Pythonで時系列データをクラスタリングする方法

2017.12.12

こんにちは。データサイエンスチームのHan-Cheolです。
この記事は、DataScience Advent Calendarの12日目の記事です。
1. はじめに
実世界のデータの多くは時間と共に変化する情報、つまり時系列データです。私たちの周辺に目を向けてみると、ウェブサイトに訪れるユーザーの行動データや消費電力データなど、身近なところでもすぐ見つけることが可能です。
今回は、「クラスタリング」手法を利用して「時系列データ」から繰り返して出現するパターンを見つけ出す方法を調べてみます。
利用するデータ
ここ数年、再生可能エネルギーや電力自由化のような話がよく聞こえてきます。このトレンドは日本の話だけではなく、機械学習・データ分析のコンペで有名なKaggleでも電力に関する内容がよく見当たります。
ここではこのトレンドに乗ってUC Irvine Machine Learning Repositoryで提供している機械学習用のデータセットの中で下記の消費電力データセットを利用します。
- データのダウンロードページURL
- 特徴
- データ取得期間: [2011/1/1, 2015/1/1)
- 測定欠測値は存在しない
- 期間中に利用開始・終了がある場合、測定値は0と表示される
- データ形式
利用するツール
データ分析環境としてはPython 3.6とJupyter Notebookを利用しています。また、時系列データのクラスタリング用途としてtslearnライブラリを使います。必要なツールは下記のリストにありますので、必要に応じて設置しましょう。
- Python (> 3.x) with Jupyter
- ライブラリ
- pandas
- scipy, numpy, cython (tslearnが依存)
- tslearn
【事例集】AIや機械学習によるビッグデータ活用をしたい方にオススメ!

「AIによるキャスト評価システムの構築」「データ分析基盤の運用費用9割削減」など、AWSを利用したAI、機械学習の成功事例をご紹介します。
2. データの取得
下記のようにwgetでデータを取得するようにしましょう。
$ wget -nv -O /tmp/LD2011_2014.txt.zip https://archive.ics.uci.edu/ml/machine-learning-databases/00321/LD2011_2014.txt.zip $ unzip /tmp/LD2011_2014.txt.zip -d /tmp/LD2011_2014 $ ls -l -h /tmp/LD2011_2014 total 679M -rw-r----- 1 hccho hccho 679M Mar 3 2015 LD2011_2014.txt drwxrwxr-x 2 hccho hccho 4.0K Mar 17 2015 __MACOSX
テキストの中身を見てみると、1番目のカラムが15分間隔の時間情報 (カラム名は無し)で、その次からはクライアント(MT_XXX)の消費電力が記録されています。下の例では横幅を100文字できっていますが、実際はもっと長いです。
$ head -n 10 /tmp/LD2011_2014/LD2011_2014.txt | cut -c 1-100 "";"MT_001";"MT_002";"MT_003";"MT_004";"MT_005";"MT_006";"MT_007";"MT_008";"MT_009";"MT_010";"MT_011 "2011-01-01 00:15:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 00:30:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 00:45:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 01:00:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 01:15:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 01:30:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 01:45:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 02:00:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; "2011-01-01 02:15:00";0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0;0; $ tail -n 10 /tmp/LD2011_2014/LD2011_2014.txt | cut -c 1-100 "2014-12-31 21:45:00";2,53807106598985;22,0483641536273;1,73761946133797;156,50406504065;86,58536585 "2014-12-31 22:00:00";1,26903553299492;22,0483641536273;1,73761946133797;164,634146341463;93,9024390 "2014-12-31 22:15:00";2,53807106598985;22,0483641536273;1,73761946133797;160,569105691057;87,8048780 "2014-12-31 22:30:00";2,53807106598985;22,0483641536273;1,73761946133797;162,60162601626;80,48780487 "2014-12-31 22:45:00";1,26903553299492;22,0483641536273;1,73761946133797;156,50406504065;85,36585365 "2014-12-31 23:00:00";2,53807106598985;22,0483641536273;1,73761946133797;150,406504065041;85,3658536 "2014-12-31 23:15:00";2,53807106598985;21,3371266002845;1,73761946133797;166,666666666667;81,7073170 "2014-12-31 23:30:00";2,53807106598985;20,6258890469417;1,73761946133797;162,60162601626;82,92682926 "2014-12-31 23:45:00";1,26903553299492;21,3371266002845;1,73761946133797;166,666666666667;85,3658536 "2015-01-01 00:00:00";2,53807106598985;19,9146514935989;1,73761946133797;178,861788617886;84,1463414
3. 生データの読み込み・確認
最初にJupyter Notebookから必要なライブラリをロードするなど、準備作業を行いましょう。
import logging
