. * **Finding Nemo (2003):** This Pixar film follows Marlin, a clownfish who sets out on a journey to find his son Nemo, who has been taken from their home. It's a funny and touching story about the power of family and the importance of never giving up. * **If you're interested in live-action films:** * **March of the Penguins (2005):** This documentary follows the annual migration of emperor penguins in Antarctica. It's a beautiful and heartwarming film that shows the incredible journey these animals take to survive. * **Babe (1995):** This heartwarming film tells the story of Babe, a pig who wants to be a sheepdog. It's a funny and touching film about following your dreams and finding your place in the world. * **If I Were an Animal (2023):** This documentary explores the lives of various animals from around the world, showing their different behaviors and adaptations. It's a fascinating and educational film that will teach you about the amazing diversity of the animal kingdom. These are just a few examples of the many great animal films that are available. I hope this helps you find the perfect film to watch! [HumanMessage(content='What movie was Brad Pitt in?'), AIMessage(content='Brad Pitt has been in many movies, but the movies you are referencing here include:\n\n* Inglourious Basterds (2009)\n* By the Sea (2015)\n* Killing Them Softly (2012)\n* Babel (2006)\n* War Machine (2017)\n\nDo you have any additional information about the movie you are looking for?'), HumanMessage(content='How about Johnny Depp?'), AIMessage(content="Here are some of the movies that Johnny Depp has been in:\n\n* **The Rum Diary (2011)**: This is an adaptation of Hunter S. Thompson's novel about a journalist who moves to Puerto Rico and falls for a taken woman.\n* **Charlie and the Chocolate Factory (2005)**: This is a remake of the 1971 film of the same name, about an eccentric candy maker who opens the doors of his factory to five lucky kids.\n* **The Tourist (2010)**: This is a thriller about an American tourist who gets caught up in a dangerous situation in Italy.\n* **The Imaginarium of Doctor Parnassus (2009)**: This is a fantasy film about a traveling theater troupe that is led by a mysterious doctor.\n* **What's Eating Gilbert Grape (1993)**: This is a drama about a young man who is taking care of his mentally disabled brother.\n\nI hope this information is helpful. Let me know if you have any other questions."), HumanMessage(content='Are there movies about animals?'), AIMessage(content='It appears you\'re interested in movies about animals. Based on the information you\'ve provided, I can recommend a few options:\n\n* **If you\'re interested in animated films:**\n * **Penguins of Madagascar: The Movie (2014):** This hilarious film follows the adventures of Skipper, Kowalski, Rico, and Private, the four penguins from the "Madagascar" franchise. They join forces with a secret organization of penguins to stop an evil octopus from taking over the world.\n * **The Lion King (1994):** This Disney classic tells the story of Simba, a young lion cub who must overcome tragedy and find his place in the world. It\'s a heartwarming and visually stunning film that\'s sure to appeal to all ages.\n * **Finding Nemo (2003):** This Pixar film follows Marlin, a clownfish who sets out on a journey to find his son Nemo, who has been taken from their home. It\'s a funny and touching story about the power of family and the importance of never giving up.\n* **If you\'re interested in live-action films:**\n * **March of the Penguins (2005):** This documentary follows the annual migration of emperor penguins in Antarctica. It\'s a beautiful and heartwarming film that shows the incredible journey these animals take to survive.\n * **Babe (1995):** This heartwarming film tells the story of Babe, a pig who wants to be a sheepdog. It\'s a funny and touching film about following your dreams and finding your place in the world.\n * **If I Were an Animal (2023):** This documentary explores the lives of various animals from around the world, showing their different behaviors and adaptations. It\'s a fascinating and educational film that will teach you about the amazing diversity of the animal kingdom.\n\nThese are just a few examples of the many great animal films that are available. I hope this helps you find the perfect film to watch!')]
韓国語、日本語も試してみました!


まとめ
最近になって、さまざまなウェブサイトでチャットボットを活用する事例が急増しています。 過去にはインターネット銀行や顧客センターとの疎通が主に電話やEメールを通じて行われたとすれば、今はチャットボットを通じてより速く便利に疎通できる時代が到来しました。
特にGoogle CloudのVertex AIやGeminiのようなツールは、誰でも簡単にチャットボットを構築できるようにサポートし、これによってより精巧なユーザー体験を提供することができます。 このような技術的進歩は、企業が顧客サービスの質を向上させ、運用効率を最大化する機会を提供します。
例えば、Comicoのようなウェブトゥーンプラットフォームでは、チャットボットを活用して顧客に即時回答を提供したり、ユーザーの好みに合ったコンテンツを推薦することができます。 これらの機能を導入することで、お客様の満足度を高め、ユーザーエクスペリエンスを大幅に改善できるはずです。
同様にPlayartのようなゲームプラットフォームでもチャットボットを活用してゲーム推薦、アカウント管理、最新アップデート案内など多様なサービスを提供することで顧客との疎通を一層強化することができるでしょう。
このようにチャットボット技術の導入は、単に便利さを超えて、企業の競争力を高め、顧客との関係をより緊密につなぐ重要なツールとなっています。 今後もこのような技術を活用した革新的な顧客サービスが期待されます。

日本のビールが大好き、韓国出身です。
現、データエンジニアとして活躍してます。
クラウドエンジニアになるために頑張っているところです!
Google Cloud11冠


Recommends
こちらもおすすめ
-

Gemini Enterprise のプランと料金を解説!!
2025.8.28


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16