推薦システムの基本的な評価指標について整理してみた
2017.6.16

はじめまして、データサイエンスチームの t2sy です。
私が所属しているデータサイエンスチームでは、Python・Rなどを用いてデータ分析を行っています。また、Apache Sparkを用いた機械学習基盤を開発しており、中でも推薦システムでは、購買などの周期性を考慮した行列分解手法による推薦アルゴリズムを実装した新機能を近日リリース予定です。
この記事では、推薦システムの開発で用いている以下の基本的な評価指標についてご紹介した上で、MAP と GMAP の簡単な比較をご紹介します。推薦の多様性、セレンディピティやABテストについてはこの記事では触れません。
- Recall
- Precision
- F-measure
- AP
- nDCG
- MAP
- GMAP
再現率と適合率
情報推薦と情報検索には類似性があり、情報検索における情報フィルタリングが一種の情報推薦とも考えることができます。従って、推薦システムの評価に再現率や適合率といった良く知られている評価指標を用いることができます。
適合文書の集合を A、 システムが推薦した文書の集合を B とした場合、再現率 (Recall) と適合率 (Precision) は以下で表せます。
集合を図示してみるとより再現率と適合率の関係がイメージし易くなります。
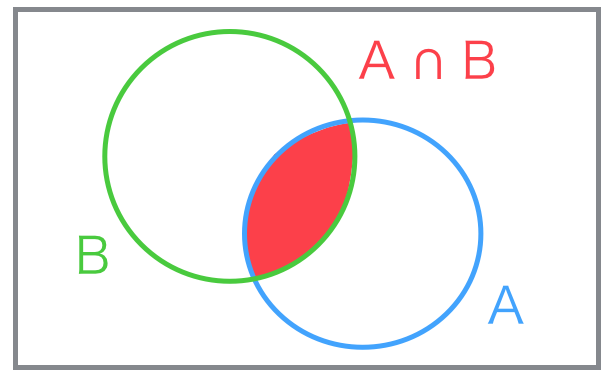
推薦システムにおいて再現率は推薦漏れの少なさ、適合率は推薦誤りの少なさに対応します。
再現率と適合率は一般にトレードオフの関係にあり、総合的な判断をしたい場合には2つが統一された評価指標があると便利です。統一された指標には E-measure や F-measure があります。
F-measure は以下で表され、再現率と適合率のバランスのパラメータβ が 1 の場合に再現率と適合率の調和平均となります。これは F1 と呼ばれ広く知られています。
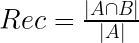


ランク付けされた推薦の評価指標
再現率や適合率は順序を考慮しない評価指標で、ランク付けされた推薦を評価する場合はその順序性を考慮する必要があります。
順序性を考慮した代表的な評価指標として 平均適合率 (Average Precision) があります。
ランク付けされた推薦において適合文書が見つかる度にその位置での適合率を求め、その算術平均を取った値が AP となります。R は適合文書の数です。
式中の I(r) は r位が適合文書の場合 1 、そうでない場合は 0 となる関数です。従って、適合文書の場合にのみ、その位置での適合率 Prec(r) を計算することに対応します。
平均適合率は単純に適合したか否かのみを考えるので二値適合性に基づく評価基準です。
より実際の推薦の評価では多くの場合、高く適合する高適合や部分的に一致する部分適合など適合性の度合いを考慮する多値適合性に基づく評価基準を用いるのが適切と考えられます。
nDCG (normalized Discounted Cumulated Gain) は多値適合性に基づく評価指標で、適合度に応じた価値を利得 (gain) として考え、ランクが下位になるほどその価値を下げる減損利得 (discounted gain) を導入し、その累積和を正規化した値です。
DCG (Discounted Cumulated Gain) は以下で表せます。g(r)はr位における利得です。
IDCG (Ideal DCG) を理想的推薦における減損利得の累積和としたとき、正規化された nDCG は以下となります。
上記以外の多値適合性に基づく評価指標に、平均適合率を拡張した Q-measure や GAP (Graded Average Precision) などがあります。
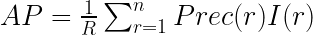
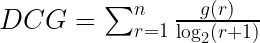
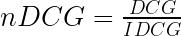
推薦システムの評価指標
AP や nDCG を用いることでランク付けされた推薦を評価することができますが、推薦システムを評価する場合、ある特定のユーザに対する推薦だけでなく複数のユーザに対する平均的な良さで評価する必要があります。
MAP (Mean Average Precision) はすべてのユーザのランク付き推薦に対して AP を求め、ユーザ集合に対して算術平均した値です。
MAPは情報検索における有名なワークショップTRECのコミュニティでも標準的に使用されています。
一方、できるだけ多くのユーザにある程度適合する推薦を提示したい場合 MAP の上下だけに着目しているだけでは不十分な場合があります。
このような場合に使える評価指標のひとつに GMAP (Geometric Mean Average Precision) があります。GMAP は名前からも想像できるように幾何平均を用います。
上記式を便宜上、変形した式が以下となります。
あるユーザへの推薦で上位 n 件の内、適合文書が一つもない場合を考えます。このとき AP + ε が非常に0に近い値となり自然対数の計算で大きな負の値を返すことから、このような推薦を提示するシステムをMAPと比べより低く評価します。
上位10位までのように測定長が短い場合、MAP や GMAP の値は不安定になりやすい傾向があることに気をつける必要があります。
その他のシステムの評価指標として、不完全性なテストコレクションから真の平均適合率を推定する infAP (inferred Average Precision) などがあります。

