Amazon Personalizeを活用した記事推薦システムを自社ブログに導入した話(1)

こんにちは。データサイエンスチームの t2sy です。
2019年10月7日にテックブログに Amazon Personalize をはじめとする機械学習を用いた記事の推薦機能を追加しました。この記事では、推薦システム導入の背景と構成、設計時に意識した点について紹介します。

推薦システム導入の背景
弊社テックブログは2015年6月に最初の記事が投稿されて以降、現在までに多くの記事が投稿されてきました。
以下の図は、弊社テックブログの累積記事数の推移です。累積記事数のため単調増加していますが、毎年12月は2016年を除くと Advent Calendar 実施のため記事数が大幅に増えていることがわかります。
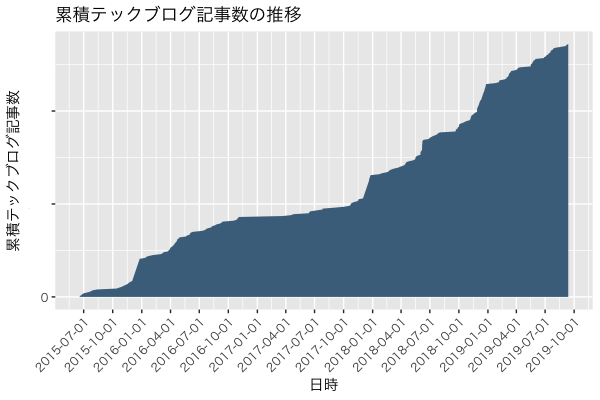
記事数がある程度の数まで増えたため、閲覧中の記事と関連性の高い記事を表示する推薦機能のニーズが生まれてきました。
今回の推薦機能を追加する以前も、各記事ページの下部にオススメ記事を表示していましたが、その選択方法は、同一タグ・カテゴリ・投稿者の記事からランダムに選択するというシンプルなものでした。
そこで、閲覧履歴や記事の内容から機械学習を用いた方法により関連性の高い記事を表示することで回遊率を向上できるのでは、と考え推薦システムの導入を8月下旬に提案しました。
目標は回遊率の向上になるのですが、同時に、記事の投稿者にとっても自身が執筆した記事の PV が増えることで、記事を執筆するモチベーションの向上に繋がり、回遊率向上と記事数増加の良い循環が生まれることを密かに期待しています。
また、Amazon.com の推薦で使われている技術と同じ技術で個人にカスタマイズされた推薦を作成できる AWS のサービス Amazon Personalize が、2019年6月から一般利用可能となりました。弊社テックブログでも Amazon Personalize の機能や使い方について計6回の連載でご紹介してきました。そのため、今回の記事推薦機能の追加にあたり Amazon Personalize を活用することは自然な選択でした。
Amazon Personalize の機能や使い方は以下の連載記事をご覧下さい。