logging.basicConfig()
logger = logging.getLogger()
logger.setLevel(logging.WARN)
import itertools
import calendar
from collections import Counter
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
pd.set_option('max_rows', 20)
from tslearn.utils import to_time_series_dataset
from tslearn.clustering import TimeSeriesKMeans
from tslearn.preprocessing import TimeSeriesScalerMeanVariance, TimeSeriesScalerMinMax
import matplotlib.pyplot as plt
import matplotlib.markers as plt_markers
%matplotlib notebook
また、少し長いですが、データの可視化のために下記のクラスを定義してください。
class Visualizer(object):
def __init__(self):
self._markers = itertools.cycle([
'o', 'v', '^', '<', '>', '1', '2', '3', '4', '8',
's', 'p', '*', 'h', 'H', '+', 'x', 'D', 'd', 'P'])
self._colors = itertools.cycle(['b', 'g', 'r', 'c', 'm', 'y'])
self._name_to_marker = {}
def _make_xticks_and_xlabels(self, xs_ticks, xtick_step, xs_labels):
"""グラフのx軸ラベル表示のために、特定単位のxtick, xlabelを生成。
"""
shown_xticks = []
shown_xlabels = []
for xtick, xlabel in zip(xs_ticks, xs_labels):
check_digit = 0
check_digit |= 1 if xlabel.minute == 0 else 0
check_digit |= 2 if xlabel.hour == 0 else 0
check_digit |= 4 if xlabel.day == 1 else 0
if (xtick_step == 'h' and (check_digit & 1) == 1) \
or (xtick_step == 'd' and (check_digit & 3) == 3) \
or (xtick_step == 'm' and (check_digit & 7) == 7):
shown_xticks.append(xtick)
shown_xlabels.append(
'{} ({})'.format(str(xlabel), calendar.day_abbr[xlabel.weekday()]))
logger.info('Adding xtick, xlabel: {}, {}'.format(xtick, xlabel))
return shown_xticks, shown_xlabels
def draw_graphs(self, df, cnt=None, scatter=True,
xlabel='Time', xtick_step='m',
ylabel='kW/15-min', ylog=False,
figsize=(12,8), dotsize=3, alpha=0.3):
"""時系列データの可視化関数。
df: Pandas DataFrame。`dt`カラムはx軸、それ以外のカラム1個がy軸(グラフ1個)に対応。
cnt: 各y軸データに対して、legend名に追加して表示する情報 (例、クラスタに属するサンプル数)。
scatter: Trueの場合scatter graphを、Falseの場合line plot graphを利用。
xlabel: x軸名。
xtick_step: h (hour), d (day), m (month).
ylabel: y軸名。
ylog: Trueの場合、y軸をlog scaleにする。
figsize: キャンバスサイズ。
dotsize: scatter=Trueの場合、各点の大きさを設定。
alpha: グラフの透明度を設定。
"""
plt.subplots(1, figsize=figsize)
# y軸: logスケール?
if ylog:
plt.yscale('log')
# グラフを描く。
xs_labels = df['dt']
xs_ticks = np.arange(len(xs_labels))
ys_columns = df.columns.tolist()
ys_columns.remove('dt')
for ys_col in ys_columns:
ys = df[ys_col]
# グラフの名前とそれのmarker/color情報を保存。
if ys_col not in self._name_to_marker:
self._name_to_marker[ys_col] = {
'marker':next(self._markers),
'color':next(self._colors)}
# cnt != Noneの場合、各グラフの名前に追加情報を付着。
if cnt:
ys_label = '{}: {}'.format(ys_col, cnt[ys_col])
else:
ys_label = ys_col
# scatter/lineグラフを描く。
if scatter:
plt.scatter(
xs_ticks, ys,
marker=self._name_to_marker[ys_col]['marker'],
c=self._name_to_marker[ys_col]['color'],
s=dotsize, alpha=alpha,
label=ys_label)
else:
plt.plot(
xs_ticks, ys,
marker=self._name_to_marker[ys_col]['marker'],
c=self._name_to_marker[ys_col]['color'],
markersize=dotsize, alpha=alpha,
label=ys_label)
logger.info('Plotting graph: {}'.format(ys_label))
# そのほか、Canvas上の設定を行う。
shown_xticks, shown_xlabels = self._make_xticks_and_xlabels(
xs_ticks, xtick_step, xs_labels)
plt.xticks(shown_xticks, shown_xlabels, rotation=90)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.grid()
lgnd = plt.legend(loc='upper left', ncol=2, markerscale=3)
plt.tight_layout()
