Apache Beamのオーバーヘッドについて調べてみた

こんにちは。データサイエンスチームのtmtkです。
この記事では、Apache Beamを紹介します。また、Apache Beamを使うことによるオーバーヘッドを簡単に観察してみます。
Apache Beamとは
[公式サイト]によると、「Apache Beamとはバッチデータ並列処理パイプラインとストリーミングデータ並列処理パイプラインのどちらも定義するための、オープンソースの統合モデルである」だそうです。具体的には、
- プログラム中でApache Beam SDKのクラスをimportし、
- Apache Beam SDKのAPIを用いてデータ処理プログラムを作成すると、
- 作成したプログラムをApache Spark, Apache Flinkなどの上で実行できる
というものです。
特徴としては、
- Dataflowモデルに基づいてデータ処理プログラムを作成することができる(参考:[Dataflow/Beam と Spark: プログラミング モデルの比較])
- Batchデータ処理とStreamingデータ処理のどちらも統一的な書き方でプログラムを書くことができる
- ひとたびApache Beamでプログラムを書いてしまえば、そのプログラムをいろいろなデータ処理エンジン(Apache Apex, Apache Flink, Apache Spark, Google Cloud Dataflow)上で動かすことができる。(これらのデータ処理エンジンをBeamではランナー と呼んでいます。)
という点があります。
歴史的には、Google Cloud Dataflow SDKがオープンソース化されたという経緯があるようです。(参考:[なぜ Apache Beam なのか : Dataflow のライバル参入を促す理由])
言語としてはJavaとPythonに対応していますが、Pythonはほとんどのランナーに対応していないため、以降はJavaを使います。
Apache Beamの導入手順
Beamを試してみるには、[公式のドキュメント]のとおりにしていけばいいです。すぐに試せると思います。
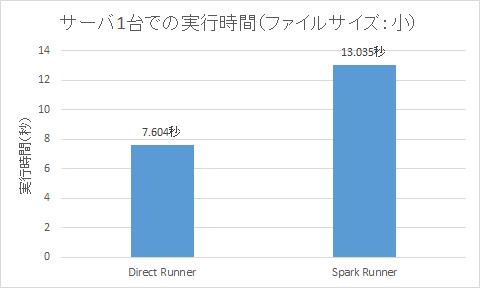
サーバ1台でのDirect RunnerとSpark Runnerの比較
分散環境で試してみる前に、サーバ1台上で、Direct RunnerとSpark Runnerについて性能の比較をしてみます。Direct Runnerというのは開発・デバッグ・テスト用にApache Beamに付属しているランナーです。サーバは16コア、メモリ16GBのCentOS7仮想マシンです。
Direct Runnerでの実行
上で示した公式ドキュメントに従ってコンパイル後、
mvn exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--inputFile=pom.xml --output=counts" -Pdirect-runner
としてDirect Runnerで実行すると、実行時間は
Total time: 7.604 s
となりました。
Spark Runnerでの実行
コンパイル後、
mvn exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner
としてSpark Runnerで実行すると、実行時間は
Total time: 13.035 s
となりました。
コンピュータ1台での環境では、Sparkのオーバーヘッドの分だけDirect Runnerのほうが高速なようです。
Hadoopクラスタ上での性能を比較する
Beamは分散処理システム上で動かすためのものなので、Hadoopクラスタ上で動かして性能を評価してみます。Hadoopクラスタは、4コアCPU、16GBメモリの6台のデータノードを持っています。
事前準備
- 先ほどは
pom.xmlを対象にWordCountを実行しました。今回はpom.xmlより大きなファイルでWordCountを実行したいので、gs://apache-beam-samples/shakespeare/*からShakespeareのテキストファイルをダウンロードしておきます。 - ダウンロードしたファイル群をSpark clusterのHDFS上にコピーしておきます。PATHを
hdfs://mycluster/user/hoge/shakespeare/*.txtとします。 - 公式ドキュメントの[Quickstart]と同じようにWordCountプロジェクトをダウンロードします。
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.1.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
Direct Runner上で実行
- 比較対象として、Hadoopクラスタ上で動作させる前に、コンピュータ1台でDirect Runnerで実行してみます。
- DirectRunnerがHDFSにアクセスできるように、
pom.xmlに依存を追加します。spark-runnerのところから、org.apache.beam:beam-sdks-java-io-hadoop-fifle-system:${beam.version},org.apache.spark:spark-streaming_2.10:${spark_version},com.fasterxml.jackson.module:jackson-module-scala_2.10:${jackson.version}の3つの依存をdirect-runnerにコピーします。
$ cd word-count-beam/ $ vim pom.xml 編集
