Glue Data Catalogにテーブルを登録したデータを対象に加速クロールを使う

はじめに
この記事はNHN テコラス Advent Calendar 2024の22日目の記事です。
私が所属するチームではGlue Crawlerを使うことが多く、その中でも加速クロールと呼ばれる機能を使ってデータを管理することが多いです。しかし加速クロールは全体クロールや増分クロールよりも設定が複雑で、理解が難しい部分があります。
そのため今回は加速クロールの説明とCloudFormationの構成のサンプルを共有したいと思います。
クローラーの種類
まずGlue Crawlerについて簡単に説明します。大きく分けて3種類の読み取り方法があります
・全体クロール
・増分クロール
・加速クロール
全体クロールのメリットは、設定が楽な点です。またデータのスキーマに変更があった場合Glueのテーブルのスキーマが自動で更新が行われます。デメリットはデータの件数が増えると実行時間とコストが上がる点になります。検証や一時的に使用する場合やデータ件数が少ない場合は一旦こちらの設定を使えば問題ありません。
増分クロールのメリットは、追加されたデータのみを読み取ることで効率よくデータを読み込んでパーティションの更新などが可能な点にあります。デメリットはデータのスキーマに変更があった場合、Glueのテーブルのスキーマを自動で更新をすることができません。また事前にGlue Tableにデータのスキーマを定義していた場合には増分クロールは利用できない点は注意が必要です。
加速クロールのメリットは、増分クロールのように増えたデータの分だけ読み取りが可能ですが、増分クロールにはできないスキーマの更新ができます。またGlue Tableで事前にスキーマを定義した場合でも、増分クロールと同じことを行うことができます。デメリットは増分クロールの上位互換のようですが、SQSやS3イベント通知などGlue以外のリソースの作成が必要なため、構築するために手間かかります。
AWSのドキュメントは以下になります。
Amazon S3 イベント通知を使用した加速クロール
また私の方でも以前加速クロールの説明をまとめたので、よければこちらも読んでみてください。
加速クロールを使う場合
次に加速クロールを利用するパターンについて説明します。
全部で2つのパターンがあります。
(1) 事前にテーブルを作成して、増えたデータにのみクローラーを実行したい場合
事前にテーブルを定義していない場合は増分クロールの設定が可能ですが、事前にテーブルを定義していた場合増分クロールが設定できません。この場合、加速クロールの設定をすることで増分のデータのみクロールすることが可能になります。
AWSのドキュメントだと以下の内容になります。
Data Catalog テーブルの Amazon S3 イベント通知用のクローラーを設定する
(2) 事前にテーブルは作成しないが、スキーマが定期的に更新される場合
データによってカラムが異なり新しいカラムが定期的に追加されるなど、データのスキーマが一定ではない場合、手動で毎回スキーマを設定するのは手間がかかります。全体クロールでも対応は可能ですが、こちらはクローラーのコストと実行時間がデータ量に応じて増加するため好ましくはありません。将来的に実行時間やコストを抑えたい場合は加速クロールを採用すると効率が良い実装をすることができます。
AWSのドキュメントだと以下になります。
Amazon S3 ターゲットの Amazon S3 イベント通知用のクローラーを設定する
今回は1について、サンプルと合わせて紹介していきます。
構成
今回の構成は以下になります。
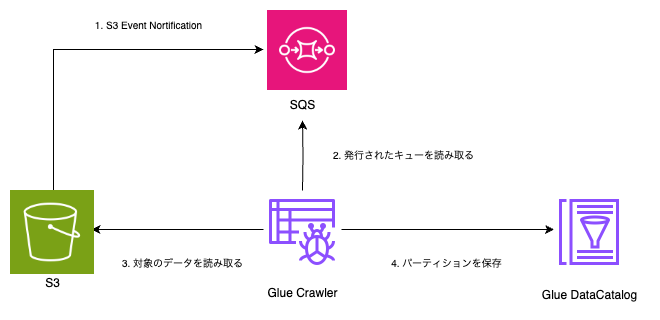
あらかじめデータのスキーマをData Catalogのテーブルに設定しておきます。
そのテーブルをもとに、Glue CrawlerがS3にあるデータとパーティションをData Catalogに登録します。
対象データ
顧客のデータが入った情報をS3にアップロードすると想定します。
今回は全体クロールで実行していたデータの一部を加速クロールに切り替えてみます。
件数: 36201件
容量: 150MB
ファイル形式はParquet使用します。
テンプレート
AWSTemplateFormatVersion: "2010-09-09"
Resources:
# S3
S3Bucket:
Type: AWS::S3::Bucket
DeletionPolicy: Retain
Properties:
BucketName: adv-2024-accelarating-crawler
VersioningConfiguration:
Status: Suspended
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
BucketKeyEnabled: true
PublicAccessBlockConfiguration:
BlockPublicAcls: TRUE