推薦システムの構成
推薦システム全体の構成は以下となります。

推薦システムの中心となる Recommendations API Gateway はテックブログサーバからの API リクエストに対して、上流の API から取得した推薦のリストを統一された形式に変換した上でテックブログサーバに返します。
現在、Recommendations API Gateway は以下の API から推薦を取得しています。
- Amazon Personalize: 個人にカスタマイズした推薦を作成できる完全マネージド型の AWS のサービス
- Collaborative Filtering Based Recommender: Apache Spark MLlib を活用した自社レコメンダー
- Content-based Recommender: 記事の内容に基づき主に自然言語処理の技術を用いて類似性の高い記事を返すレコメンダー
また、図中の Model Management Tool は配信対象となるモデルのID発行や、配信回数の設定、配信登録/解除などの管理を行う CLI (Command Line Interface) ツールです。
推薦システムの設計で意識した点
推薦システムの設計で意識した点は以下の3つです。
- インターフェイスをできるだけシンプルにする
- マネージドサービスを活用する
- 試したいモデルをすぐ試せるようにする
インターフェイスをできるだけシンプルにする
テックブログサーバの運用管理・保守は、私が所属するデータサイエンスチームでなく他部署が行なっています。推薦機能はあくまでテックブログの付加機能のひとつであるため、他部署の作業ができるだけ発生しないように意識しました。
具体的には、テックブログサーバは推薦を取得するために Recommendations API Gateway に API リクエストを投げますが、各種レコメンダーのモデル選択や選択されたモデルに対する API の実行、配信モデルの制御などは Recommendations API Gateway に一任する仕組みとしています。
従って、テックブログサーバから見ると背後にある個々のレコメンダーを意識する必要がないため、複雑な API リクエストを構築せずに済みます。その結果、コード変更も最小限に留めることができます。
また、テックブログサーバでは Fluentd を用いて日次でアクセスログを Amazon S3 にアップロードする仕組みが既にありました。この S3 上のデータを活用し、 AWS Lambda でアクセスログを学習用データとして整形し、弊社レコメンダーや Amazon Personalize に学習データとして入力しています。
現在のアクセス量では AWS Lambda の最長実行時間 15 分以内に余裕をもって整形とデータ入力処理を終えていますが、アクセスログのサイズに応じて適した構成へと見直していく予定です。
マネージドサービスを活用する
マネージドサービスが普及した現在では、その利点について改めて言及する必要もないかもしれませんが、一般的にマネージドサービスを利用することで運用管理・保守にかかるコストを軽減することができます。
Recommendations API Gateway にはA/Bテストの機能がありますが、モデルの配信設定などの状態は Docker 上で保持せずマネージドサービスである Amazon DynamoDB で保持しており、DB の運用管理・保守にかかる負担を軽減できます。
システムの運用監視においては、 Amazon CloudWatch Alarms と Amazon SNS を使うことで、監視対象のメトリクスが期間内に指定した閾値を超えた場合に通知する仕組みを簡単に作成することができます。
また、Amazon SageMaker の自動モデルチューニングやモデル追跡機能を利用することで機械学習モデルの管理を省力化でき、機械学習モデルの開発により専念することができます。
試したいモデルをすぐ試せるようにする
データサイエンスチームでは、機械学習の論文を読んで再現実験を行ったり、論文中の実験で使用されたデータとは異なる領域のデータに適用して評価を行ったりすることがあります。そのため、情報推薦や自然言語処理のアルゴリズムをオンライン上で手軽に試したり比較・評価できる環境があると便利です。 そこで、Content-based Recommender は Amazon SageMaker 等で作成したモデルの予測結果を指定された S3 上に決められた形式で配置するとすぐに配信できる仕組みとしました。
余談ですが、Content-based Recommender の API サーバは Go で書いており、実装に go-swagger/go-swagger を使用しました。go-swagger を用いると REST API を宣言的に記述、必要なコードの大部分を自動生成することができます。その結果、API 仕様と実装の乖離を少なくすることができ、開発効率を上げることができました。
おわりに
この記事では、テックブログに機械学習を用いた推薦システムを導入した背景と構成、設計時に意識した点について紹介しました。既存のテックブログサーバとなるべく疎結合になるようにシステム構成を考えましたが、今後も定期的に構成を再考し、必要に応じて改善していきたいと思います。次回は、推薦システム導入後のA/Bテストの経過について書く予定です。


2016年11月、データサイエンティストとして中途入社。時系列分析や異常検知、情報推薦に特に興味があります。クロスバイク、映画鑑賞、猫が好き。


Recommends
こちらもおすすめ
-

Apache Sparkのパーティション分割について
2022.12.29
-

画像分類の機械学習モデルを作成する(1)ゼロからCNN
2018.4.17
-

JDLA「G検定」試験の合格体験記
2018.12.12
-
BERTの学習済みモデルを使ってみる
2018.11.9


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16