- コンパイル・実行します。(実行する前に$HADOOP_CONF_DIRが設定されているか確認します。)
cd word-count-beam/ mvn compile -Pdirect-runner mvn exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--inputFile=hdfs://mycluster/user/hoge/shakespeare/* --output=counts" -Pdirect-runner
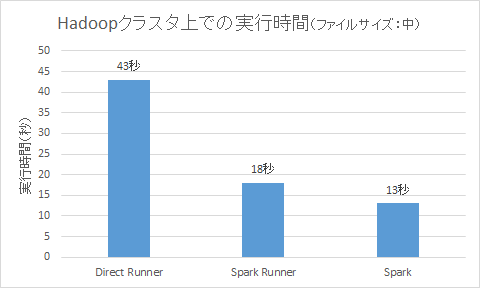
- 実行結果は次のようになりました。
Total time: 43.172 s
Spark Runner上で分散処理
- 次に、Hadoopクラスタ上のSpark RunnerでWordCountを実行してみます。(Spark2で実行するとエラーが出るので、Spark 1.6.xで実行することに注意します。SPARK_HOMEをSpark1.6のものに忘れずに変えるようにします。)
mvn package -Pspark-runner spark-1.6.3-bin-hadoop2.6/bin/spark-submit --class org.apache.beam.examples.WordCount target/word-count-beam-bundled-0.1.jar --output=counts --inputFile=hdfs://mycluster/user/hoge/shakespeare/* --runner=SparkRunner
- 実行結果は次のようになりました。(Mavenによる実行ではないので、実行時間はストップウォッチによるおおよその計測になります。)
実行時間:約18秒
- 分散処理による高速化が生きてますね。
Beamを介さないSpark上での分散処理
- 同等のプログラムをBeamを介さずに直接Sparkで実行してみます。
org.apache.beam.examples.WordCountと[Apache Spark Examples]を参考に、以下のようにプログラムを書きます。
src/main/java/com/example/WordCount.java
package com.example;
import org.apache.spark.api.java.*;
import org.apache.spark.SparkConf;
import java.util.Arrays;
import scala.Tuple2;
public class WordCount{
public static void main(String[] args){
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("Word Count"));
JavaRDD<String> textFile = sc.textFile("hdfs://mycluster/user/hoge/shakespeare/*");
JavaRDD<String> counts = textFile
.flatMap(s -> Arrays.asList(s.split("[^\\p{L}]+")))
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b)
.map(x -> x._1 + ": " + x._2);
counts.saveAsTextFile("file:///home/hoge/counts");
}
}
pom.xmlを以下のようにします。
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<version>0.1</version>
<artifactId>test</artifactId>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.3</version>
</dependency>
</dependencies>
</project>
次のコマンドでWordCountを実行します。
~/local/spark-1.6.3-bin-hadoop2.6/bin/spark-submit --class com.example.WordCount target/test-0.1.jar
- 実行結果は次のようになりました。
実行時間:約13秒
Beamを介したことによるオーバーヘッドが約5秒あることがわかります。
まとめ
Apache Beamは既存のSpark環境に簡単に導入できることがわかりました。また、ネイティブのSparkアプリケーションと比べて若干のオーバーヘッドがあることがわかりました。
Dataflowモデルでのプログラミングや複数ランナーで実行可能であることなど、Apache Beamには優れた点がありますが、代償としてのオーバーヘッドに注意する必要がありそうです。

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

FIT2018 第17回情報科学技術フォーラム参加報告(1)FIT2018概要編
2018.9.20
-

AWS GlueとAmazon Machine Learningでの予測モデル
2017.12.17
-

機械学習を学ぶための準備 その5(行列のいろいろ)
2015.12.19
-

機械学習 曲線フィッテングについて おまけ?編
2016.4.28
-

NHN FORWARD 2019 参加レポート-AI/機械学習セッションの紹介-
2019.12.4

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16