BigQuery がなぜ人気なのかをアーキテクチャの観点から考えてみた!
2024.12.23

はじめに
こんにちは、Shunです!
先日、Amazon Aurora DSQL と Cloud Spanner のアーキテクチャを比較した際に、クラウドサービスの差異は基本となるアーキテクチャが大きく関係していると感じました。

そこで今回は Google Cloud と言えば、BigQuery と言われるぐらい代表的なサービスである BigQuery をアーキテクチャの観点からその人気の秘訣を見ていきたいと思います!
BigQuery の概要を知りたい方は以下の記事を先にご覧ください!

BigQuery が人気の秘訣
BigQuery がなぜ人気なのか?
それは
速くて安い!!!
これに尽きると思います!
きっと私たちは生活をする上で、交通手段や食事など多くの場面で「速くて安い」 を選んでいるのではないでしょうか?
データウェアハウスもきっとその一つです。
なぜ速くて安いのか?
以下の2つの仕組みがそれを実現させています。
- カラム型データストア
- ツリーアーキテクチャ
それぞれについてもう少し詳細に見ていきましょう。
カラム型データストア
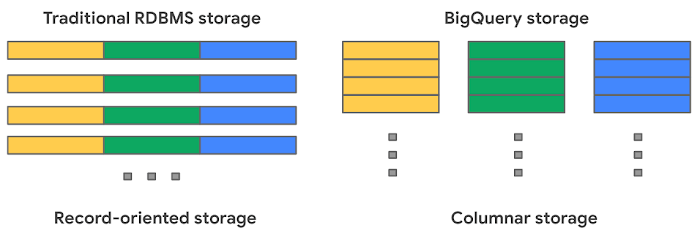
出典: BigQuery Admin reference guide: Storage internals
BigQuery は、データを列ごとにまとめて格納するカラム型データストアを採用しています。
従来の RDB のような行ごとにデータを格納する方式とは異なり、必要な列だけを読み込むことができるため、集計処理などを高速かつ安価に行うことができます。
例えば、売上合計を求める際に、カラム型であれば「売上」の列だけを読み込めば良いので、テーブル全体を読み込む必要がなく、処理速度が大幅に向上します。
このカラム型データストアにより、BigQuery は大量のデータを高速かつ安価に分析することを実現しています。
ツリーアーキテクチャ
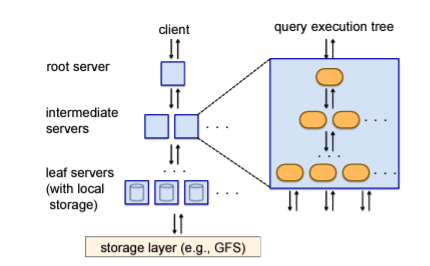
出典: Dremel: A Decade of Interactive SQL Analysis at Web Scale
BigQuery は ツリーアーキテクチャ により、クエリを複数のサーバーに分散して処理することで、高速化を実現しています。
クライアントから受け取ったクエリは、ルートサーバーで分割され、複数のリーフサーバーに分配されます。各サーバーで処理された結果をまとめることで、大規模なデータも効率的に処理できます。
このツリー構造による並列処理が、BigQuery の高速なクエリ処理を支えています。
BigQuery のアーキテクチャ
続いては、BigQuery 全体のアーキテクチャを見ていきます。
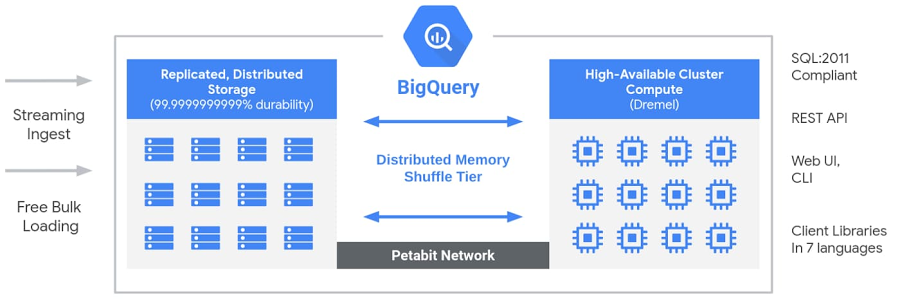
出典: BigQuery explained: An overview of BigQuery’s architecture
BigQuery のアーキテクチャは、ストレージとコンピューティングリソースが分離されていることが大きな特徴です。
これにより、「ツリーアーキテクチャ」で必要なコンピューティングリソースだけをスケールすることができます。
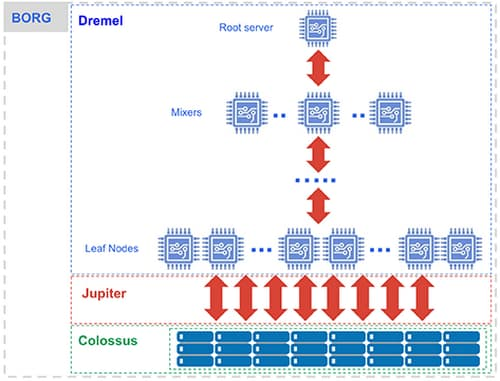
また BigQuery は、Borg、Dremel、Jupiter、Colossus などの Google 独自の技術が採用されています。
Dremel(コンピューティング)
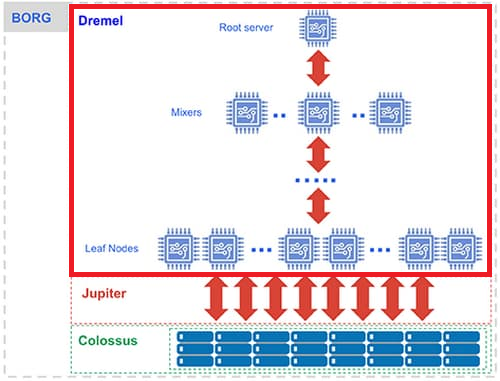
Dremel は、SQL クエリをツリー状に分解し、各部分を「スロット」と呼ばれる単位で並列処理することで高速化を実現する、BigQuery のクエリ実行エンジンです。