![GMAP = \sqrt[n]{\prod_{n} AP_{n}}](https://s0.wp.com/latex.php?latex=GMAP+%3D+%5Csqrt%5Bn%5D%7B%5Cprod_%7Bn%7D+AP_%7Bn%7D%7D+++&bg=ffffff&fg=000&s=3&c=20201002)
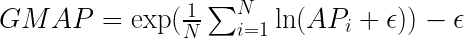
MAPとGMAPを比較してみる
Apache Spark には推薦システムや検索システムの評価指標として、org.apache.spark.mllib.evaluation.RankingMetrics に前述した precision や nDCG, MAP が実装されています。今回、MAP 実装に倣い GMAP を書いてみました。ε の値は 0.00001 としています。
lazy val geometricMeanAveragePrecision: Double = {
val e = 0.00001
val logAP = predictionAndLabels.map { case (pred, lab) =>
val labSet = lab.toSet
if (labSet.nonEmpty) {
var i = 0
var cnt = 0
var precSum = 0.0
val n = pred.length
while (i < n) {
if (labSet.contains(pred(i))) {
cnt += 1
precSum += cnt.toDouble / (i + 1)
}
i += 1
}
ln((precSum / labSet.size) + e)
} else {
ln(e)
}
}.mean()
exp(logAP) - e
}
一部のユーザに極端に悪い推薦を返すような推薦システムをGMAPが検出できるかを、2つの簡単な人工データに対して MAP と GMAP を比較することで確認してみます。
まず、ある推薦システム (M1) が以下のような10人のユーザに5つの推薦を提示し、その内1つから2つが適合文書である場合を考えます。
List の各要素はユーザを表し2つの Array から成る Tuple型となっています。左の Array がシステムが提示した推薦文書ID、右の Array が適合文書IDです。
val predictionsAndLabels = List(
(Array("a", "h", "j", "l", "p" ), Array("a", "b", "c")),
(Array("t", "b", "f", "h", "k" ), Array("a", "b", "c")),
(Array("x", "b", "d", "c", "a" ), Array("a", "b", "c")),
(Array("f", "b", "c", "d", "y" ), Array("d", "e", "f")),
(Array("a", "b", "c", "d", "e" ), Array("d", "e", "f")),
(Array("p", "e", "m", "n", "f" ), Array("d", "e", "f")),
(Array("h", "i", "a", "c", "e" ), Array("g", "h", "i")),
(Array("o", "i", "g", "h", "k" ), Array("g", "h", "i")),
(Array("a", "g", "e", "v", "x" ), Array("g", "h", "i")),
(Array("z", "j", "a", "s", "q" ), Array("j", "k", "l"))
)
次に、別の推薦システム (M2) では最後のユーザにだけ適合文書が1つも含まれていない推薦を提示したとします。
val badPredictionsAndLabels = List(
(Array("a", "h", "j", "l", "p" ), Array("a", "b", "c")),
(Array("t", "b", "f", "h", "k" ), Array("a", "b", "c")),
(Array("x", "b", "d", "c", "a" ), Array("a", "b", "c")),
(Array("f", "b", "c", "d", "y" ), Array("d", "e", "f")),
(Array("a", "b", "c", "d", "e" ), Array("d", "e", "f")),
(Array("p", "e", "m", "n", "f" ), Array("d", "e", "f")),
(Array("h", "i", "a", "c", "e" ), Array("g", "h", "i")),
(Array("o", "i", "g", "h", "k" ), Array("g", "h", "i")),
(Array("a", "g", "e", "v", "x" ), Array("g", "h", "i")),
(Array("z", "x", "c", "q", "p" ), Array("j", "k", "l")) // bad recommendation
)
M1、M2に対する MAP と GMAP は以下のようになりました。
| MAP | GMAP | |
|---|---|---|
| M1 | 0.369 | 0.320 |
| M2 | 0.352 | 0.121 |
M1の推薦結果に対して MAPが 0.369、GMAP 0.320 となりました。MAP に対して GMAP はやや低い値ですが大きくは変わらない値と言えそうです。
一方、M2の推薦結果に対しては MAP は 0.352、GMAP が 0.121 となりました。MAPが 約0.02 低下したのに対して、GMAP は 約0.20 と大きく低下したことから、GMAP は一部のユーザに極端に悪い推薦を提示する推薦システムの検出に向いておりシステムの性能改善に役立つと考えられます。
おわりに
今回は推薦システムにおける基本的な評価指標をご紹介し、その中でロバストな推薦システムの開発に役立つ GMAP を Apache Spark に実装し簡単なデータで比較を行いました。
推薦システムの開発では、目指している方向性に対し適切な評価指標を用いて継続的にパラメータチューニングなどの改善を行うことが重要であると思います。
今回、紹介しきれなかった推薦システムの評価に関する内容として、統計的検定による2つ以上のシステム比較や、テストコレクションを用いた評価があります。
本記事を書くにあたり参考にさせて頂いた情報アクセス評価方法論では、これらの内容にも触れていますので興味を持たれた方は是非手にとっていただければと思います。
参考文献
1. Extending Average Precision to Graded Relevance Judgments
2. A Theoretical Analysis of NDCG Ranking Measures
3. Inferred AP : Estimating Average Precision with Incomplete Judgments
4. On GMAP: and other transformations.
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
2016年11月、データサイエンティストとして中途入社。時系列分析や異常検知、情報推薦に特に興味があります。クロスバイク、映画鑑賞、猫が好き。
Recommends
こちらもおすすめ
-

機械学習の受託案件を通じて気づいた5つのこと
2019.3.8
-

5分でわかる、1時間でできる、 OSSコントリビューション
2017.10.23
-

社内エンジニア読書会の進め方 ーAI・機械学習チーム編ー
2019.4.4


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15