BigQuery ML の Matrix Factorization で映画の推薦を行ってみる
2020.5.26

こんにちは。データサイエンスチームの t2sy です。
Google BigQuery は、Google が提供する高スケーラビリティでコスト効率に優れたサーバーレス型のクラウド データウェアハウス (DWH) です。BigQuery ML を使用すると標準 SQL クエリを用いて機械学習モデルを作成・実行できます。
2020/4/17 に BigQuery ML の Matrix Factorization (Beta) がリリースされました。
この記事では、 Using BigQuery ML to make recommendations from movie ratings のチュートリアルを参考に BigQuery ML の Matrix Factorization を MovieLens 20M Dataset に適用し、各ユーザへの映画の推薦を生成してみます。
BigQuery はクエリとストレージに対して課金が発生しますが、特定の上限までの無料枠があります。詳しくは、BigQuery の料金をご覧下さい。また、BigQuery ML でモデルを作成して使用すると、モデルのトレーニングで使用したデータ量とデータに実行したクエリに基づいて料金が発生します。BigQuery ML の料金については、BigQuery ML の料金をご覧下さい。
記事執筆時点 (2020年5月) では Matrix Factorization の訓練はオンデマンドクエリには対応しておらず、BigQuery Reservations でコミットメント (BigQuery スロットの割り当て数) を購入する必要があります。試用の場合は 60 秒のコミット期間以降はキャンセル可能な Flex Slots を使うことで費用を最小限に抑えることができます。
全体の流れは以下です。
- データの取得
- データセットの作成
- データの読み込み
- モデルの作成
- モデルの評価
- 推薦の生成
BigQuery を操作する方法は Cloud Console の Web UI、bq コマンドラインツール、REST API、クライアントライブラリの4つがあります。この記事では、主に bq コマンドラインツールで BigQuery とやり取りを行います。
データの取得
MovieLens 20M Dataset は、GroupLens が公開しているユーザの映画に対する評価を集めたデータセットです。138,493 人のユーザが計 27,278 本の映画に対して 5段階 (1-5) で評価付けした 20,000,263 件の評価が含まれています。期間は 1995-01-09 から 2015-03-31 です。
GCP のコンソールを開き、Cloud Shell を起動します。MovieLens 20M Dataset をダウンロード、チェックサムの一致を確認し zip ファイルから ratings.csv と movies.csv を展開します。
$ curl -O 'http://files.grouplens.org/datasets/movielens/ml-20m.zip' $ md5sum ml-20m.zip cd245b17a1ae2cc31bb14903e1204af3 ml-20m.zip $ unzip ml-20m.zip ml-20m/ratings.csv ml-20m/movies.csv Archive: ml-20m.zip inflating: ml-20m/movies.csv inflating: ml-20m/ratings.csv
ratings.csv にはユーザID、映画ID、ユーザの視聴した映画に対する評価とタイムスタンプが含まれています。最初の10行は以下です。
$ head -n 10 ml-20m/ratings.csv userId,movieId,rating,timestamp 1,2,3.5,1112486027 1,29,3.5,1112484676 1,32,3.5,1112484819 1,47,3.5,1112484727 1,50,3.5,1112484580 1,112,3.5,1094785740 1,151,4.0,1094785734 1,223,4.0,1112485573 1,253,4.0,1112484940
また、movies.csv には各映画の ID、タイトル、ジャンルが含まれています。最初の10行は以下です。
$ head -n 10 ml-20m/movies.csv movieId,title,genres 1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy 2,Jumanji (1995),Adventure|Children|Fantasy 3,Grumpier Old Men (1995),Comedy|Romance 4,Waiting to Exhale (1995),Comedy|Drama|Romance 5,Father of the Bride Part II (1995),Comedy 6,Heat (1995),Action|Crime|Thriller 7,Sabrina (1995),Comedy|Romance 8,Tom and Huck (1995),Adventure|Children 9,Sudden Death (1995),Action
データセットの作成
bq コマンドラインツールを使用し BigQuery にデータセットを作成します。
- データセット: テーブルとビューへのアクセスを整理して制御するために使用される最上位のコンテナ。テーブルやビューはデータセットに属する。
- テーブル: 個々のレコードは行の形式にまとめられ、各レコードは列 (フィールド) で構成される。すべてのテーブルは、列名、データ型、その他の情報を記述するスキーマによって定義される。
bq mk コマンドで dataset フラグを指定し、データセットを作成します。データセット名は techblog_ml_20m としています。
$ bq version
This is BigQuery CLI b'2.0.57'
$ BQ_DATASET_NAME="techblog_ml_20m"
$ bq mk \
--dataset \
--description "MovieLens 20M movie ratings." \
$BQ_DATASET_NAME
データの読み込み
bq load コマンドを用いて CSV データを BigQuery のテーブルに読み込みます。ratings テーブルに ratings.csv、 movies テーブルに movies.csv を読み込みます。 CSV の先頭1行は列情報のため skip_leading_rows フラグに 1 を指定しスキップします。
$ BQ_RATINGS_TABLE="ratings"
$ bq load \
--source_format=CSV \
--skip_leading_rows 1 \
$BQ_DATASET_NAME.$BQ_RATINGS_TABLE \
ml-20m/ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
$ BQ_MOVIES_TABLE="movies"
$ bq load \
--source_format=CSV \
--skip_leading_rows 1 \
$BQ_DATASET_NAME.$BQ_MOVIES_TABLE \
ml-20m/movies.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
モデルの作成
Matrix Factorization を用いて、各ユーザへの映画の推薦を生成してみます。
Matrix Factorization はユーザによるアイテムの評価行列 
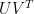
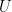


