Cloud Spanner の Data Boost を試してみた!
2024.11.29

はじめに
こんにちは。Koo です。
皆さん、Cloud Spanner の強力な機能の一つである Data Boost をご存知ですか?
本記事では、Data Boost の仕組みや活用法について分かりやすく解説します。
特に、Cloud Spanner のデータを BigQuery や Dataflow などで効率的に分析したい方に役立つ内容です。
ぜひ、最後までご覧ください!
Cloud Spanner とは
Cloud Spanner の概要については、こちらの記事をご覧ください。

Data Boost とは
Spanner Data Boost は、サポートされている Spanner ワークロード用の独立したコンピューティング リソースを提供する、フルマネージドのサーバーレス サービスです。Data Boost を使用すると、プロビジョニングされた Spanner インスタンス上の既存のワークロードへの影響がほぼゼロの状態で、分析クエリとデータ エクスポートを実行できます。このサービスは、Google がリージョン レベルで管理する Spanner クラスタで構成されています。
出典 : Data Boost の概要
Data Boost は、既存の Cloud Spanner インスタンスのリソースに負荷をかけることなく、専用のサーバーレスリソースを使ってデータを分析またはエクスポートするための仕組みです。
これにより、リアルタイムトランザクションに影響を与えることなく、データを効率的に処理できます。
以下の画像は、Cloud Spanner の内部アーキテクチャにおける Data Boost の役割を示したものです。
画像を参照しながら、Data Boost を分かりやすく説明します!
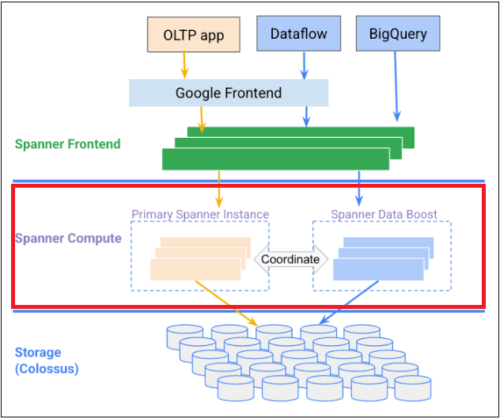
出典 : Data Boost の概要
◾️Spanner Compute
画像の真ん中(赤いところ)のところです。
Cloud Spanner の実際の演算を実行する部分で、主に以下の役割を果たします。
– Primary Instance : 通常の読み取り、書き込み、トランザクション処理を実行します。
– Data Boost : 大量のデータを迅速に分析またはコピーする作業を専用に処理します。
