R で集計していたら Inf に遭遇した話

こんにちは。データサイエンスチームの t2sy です。
R の numeric には Inf (positive infinity)、-Inf (negative infinity)、 NaN (not a number) といった特殊な値があります。以下のようにゼロ除算によりこれらの値を確認できます。
1/0 #> [1] Inf -1/0 #> [1] -Inf 0/0 #> [1] NaN
この記事では、ゼロ除算でなく max()、 min()、 mean() といった基本的な関数を使って集計していたら Inf/-Inf/NaN に遭遇したという話について紹介します。
この記事でお伝えしたいことは以下です。
- base::min(NA, na.rm = TRUE) は警告付きで Inf を返す
- base::max(NA, na.rm = TRUE) は警告付きで -Inf を返す
- base::mean(NA, na.rm = TRUE) は NaN を返す
- dplyr::summarise_at() や dplyr::summarise_all() で max()、 min() を使うと上記の警告を出力しない (dplyr 0.7.4 時点)
実行環境は OSX 10.11.3、R 3.4.3、tibble 1.4.1、dplyr 0.7.4 です。
どのような場面で遭遇したか
例として以下の人工データセットを用いて説明します。
library(tibble)
library(dplyr)
df <- tibble(
date = c("2018-02-01", "2018-02-01", "2018-02-01",
"2018-02-02", "2018-02-02", "2018-02-02",
"2018-02-03", "2018-02-03", "2018-02-03"),
time = c("01:24", "12:10", "19:23", "00:38", "09:20",
"20:11","03:20", "06:02", "23:21"),
s1 = c(1, 6, 2, 3, 5, 9, 8, 4, 7),
s2 = c(5, NA, 4, NA, NA, NA, NA, 2, 2))
df$date <- as.Date(df$date)
df
#> # A tibble: 9 x 4
#> date time s1 s2
#> <date> <chr> <dbl> <dbl>
#> 1 2018-02-01 01:24 1.00 5.00
#> 2 2018-02-01 12:10 6.00 NA
#> 3 2018-02-01 19:23 2.00 4.00
#> 4 2018-02-02 00:38 3.00 NA
#> 5 2018-02-02 09:20 5.00 NA
#> 6 2018-02-02 20:11 9.00 NA
#> 7 2018-02-03 03:20 8.00 NA
#> 8 2018-02-03 06:02 4.00 2.00
#> 9 2018-02-03 23:21 7.00 2.00
各カラムの意味は以下です。
- date: 日付
- time: 時刻
- s1: センサ1の観測値
- s2: センサ2の観測値
分析の初期段階で、データの特徴を捉えるために日次の要約統計量を計算している状況を考えます。上記は2つのセンサのみですが、実際は多くのセンサ (例えば数百から数千規模) からデータを取得しているような状況を想像してください。
glimpse(df) #> Observations: 9 #> Variables: 4 #> $ date <date> 2018-02-01, 2018-02-01, 2018-02-01, 2018-02-02, 2018-02-... #> $ time <chr> "01:24", "12:10", "19:23", "00:38", "09:20", "20:11", "03... #> $ s1 <dbl> 1, 6, 2, 3, 5, 9, 8, 4, 7 #> $ s2 <dbl> 5, NA, 4, NA, NA, NA, NA, 2, 2
センサ2のデータに欠損値 NA が含まれていますが、全体的なデータの特徴・傾向を捉えるために、このまま日次の要約統計量を計算してみます。
df_summary <- df %>%
group_by(date) %>%
summarise_at(vars(starts_with("s")),
funs(min = min, max = max, med = median, mn = mean, sd = sd))
df_summary %>%
select(date, starts_with("s1_"))
#> # A tibble: 3 x 6
#> date s1_min s1_max s1_med s1_mn s1_sd
#> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2018-02-01 1.00 6.00 2.00 3.00 2.65
#> 2 2018-02-02 3.00 9.00 5.00 5.67 3.06
#> 3 2018-02-03 4.00 8.00 7.00 6.33 2.08
df_summary %>%
select(date, starts_with("s2_"))
#> # A tibble: 3 x 6
#> date s2_min s2_max s2_med s2_mn s2_sd
#> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2018-02-01 NA NA NA NA NA
#> 2 2018-02-02 NA NA NA NA NA
#> 3 2018-02-03 NA NA NA NA NA
センサ1は要約統計量が得られているのに対しセンサ2は全て NA となっています。これは min()、max()、median()、mean()、sd() の na.rm 引数がデフォルトで FALSE のため、ベクトルに NA が含まれると NA を返すからです。
次に dplyr::summarise_at() に na.rm = TRUE を指定し、 NA を除外した上で要約統計量を計算してみます。この時、警告・エラーは出力されません。
