Colab Enterpriseを使って、BigQueryのデータセットからNBAプレーオフの順位を予想して実際の結果と比べてみた:2022-2023シーズン
2024.4.17

はじめに
こんにちは、Shunです!
本年度ももうそろそろ終わってしまいますね。
あ、NBA 2023-2024のレギュラーシーズンの話です。
今年もNBAのプレーオフが始まろうとしており、ネットレーティング過去最高のセルティックスの優勝か、それとも八村塁を擁するレイカーズが頂点に立つのか、目が離せません!
NBAファイナルの試合日には有休を取るつもりです、取ります(宣言)
(7試合あります)
前置きが長くなりましたが今回は、
Google CloudのColab Enterpriseという簡単にPython実行環境を利用できるサービスを使って、NBA 2022-2023 レギュラーシーズンのスタッツから順位予想を行って、実際に行われたプレーオフの結果と答え合わせをします。
想定読者
- Colab Enterpriseに興味がある方
- Google Cloudのデータ分析ツールに興味がある方
- バスケのデータ分析に興味がある方
本記事で取り扱う内容
- Colab Enterpriseの概要
- Colab Enterpriseを用いたデータ分析方法
- データ分析の過程の解説
本記事で取り扱わない内容
- BigQueryのセットアップ方法
気になる方は、以下記事の前半箇所を参照ください。