Matrix Factorization モデルの作成は、CREATE MODEL ステートメントを使用します。モデルは BigQuery データセット内に作られます。
CREATE OR REPLACE MODEL
techblog_ml_20m.mf_model OPTIONS (model_type="matrix_factorization",
user_col="user_id",
item_col="item_id",
l2_reg=9.83,
num_factors=24) AS
SELECT
user_id,
item_id,
rating
FROM
techblog_ml_20m.ratings
OPTIONS にモデルのオプションを指定します。アルゴリズムを指定する MODEL_TYPE は必須です。今回は matrix_factorization を指定します。
情報推薦に用いられるデータは一般に、明示的フィードバック (explicit feedback) と暗黙的フィードバック (implicit feedback) に分類 [1] されます。MovieLens のようにユーザにより映画の評価が与えられるデータの場合は明示的フィードバック、Web ページの閲覧数や閲覧時間、クリック、検索履歴、商品購買などユーザの行動履歴データに基づく場合は暗黙的フィードバックです。
明示的フィードバックに基づくデータを扱う場合は OPTIONS の FEEDBACK_TYPE に EXPLICIT (デフォルト値) を指定します。EXPLICIT を指定した場合、Alternating Least Squares (ALS) と呼ばれる交互最適化アルゴリズムでモデルの訓練が行われます。 また、暗黙的フィードバックに基づくデータを扱う場合は IMPLICIT を指定することで、コスト関数の二乗誤差を代理評価に基づく confidence level で重み付けする Weighted-Alternating Least Squares アルゴリズム [2] で訓練されます。
NUM_FACTORS は潜在因子の数で、デフォルト値は訓練サンプルサイズを n として 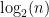
bq query コマンドでモデルを作成する SQL クエリを実行します。ジョブの完了には50分程かかりました。
bq query \
--use_legacy_sql=false \
--location=US \
'CREATE OR REPLACE MODEL
techblog_ml_20m.mf_model OPTIONS (model_type="matrix_factorization",
user_col="user_id",
item_col="item_id",
l2_reg=9.83,
num_factors=24) AS
SELECT
user_id,
item_id,
rating
FROM
techblog_ml_20m.ratings'
モデルの評価
ML.EVALUATE 関数を使用して、訓練時のモデルの評価指標を取得できます。
SELECT
*
FROM
ML.EVALUATE(MODEL techblog_ml_20m.mf_model,
(
SELECT
user_id,
item_id,
rating
FROM
techblog_ml_20m.ratings))
評価指標はモデルによって異なり、Matrix Factorization の場合は以下の評価指標が得られます。
- mean_absolute_error
- mean_squared_log_error
- median_absolute_error
- r2_score
- explained_variance
bq query コマンドでモデルの評価指標を取得する SQL クエリを実行します。
$ bq query \ > --use_legacy_sql=false \ > --location=US \ > 'SELECT > * > FROM > ML.EVALUATE(MODEL techblog_ml_20m.mf_model, > ( > SELECT > user_id, > item_id, > rating > FROM > techblog_ml_20m.ratings))' Waiting on bqjob_r362b02652a9999da_00000172356d9a46_1 ... (67s) Current status: DONE +---------------------+--------------------+------------------------+-----------------------+-------------------+--------------------+ | mean_absolute_error | mean_squared_error | mean_squared_log_error | median_absolute_error | r2_score | explained_variance | +---------------------+--------------------+------------------------+-----------------------+-------------------+--------------------+ | 0.5085813463072671 | 0.4450030854298618 | 0.03198410269191848 | 0.40146348753826455 | 0.597893852145977 | 0.5978938521459687 | +---------------------+--------------------+------------------------+-----------------------+-------------------+--------------------+
データへの当てはまりの良さを表す統計尺度である決定係数 (r2_score) は 0.598 です。
推薦の生成
ML.RECOMMEND 関数で訓練したモデルを用いて、全てのユーザと映画の組み合わせに対する評価を予測してみます。
CREATE OR REPLACE TABLE techblog_ml_20m.predicted_ratings OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL techblog_ml_20m.mf_model)