df_summary2 <- df %>%
group_by(date) %>%
summarise_at(vars(starts_with("s")),
funs(min = min, max = max, med = median, mn = mean, sd = sd),
na.rm = TRUE)
センサ2の集計結果を確認してみます。
df_summary2 %>%
select(date, starts_with("s2"))
#> # A tibble: 3 x 6
#> date s2_min s2_max s2_med s2_mn s2_sd
#> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2018-02-01 4.00 5.00 4.50 4.50 0.707
#> 2 2018-02-02 Inf -Inf NA NaN NaN
#> 3 2018-02-03 2.00 2.00 2.00 2.00 0
2018-02-02 の結果に Inf/-Inf/NaN が含まれていることがわかります。思わぬ場面で、Inf に遭遇してしまいました。
これは何故でしょうか。まず、集計前のデータをもう一度確認してみると、 センサ2の 2018-02-02 におけるデータは全て NA となっています。
df %>%
filter(date == as.Date("2018-02-02")) %>%
select(date, s2)
#> # A tibble: 3 x 2
#> date s2
#> <date> <dbl>
#> 1 2018-02-02 NA
#> 2 2018-02-02 NA
#> 3 2018-02-02 NA
dplyr::summarise_at() はベクトル c(NA, NA, NA) に max() や min() などの関数を na.rm = TRUE を指定した上で適用しています。これらを単独で実行してみます。
max(c(NA, NA, NA), na.rm = TRUE) #> Warning in max(c(NA, NA, NA), na.rm = TRUE): max の引数に有限な値がありませ #> ん: -Inf を返します #> [1] -Inf max() #> Warning in max(): max の引数に有限な値がありません: -Inf を返します #> [1] -Inf min(c(NA, NA, NA), na.rm = TRUE) #> Warning in min(c(NA, NA, NA), na.rm = TRUE): min の引数に有限な値がありませ #> ん: Inf を返します #> [1] Inf min() #> Warning in min(): min の引数に有限な値がありません: Inf を返します #> [1] Inf mean(c(NA, NA, NA), na.rm = TRUE) #> [1] NaN
min()、max() は引数を指定しない場合や、値が全て NA で na.rm = TRUE を指定した場合にそれぞれ警告付きで Inf、-Inf を返し、 mean() は値が全て NA で na.rm = TRUE を指定した場合、 NaN を返すことがわかります。
単独で実行した場合は、警告付きで返りますが、dplyr::summarise_at()、 dplyr::summarise_all() で min()、 max() を使った場合、警告は出力されませんでした。そのため、意図しない Inf、-Inf が含まれていることに気づかずに分析を進めてしまう可能性があります。 (dplyr::summarise() では警告が出力されます)
ggplot2 による可視化では気づきにくい
Inf、-Inf が混ざったデータは ggplot2 で図示しても気づきにくいため、誤った解釈をしてしまう可能性がある点にも注意が必要です。
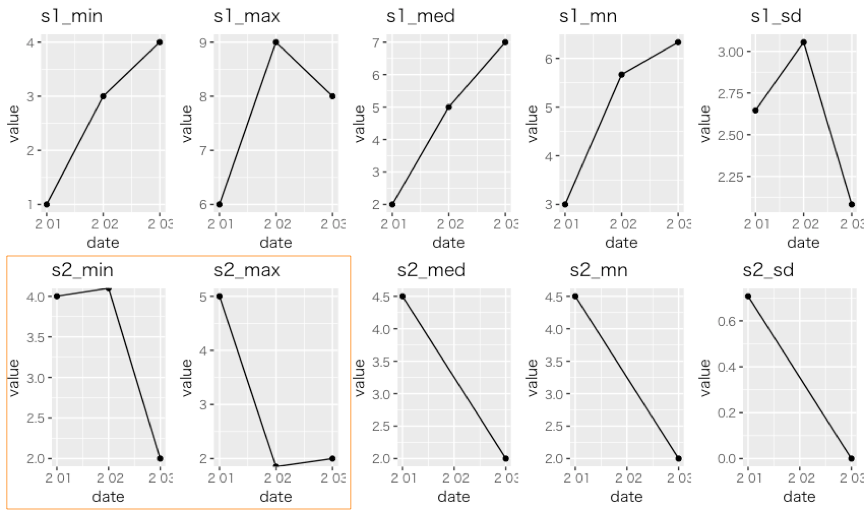
今回は集計結果の Inf/-Inf/NaN を NA で置換してみます。
df_summary3 <- df_summary2 %>%
mutate_at(vars(starts_with("s")), funs(ifelse(is.finite(.), ., NA)))
df_summary3 %>%
select(date, starts_with("s2"))
#> # A tibble: 3 x 6
#> date s2_min s2_max s2_med s2_mn s2_sd
#> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2018-02-01 4.00 5.00 4.50 4.50 0.707
#> 2 2018-02-02 NA NA NA NA NA
#> 3 2018-02-03 2.00 2.00 2.00 2.00 0
NA 置換後の df_summary3 を図示すると以下になります。
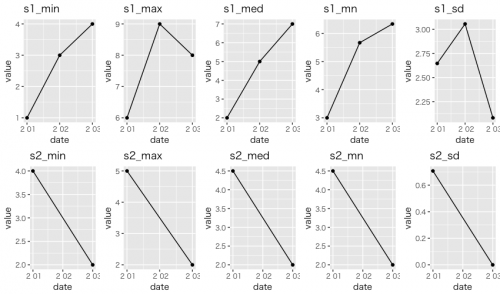
おわりに
今回はセンサデータを R で集計していたら思わぬ場面で Inf に遭遇したという話について紹介しました。
分析の後半で大惨事にならないためにも、データの傾向を捉えるために基本集計や前処理を行う分析の初期段階から、意図しない Inf/-Inf/NaN/NA が混入していないか base::summary() や tibble::glimpse() などを用いて確認することや、これらの値の発生過程を追跡・特定できる仕組みを構築しておくことは重要だと思います。
参考文献
[1] HOW R CALCULATES INFINITE, UNDEFINED, AND MISSING VALUES

2016年11月、データサイエンティストとして中途入社。時系列分析や異常検知、情報推薦に特に興味があります。クロスバイク、映画鑑賞、猫が好き。


Recommends
こちらもおすすめ
-

R からシームレスに Python を呼べる reticulate が便利だった
2018.4.13
-

Rで実践!欠損データ分析入門【2】
2017.12.20
-

「統計的因果探索」の一部を動かしてみた
2018.12.20


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16