- Colab Enterpriseのセットアップ方法
気になる方は、以下記事の前半箇所を参照ください。

Colab Enterpriseとは
概要
Colab Enterpriseは、Google Cloudが提供するJupyter Notebookを簡単かつ安全に扱えるデータ分析環境です。
IAMによるアクセス制御、データ保存リージョンの選択などの管理機能を備えています。従量課金制で、リソース使用量に応じた料金がかかります。
使い方は、ランタイムテンプレートを作成し、ランタイムを作成してNotebookに接続するだけで簡単に利用を開始できます。
また、コード補完にはGeminiを利用できます。
参考: Introduction to Colab Enterprise
料金
Colab Enterpriseの実行環境として利用するCompute Engineのリソース量に対しての課金となります。
各インスタンスタイプの特徴はこちらを参照してください。
実施すること
概要
この記事では、NBA 2022-2023 レギュラーシーズンの統計を用います。
統計データはBigQueryに格納し、Colab Enterpriseから取得します。
その後、取得したデータを正規化し、トーナメント形式で2022-2023シーズンのプレーオフ結果を予想し、実際の結果と照らし合わせます。
手順
- データセットを取得する
- BigQueryへデータを格納
- Colab Enterpriseのセットアップ
- Colab EnterpriseからBigQueryのデータセットを取得
- プレーオフトーナメントの予想と答え合わせ
分析方法
バスケの試合結果に大きく影響する「Four Factors」という指標を使用します。
この指標は、シュートの効率性(eFG%)、ターンオーバーの割合(TOV%)、フリースローの割合(FTR)、オフェンスリバウンドの獲得率(ORB%)の勝敗を左右する主要な要素の4つを数値化したものです。
参考: バスケットボールを数字で分解する。~みんなに知ってほしいFour Factors~
(1)eFG%
3pに付加価値をつけたシュート効率
eFG% = (3P * 1.5 + 2P) / FGA
(2)TOV%
シュートを打てずに攻撃が終わる割合
TOV% = TOV / (FGA + 0.44 * FTA + TOV)
(3)FTR
総シュート試投数(FGA)に占める総フリースロー数の割合
FTR = FTA/FGA
(4)ORB%
オフェンスリバウンドの獲得率
ORB% = ORB / (ORB + 相手DRB)
今回、分析に使用するデータセットからは相手チームのDRBを取得できないため、[ORB%]を除いた[eFG%]、[TOV%]、[FTR]のThree Factors?の値を用います。
[eFG%]、[FTR]は高いほど良く、[TOV%]は低いほど良い数値となります。
NBAプレーオフのルール
NBAプレーオフのルールを簡単に説明します。
- レギュラーシーズンは、西カンファレンスと東カンファレンスそれぞれ15チームによって行われます。
- 各カンファレンスの上位8チームがプレーオフへ進出します。
- プレーオフはトーナメント形式で実施され、7試合制のシリーズで4勝したチームが次のラウンドへ進みます。
- トーナメントは1位vs8位、2位vs7位、3位vs6位、4位vs5位の対戦で構成されます。
- 2回戦では、1位vs8位の勝者が4位vs5位の勝者と、2位vs7位の勝者が3位vs6位の勝者と対戦します。
- NBAファイナルでは、各カンファレンスのチャンピオン同士が対戦します。
環境構築
1. データセットの準備
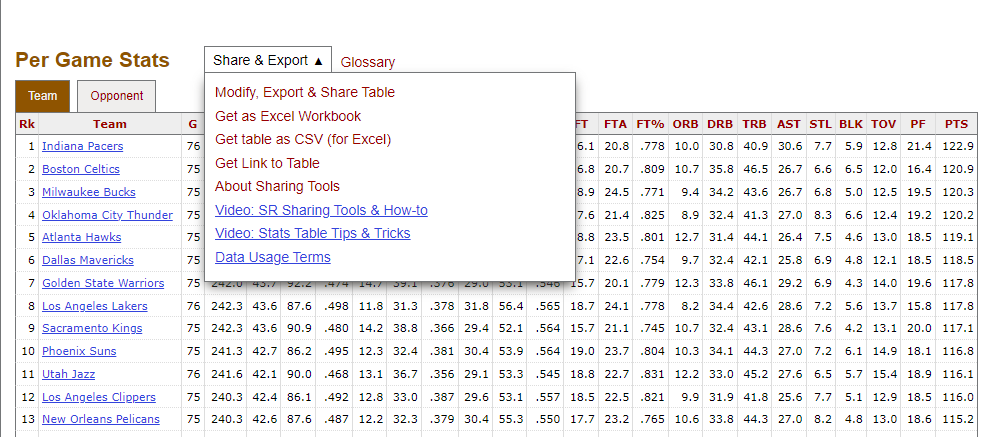
いつもお世話になっている、「Basketball Reference」というNBAのデータをまとめたサイトからデータセットを取得します。
今回使用するデータセットは、NBA 2022-2023シーズンの「Per Game Stats」として、全30チームの平均得点やフィールドゴール率などが記録されています。
「Share & Export」からデータをダウンロードすることができます。
2. BigQueryへデータを格納
ダウンロードしたファイルからスキーマ情報など不要な情報を削除し、BigQueryにアップロードします。
スキーマは以下のように定義しています。
[
{
"name": "TEAM",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "G",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "MP",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "FG",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "FGA",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "FG%",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "3P",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "3PA",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "3P%",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "2P",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "2PA",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "2P%",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "FT",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "FTA",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "FT%",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "ORB",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "DRB",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "TRB",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "AST",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "STL",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "BLK",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "TOV",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "PF",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "PTS",
"type": "FLOAT",
"mode": "NULLABLE"
}
]
以下のように、プレビューからデータを確認します。

