BigQueryのARRAYとSTRUCTの違いと使い分けをマスターしよう
2024.7.31

概要
BigQueryは、膨大なデータを効率的に処理するための強力なツールですが、ARRAYとSTRUCTという2つのデータ型を適切に使い分けることで、その力を最大限に引き出すことができます。今回は、この2つのデータ型の違いを詳しく解説し、それぞれの特性や用途、さらにUNNESTを使った詳細な使用方法についてご紹介します。
BigQueryのARRAYとは?
ARRAYは、同じデータ型の複数の値を格納できるコレクションです。以下に、ARRAYの基本的な特性と用途を説明します。
特性
- 同じデータ型の要素を格納
ARRAYは、同じデータ型(INTEGER、STRINGなど)の複数の値を1つのフィールドに格納します。 -
インデックスによるアクセス
配列の要素には、インデックス(1から始まる)を使用してアクセスします。
用途
同じ種類のデータをまとめて扱う場合に便利です。例えば、複数の電話番号、タグ、スコアなどを1つのフィールドに格納できます。
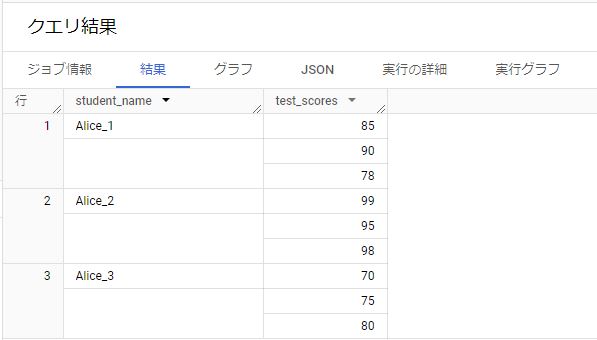
例1) ARRAY [Array]
学生のテストスコアをARRAYとして格納する例です。
SELECT "Alice_1" as student_name, [85, 90, 78] AS test_scores UNION ALL SELECT "Alice_2" as student_name, [99, 95, 98] AS test_scores UNION ALL SELECT "Alice_3" as student_name, [70, 75, 80] AS test_scores
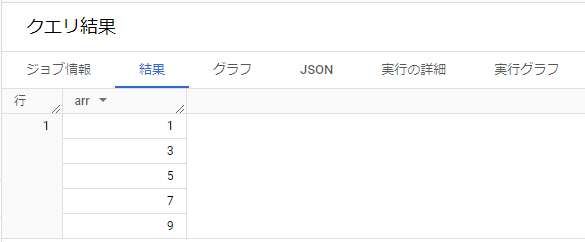
例2) GENERATE_ARRAY [GENERATE_ARRAY]
1から特定の番号までの連番が欲しくなる際使う関数です。1から10までの連番から2ステップで増加する例です。
SELECT GENERATE_ARRAY(1, 10, 2) AS arr;
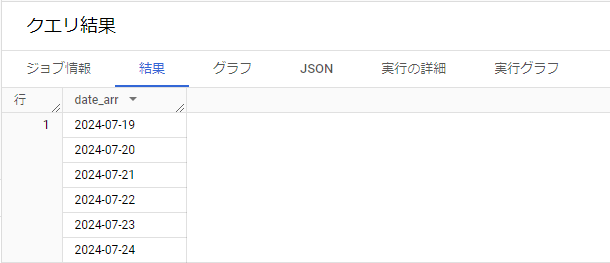
参考:GENERATE_DATE_ARRAY [GENERATE_DATE_ARRAY]
日付も開始日から終了日まで連続日が必要の際、使う関数です。
SELECT GENERATE_DATE_ARRAY("2024-07-19", "2024-07-24") AS date_arr;
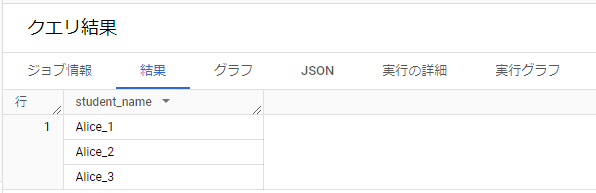
例3) ARRAY_AGG [ARRAY_AGG]
ARRAY_AGG関数を用いて1つの配列にするということが考えられるかと思います。
以下のクエリを実行するとクエリ結果にstudent_nameが配列化されて1つにまとまっているのが確認できます。
WITH Student_names AS ( SELECT "Alice_1" as student_name UNION ALL SELECT "Alice_2" as student_name UNION ALL SELECT "Alice_3" as student_name) SELECT ARRAY_AGG(student_name) as student_name FROM Student_names;
配列内の特定位置にある要素にアクセスすることがあります。これを実現するためには、OFFSETとORDINALという二つの関数を使用できますが、これらはインデックスの開始位置が異なります。
- OFFSET:0から始まるインデックスを使用して配列の要素にアクセスします。
- ORDINAL:1から始まるインデックスを使用して配列の要素にアクセスします。
