NHN FORWARD 2019 参加レポート-AI/機械学習セッションの紹介-

こんにちは。データサイエンスチームの t2sy です。
2019年11月27日に韓国ソウル特別市江南区で開催された NHN FORWARD に弊社から私を含め2名が参加しました。この記事では、私が NHN FORWARD で聴講したセッションの中で、AIや機械学習に関するセッションについて紹介します。
当日のセッションは全て韓国語で行われましたが、私は韓国語がほとんどわからないため通訳さんからの情報を頼りにしました。従って、細部の情報が不足していたり不正確である可能性がある点をご了承下さい。
「Recommendation Systems: Concepts, Techniques, and Research Results」
本セッションは Hanyang University でビッグデータや機械学習の研究を行なっている Sang-Wook Kim 氏による招待講演です。
セッションは推薦システムの概要から始まりました。近年では Amazon や Netflix を例として多くの企業が推薦システムを活用していることが紹介され、推薦システムの分類として以下の4つが挙げられました。
- Content-based approach
- Collaborative filtering (CF) approach
- Trust-based approach
- Hybrid approach
上記の内、広く使われている Collaborative filtering (CF) に関する講演者らの研究紹介が行われました。CF を実現する手法は Matrix Factorization や Deep Learning などがあります。
Told You I Didn’t Like It”: Exploiting Uninteresting Items for Effective Collaborative Filtering
最初に、紹介された研究は「“Told You I Didn’t Like It”: Exploiting Uninteresting Items for Effective Collaborative Filtering」です。
従来の CF 法は主にユーザにより与えられた ratings にしか着目していましたが、実世界の rating matrix では全体の 4 %しか評価が付けられたアイテムが存在しない場合があります。この研究の動機として、このような非常に疎な行列に対する CF 法は性能が上がらないという課題点が挙げられました。疎になる理由として、時間とお金の制約のためユーザが興味を持ち実際に購入/使用したアイテムは少数であることが考えられます。
本研究のアイデアは rating matrix の中で rating が付けられていないアイテム (i.e. unrated Items) に着目し、その値を推測することで CF 法の性能向上を図るというものです。
ユーザの嗜好を、アイテムを購入/使用する前のユーザのアイテムへの印象である pre-use preference と、アイテムを購入/使用した後のユーザのアイテムへの印象である post-use preference に分けます。
以下の表を例に、あるユーザの3つの映画に対する pre-use preference と post-use preference を考えます。
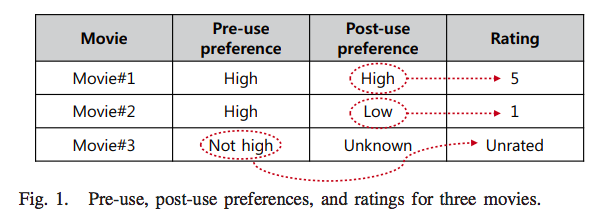
このユーザは Movie#1、Movie#2 に対して高い pre-use preference (i.e. interesting items) を示し、Movie#3 に対しては低い pre-use preference (i.e. uninteresting items) を示しています。従って、ユーザは pre-use preference の高い Movie#1、Movie#2 の映画を実際に観ます。鑑賞後、Movie#1 は面白かったため post-use preference は高く、それに対応する 5 という高い rating を付けます。また、Movie#2 は面白くなかったため、post-use preference は低く、それに対応する 1 という低い rating を付けます。一方で、Movie#3 は元々興味がない uninteresting items であるため、映画を観賞することはないので post-use preference は Unknown となります。
ベン図で関係性を整理すると以下になります。
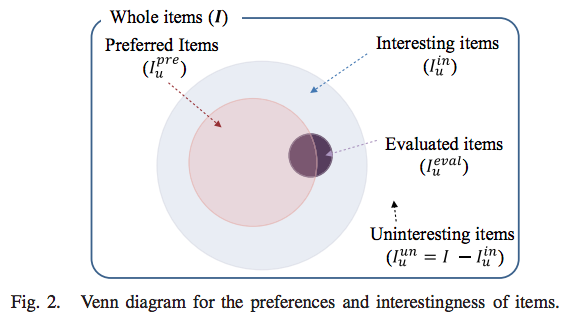
提案されたアプローチは unrated items から uninteresting items を推定し、対応する rating matrix の要素に 0 を代入した zero-injected matrix を作り、CF 法を適用するというものです。zero-injected matrix は元の rating matrix に対してより豊富な情報を持っていると考えられます。
本アプローチの全体像は以下です。
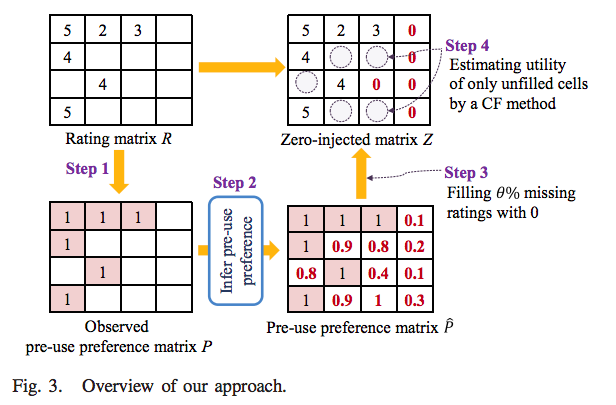