BlockPublicPolicy: TRUE
IgnorePublicAcls: TRUE
RestrictPublicBuckets: TRUE
OwnershipControls:
Rules:
- ObjectOwnership: BucketOwnerEnforced
# IAM Role
CrawlerRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "glue.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSQSFullAccess
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
- !Ref CrawlerPolicy
# IAM Policy
CrawlerPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
PolicyDocument:
Version: '2012-10-17'
Statement:
-
Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::adv-2024-accelarating-crawler/user/*
Type: string
# SQS Policy
SQSPoicy:
Type: AWS::SQS::QueuePolicy
Properties:
Queues:
- !Ref SQSQueue
PolicyDocument:
Version: '2012-10-17'
Statement:
-
Sid: sqs-message
Effect: Allow
Principal:
Service: s3.amazonaws.com
Action:
- sqs:*
Resource:
- !GetAtt SQSQueue.Arn
Condition:
StringEquals:
"aws:SourceAccount": !Ref AWS::AccountId
ArnLike:
"aws:SourceArn": "arn:aws:s3:*:*:adv-2024-accelarating-crawler"
# SQS
SQSQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: adv_sqs_queue
# DB
GlueDB:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: adv_2024_glue_db
# Glue Crawler
GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: adv_2024_glue_crawler_event
Role: !GetAtt CrawlerRole.Arn
Targets:
CatalogTargets:
- DatabaseName: !Ref GlueDB
Tables:
- !Ref GlueTable
EventQueueArn: !GetAtt SQSQueue.Arn
SchemaChangePolicy:
UpdateBehavior: LOG
DeleteBehavior: LOG
RecrawlPolicy:
RecrawlBehavior: CRAWL_EVENT_MODE
# Glue Table
GlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref GlueDB
TableInput:
Name: adv_user
TableType: EXTERNAL_TABLE
Parameters: {"classification": "parquet"}
StorageDescriptor:
InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Columns:
- Name: aws_account_id
Type: string
- Name: company_name
Type: string
- Name: signup_id
Type: int
- Name: discount_rate
Type: double
Location: s3://adv-2024-accelarating-crawler/user/
SerdeInfo:
Parameters: { "serialization.format": "1" }
SerializationLibrary: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
PartitionKeys:
- Name: payer_aws_account_id
Type: string
- Name: year
Type: string
- Name: month
Type: string
- Name: create_date