WITH student_names AS (
SELECT "Alice_1" as student_name
UNION ALL SELECT "Alice_2" as student_name
UNION ALL SELECT "Alice_3" as student_name)
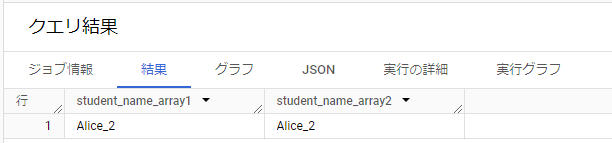
SELECT ARRAY_AGG(student_name)[OFFSET(1)] AS student_name_array1
,ARRAY_AGG(student_name)[ORDINAL(2)] AS student_name_array2
FROM Student_names;
例4) ARRAY_REVERSE [ARRAY_REVERSE]
ARRAY_REVERSEの関数を確認します。配列内の要素の順序を反転させます。
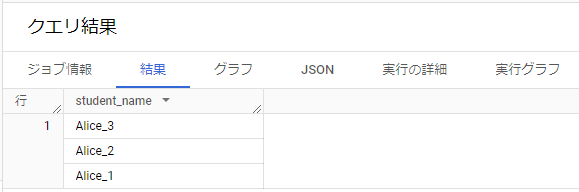
以下のクエリーを実行するとarray_aggの関数を利用して値を配列を作った後、ARRAY_REVERSEの関数を利用して下記のクエリー結果のように配列の値が逆順に整列されて表示されました。
WITH student_names AS ( SELECT "Alice_1" as student_name UNION ALL SELECT "Alice_2" as student_name UNION ALL SELECT "Alice_3" as student_name) SELECT ARRAY_REVERSE(ARRAY_AGG(student_name)) as student_name FROM student_names;
例5) ARRAY_LENGTH [ARRAY_LENGTH]
ARRAY_LENGTHの関数を確認します。配列の要素数を求める際に使用される関数です。
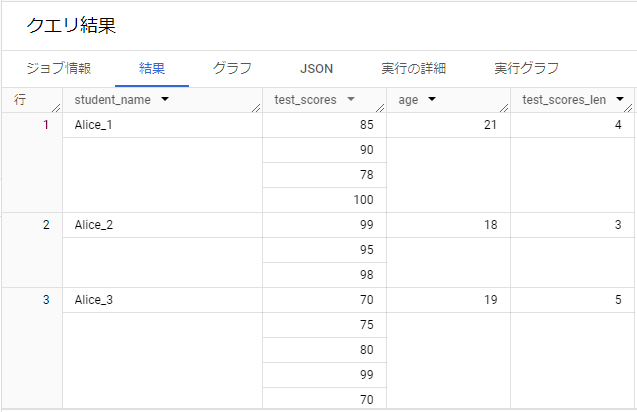
学生の名前、スコアの結果を示す結果ですが、スコアの配列要素数がいくつあるかを確認する関数であり、その結果は以下のクエリ結果です。
WITH student_info AS (
SELECT "Alice_1" as student_name, [85, 90, 78, 100] AS test_scores, 21 as age
UNION ALL SELECT "Alice_2" as student_name, [99, 95, 98] AS test_scores, 18 as age
UNION ALL SELECT "Alice_3" as student_name, [70, 75, 80, 99, 70] AS test_scores, 19 as age)
SELECT *,
ARRAY_LENGTH(test_scores) AS test_scores_len
FROM student_info;
BigQueryのSTRUCTとは?
STRUCTは、異なるデータ型の複数のフィールドを持つ複合データ型です。以下に、STRUCTの基本的な特性と用途を説明します。Struct type
特性
1. 異なるデータ型のフィールドを持つ
STRUCTは、異なるデータ型の複数のフィールドを持つことができ、各フィールドには異なる名前が付けられます。
2. ネストされた構造
STRUCTのフィールドには、さらにSTRUCTやARRAYを含めることができます。これにより、複雑なネスト構造を作成できます。
用途
異なる種類のデータを論理的にグループ化して扱う場合に便利です。例えば、1人の人物の名前、年齢、住所、電話番号などを1つのSTRUCTにまとめて格納できます。
例