◾️Spanner Data Boost
Data Boost は、Cloud Spanner Compute 内に専用のリソースを確保し、そこにデータをコピーします。
このコピーされたデータは、BigQuery や Dataflow などの分析ツールに適した形式に変換され、分析作業に活用されます。
特に注目すべきは、既存のワークロードに影響を与えないことです。
通常データベースの分析処理はトランザクションに負荷をかけがちですが、Data Boost は専用のリソースで処理を行うため、リアルタイムトランザクションの性能に影響を与えません。
Data Boost のメリット
1. 性能向上
Data Boost は、Cloud Spanner のデータを複数のピースに分割して並列処理を行うことで、クエリ処理の速度を劇的に向上させます。
これにより、従来は数時間かかっていたタスクを、数分で完了させることが可能になります。
このアプローチは、大規模なデータセットに対するクエリやバッチ処理の速度を大幅に短縮し、効率的なデータ管理を実現します。
2. 分析ワークロード隔離
分析作業をメイン Cloud Spanner インスタンスと分離し、OLTP と OLAP ワークロード間の干渉を最小限に抑えます。これにより、リアルタイムのトランザクション処理パフォーマンスに影響を与えることなく、
分析タスクを実行できるようになります。
3. コスト削減
Data Boost は、必要なタイミングでのみ追加リソースを利用するため、インスタンスの拡張コストを効果的に削減できます。
特に、断続的に発生する大規模な分析作業やピーク時の負荷に対応する場合、無駄なコストを抑えつつ、リソースを最適に配分することが可能です。
これにより、企業はコスト効率良く運用できるだけでなく、スケーラビリティにも柔軟に対応できます。
Data Boost の料金
Spanner Data Boost は、サーバーレス処理ユニット(SPU)の使用量に基づき、秒単位で課金されます。
| Cost per SPU per hour |
|---|
| $0.00153 |
※ 例 : 10 SPU を1時間使用した場合、10 × $0.00153 = $0.0153 (約 2.3 円) となります。
※ 試算は Tokyo(asia-northeast1) になります。