STEP 2 の pre-use preference の推定で、ユーザが既にアイテムを評価している場合は、そもそも興味があるのでアイテムを購入/使用したと考えられるため 1 を代入します。一方で、unrated items の pre-use preference の推定は簡単ではありませんが、OCCF (One-Class Collaborative Filtering) [1] のアイデアを活用し推定する方法を提案しています。
STEP 3 では、推定した pre-use preference スコアに基づき、uninteresting items を推測します。ここで、推定された pre-use preference スコアを順序付けし 0 を代入 (zero-injection) する下側の割合を決めるパラメータを 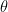
ユーザがアイテムを評価しておらず、かつ uninteresting items と推測される場合、行列の要素に 0 を代入します。これにより、得られた行列 zero-injected matrix に対して CF 法を適用します。
実験では ICF (item-based collaborative filtering)、SVD、SVD++ に対して提案されたアプローチを適用した場合に Precision, Recall, nDCG, MRR などの指標が顕著に改善されていることを報告しています。
このアプローチの利点として、uninteresting items は推薦リストから除外されることが期待でき、また zero-injected matrix は元の rating matrix よりも豊富な情報を持っているため性能向上が期待できます。さらに、ビジネスの現場では中々新しい提案は受け入れられにくいことがありますが、本アプローチは既存の CF 法に対して直交する手法のため、拡張が容易で受け入れられやすい点を挙げていました。
How to Impute Missing Ratings?: Claims, Solution, and Its Application to Collaborative Filtering
次に、紹介された論文は「How to Impute Missing Ratings?: Claims, Solution, and Its Application to Collaborative Filtering」です。
既存の CF における rating matrix への Data Imputation アプローチは、複数の値 (e.g. 1-5) で欠損している ratings を推測する方法と、単一の値 (e.g. 0) で欠損している ratings を推測する2つのグループに分類されます。前者はユーザとアイテムの特性を考慮できる一方、代入値は高くなる傾向があります。後者は、低い値で代入することができますがユーザとアイテムの特性を反映することはできません。前述した Zero-injection は後者に分類されます。この限界に対して、実世界のデータセットでの知見を通して Data Imputation アプローチが従うべき以下の3つの主張を提案しました。
- Claim 1: 欠損している ratings の多くは uninteresting items のため、多くの代入値は低い rating である必要がある
- Claim 2: interesting items の代入値は uninteresting items より高くなる必要がある
- Claim 3: 代入値はユーザがアイテムに与えることができる範囲内である必要である
この論文では、生成モデルである VAE (Variational Autoencoder) を用いてユーザとアイテムの特徴を抽出し、MLP (Multi-Layer Perceptron) で post-use preference を推定する方法を提案しています。このアプローチの全体像は以下です。
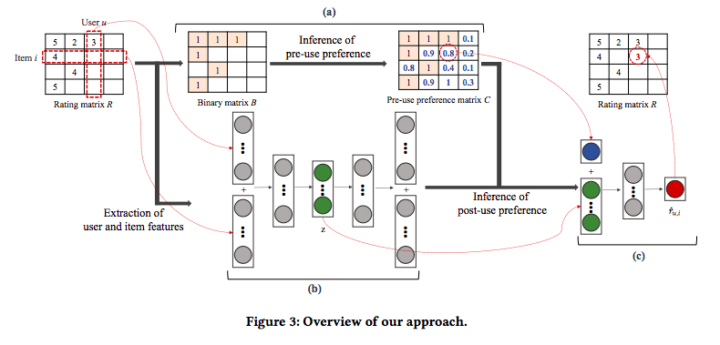
実験では提案アプローチにより MovieLens、CiaoDVD、Watcha の3つのデータセットに対して3つの主張を概ね満たすことを報告しています。
gOCCF: Graph-Theoretic One-Class Collaborative Filtering Based on Uninteresting Items
次に、紹介された論文が「gOCCF: Graph-Theoretic One-Class Collaborative Filtering Based on Uninteresting Items」です。
先程の unrated items に対する pre-use preference の推定では OCCF (One-Class Collaborative Filtering) [1] のアイデアが用いられました。
OCCF は one-class 設定の処理に特に適した CF 法のグループです。ユーザがアイテムに対して rating を付ける明示的フィードバック (Explicit Feedback) に対して、クリックやブックマークなどの行動履歴は暗黙的フィードバック (Implicit Feedback) であり、0 又は 1 で表現される場合 one-class 設定と呼ばれます。しかし、従来の OCCF 法はデータセットの疎性が高まる (i.e. many unrated items) につれて性能 (MRR) が低下するという課題がありました。