テンプレートの詳細
S3
データを集約するS3を準備します。
データごとにイベント通知を利用してキューを発行します
SQS
S3イベント通知で発行されたキューを管理します。
Glue Crawler
集約したデータをSQSのキューを元に読み取ります。
Glue Table
Glue Crawlerで読み取り対象のデータを準備します。
今回は私が使用するデータをもとに作成をしています。
使ってみる場合は以下の部分に使いたいデータの構造を設定してみてください。
StorageDescriptor:
InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Columns:
- Name: aws_account_id
Type: string
- Name: company_name
Type: string
- Name: signup_id
Type: int
- Name: discount_rate
Type: double
Location: s3://adv-2024-accelarating-crawler/user/
SerdeInfo:
Parameters: { "serialization.format": "1" }
SerializationLibrary: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
PartitionKeys:
- Name: payer_aws_account_id
Type: string
- Name: year
Type: string
- Name: month
Type: string
- Name: create_date
S3イベント通知の設定
イベント通知の設定はCloudFormationに記述すると循環参照が発生するため、Cloudformation実行後にAPIで設定します。
CloudFormationにLambdaでカスタムリソースを作成して実行する形式でも良いです。
$ aws s3api --profile xxx put-bucket-notification-configuration --bucket adv-2024-accelarating-crawler --notification-configuration file://s3config.json
s3config.json
{
"QueueConfigurations": [
{
"Id": "adv_2024_glue_crawler",
"QueueArn": "arn:aws:sqs:ap-northeast-1:xxx:adv_sqs_queue",
"Events": [
"s3:ObjectCreated:*"
],
"Filter": {
"Key": {
"FilterRules": [
{
"Name": "Prefix",
"Value": "user/"
}
]
}
}
}
]
}
実際に動かす
S3バケットにデータをアップロードします。S3に移動後、SQSが発行されます。
SQSを確認するとキューが溜まっていると思います。
その後クローラーを実行すると、1回目の実行はSQSが消費されずに実行されます。
CloudWatch Logsを確認すると以下のようなメッセージが表示されているはずです。
INFO : The crawler is configured to crawl changes identified by Amazon S3 events, but the current crawl is running in listing mode.
2回目の実行からはSQSが消費されます。今回は以下のようなメッセージが表示されているはずです。
INFO : The crawl is running by consuming Amazon S3 events.
最後にAthenaでクエリを実行すると、データが取り込まれていることがわかります。
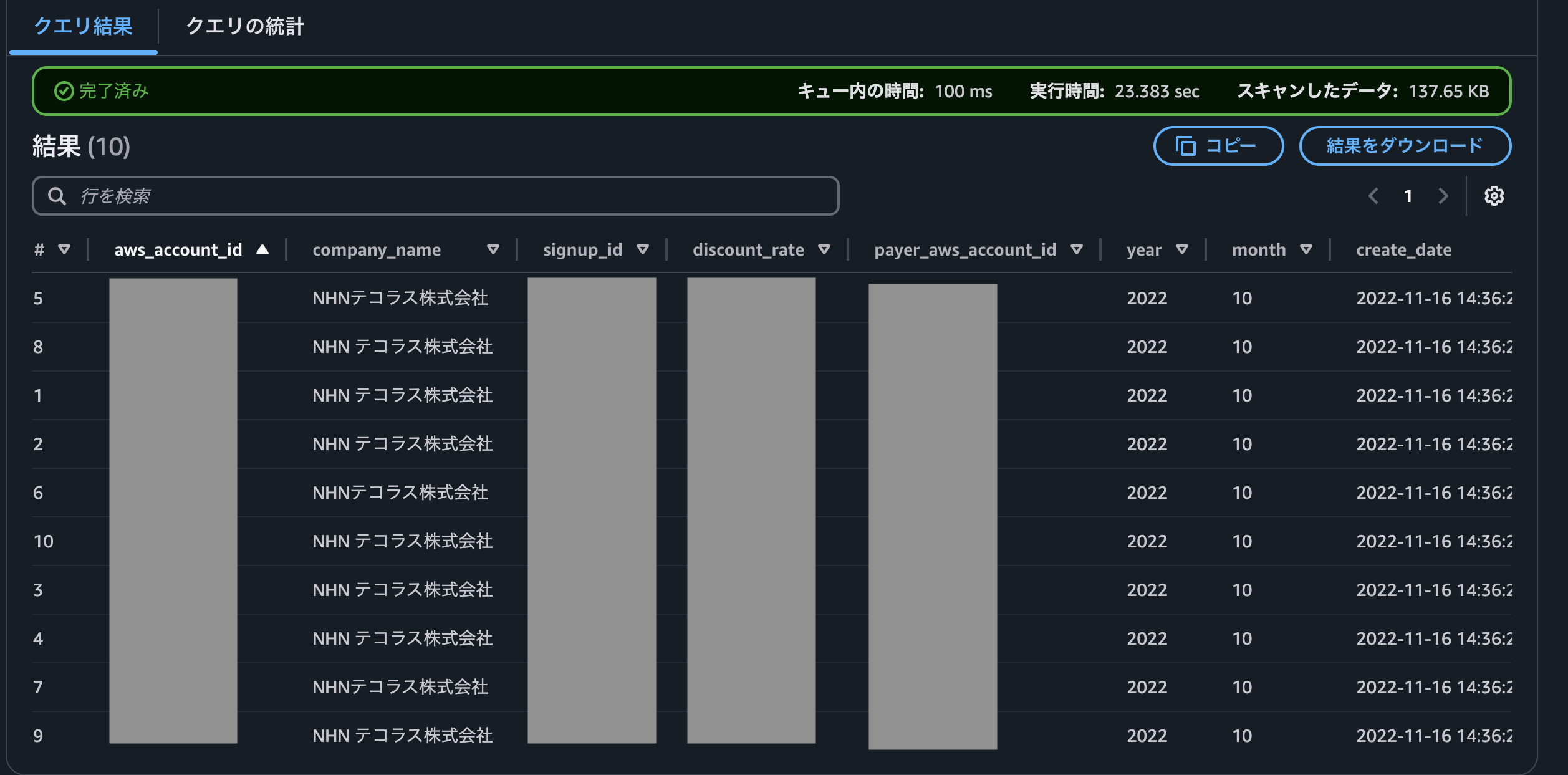
全体クロールと加速クロールを比較する
加速クロールのときに準備したデータを対象に全体クロールを実行しました。
結果は以下になりました。
| 初回実行 | 2回目 | |
|---|---|---|
| 全体クロール | 7分37秒 | 6分17秒 |
| 加速クロール | 7分13秒 | 2分29秒 |
初回実行は加速クロールも全体クロールを行うため、実行時間に差はありません。
2回目以降は、実行時間が全体クロールと比べて半分以下になっています。
またコストと直結するDPU hoursという値も比較してみます。DPU hoursは1時間ごとに使用したクローラーの性能の量を表した値で、これが大きいほどコストが高くなります。
| 初回実行 | 2回目 | |
|---|---|---|
| 全体クロール | 0.286 | 0.289 |
| 加速クロール | 0.273 | 0.050 |