# Show it.
plt.plot()
# Visualizerオブジェクトを生成。
viz = Visualizer()
続けて、上のデータをPythonで読み込みます。CSVファイルなのでPandasを使えば簡単に読み込むことができます。ただ、区切り文字がカスタム化されたものなので、下記のようにオプションを指定して読み込みましょう。
filepath = '/tmp/LD2011_2014/LD2011_2014.txt'
# Pandas DataFrameとして読み込む。
df_raw = pd.read_csv(filepath, sep=';', decimal=',')
# 測定時間カラムのカラム名を"str_dt"と与えて、またこれをPython datetime
# 形式に変換した新しい"dt"カラムを追加する。
df_raw = df_raw.rename(columns={'Unnamed: 0':'str_dt'})
df_raw['dt'] = df_raw['str_dt'].apply(
lambda s: datetime.strptime(s, '%Y-%m-%d %H:%M:%S'))
# 読み込み結果を検証する。
# カラムが多いので一部分だけを出力してみる。
df_raw[['str_dt', 'dt', 'MT_001', 'MT_002', 'MT_003', 'MT_004', 'MT_005']]

この五つのクライアント(MT_001~005)を可視化してみると下記のようになります。どちらも2012年以前のデータの数値が0なので、契約が行われてなかったことが分かります。
viz.draw_graphs(
df_raw[['dt', 'MT_001', 'MT_002', 'MT_003', 'MT_004', 'MT_005']],