この課題に対して、本論文ではグラフ理論に基づく OCCF である gOCCF (graph-based OCCF methods) を提案しています。
このアプローチでは one-class 設定を positive preferences (i.e. interesting items) と negative preferences (i.e. uninteresting items) の binary-class 設定に変換します。
ユーザーとアイテムの二部グラフ (bipartite graph) で構成し、ユーザと interesting items の関係を表すグラフを positive graph 

gOCCF の全体像は以下です。
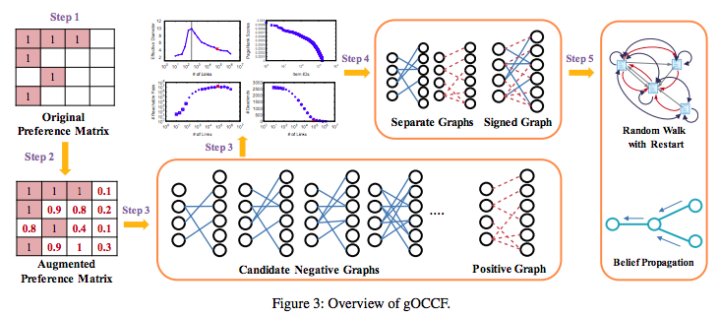
gOCCF は5つのステップで構成されています。
- ユーザ数を
、アイテム数を
、 rated item を
として preference matrix
とする
を利用してユーザの unrated item に対する関心の度合いを予測する
- 計算した関心の度合いや graph shattering theory、information propagation を考慮し、ユーザごとの uninteresting items を決める
- 得られた uninteresting items とユーザの関係、interesting items とユーザの関係をソーシャルネットワーク分析の観点からモデル化する
- モデル化されたグラフに対してソーシャルネットワーク分析を行い Top-N 推薦リストを得る
STEP 3 では
また、STEP 5 で、モデル化されたグラフに対して推薦リストを得るために RWR (random walk with restart) や確率伝播アルゴリズム (belief propagation) を用いることが提案されています。
論文では、MovieLens、Watcha、CiteULike の3つのデータセットに対して gOCCF の有効性を検証し、特に非常に疎なデータセットで従来法に比べて良い性能が得られたことを報告しています。
CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks
次に、紹介された論文が「CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks」です。
生成モデルである GAN (Generative Adversarial Networks) は画像生成や音楽生成を始めとして様々な分野で成功を収めています。GAN を情報検索や情報推薦の分野に応用するという研究には既に IRGAN [2] や GraphGAN [3] がありました。
先行研究のひとつである IRGAN では、Generator はユーザに関連性の高いアイテムのインデックスを生成しようと試みます。一方で、Discriminator は Generator が生成した模倣アイテムとユーザにとって本当に関連性の高いアイテム (i.e. ground truth) を識別しようと試みます。Generator では softmax function が使われ、Discriminator のスコア関数では sigmoid function が使われます。IRGAN の Discriminator は確率的勾配降下法で学習できますが、Generator は離散値 (インデックス) のサンプリングが必要なため policy-gradient based reinforcement learning [4] を用いて更新します。
本論文では、IRGAN や GraphGAN でのアイテムインデックスの生成アプローチでは限界がある点を指摘しています。GAN の訓練過程で、初期段階では Generator はほぼランダムにサンプリングを行い Discriminator のガイダンスを受けながら徐々に性能が向上していきます。しかし、訓練が進むと Generator は ground truth と同じアイテムをサンプリングすることが想定され、ラベルが混在する結果、 Discriminator の学習が混乱してしまう可能性があります。
本論文では、GAN の敵対的訓練における上記の課題を解決するために、Generator は離散的なサンプリングではなく、実数ベクトルである purchase vector を生成する方法、CFGAN フレームワークを提案しています。論文では、CFGAN の有効性について Watcha、Ciao、Movielens 100K、Movielens 1M の4つのデータセットを用いた実験で検証しています。
本セッションの最後では、大規模グラフの性質に応じて、グラフを効率的に処理するための技法を提案した RealGraph が紹介されました。既存の分散型グラフエンジンと比較して安価に良い性能が得られる利点が挙げられました。RealGraph について興味がある方は以下をご覧下さい。

「ハイパーパラメータチューニングでモデルの性能を改善する」
本セッションは、機械学習で重要なトピックであるハイパーパラメータチューニング、特に DNN (Deep Neural Network) における Random Search やベイズ最適化についての紹介という内容でした。
最初に、良いモデルを探すための最初の過程として訓練データの追加が挙げられました。しかし、多くの場合で訓練データに用いるためのラベル付けは人間が行う必要があり高コストです。