ハンズオン
1.事前準備
■ Data Boost を使うためには spanner.databases.useDataBoost IAM権限がなければなりません。
ユーザーアカウントに付与してください。
■ BigQuery Connection API を有効化します。
■ Cloud Spanner と データベース、データ作成
2.データ確認
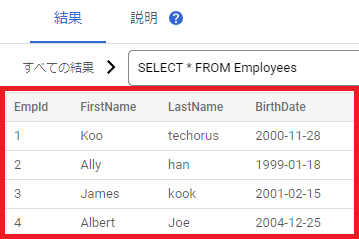
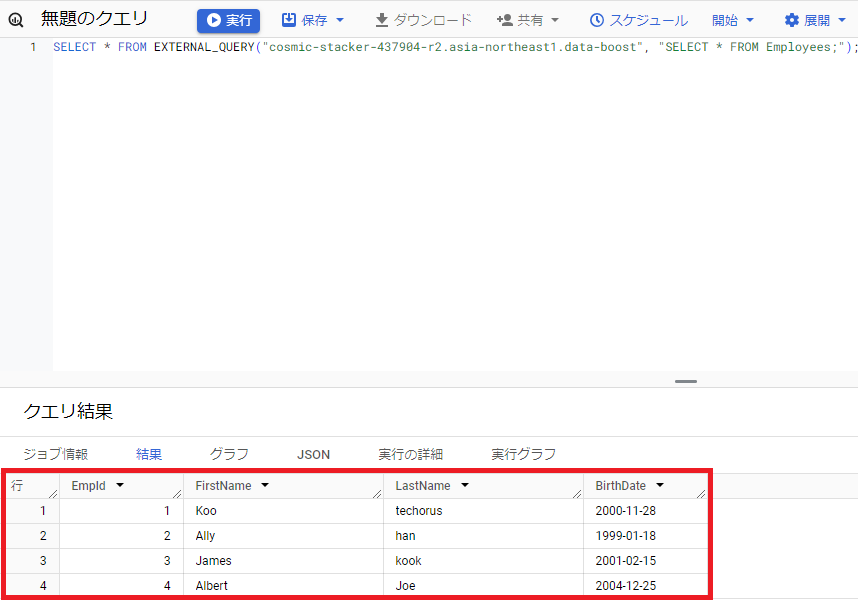
Employees テーブルに4つのデータを保存
3.Cloud Spanner で BigQuery を結合方法
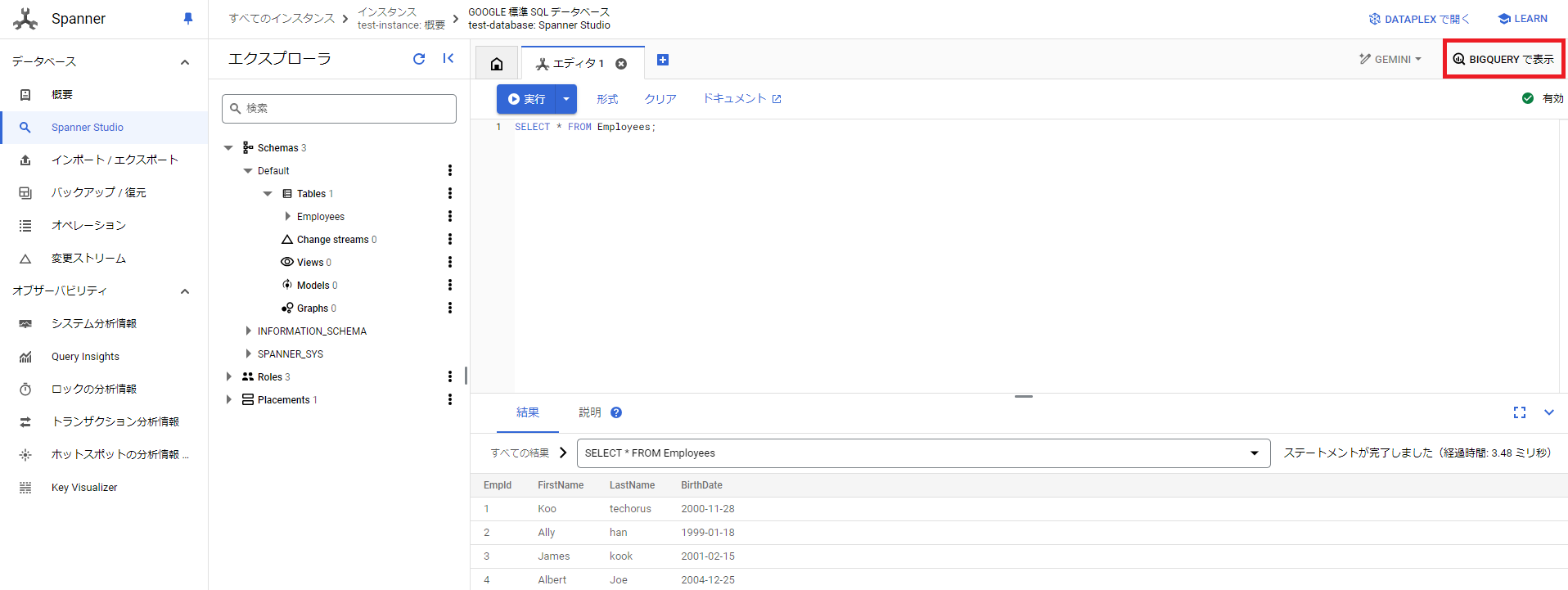
Spanner Studio の画面です。
上段右側に「BIGQUERY で表示」を押します。
4.BigQuery で表示の画面
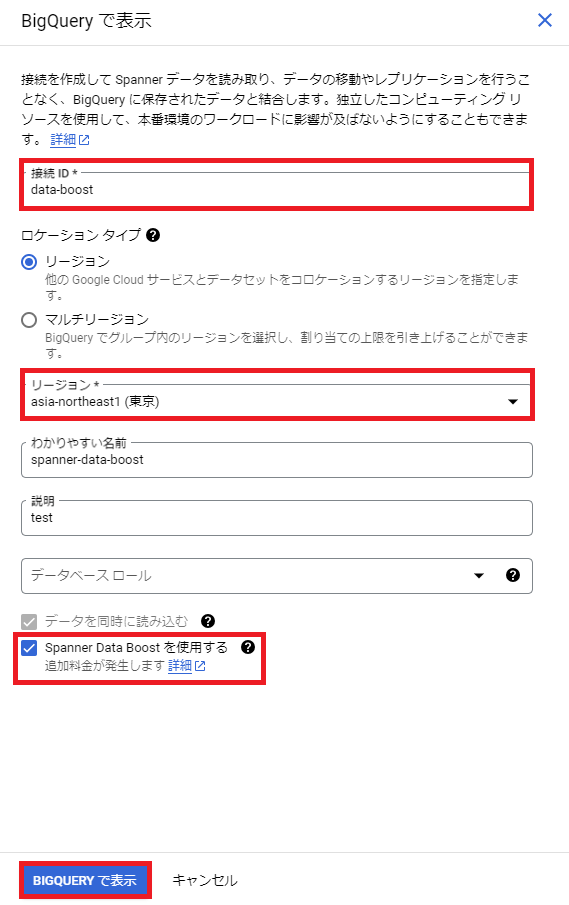
接続 ID は「data-boost」、リージョンは「asia-northeast1(東京)」に設定しました。
分かりやすい名前と説明は任意なので作成しなくてもいいのですが、あれば見やすいです。
一番下の「Spanner Data Boost を使用する」ボタンを押すと、「データを同時に読み込む」は自動に選択されます。
設定が終わったら「BigQuery で表示」を押します。
- コマンドでも可能です。
bq mk --connection \
--connection_type='CLOUD_SPANNER' \
--properties='{"database":"projects/”プロジェクトID”/instances/test-instance/databases/test-database", "useParallelism":true, "useDataBoost": true}' \
--location='asia-northeast1' \
my_connection
//bq mk コマンドを使用して、Data Boost の2つの必須プロパティを持つ my_connection という名前の新しい接続を作成します。
5.BigQuery Studio 画面