xtick_step='m',
dotsize=2,
alpha=0.4)
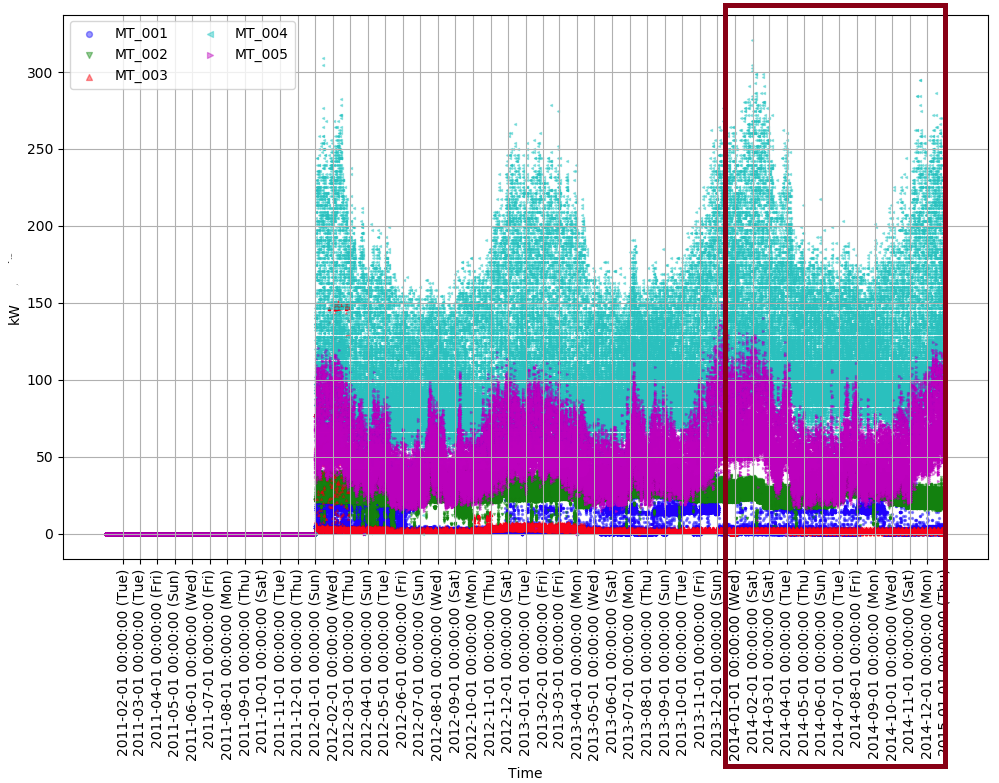
今回は実験をスピーディにするため最後の1年間のデータだけ(茶色い四角形で囲われた部分)を使用するようにします。
df_sample = df_raw[df_raw['dt'] >= '2014-01-01 00:00:00']
4. 時系列データのクラスタリングと距離関数
時系列データを扱う時に注意すべき点が、二つの時系列データ間の距離(類似度)を計算する手法の選択です。タスクによってはデータが時間軸に対してある程度ズレがあっても同じパターンとして認識したい場合があります。たとえば、音声認識タスクでは同じ発話でも話者によって(または同じ話者でも状況によって)そのスピードが違います。このようなズレを補完するためにDynamic Time Wrapping (DTW)のような距離関数が用いられます。
しかし、今回使う消費電力のデータでは時間軸に対してズレがあることは重要な違いを意味するので(出勤前・後や昼・夜の違い)、DTWではなくユークリッド距離を利用します。
クラスタリングの前に、各クライアントの消費量電力データを1次元ベクトル表現に変換します。これが今回使うtslearnライブラリの入力データになります。また、全データ値が0の場合は例外として除外するようにしています。
AWSのビッグデータ活用・機械学習導入支援サービス
def get_target_column_names(cols):
columns = cols.tolist()
columns.remove('str_dt')
columns.remove('dt')