次に、ハイパーパラメータ探索に話が移りました。機械学習モデルのハイパーパラメータ最適化はブラックボックス最適化 (Black-Box Optimization) と考えられます。
最初の探索手法として Grid Serarch が挙げられました。Grid Serarch は探索範囲を格子状に取り、全ての格子点でメトリクスを計算し最良のハイパーパラメータを見つける手法です。これは、単純で分かり易い一方で計算時間がかかってしまうという問題があります。
Grid Serarch の問題点を改善する手法として Random Search とベイズ最適化 (Bayesian Optimization) が紹介されました。ベイズ最適化により効率的なハイパーパラメータの探索が可能となります。ベイズ最適化では最適化したい関数がガウス過程 (Gaussian process) に従うと仮定します。
スライド中で言及されていた Random Search やベイズ最適化、ガウス過程の文献は以下です。詳しい仕組みに興味のある方はご覧下さい。
- 「Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design」
- 「Random Search for Hyper-Parameter Optimization」
- 「A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning」
続いて、scikit-learn の GaussianProcessRegressor クラスを用いたベイズ最適化の実装例が解説されました。
最後に、ハイパーパラメータ最適化のために構築したシステムが紹介されました。
このシステムは、Kubernetes を用いたクラスタ構成になっており、複数のGPU サーバで並列処理が可能です。また、TensorBoard で学習結果を可視化できるようです。
Random Search とベイズ最適化の Accuracy の比較として、CIFAR-10 での Resnet-110、Resnet-56 モデルの実験結果が示され、ほぼ同程度の Accuracy となっていました。計算時間に関して、ベイズ最適化も並列化できる方法はあるものの Random Search は並列化が容易で計算時間の利点がある点が説明されました。
「初めての雰囲気そのまま: Music Mood Classification」
本セッションは、オンライン音楽サービス Bugs でユーザの状況に合ったムードの曲を推薦するために、曲のムードを Multi-Label Classification で予測する機械学習モデルを開発したという内容でした。
Bugs では、曲の推薦でこれまで Collaborative filtering (CF) を利用していましたが、曲のジャンルやタグを用いた Content-based filtering (CBF) に切り替えたようです。その後、ジャンルやタグのみでは曲に対する特徴が足りないという問題に直面し、音源から曲の embedding feature を抽出するというアプローチを取りました。このアプローチを選んだ背景には、音楽は聞きたい状況に応じて曲を選択することが多いという知見からのようです。ここで、ムードは “雰囲気” や “趣” を指します。
続いて、データセットの構築に関する話に移りました。1つの曲に対して以下の9つのラベルから1つ以上のラベルを割り当てます。最初の段階では、Thayer’s model や Russell’s Circumplex Model を参考にしたようです。(以下は、韓国語から訳した表現のためニュアンスが微妙に異なる可能性があります。)
- エキサイティング
- 穏やか
- 静かな
- 甘い
- 切ない
- 強い
- 柔らかい
- 明るい
- 暗い
データのラベリング作業は Bugs の編集者に依頼し、1曲ずつ聞いてラベリングを行ったようです。
次に、モデルアーキテクチャについて紹介がありました。
大まかには、MP3音源をスペクトログラム (Spectrogram) に変換し、多段の 1D-CNN で特徴量抽出を行い FNN (Feed-forward Neural Networks) に入力し分類結果を得るという構成でした。損失関数は Multi-Label Classification のため binary cross entropy でした。
モデルの試作段階では、音源の全てを使わず曲の中央あたりの30秒を利用したようです。この理由として、曲の最初や最後はフェードインやフェードアウトで上手くムードを捉えられない一方で、曲の中央あたりはサビがある可能性が高いため実際に性能が良かったためとのことでした。
また、スペクトログラムから抽出した特徴に加えてジャンルや歌手の性別などのメタ特徴を追加したり、Fine Tuning を行うことで性能を向上させることができたとのことです。
Recall や Precision、F1 Score によるモデルの定量的な評価だけでなく、定性的な評価として甘いムードと予測された曲が実際はヒップホップや暗い曲であったというモデルが予測に失敗するケースも紹介され、甘い曲のデータが少ない点や曲中の間が影響しているのではなどの考察が共有されました。
最後に、曲の一部分だけでなく全体を使うように改良したいなど今後の展望が述べられました。
スライド中で言及されていた文献は以下です。