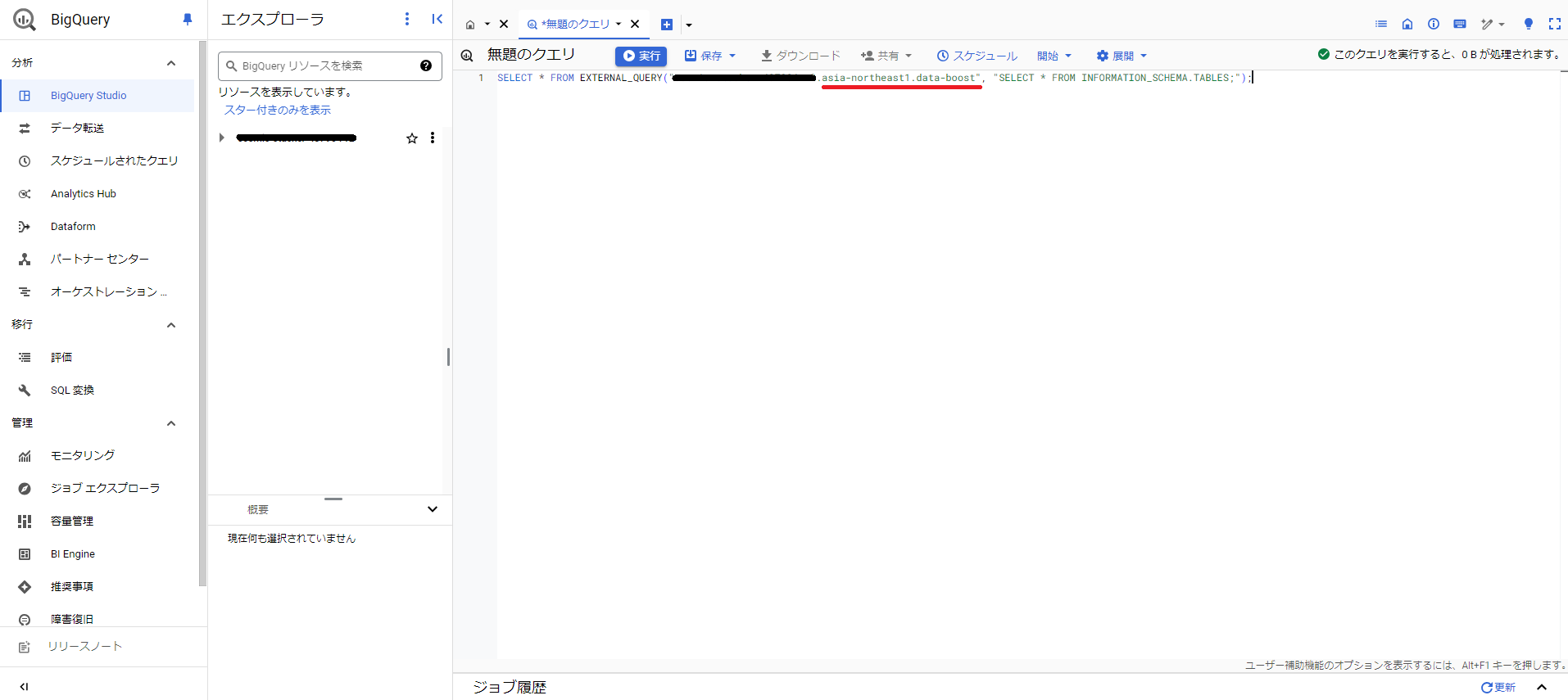
「BigQuery で表示」を押すと、BigQuery Studio の画面が出てきます。
無題のクエリに自分のプロジェクト ID とリージョン、Data Boost 名前が表示されます。
6.Cloud Spanner のデータにアクセス確認
SELECT * FROM EXTERNAL_QUERY("プロジェクトID.asia-northeast1.data-boost", "SELECT * FROM Employees;");
//EXTERNAL_QUERY は、BigQuery で外部データソースにアクセスしてクエリーを実行できるようにしてくれます。
上のクエリを実行すると、BigQuery から Cloud Spanner のデータにアクセスが出来ます。
今日は簡単にどのように使うのかについて、ハンズオンしてみました。
Data Boost の使用によって性能がどれだけ良くなったのか、費用がどれだけ削減されたのかはまだ実感できませんでした。
次の記事では、実際に使用した事例の紹介とデータを大量に入れて、性能テストについて作成しようと思います。
まとめ
今回紹介した Cloud Spanner Data Boost は、Cloud Spanner のデータを効率的に分析するための強力なツールです。
既存のリソースに負荷をかけることなく、専用のリソースを使用して高速かつ安定した分析を実現します。
特に、BigQuery や Dataflow との統合を通じて、大量データの処理や分析をスムーズに行うことが可能です。
リソースの効率的な活用や分析性能向上をお考えの方は、ぜひ Data Boost をお試しください!
最後までお読みいただきありがとうございました。

料理と音楽が好きなデータベースエンジニアです。 MySQL と Google Cloud、特に Cloud Spanner への関心が高いです。


Recommends
こちらもおすすめ
-

【初心者向け】Cloud Spanner を触ってみましょう!
2024.10.21
-
【初心者向け】Cloud Spanner のバックアップを理解しよう!
2024.11.18



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16