全体クロールは常に全体を読み取っているためコストは一定ですが、加速クロールは2回目以降は1/5以下削減されていることがわかります。
まとめ
今回はあらかじめGlue Data Catalogにテーブルを登録した状態で加速クロールを使う方法を説明しました。加速クロールを利用するとテーブルを定義した状態でも増分データのみを読み込むことで、実行時間とコストが削減されます。
しかしSQSやS3イベント通知設定など他の設定も増えるため全体クロールや増分クロールの上位互換というわけではありません。そのため利用したいプロジェクトの方針に合うかどうかの検討が必要になります。もし目的に合っているのであれば一度検証してみる価値はあると思います。
(補足) 全体クロールのテンプレート
S3、S3に設置したデータ、Glueのデータベース、は加速クロールのものを利用しています。
AWSTemplateFormatVersion: "2010-09-09"
Resources:
# IAM ROle
CrawlerRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "glue.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSQSFullAccess
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
- !Ref CrawlerPolicy
# IAM Policy
CrawlerPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
PolicyDocument:
Version: '2012-10-17'
Statement:
-
Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::adv-2024-accelarating-crawler/user/*
# crawler
GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: adv_2024_glue_crawler_all
Role: !GetAtt CrawlerRole.Arn
Targets:
CatalogTargets:
- DatabaseName: adv_2024_glue_db
Tables:
- !Ref GlueTable
SchemaChangePolicy:
UpdateBehavior: "LOG"
DeleteBehavior: "LOG"
# Glue Table
GlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: adv_2024_glue_db
TableInput:
Name: adv_user_crawl_all
TableType: EXTERNAL_TABLE
Parameters: {"classification": "parquet"}
StorageDescriptor:
InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Columns:
- Name: aws_account_id
Type: string
- Name: company_name
Type: string
- Name: signup_id
Type: int
- Name: discount_rate
Type: double
Location: s3://adv-2024-accelarating-crawler/user/
SerdeInfo:
Parameters: { "serialization.format": "1" }
SerializationLibrary: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
PartitionKeys:
- Name: payer_aws_account_id
Type: string
- Name: year
Type: string
- Name: month
Type: string
- Name: create_date
Type: string

2018年新卒入社。エンジニア。フロントエンド&サーバサイドを担当。 Vue.js, Ruby on Rails, Ruby, Javaを主に使用する。 会社では全力で働き、家では全力で遊ぶ。


Recommends
こちらもおすすめ
-

Auto Scalingで起動テンプレートに更新をかけずにAMIを更新する方法
2024.12.20
-

AWS GlueとAmazon Machine Learningでの予測モデル
2017.12.17
-

NHN テコラス Advent Calendar 2024 を振り返る
2024.12.26


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16