return columns
def remove_all_zero_ys(yss):
filtered_yss = []
for ys in yss:
all_zero = True
for y in ys:
if y[0] != 0.0:
all_zero = False
break
if not all_zero:
filtered_yss.append(ys)
return np.array(filtered_yss)
# X-axisデータ。
xs = df_sample['dt']
# Y-axisデータ (複数)。
y_columns = get_target_column_names(df_sample.columns)
yss = to_time_series_dataset(
df_sample.as_matrix(y_columns).T)
# 全項目がzeroのデータは削除
filtered_yss = remove_all_zero_ys(yss)
続けて、クラス多数を12 (今回は最適なクラスタ数を調べる部分は行ってませんが、実際は試行錯誤しながら調べてみる必要があります)にしてデータをクラスタリングします。この時、実験の再現性のためにクラスタ中心を初期化する時に使われるランダム値を固定します。
n_clusters = 12
clustering_metric = 'euclidean'
rand_seed = 12345
km = TimeSeriesKMeans(
n_clusters=n_clusters,
metric=clustering_metric,
random_state=rand_seed)
km.fit(filtered_yss)
クラスタリングされた結果を可視化してみましょう。
# `dt`, `cluster-0`, `cluster-1`, ...のカラムを持つDataFrameを作成。
data = []
for cluster_x in km.cluster_centers_:
data.append(
[point_x[0] for point_x in cluster_x]
)
columns = ['cluster-{}'.format(idx) for idx in range(n_clusters)]
clusters = np.array(data).T
df_clusters = pd.DataFrame(clusters, columns=columns)
df_clusters['dt'] = xs.values
# クラスタに属するデータ数を計算。
cnt = Counter(km.labels_)
cluster_labels = {}
for k in cnt:
cluster_labels['cluster-{}'.format(k)] = cnt[k]
# グラフを表示。
viz.draw_graphs(df_clusters, cnt=cluster_labels,
xtick_step='m',
alpha=0.4)
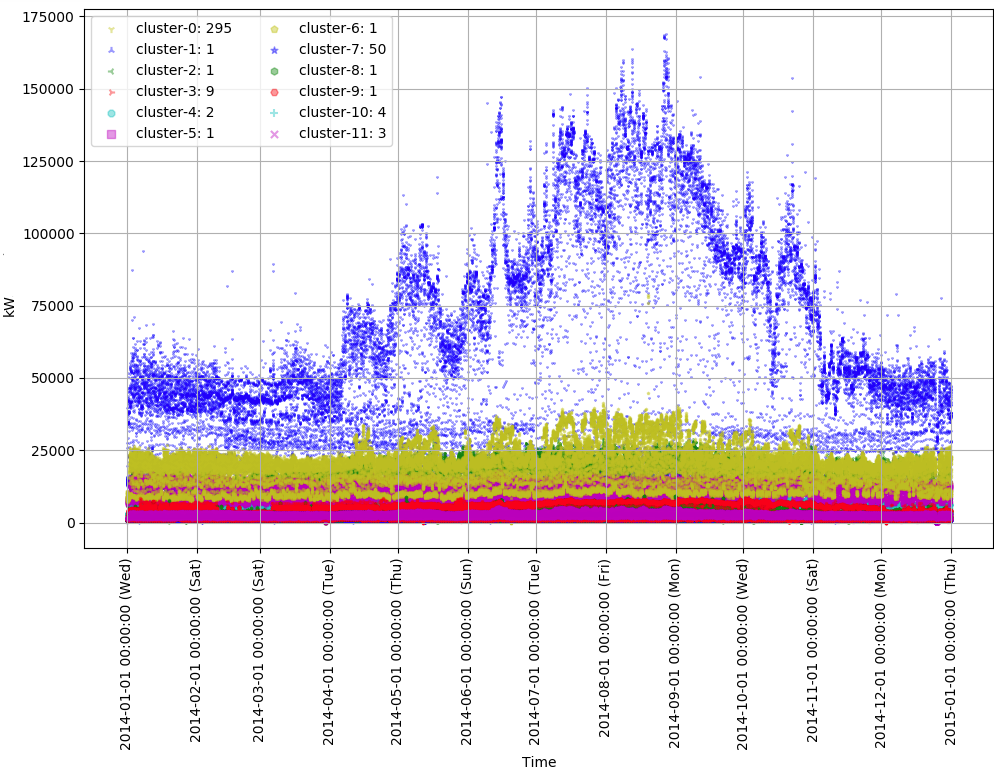
上のグラフで初期の30日間のデータを拡大したグラフが下記のものです。
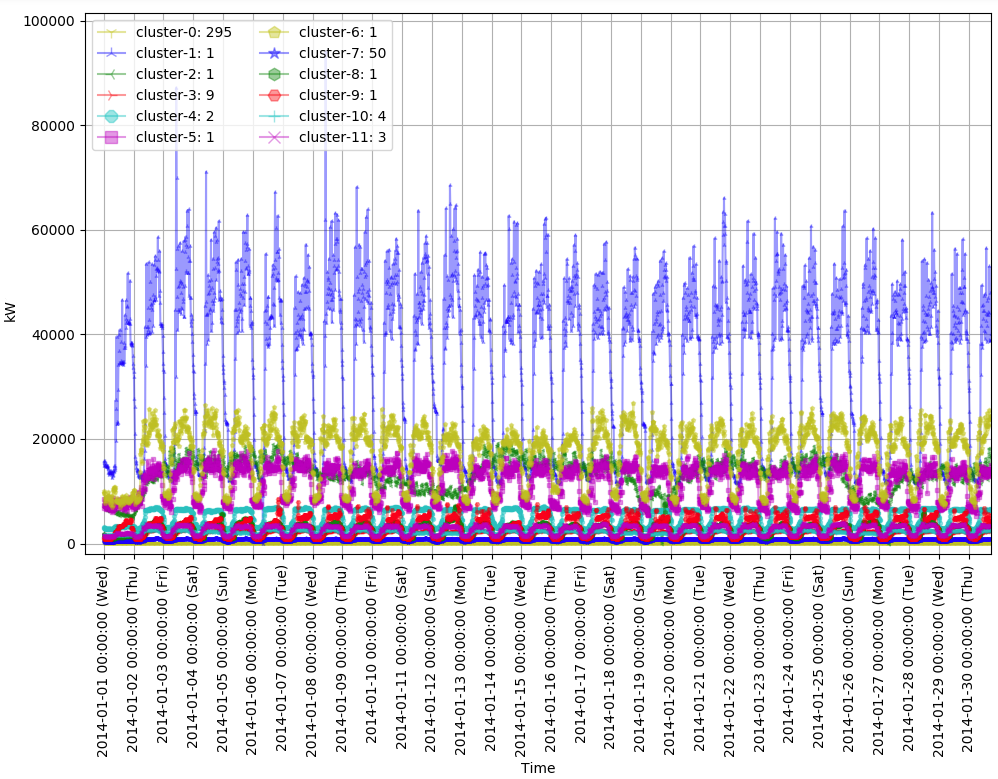
この二つのグラフから下記のような特徴が現れます。
- 絶対値が非常に高く、夏にピークを迎えるクラスタ (cluster-1)が目立つ。
