Amazon Personalize Web-APIで情報推薦サービスを実現する(4)

【連載】Amazon Personalize Web-APIで情報推薦サービスを実現する
(1)シグネチャバージョン4を使うメソッドの定義と必要なデータ
(2)データセットグループとスキーマ
(3)データセットとイベントトラッカー
▶︎(4)データをリアルタイム登録する方法とレシピ
(5)機械学習を実行するソリューション、機械学習モデルをデプロイするキャンペーン
(6)レコメンド結果と利用料金
今までの記事では、次のような内容を説明してきました。
- Amazon Personalize Web-APIで情報推薦サービスを実現する(1)
シグネイチャバージョン4を使うメソッドの定義と、Amazon Personalizeを利用する上で必要なデータについて - Amazon Personalize Web-APIで情報推薦サービスを実現する(2)
Amazon Personalizeにデータを登録するために必要な、データセットグループとスキーマについて - Amazon Personalize Web-APIで情報推薦サービスを実現する(3)
Amazon Personalizeにデータを登録する場所である、データセットとイベントトラッカーについて
この記事では、前の記事で用意したイベントトラッカーを使って、データセットにデータを登録する方法を説明したいと思います。
データを用意する
この記事では、Amazon Personalizeの公式ドキュメントでも使われているユーザーによる映画の評価データMovieLensを使います。MovieLensは、ミネソタ大学の研究グループGroupLensが運営する映画推薦サイトmovielensで集められたデータから作られており、出典を明記することで基本的にどんな研究目的でも利用可能とのことです。この記事ではAmazon Personalizeの公式ドキュメントで使われているものと同じデータであるMovieLens Latest Datasetsを使います.
適当なディレクトリ(環境変数及びプログラム中の定数DIRに絶対パスが入っているとする)に移動してダウンロードし、zipファイルを展開します。
$ export DIR=`pwd` $ wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip $ unzip ml-latest-small.zip $ ls ml-latest-small links.csv movies.csv ratings.csv README.txt tags.csv
いくつかのファイルが含まれていますが、情報推薦のための学習データとしては、ファイルratings.csvを使います。ratings.csvには、MovieLens Latest Datasetsのドキュメントに記載がある通り、次のようなフォーマットでデータが記録されています。
userId,movieId,rating,timestamp
userIdとmovieIdはそれぞれユーザーと映画を識別するためのIDで、ratingは0.5(最低評価)から0.5刻みで最大5(最高評価)の値が記録されています。timestampはいわゆるUNIXタイムで、文献[1]によるとmovielensサイトでユーザーが映画に評価を付けた時間を表すとのことです。
データを登録する
データファイルが準備できたら、ファイルからデータを読み学習データとしてAmazon Personalizeに登録します。
データを登録するためのメソッドは、次のように定義できます。
def PutEvents(eventList, sessionId, trackingId, userId)
endpoint = "https://personalize-events.#{REGION}.amazonaws.com/events"
post_data = {'eventList' => eventList,
'sessionId' => sessionId,
'trackingId' => trackingId,
'userId' => userId
}.to_json
call(endpoint, 'AmazonPersonalizeEvents.PutEvents', post_data)
end
APIのendpointが今まで定義したメソッドのものと異なるアドレスであることに注意して下さい。
このメソッドPutEventsを用いてファイルのデータを登録するRubyのコードは、例えば次のようになるでしょう。
trackingId = '3febd1f4-daa1-42da-8233-3ca785bf9c2b'
DATAFILE="#{DIR}/ml-latest-small/ratings.csv"
File.open(DATAFILE) {|file|
header = file.readline # skip header
file.each_line() {|line|
items = line.chomp.split(",")
userId, movieId, rating, timestamp = items[0], items[1], items[2], items[3]
sentAt = Time.now.to_i
event = {
'eventType' => 'rating',
'sentAt' => sentAt,
'properties' => {
'userId' => userId,
'itemId' => movieId,
'eventValue' => rating,
'timestamp' => timestamp
}.to_json
}
PutEvents([event], 'sessionId', trackingId, userId)
}
}
