R + tableau – ワードクラウド(Word Cloud)で映画ムーランの台本を可視化

こんにちは。データサイエンスチームのjwsです。
アニメーション映画である「ムーラン(Mulan, 1998)」をご存知ですか?
今回はその台本データから、tableauを使用してワードクラウドを作成してみました。
ワードクラウドとは
文章で使われた単語の頻度を計算して可視化する手法です。
登場頻度によって文字の大きさや向き、色等を変えることで
ひと目で文章の内容を把握することができます。
簡単なストーリー
Shan-Yuが率いるHun族の攻撃に立ち向かうため、
中国の皇帝は各家に男子1人の徴兵を命じました。
しかし、Fa家に男性はMulanのお父さんであるFa Zhouだけでした。
年寄りのお父さんに代わって徴兵に応じることを決めたFa Mulanは男装して入隊に成功、
Mulanを成功に導いてFa家の守護神への昇格を目指す赤竜Mushuや
討伐隊で出会ったYao, Ling, Chien-Poたちと一緒に戦場で活躍していきます。
ソースデータ
http://www.imsdb.com/scripts/Mulan.html
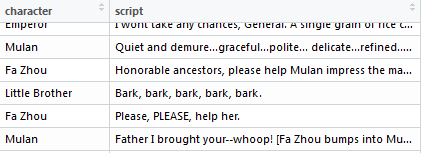
【台本抜粋】
・・・
[Cut to Mulan using her chopsticks to single out a grain of rice on top of the
mound of rice]
Mulan: Quiet and demure…graceful…polite…[picking up some rice with her
chopsticks and eating a mouthful] delicate…refined…poised… [She sets
down her chopsticks and writes down a final word on her right arm] punctual.
・・・
データ加工
台本の容量が大きくなかったので、ローカルPCのRで加工しました。
①ト書きと台詞の区分:ト書きは「[]」で表現されているので判定しやすい。
library(sqldf)
sqldf("select
script,
case when script like '%:%' then 'line'
when script like '%[%' then 'description'
when script like '%]%' then 'description'
else null
end as flag
from dataset") -> dataset

②台詞のみ抽出
sqldf("select
script
from dataset
where flag = 'line'") -> dataset_line
③キャラクター名の抽出:台詞を「:」でsplit。
library(magrittr)
dataset_line %<>%
tidyr::separate(col=script, into=c("character", "script"),
sep=":", fill="left")
④記号の削除、一部文字の修正:自分の好みに合わせてチューニング
dataset_line$script <- gsub(pattern="[,!\\?\\.-]", " ", dataset_line$script) dataset_line$script <- gsub(pattern="Fa Li", "Fa-Li", dataset_line$script) dataset_line$script <- gsub(pattern="Fa Zhou", "Fa-Zhou", dataset_line$script)
⑤単語に分割:台詞をスペースでsplit。
dataset_word <- as.data.frame(
strsplit(dataset_line[1,]$script, " "), col.names="word")
for(i in 2:nrow(dataset_line)){
temp <- as.data.frame(
strsplit(dataset_line[i,]$script, " "), col.names="word")
dataset_word <- rbind(dataset_word, temp)
}
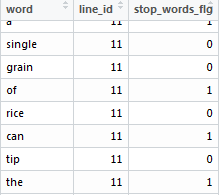
⑥stop wordsの判定
:一般的であまり意味を持たない単語(ex. the, a, …)が結果に影響を与えてしまうので、
ネットで拾ったstop wordsのリストを利用して除外することに。
sqldf("select
word,
line_id,
case when word in (select stop_words from stop_words) then 1
else 0
end as stop_words_flg
from dataset_word") -> dataset_word
tableauで可視化

⇒ 主人公の名前「Mulan」が一番多く登場しています。
※具体的な作成方法は、tableauのマニュアルをご参照ください。
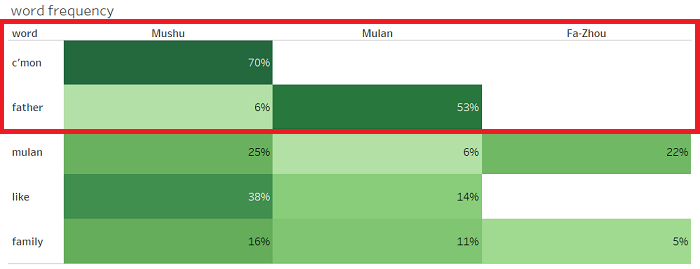
⇒ 各単語のキャラクターごとの発言率です。
「c’mon」の発言頻度は、約7割がMushuによるものです。
一方、「father」という言葉は、Mulanの台詞に半分以上含まれていました。
これだけ見ても、ある程度キャラクターの性格が伝わってきます。
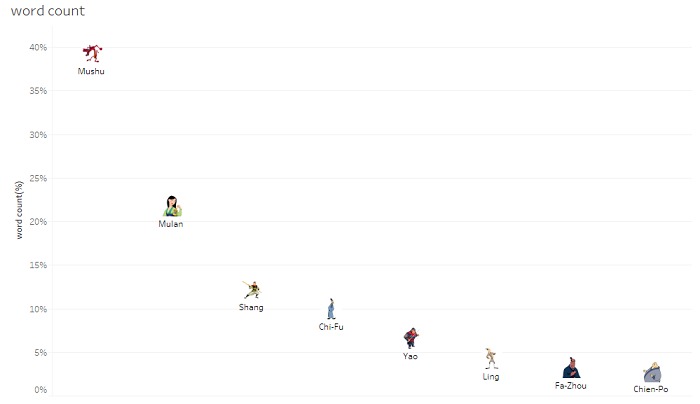
⇒ MushuとMulanの台詞が全体単語数の約6割を占めています。さすが主人公コンビですね。


Recommends
こちらもおすすめ
-

Rで実践!欠損データ分析入門【1】
2017.12.8
-

plumberとshinyを使ってマイクロサービスを作ってみた
2018.12.5
-

社内エンジニア読書会の進め方 ーAI・機械学習チーム編ー
2019.4.4
-

PythonやR言語で相関係数を計算する方法
2018.2.20

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16