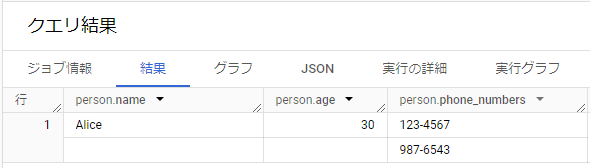
人物の情報をSTRUCTとして格納する例です。
SELECT STRUCT('Alice' AS name,
30 AS age,
['123-4567', '987-6543'] AS phone_numbers) AS person
BigQueryのARRAYとBigQueryのSTRUCTの違い
ARRAYとSTRUCTの主な違いは以下の通りです。
1. データ型の統一性
ARRAYは同じデータ型の要素のみを格納しますが、STRUCTは異なるデータ型のフィールドを持つことができます。
2. アクセス方法
ARRAYの要素にはインデックスを使用してアクセスし、STRUCTのフィールドには名前を使用してアクセスします。
3. 用途
ARRAYは同種のデータをまとめるのに適しており、STRUCTは異種のデータを論理的にグループ化するのに適しています。
BigQueryのUNNESTを使った操作
UNNEST関数を使うことで、ARRAYやSTRUCTのネストされたデータをフラット化し、より扱いやすい形式に変換することができます。UNNEST
例1) ARRAYのUNNEST
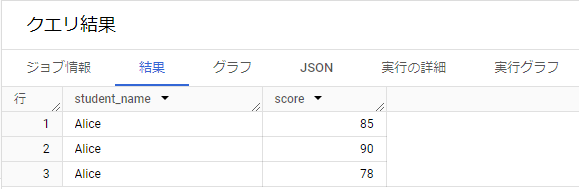
学生の名前とそれぞれのテストスコアを持つARRAYをUNNESTする例です。
SELECT student_name,
score
FROM (
SELECT 'Alice' AS student_name, [85, 90, 78] AS test_scores),
UNNEST(test_scores) AS score
例2) STRUCTのUNNEST
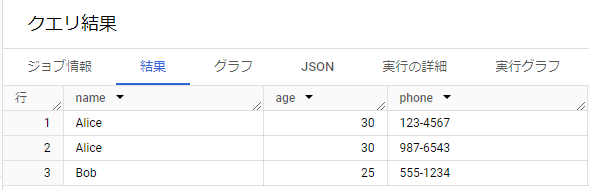
STRUCTの配列をUNNESTして、各フィールドにアクセスする例です。
SELECT person.name,
person.age,
phone
FROM
UNNEST([
STRUCT('Alice' AS name, 30 AS age, ['123-4567', '987-6543'] AS phone_numbers),
STRUCT('Bob' AS name, 25 AS age, ['555-1234'] AS phone_numbers)
]) AS person,
UNNEST(person.phone_numbers) AS phone
まとめ
BigQueryのARRAYとSTRUCTを理解し使いこなすことで、データの柔軟な操作が可能になります。ARRAYは同種のデータをまとめるのに適しており、STRUCTは異種のデータをグループ化するのに適しています。UNNESTを使うことで、ネストされたデータをフラット化し、クエリの結果をより扱いやすくできます。
用途に応じてこれらのデータ型を適切に選択し、効率的なデータ解析を行いましょう。ぜひ、今回紹介したクエリ例を参考にして、BigQueryの強力な機能を活用してみてください。

日本のビールが大好き、韓国出身です。
現、データエンジニアとして活躍してます。
クラウドエンジニアになるために頑張っているところです!
Google Cloud11冠


Recommends
こちらもおすすめ
-

【BigQuery】テーブルの種類を整理してみる
2024.6.13
-

Google BigQueryからAmazon Redshiftにデータを移行してみる
2019.11.29
-
【バスケデータ分析】BigQueryで探るシュート効率
2023.12.15
-

CLI で覚える Google BigQuery
2020.1.30


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16