3. Colab Enterpriseのセットアップ
ノートブックを新規作成します。

右上の「接続」を選択するだけで、実行環境を準備できます。

しばらくすると、接続が完了します。
ランタイムテンプレートの準備がまだの方は、以下をご覧ください。
4. Colab EnterpriseからBigQueryのデータセットを取得
まず、Google Cloudのサービスを呼び出すためのユーザー認証を実施します。
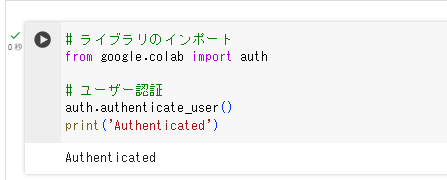
# ライブラリのインポート
from google.colab import auth
# ユーザー認証
auth.authenticate_user()
print('Authenticated')
次に、分析で使用するデータをBigQueryから取得します。
# ライブラリのインポート from google.cloud import bigquery # BigQueryクライアントの初期化 project_id = '[プロジェクトID]' client = bigquery.Client(project=project_id) # クエリの実行 query = """ SELECT TEAM, (`3P` * 1.5 + `2P`) / FGA AS `eFG%`, TOV / (FGA + 0.44 * FTA + TOV) AS `TOV%`, FTA/FGA AS FTR FROM `[プロジェクトID].[データセット名].[テーブル名]` LIMIT 1000 """ query_job = client.query(query) teams_data = query_job.to_dataframe() # 結果の確認 print(teams_data.head(31))
結果は次のように表示されます。
TEAM eFG% TOV% FTR
0 Utah Jazz 0.547327 0.133135 0.265033
1 Toronto Raptors 0.516429 0.103269 0.256298
2 Detroit Pistons 0.520092 0.133030 0.295063
3 Miami Heat 0.531067 0.123944 0.269637
4 Dallas Mavericks 0.564650 0.113442 0.297746
5 Portland Trail Blazers 0.549766 0.130956 0.288056
指標ごとの数値差が大きいこと、各指標内での差はそれほど大きくない、ということが分かります。
このため、分析を容易にするためにこれらの値を正規化します。
import pandas as pd from sklearn.preprocessing import MinMaxScaler # 特徴量の列のみを抽出 features = teams_data[['eFG%', 'TOV%', 'FTR']] # 正規化の実行 scaler = MinMaxScaler() # MinMaxScalerのインスタンスを作成 normalized_features = scaler.fit_transform(features) # 特徴量を正規化 # 正規化された特徴量をデータフレームに戻す normalized_df = pd.DataFrame(normalized_features, columns=features.columns) # チーム名を追加 normalized_df['TEAM'] = teams_data['TEAM'] # 結果の確認 print(normalized_df.head(31))
余談ですが、
Colab Enterpriseでは、コメントアウトで書きたい内容を記述すると、Genimiが呼び出され、コードの提案を実施してくれます。

結果は次のように表示されます。
これで各指標を一律で比較しやすくなりました。
eFG% TOV% FTR TEAM
0 0.558677 0.786081 0.543647 Utah Jazz
1 0.025796 0.000000 0.428062 Toronto Raptors
2 0.088961 0.783323 0.940993 Detroit Pistons
3 0.278240 0.544173 0.604555 Miami Heat
4 0.857431 0.267749 0.976493 Dallas Mavericks
5 0.600731 0.728734 0.848279 Portland Trail Blazers
Colab Enterpriseからは以下のように見ることができます。