- 複数の時系列データが含まれるクラスタは半分しか存在しない。また、2番目のグラフを見てみると、データ1個でクラスタ1個が生成されたケースはその多く (cluster-1, 2, 5, 6)が他と比べてとても高い絶対値(10,000~70,000kW以上)を持っていることが分かる。
cluster-1に属するクライアントは夏場に最大40,000kWの消費電力を要りますが、これは一般家庭の最大消費電力 (100V x 30Aの場合)である3kWの約13,000倍に達します。このような消費電力を考えると大規模の工場ではないかと思われます。
続けて絶対値が異常に高いcluster-1を除外したcluster-2, 5, 6だけをプロットしてみると下記のようなグラフになります。
# cluster-1を除外した、最大値が大きい三つのクラスタ (cluster-2, 5, 6)をプロット
target_clusters = ['cluster-{}'.format(idx) for idx in [2,5,6]]
filtered_df_clusters = df_clusters[['dt'] + target_clusters]
viz.draw_graphs(filtered_df_clusters, cnt=cluster_labels,
xtick_step='d',
scatter=False,
alpha=0.4)
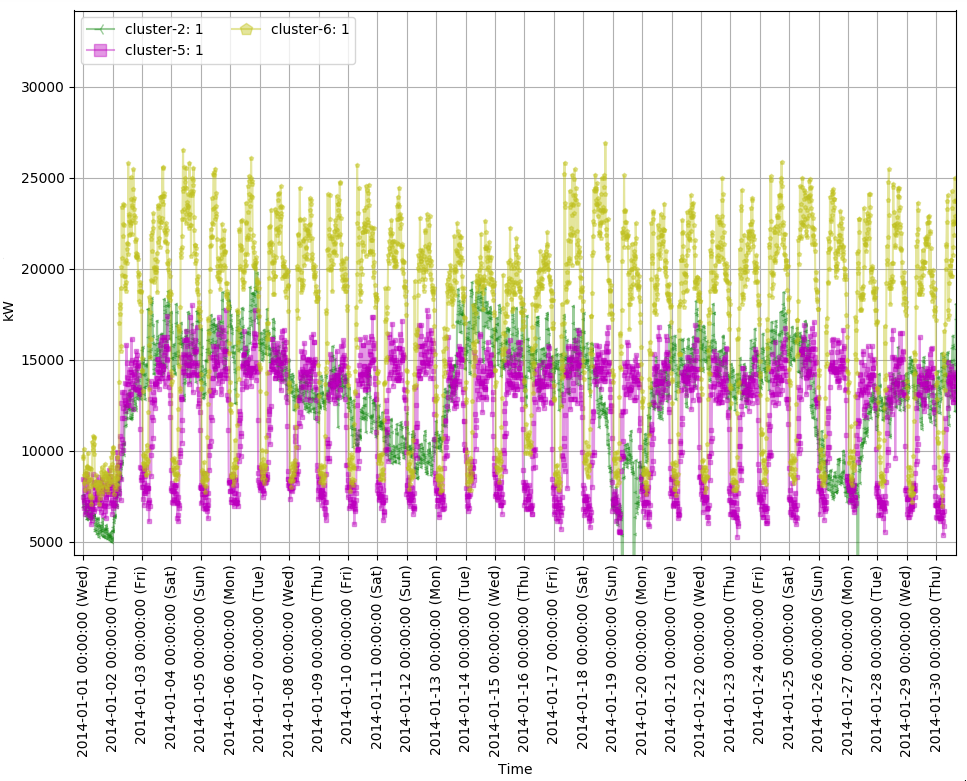
最初に、1月1日はお休みなので消費電力が低くなっていることが分かります。そしてcluster-1と5は最大消費電力の差があるものの、パターンはとても似ていることが分かります。規模が違う同じ業種ではないかと推測できます。しかし、cluster-2に属するクライアントの消費電力は週末(土日)の間に落ちる特徴が見られます。公共機関のように週末には営業をしない所のデータと思われます。