上記の SQL クエリを実行します。
$ bq query \ > --use_legacy_sql=false \ > --location=US \ > 'CREATE OR REPLACE TABLE > techblog_ml_20m.predicted_ratings OPTIONS() AS > SELECT > * > FROM > ML.RECOMMEND(MODEL techblog_ml_20m.mf_model)' Waiting on bqjob_r4bc7e5d2ef1d6610_0000017235a66bfb_1 ... (227s) Current status: DONE Created datascience-bigquery-exp.techblog_ml_20m.predicted_ratings
bq head コマンドで評価の予測値を確認してみます。
$ bq head -t $BQ_DATASET_NAME.predicted_ratings +---------------------+---------+---------+ | predicted_rating | user_id | item_id | +---------------------+---------+---------+ | 2.2759246202792496 | 101623 | 26495 | | 2.6420400938221542 | 90615 | 3944 | | 2.7093981464391663 | 111867 | 110867 | | 1.9122884800957562 | 81147 | 52617 | | 3.816966711260807 | 4716 | 83575 | ...
評価の予測値のテーブルと映画情報を持つ movies テーブルを結合し、ユーザーごとのオススメ映画 TOP-5 を取得してみます。
SELECT
user_id,
ARRAY_AGG(STRUCT(movie_title,
genre,
predicted_rating)
ORDER BY
predicted_rating DESC
LIMIT
5)
FROM (
SELECT
user_id,
item_id,
predicted_rating,
movie_title,
genre
FROM
techblog_ml_20m.predicted_ratings
JOIN
techblog_ml_20m.movies
ON
item_id = movie_id)
GROUP BY
user_id
上記の SQL クエリを実行します。
$ bq query \ > --destination_table $BQ_DATASET_NAME.predicted_rating_top_five \ > --use_legacy_sql=false \ > --location=US \ > 'SELECT > user_id, > ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) > ORDER BY predicted_rating DESC LIMIT 5) > FROM ( > SELECT > user_id, > item_id, > predicted_rating, > movie_title, > genre > FROM > techblog_ml_20m.predicted_ratings > JOIN > techblog_ml_20m.movies > ON > item_id = movie_id) > GROUP BY > user_id' Waiting on bqjob_r2270c5f64fc5de05_0000017235ad4267_1 ... (317s) Current status: DONE
出力に配列を含むため、コンソールからテーブルのプレビューを確認してみます。
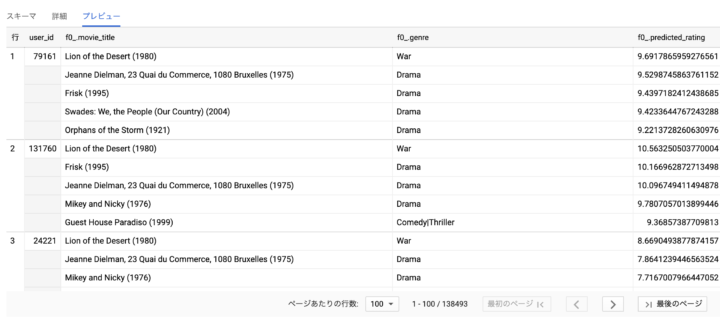
次に、ユーザーごとのオススメ映画 TOP-5 に含まれることの多い映画を調べてみます。
SELECT f.movie_title, f.genre, COUNT(f.movie_title) AS count, AVG(f.predicted_rating) AS mean_rating FROM techblog_ml_20m.predicted_rating_top_five AS T CROSS JOIN UNNEST(T.f0_) AS f GROUP BY f.movie_title, f.genre ORDER BY COUNT(f.predicted_rating) DESC LIMIT 10
上記の SQL クエリを実行します。
$ bq query \ > --use_legacy_sql=false \ > --location=US \ > 'SELECT > f.movie_title, > f.genre, > COUNT(f.movie_title) AS count, > AVG(f.predicted_rating) AS mean_rating > FROM > techblog_ml_20m.predicted_rating_top_five AS T > CROSS JOIN > UNNEST(T.f0_) AS f > GROUP BY > f.movie_title, > f.genre > ORDER BY > COUNT(f.predicted_rating) DESC > LIMIT > 10' Waiting on bqjob_r57f743281b34347a_0000017237397606_1 ... (0s) Current status: DONE +-------------------------------------------------------------+--------------------+-------+--------------------+ | movie_title | genre | count | mean_rating | +-------------------------------------------------------------+--------------------+-------+--------------------+ | Always for Pleasure (1978) | (no genres