5. プレーオフトーナメントの予想と答え合わせ
ここでは、プレーオフトーナメントの予想と答え合わせを実施します。
まず、各カンファレンスのトーナメント表を作成します。
各カンファレンスのteamA、Bの同じ配列にあるチームが繰り返し、試合を行います。
# マッチアップデータの東西分割
east_matchups = pd.DataFrame({
'teamA': ['Milwaukee Bucks', 'Cleveland Cavaliers', 'Philadelphia 76ers', 'Boston Celtics'],
'teamB': ['Miami Heat','New York Knicks', 'Brooklyn Nets', 'Atlanta Hawks']
})
west_matchups = pd.DataFrame({
'teamA': ['Denver Nuggets', 'Phoenix Suns', 'Sacramento Kings','Memphis Grizzlies'],
'teamB': ['Minnesota Timberwolves', 'Los Angeles Clippers', 'Golden State Warriors','Los Angeles Lakers']
})
次に、各チームに対応する値を取得し、各値の差を特徴量として定義します。
def calculate_matchup_features(matchup, teams_stats):
# 指定されたマッチアップのチーム統計を抽出
teamA_stats = teams_stats.loc[teams_stats['TEAM'] == matchup['teamA']].iloc[0]
teamB_stats = teams_stats.loc[teams_stats['TEAM'] == matchup['teamB']].iloc[0]
# 特徴量
features = {
'eFG_percent_diff': teamA_stats['eFG%'] - teamB_stats['eFG%'],
'TOV_percent_diff': teamA_stats['TOV%'] - teamB_stats['TOV%'],
'FTR_diff': teamA_stats['FTR'] - teamB_stats['FTR'],
}
return features
定義した特徴量に、僕の感覚的な重みづけを行います。
プレーオフは、効率的に点を取る(eFG%)よりも、いかにミス(TOV%)を減らし、フリースローを獲得(FTR)できるかが非常に重要だと思っています。
そして、スポーツに絶対はないので、ランダム値も定義します。
import random
def simple_predict_winner(features):
# 感覚的な重み付け
efg_weight = 0.3
tov_weight = 0.35
ftr_weight = 0.35
# スコアを計算
score = (features['eFG_percent_diff'] * efg_weight) - \
(features['TOV_percent_diff'] * tov_weight) + \
(features['FTR_diff'] * ftr_weight)
# ランダム要素も追加
random_factor = random.uniform(-0.2, 0.2)
score += random_factor
# スコアが正ならteamA、それ以外ならteamBの勝利
return 'teamA' if score >= 0 else 'teamB'
これでルールなどの準備は完了です。
ここからは、実際にトーナメントを実施します。
def simulate_conference_tournament(matchups, teams_stats, conference_name):
print(f"Starting the {conference_name} Conference Tournament\n")
# トーナメントをシミュレートし、チャンピオンを決定する
champion = simulate_tournament(matchups, teams_stats)
print(f"The {conference_name} Conference Champion is: {champion}\n")
return champion
# トーナメントを実施
def simulate_tournament(matchups, teams_stats):
current_round = matchups
round_number = 1
while len(current_round) > 0:
print(f"\nRound {round_number}:")
winners = []
for i in range(len(current_round)):
teamA = current_round.iloc[i]['teamA']
teamB = current_round.iloc[i]['teamB']
# 先に4勝したチームが次のラウンドへ進みます。
winsA, winsB = 0, 0
while winsA < 4 and winsB < 4:
matchup_features = calculate_matchup_features({'teamA': teamA, 'teamB': teamB}, teams_stats)
winner_key = simple_predict_winner(matchup_features)
if winner_key == 'teamA':
winsA += 1
else:
winsB += 1
winner_team = teamA if winsA == 4 else teamB
print(f"{teamA} vs {teamB} - Winner: {winner_team} ({winsA}-{winsB})")
winners.append(winner_team)
# 次のラウンドのマッチアップを準備
if len(winners) > 1:
next_round_teams = {'teamA': winners[::2], 'teamB': winners[1::2]}
current_round = pd.DataFrame(next_round_teams)
else:
# 1チームのみ残っている場合(チャンピオンが決定)
print(f"\nChampion: {winners[0]}\n")
return winners[0]
round_number += 1
# 東西カンファレンスのチャンピオンを取得
east_champion = simulate_conference_tournament(east_matchups, teams_data, "East")
west_champion = simulate_conference_tournament(west_matchups, teams_data, "West")
# NBAファイナルのマッチアップ
print("NBA Finals:")
nba_finals_matchup = pd.DataFrame({
'teamA': [east_champion],
'teamB': [west_champion]
})
# NBAファイナルズをシミュレート
nba_champion = simulate_tournament(nba_finals_matchup, teams_data)
print(f"The NBA Champion is: {nba_champion}")
得られた結果は、以下です。