この機能が「ツリーアーキテクチャ」を実現するための仕組みとなります。
Colossus(ストレージ)
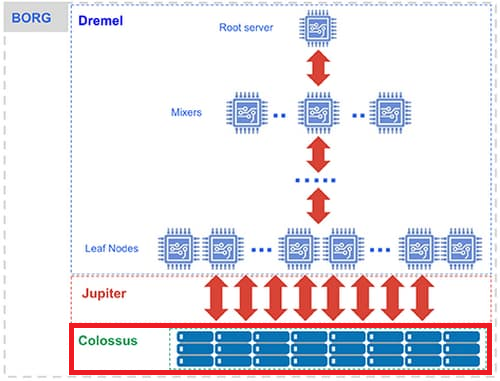
Colossus は、BigQuery のデータを格納する、Google のグローバルストレージシステムです。列指向のストレージ形式と圧縮アルゴリズムにより、大量の構造化データの読み取りを最適化しています。
この機能が「カラム型データストア」を実現する仕組みとなります。
Jupiter(ネットワーク)
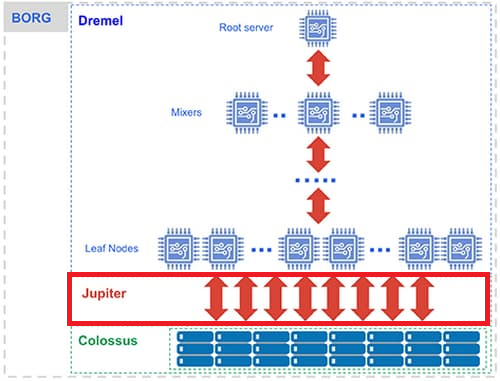
Jupiter は、BigQuery のストレージ (Colossus) とコンピューティング (Dremel) を接続する、Google のネットワークです。ペタビット級の帯域幅を持つ Jupiter により、大量のデータがストレージとコンピューティングの間を高速に移動し、クエリ処理の高速化を実現します。
Borg(コンテナオーケストレーション)
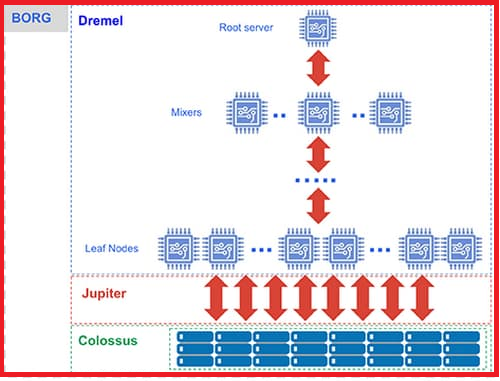
Borg は、Google のコンテナオーケストレーションシステムであり、Kubernetes の前身です。BigQuery では、Borg が Dremel のスロットなどのコンポーネントを実行し、リソースを効率的に管理しています。
BigQuery の事例
資生堂: BigQuery を用いたデータ分析基盤でコスト 8 割減、処理時間 9 割減を達成、AI / MLを含めたデータ活用を活性化
資生堂は、DX推進の一環として、Google Cloud 上にBigQueryを用いたデータ分析基盤を構築しました。従来のデータ分析環境では、外部委託による非効率な運用や複雑な DB サーバー群により、処理時間とコストが膨大になっていました。そこで、BigQueryの処理性能とコスト削減効果に着目し、新たなデータ分析基盤を構築しました。
その結果、コストを8割、処理時間を9割削減することに成功しました。
freee:データ ウェアハウス構築に BigQuery を採用することで、5 ~ 10 倍のパフォーマンスと運用性、利便性を向上
freee はデータ基盤を刷新時に BigQuery を採用し、処理速度の向上、コスト削減を実現しました。
処理速度は、従来の環境と比べて5~10倍高速化し、コストを大幅に削減することに成功しました
まとめ
ここまでなぜ BigQuery は「速くて安い」のかについて見てきました。
改めて BigQuery が「速くて安い」理由は以下の2つになります!
- カラム型データストア
- ツリーアーキテクチャ
これらを実現するために、BigQuery はストレージとコンピューティングの分離や Dremel などの Google 独自のアーキテクチャが採用されています!
このアーキテクチャは、BigQuery に限らず、Google Kubernetes Engine (GKE) や Cloud Spanner にも取り入れられています。
アーキテクチャを知ることで、Google Cloud を代表するサービスがなぜ特徴があり、人気があるのかを知れました!
最後までお読みいただきありがとうございます!
参考資料

Google Cloud Partner Top Engineer 2025、2024 AWS All Cert、ビール検定1冠


Recommends
こちらもおすすめ
-

Cloud Spanner の Data Boost を試してみた!
2024.11.29
-

ETL ツール TROCCO で始める AWS コスト分析ダッシュボード構築
2025.9.25
-

BigQuery ML で単語をクラスタリングしてみる
2020.3.12


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16