listed) | 61957 | 7.1941668499310145 | | Marihuana (1936) | Documentary|Drama | 56658 | 7.1838062669877845 | | Phish: Bittersweet Motel (2000) | Documentary | 13409 | 8.60023566596188 | | Dream Demon (1988) | Horror | 12305 | 6.088730837304773 | | Moment to Remember, A (Nae meorisokui jiwoogae) (2004) | Drama|Romance | 11831 | 7.799511635504388 | | Falls, The (1980) | Drama|Sci-Fi | 10434 | 8.623845902001628 | | Connections (1978) | Documentary | 8540 | 7.869813909207264 | | Man Who Saves the World, The (Dünyayi Kurtaran Adam) (1982) | Adventure|Sci-Fi | 8323 | 9.247291009728722 | | Jeanne Dielman, 23 Quai du Commerce, 1080 Bruxelles (1975) | Drama | 7266 | 8.188620253862926 | | Design for Living (1933) | Comedy|Romance | 6949 | 8.09001673929286 | +-------------------------------------------------------------+--------------------+-------+--------------------+
大衆向けではない映画も多く含まれており興味深いです。
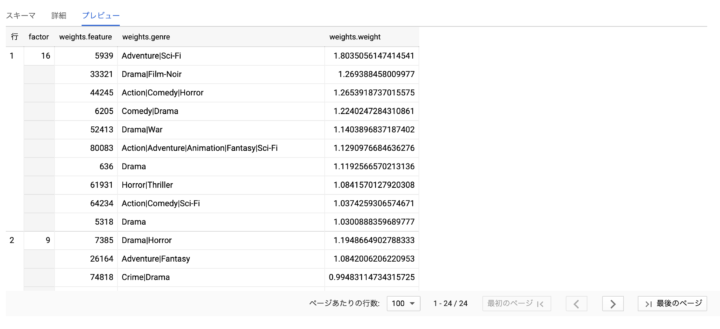
最後に、各潜在因子について関連の強い映画のジャンルを確認してみます。
SELECT
factor,
ARRAY_AGG(STRUCT(feature,
genre,
weight)
ORDER BY
weight DESC
LIMIT
10) AS weights
FROM (
SELECT
* EXCEPT(factor_weights)
FROM (
SELECT
*
FROM (
SELECT
factor_weights,
CAST(feature AS INT64) AS feature
FROM
ML.WEIGHTS(model techblog_ml_20m.mf_model)
WHERE
processed_input= "item_id")
JOIN
techblog_ml_20m.movies
ON
feature = movie_id) weights
CROSS JOIN
UNNEST(weights.factor_weights)
ORDER BY
feature,
weight DESC)
GROUP BY
factor
上記の SQL クエリを実行します。
$ bq query \ > --destination_table $BQ_DATASET_NAME.top_genres_per_factor \ > --use_legacy_sql=false \ > --location=US \ > 'SELECT > factor, > ARRAY_AGG(STRUCT(feature, genre, > weight) > ORDER BY > weight DESC > LIMIT > 10) AS weights > FROM ( > SELECT > * EXCEPT(factor_weights) > FROM ( > SELECT > * > FROM ( > SELECT > factor_weights, > CAST(feature AS INT64) as feature > FROM > ML.WEIGHTS(model techblog_ml_20m.mf_model) > WHERE > processed_input= "item_id") > JOIN > techblog_ml_20m.movies > ON > feature = movie_id) weights > CROSS JOIN > UNNEST(weights.factor_weights) > ORDER BY > feature, > weight DESC) > GROUP BY > factor' Waiting on bqjob_r7ebc28b81f25164e_0000017235b39e59_1 ... (1s) Current status: DONE
潜在因子を構成する各ジャンルの重みを確認できます。
おわりに
この記事では、BigQuery 上で、機械学習モデルを作成・実行する BigQuery ML の Matrix Factorization を MovieLens 20M Dataset に適用し、各ユーザへの推薦の生成を確認しました。BigQuery ML を用いることで、スケーラビリティを備えた BigQuery 上で標準 SQL を使い機械学習モデルを迅速に作成・実行することができます。
現実のタスクでは、ユーザによる映画の評価データのような明示的フィードバックが得られない場合もあります。暗黙的フィードバックに対する Matrix Factorization はチュートリアルの Using BigQuery ML to make recommendations from Google analytics data が参考になります。
参考文献
[1] 推薦システム
[2] Collaborative Filtering for Implicit Feedback Datasets
[3] bq コマンドライン ツール リファレンス


2016年11月、データサイエンティストとして中途入社。時系列分析や異常検知、情報推薦に特に興味があります。クロスバイク、映画鑑賞、猫が好き。


Recommends
こちらもおすすめ
-

JDLA「G検定」試験の合格体験記
2018.12.12
-

ISUCON5の下側
2015.11.11



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16