全文
Starting the East Conference Tournament Round 1: Milwaukee Bucks vs Miami Heat - Winner: Miami Heat (1-4) Cleveland Cavaliers vs New York Knicks - Winner: New York Knicks (2-4) Philadelphia 76ers vs Brooklyn Nets - Winner: Brooklyn Nets (2-4) Boston Celtics vs Atlanta Hawks - Winner: Boston Celtics (4-1) Round 2: Miami Heat vs New York Knicks - Winner: New York Knicks (2-4) Brooklyn Nets vs Boston Celtics - Winner: Boston Celtics (2-4) Round 3: New York Knicks vs Boston Celtics - Winner: New York Knicks (4-2) The East Conference Champion is: New York Knicks Starting the West Conference Tournament Round 1: Denver Nuggets vs Minnesota Timberwolves - Winner: Denver Nuggets (4-2) Phoenix Suns vs Los Angeles Clippers - Winner: Phoenix Suns (4-3) Sacramento Kings vs Golden State Warriors - Winner: Sacramento Kings (4-0) Memphis Grizzlies vs Los Angeles Lakers - Winner: Memphis Grizzlies (4-1) Round 2: Denver Nuggets vs Phoenix Suns - Winner: Denver Nuggets (4-1) Sacramento Kings vs Memphis Grizzlies - Winner: Sacramento Kings (4-0) Round 3: Denver Nuggets vs Sacramento Kings - Winner: Denver Nuggets (4-0) The West Conference Champion is: Denver Nuggets NBA Finals: Round 1: New York Knicks vs Denver Nuggets - Winner: Denver Nuggets (2-4) The NBA Champion is: Denver Nuggets
ナゲッツが優勝したとの予想は的中しています!!!
ただ、ファイナルにはニックスが進んでいます!
今回の予想と結果を以下の表にまとめました。赤字が予想と結果が一致している箇所です。
| 順位 | 予想 | 結果 |
|---|---|---|
| 1 | Denver Nuggets | Denver Nuggets |
| 2 | New York Knicks | Miami Heat |
| ベスト4 | Sacramento Kings | Los Angeles Lakers |
| ベスト4 | Boston Celtics | Boston Celtics |
| ベスト8 | Phoenix Suns | Phoenix Suns |
| ベスト8 | Memphis Grizzlies | Golden State Warriors |
| ベスト8 | Miami Heat | New York Knicks |
| ベスト8 | Brooklyn Nets | Philadelphia 76ers |
| ベスト16 | Minnesota Timberwolves | Minnesota Timberwolves |
| ベスト16 | Los Angeles Clippers | Los Angeles Clippers |
| ベスト16 | Golden State Warriors | Sacramento Kings |
| ベスト16 | Los Angeles Lakers | Memphis Grizzlies |
| ベスト16 | Milwaukee Bucks | Milwaukee Bucks |
| ベスト16 | Cleveland Cavaliers | Cleveland Cavaliers |
| ベスト16 | Brooklyn Nets | Philadelphia 76ers |
| ベスト16 | Atlanta Hawks | Atlanta Hawks |
上位チームもそこそこ当たっています。
ただこの後、何度か同じ予想を実行したのですが、ナゲッツ、キングス、シクサーズなど特定のチームが優勝となることが多かったです。
今回は、Four Factorsの中から3つの値と分析に使用する指標が少なかったため、対象の値が良いチームが優勝する傾向になってしまいました。
実際の結果通りではあるのですが、1位シードのバックスは8位シードのヒートにかなりの確率で負けてました。
元データを見てもバックス有利のはずでしたが、やはりデータ分析の世界でもプレーオフ・ヒートでした。
まとめ
今回は、BigQueryとColab Enterpriseを使って、2022-2023 NBAプレーオフトーナメントの結果予想と答え合わせをしてみました。
やってみたいなぁと思ってから結果予想まで、環境構築にかかる時間はほぼなく、どのように分析を行おうと考える時間を多くとることができました。
パブリッククラウドが提唱している本来やるべき業務に注力ができる。というメリットを身をもって感じました。
今回は過去の結果を取り入れていないため、予想の精度については改善の余地があります。
NBAのレギュラーシーズンもそろそろ終わりますし、レギュラーシーズンのデータと過去のプレーオフデータを読み込ませて、モデルを作って分析をしたいです。
最後まで読んでいただきありがとうございます!

Google Cloud Partner Top Engineer 2025、2024 AWS All Cert、ビール検定1冠


Recommends
こちらもおすすめ






Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16