Amazon Personalize Web-APIで情報推薦サービスを実現する(2)

Topics
【連載】Amazon Personalize Web-APIで情報推薦サービスを実現する
(1)シグネチャバージョン4を使うメソッドの定義と必要なデータ
▶︎(2)データセットグループとスキーマ
(3)データセットとイベントトラッカー
(4)データをリアルタイム登録する方法とレシピ
(5)機械学習を実行するソリューション、機械学習モデルをデプロイするキャンペーン
(6)レコメンド結果と利用料金
前回の記事では、Amazon Personalize Web-APIを利用するためのシグネチャバージョン4の準備と、使うデータの概要を簡単に説明しました。
今回から、Amazon Personalizeのデータを作成するプログラム例を紹介していきたいと思います。
データセットグループを操作する
なにはともあれ、データセットグループが無いと何もできません。
前回の記事で定義したメソッドcallを用いて、データセットグループの一覧を出すことができます。
def ListDatasetGroups(maxResults = 100)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'maxResults' => maxResults,
}.to_json
call(endpoint, 'AmazonPersonalize.ListDatasetGroups', post_data)
end
このメソッドを呼び出すと、最初はカラのJSONが返ってきます。
{
"datasetGroups": [
]
}
ここで、名前をつけてデータセットグループを作成するメソッドを定義します。
def CreateDatasetGroup(name)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'name' => name
}.to_json
call(endpoint, 'AmazonPersonalize.CreateDatasetGroup', post_data)
end
「sample-dataset-group」という名前でデータセットグループを作成すると、データセットグループのARN(Amazon Resource Name)が返ってきます(何らかの理由で作成に失敗しない限り)。
CreateDatasetGroup("sample-dataset-group")
{
"datasetGroupArn": "arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group"
}
作成したあとは、一覧でも出てきます。
ListDatasetGroups()
{
"datasetGroups": [
{
"creationDateTime": 1559193841.375,
"datasetGroupArn": "arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group",
"lastUpdatedDateTime": 1559193851.721,
"name": "sample-dataset-group",
"status": "ACTIVE"
]
}
statusがACTIVEになっていますが、Amazon Personalizeのデータの一部は即時反映されるわけでは無く、CreateDatasetGroupのドキュメントにも記載されている通り、statusは次のように順に変化します。
- CREATE PENDING > CREATE IN_PROGRESS > ACTIVE -or- CREATE FAILED
このstatusは、ListDatasetGroupsで一覧を出して探さなくても、CreateDatasetGroupやListDatasetGroupsで取得したdatasetGroupArnを用いて得られるデータセットグループ詳細で確認できます。
データセットグループ詳細を見るメソッドは次のように定義できます。
def DescribeDatasetGroup(datasetGroupArn)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'datasetGroupArn' => datasetGroupArn,
}.to_json
call(endpoint, 'AmazonPersonalize.DescribeDatasetGroup', post_data)
end
このメソッドを呼ぶと、指定したARNに対するデータセットグループの情報がJSONで返ってきます。
DescribeDatasetGroup('arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group')
{
"datasetGroup": {
"creationDateTime": 1559193841.375,
"datasetGroupArn": "arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group",
"lastUpdatedDateTime": 1559193851.721,
"name": "sample-dataset-group",
"status": "ACTIVE"
}
}
statusが確認できるので、CreateDatasetGroupでデータセット作成リクエストを送信したあと、例えば次のようにプログラム中でACTIVEになるのを待つ必要があります。
ret = CreateDatasetGroup('sample-dataset-group')
datasetGroupArn = JSON.parse(ret.body)['datasetGroupArn']
ret = DescribeDatasetGroup(datasetGroupArn)
sampleDatasetGroup = JSON.parse(ret.body)['datasetGroup']
while sampleDatasetGroup['status'] =~ /(CREATE PENDING)|(CREATE IN_PROGRESS)/
puts "dataset group creation in progress..."
sleep(3)
ret = DescribeDatasetGroup(datasetGroupArn)
sampleDatasetGroup = JSON.parse(ret.body)['datasetGroup']
end
スキーマを操作する
データセットグループを作ったらデータを入れたくなりますが、その前にどのようなデータを入れるかを考えておきましょう。
今回は、シンプルで汎用性もある、公式ドキュメントと同じスキーマを使います。
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{ "name": "EVENT_TYPE",
"type": "string"
},
{
"name": "EVENT_VALUE",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}
USER_IDとITEM_IDは、それぞれ名称の通りユーザと推薦情報を表すIDで、推薦情報サービスを構築する人が勝手にデザインできます。会員ナンバー等の数列でもメールアドレスでも何でも良いでしょう。