trackingIdの値は、イベントトラッカーの属性を使います(前回の記事を参照して下さい)。PutEventsの1つ目の引数はイベントリストで複数のイベントを渡すことができるので、今回は1つずつ渡しますが配列化しています。公式ドキュメントによると、最大10個のイベントを1度に送信できるとのことです。eventTypeは任意の名前を付けることができますが、ここでは「rating」と名付け、「ユーザーが映画を評価した」というイベントが発生した、という状況を想定しました。
イベントの中のpropertiesには、スキーマに対応したデータを入れます。ここで注意することは、スキーマでは予約語の項目USER_ID/ITEM_ID/EVENT_TYPE/EVENT_VALUE/TIMESTAMPはスネークケースであり、それらに対応するPutEventsの項目はキャメルケースであるということです。この対応付は自動的に行われ、もし不一致があるとデータ送信時(PutEvents実行時)にエラーが返ってきます。
{
"message": "Schema validation failed"
}
「rating」以外の名前を付けたイベントデータを送信することで、色々な切り口の情報推薦サービスが実現できます。ECサイトなら「search」(商品名検索時)、「view」(商品閲覧時)、「click」(商品詳細情報へのリンクをクリック時)などと複数の名前を使ってデータを送信することで、関心の高さが異なる状況に応じた情報推薦が可能となるでしょう。
APIを用いるプログラミング技術としては、JSON形式で表された複数のイベント情報を含んだJSON形式のデータを送信するということで、ネスト構造のJSON形式データを送信しなければならないことに注意して下さい。第3回の記事でスキーマ情報を表示した時と同様に、イベント情報のJSON形式文字列がエスケープされ、HTTPリクエストとなり送信されます。作成されたJSON形式データは、例えば次のようになります。
{
"eventList": [
{
"eventType": "rating",
"properties": "{\"userId\":\"1\",\"itemId\":\"1\",\"eventValue\":\"1.5\",\"timestamp\":1557302894}",
"sentAt": 1559713239
}
],
"sessionId": "sessionId",
"trackingId": "3febd1f4-daa1-42da-8233-3ca785bf9c2b",
"userId": "1"
}
レシピを選ぶ
レシピは情報推薦の種類とそれに対応する前処理及び機械学習アルゴリズムのセットを指し、種類は3種類が用意されています。
- USER_PERSONALIZATION:ユーザーが関心を持ちそうな情報を推測する
- SEARCH_PERSONALIZATION:ユーザーの関心を推測して、情報のリストを並べ替える
- RELATED_ITEMS:ある情報に関係がありそうな情報を推測する
種類によって、使うことができる機械学習アルゴリズムが変わります。この記事では映画の評価データを用意したので、USER_PERSONALIZATIONを使ってユーザーが関心を持ちそうな映画情報を推測することにしましょう。レシピは自分で作成することも出来ますが、この記事ではAmazonにより用意されている定義済みレシピを使うことにします。
USER_PERSONALIZATIONに対するレシピはニューラルネットワークを用いる学習アルゴリズムと、単純に「たくさんある情報は、どのユーザーも関心を持つに違いない」とするアルゴリズムの2種類が用意されています。この記事では、ニューラルネットワークを用いる学習アルゴリズムのうち、一番シンプルなHRNN(hierarchical recurrent neural network)レシピを使うことにします。
ただし、このレシピでは、用意した映画の評価データのうち、評価の高さの情報は使用されないようです。確かに公式のPython-SDKによるサンプルプログラムを見ても、評価が高いデータを選んで学習データとしていることが分かります(低い評価を付けていても、ユーザーが関心を持っていると判断されてしまうから)。
data = data[data['RATING'] > 3.6] # keep only movies rated 3.6 and above
元々、スキーマの中で評価データを入れる項目であるEVENT_VALUEは文字列として定義されているので、数値データとは扱われないわけです。
このレシピのARN(Amazon Resouce Name)は
arn:aws:personalize:::recipe/aws-hrnn
です。このrecipeArnは、次の記事で使います。
次の予定
ここまでで、図の赤字になっている部分の準備ができました。
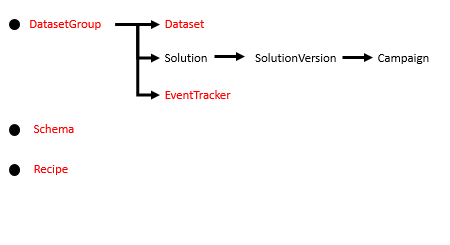
次の記事では、機械学習アルゴリズムにパラメータを設定し、機械学習を実行させようと思います。

参考文献

大学で民俗学や宗教についてのフィールドワークを楽しんでいたのですが,うっかり新設された結び目理論と幾何学を勉強する研究室に移ってしまい,さらに大学院では一般相対性理論を研究するという迷走した人生を歩んでいます.プログラミングが苦手で勉強中です.


Recommends
こちらもおすすめ
-

BigQuery ML で単語をクラスタリングしてみる
2020.3.12
-

AWS無料セミナー開催レポート | 大人気のAWS入門セミナー
2018.11.17
-

ディープラーニングにおけるdeconvolutionとは何か
2018.11.6


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16