- 「Convolutional Neural Networks for Sentence Classification」
- 「Transfer learning from pre-trained models」
「Hi Bugs. 私の声、聞こえるかい?: DNNボイストリガー開発記」
近年、Amazon Alexa や Siri、Google Assistant など音声アシスタントの機能を搭載したアプリケーションは身近となってきました。
本セッションは、オンライン音楽サービス Bugs のスマートフォンアプリにボイストリガー機能を実装した経験を通じて得られた知見の共有という内容でした。
ボイストリガーとは音声アシスタントを呼び出す時の始めのフレーズのことで、Amazon Alexa では「Alexa」というフレーズです。Amazon Alexa ではこのフレーズをウェイクワードと呼びます。
ボイストリガー機能を開発するにあたり、最初にトリガーワードを決める必要があり、発音のし易さや音節の数が多すぎると誤認識が増えることを踏まえて「Hi Bugs」を選んだようです。
セッションは、ボイストリガーを実現するための音声認識の構成要素から始まりました。音声認識の構成要素には音声分析、音響モデル、言語モデル、探索過程があります。
音声分析での特徴抽出には MFCC (Mel-Frequency Cepstrum Coefficients) 、音響モデルには HMM (Hidden Markov Model) の出力確率に DNN を用いた DNN-HMM、言語モデルには N-gram を用いたようです。また、探索過程では、Viterbiアルゴリズムにより観測された系列から最も尤もらしい状態の系列 (経路) を推測しています。使用したフレームワークは Kaldi、TensorFlow、PyTorch などです。
次に、音声データの収集についての話に移りました。
音声データの収集は時間がかかるため Bugs を利用しているユーザの年代を分析し、20代のユーザが利用の 50 %弱を占めることから、最初は20代のデータを集めることから始めました。
100人のデータで 84 %の精度でしたが、600人のデータで 98 %まで精度が向上したことでサービスインに踏み切ったようです。
データ収集の工夫として、最初に収集されたデータはクリーンなデータが中心でしたが、さらなる改良のためにノイズや誤認識を含むデータの収集が必要と考え、Bugs の利用シーンからラウンジや運転中、電車内、ショッピングモールなどの状況下のデータを収集し、訓練データに追加した点が挙げられました。また、方言を考慮するために音声データを入力する人の出身地をバラバラにしたとのことでした。
おわりに
この記事では、NHN FORWARD で聴講したセッションの中で、AIや機械学習に関するセッションを4つ紹介しました。
招待講演の「Recommendation Systems: Concepts, Techniques, and Research Results」では、実世界のデータへの適用を見据えた推薦システムの性能向上を図る研究が紹介されました。また、「ハイパーパラメータチューニングでモデルの性能を改善する」では Random Search とベイズ最適化の仕組みや比較が解説されました。さらに、「初めての雰囲気そのまま: Music Mood Classification」、「Hi Bugs. 私の声、聞こえるかい?: DNNボイストリガー開発記」では、実際のオンライン音楽サービスに、機械学習の機能を組み込む際に直面する様々な課題に対する試行錯誤と解決策が紹介されました。
最後に、会場で貰ったノベルティを紹介します。

参考文献
[1] Pan, R.; Zhou, Y.; Cao, B.; Liu, N. N.; Lukose, R.; Scholz, M.; and Yang., Q. 2008. One-class collaborative filtering. In Proc. of the IEEE Int’l Conf. on Data Mining (ICDM), 502–511.
[2] Jun Wang et al. 2017. IRGAN: A minimax game for unifying generative anddiscriminative information retrieval models. In ACM SIGIR. 515–524
[3] Hongwei Wang et al. 2018. GraphGAN: Graph representation learning withgenerative adversarial nets. In AAAI. 2508–2515.
[4] Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning. In Reinforcement Learning. Springer, 5–32.

2016年11月、データサイエンティストとして中途入社。時系列分析や異常検知、情報推薦に特に興味があります。クロスバイク、映画鑑賞、猫が好き。


Recommends
こちらもおすすめ
-

手を動かして GBDT を理解してみる
2019.5.24
-
ディープラーニングを使ったウェブアプリケーションをすばやく作る
2018.12.1


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16