EVENT_TYPEは、何かユーザが取った行動を表します。ECサイトなら閲覧、検索、購入などがあるでしょうし(AIDMAモデルのようなものが考えられます)、SNSならお店や商品につけた評価やいわゆる「いいね」を押したかどうかなどもあり得るかもしれません。
EVENT_VALUEは、EVENT_TYPEに対応する値が入ります。閲覧や検索なら回数が入るでしょうし、購入なら回数や購入価格、評価なら点数などを入れることになります。このスキーマではtypeはstringとlongしか使っていませんが、Amazon PersonalizeのスキーマはApache Avroが採用されており、使えるデータ型はAvroの公式ドキュメント※ に記載されています。
※現在リンクは削除されています(https://avro.apache.org/docs/current/spec.html#schemas)
スキーマを作成する前は、一覧を出すことでスキーマが存在しないことを確認できます。スキーマの一覧を得るメソッドは、データセットグループの一覧を得るメソッドとほぼ同じです。
def ListSchemas(maxResults = 100)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'maxResults' => maxResults,
}.to_json
call(endpoint, 'AmazonPersonalize.ListSchemas', post_data)
end
このメソッドを呼び出すと、最初はカラのJSONが返ってきます。
{
"schemas": [
]
}
ここで、名前をつけてスキーマを作成するメソッドを定義します。
def CreateSchema(name, schema)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'name' => name,
'schema' => schema
}.to_json
call(endpoint, 'AmazonPersonalize.CreateSchema', post_data)
end
このCreateSchemaは、スキーマの名前とスキーマを定義するJSON文字列を引数として渡し呼び出します。「sample-schema」という名前を付け、作成が成功すると、スキーマのARNが返ってきます。
CreateSchema('sample-schema', <<-EOS)<br />
{ "type": "record",<br />
"name": "Interactions",<br />
"namespace": "com.amazonaws.personalize.schema",<br />
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},<br />
{
"name": "EVENT_TYPE",
"type": "string"
},<br />
{
"name": "EVENT_VALUE",
"type": "string"
},<br />
{
"name": "TIMESTAMP",
"type": "long"
}<br />
],<br />
"version": "1.0"<br />
}<br />
EOS
{
"schemaArn": "arn:aws:personalize:ap-northeast-1:123456:schema/sample-schema"
}
ここで、<<-EOSというのはRubyのヒアドキュメント記法です。
ARNから詳細を確認するメソッドも、データセットグループの場合とほぼ同じです。
def DescribeSchema(schemaArn)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'schemaArn' => schemaArn,
}.to_json
call(endpoint, 'AmazonPersonalize.DescribeSchema', post_data)
end
このDescribeSchemaを呼び出すと、スキーマの定義やスキーマの名前を含んだ詳細が得られます。
DescribeSchema('schemaArn": "arn:aws:personalize:ap-northeast-1:123456:schema/sample-schema')
{
"schema": {
"creationDateTime": 1557390177.961,
"lastUpdatedDateTime": 1557390177.961,
"name": "sample-schema",
"schema": "{\n \"type\": \"record\",\n \"name\": \"Interactions\",\n \"namespace\": \"com.amazonaws.personalize.schema\",\n \"fields\": [\n {\n \"name\": \"USER_ID\",\n \"type\": \"string\"\n },\n {\n \"name\": \"ITEM_ID\",\n \"type\": \"string\"\n },\n {\n \"name\": \"EVENT_TYPE\",\n \"type\": \"string\"\n },\n {\n \"name\": \"EVENT_VALUE\",\n \"type\": \"string\"\n },\n {\n \"name\": \"TIMESTAMP\",\n \"type\": \"long\"\n }\n ],\n \"version\": \"1.0\"\n}\n",
"schemaArn": "arn:aws:personalize:ap-northeast-1:123456:schema/sample-schema"
}
}
ここでオブジェクト名「schema」の値の部分が読み難くなっているのは、JSONの中にJSONデータを埋め込むネスト構造になっているため、記号や改行がエスケープされているからです。CreateSchemaやDescribeSchemaのAPIドキュメントを見ても、schemaの部分は以下のようにJSONフォーマットでありながら型はStringとなっています。
最初、StringじゃなくてJSONを入れて、ハマりました
schema
- A schema in Avro JSON format.
Type: String
Length Constraints: Maximum length of 10000.
Required: Yes
statusという属性は無く、即時作成されることが分かります。
次の予定
ここまでで、図の赤字になっている部分の準備ができました。
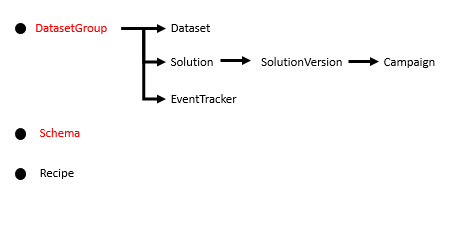
次の記事では、今回準備したデータセットグループとスキーマを使って、データを登録するための箱であるデータセットの作成などを説明していきたいと思います。


大学で民俗学や宗教についてのフィールドワークを楽しんでいたのですが,うっかり新設された結び目理論と幾何学を勉強する研究室に移ってしまい,さらに大学院では一般相対性理論を研究するという迷走した人生を歩んでいます.プログラミングが苦手で勉強中です.


Recommends
こちらもおすすめ
-

AWS GlueとAmazon Machine Learningでの予測モデル
2017.12.17
-

データサイエンス関連参加イベントまとめ(2017年)【後半】
2017.12.2




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16