続けて、今回は消費電力の絶対値が小さい四つのクラスタ (cluster-0, 3, 7, 10)の特徴をみてみます。このクラスタには多くのデータが含まれています。クラスタ名の右側がクラスタに属するデータ数です。最初にグラフは1年間のデータで、二番目のグラフは最初の30日間のデータです。
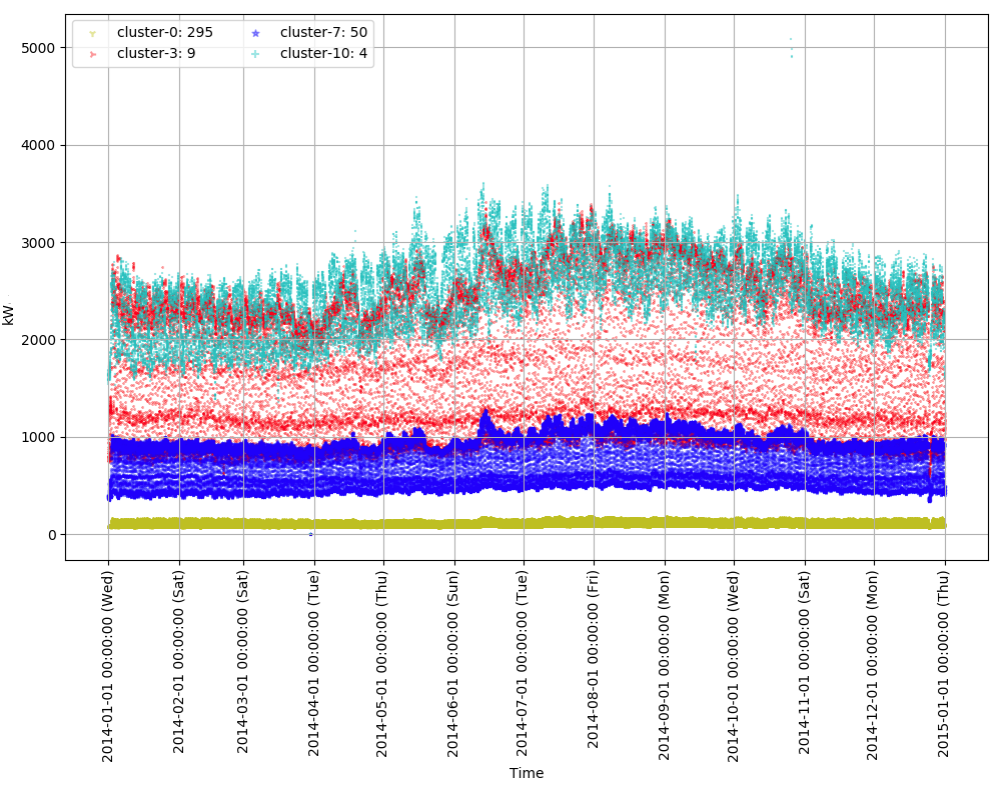
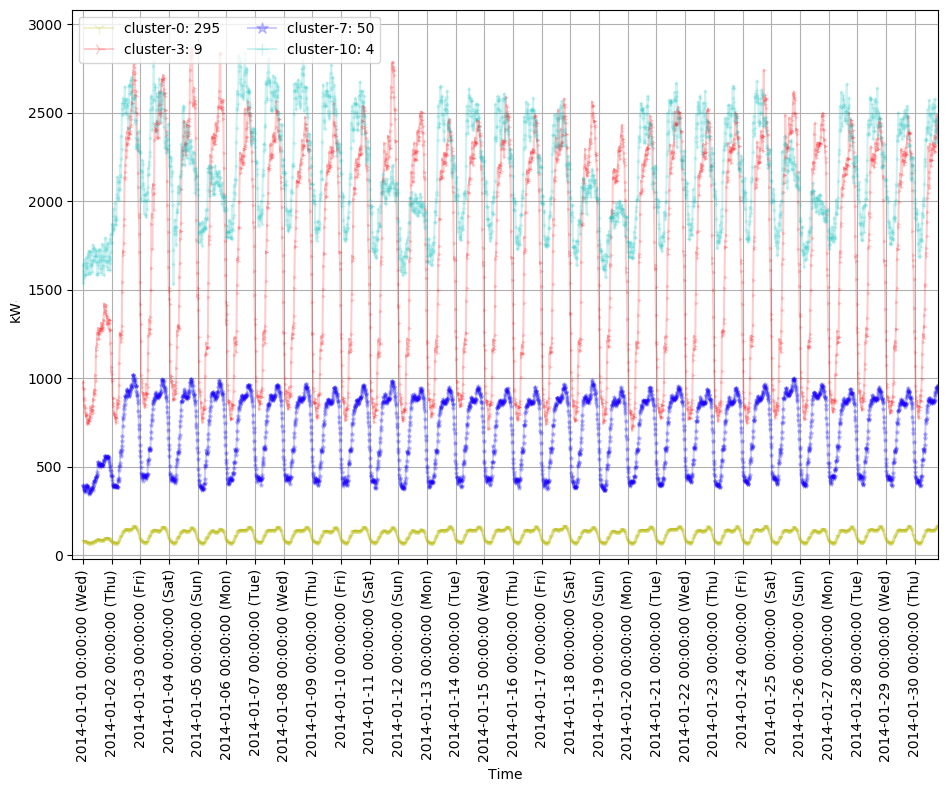
このグラフで一番目立つ特徴はcluster-0と7がとても安定的なパターンを見せているところです。消費電力を考えると、一般家庭ではないかと思われます。また、cluster-10は週末に掛けて消費電力が減る特徴を見せています。絶対値は6-7倍違いますが、以前見たcluster-2と同じ業種ではないかと考えられます。
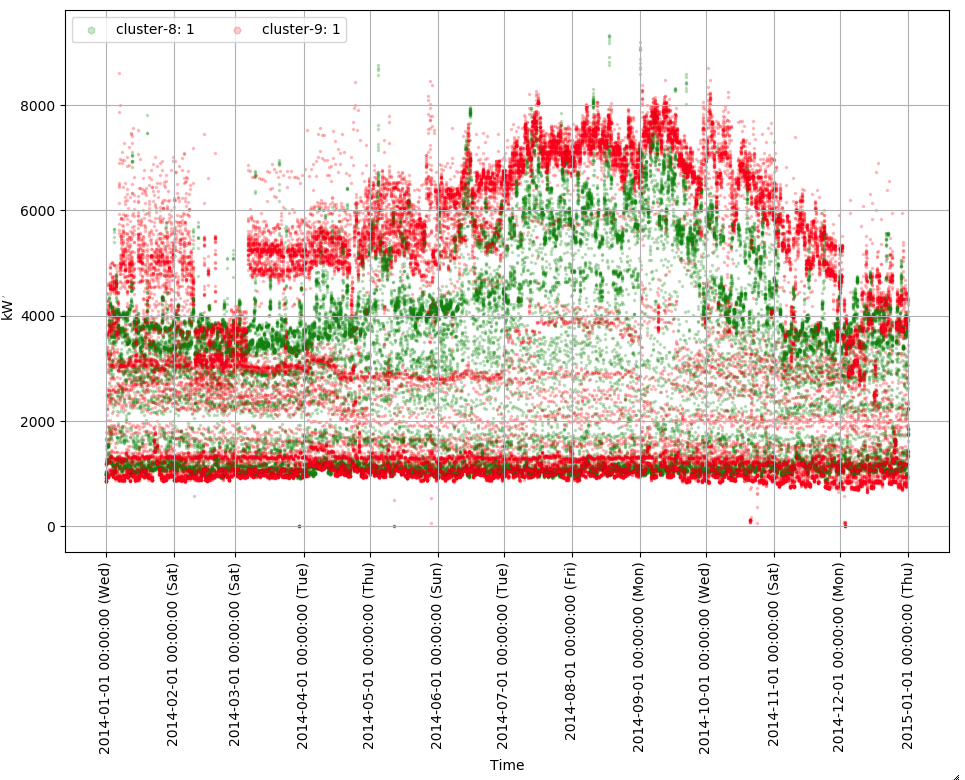
最後の消費電力が中間だった四つのクラスタ (cluster-4, 8, 9, 11)見てみます。こちらはcluster-8と9、cluster4と11を別のグラフで見せたいと思います。最初にcluster-8と9のグラフを見てみましょう。cluster-8と9のグラフは両方消費電力の最小・最大値の差が大きく、絶対値としてはお互い似ています。別のクラスタとして認識されたことは、cluster-9に属する時系列データでは2月から3月に掛けて最大消費電力が他の時期の半分以下になったことがありますが、これが原因で別のクラスタとして認識されたと思われます。
しかし、このような極端な消費電力の差がある業種はどのようなものがあるのでしょうか。なかなか思いつかない部分です。
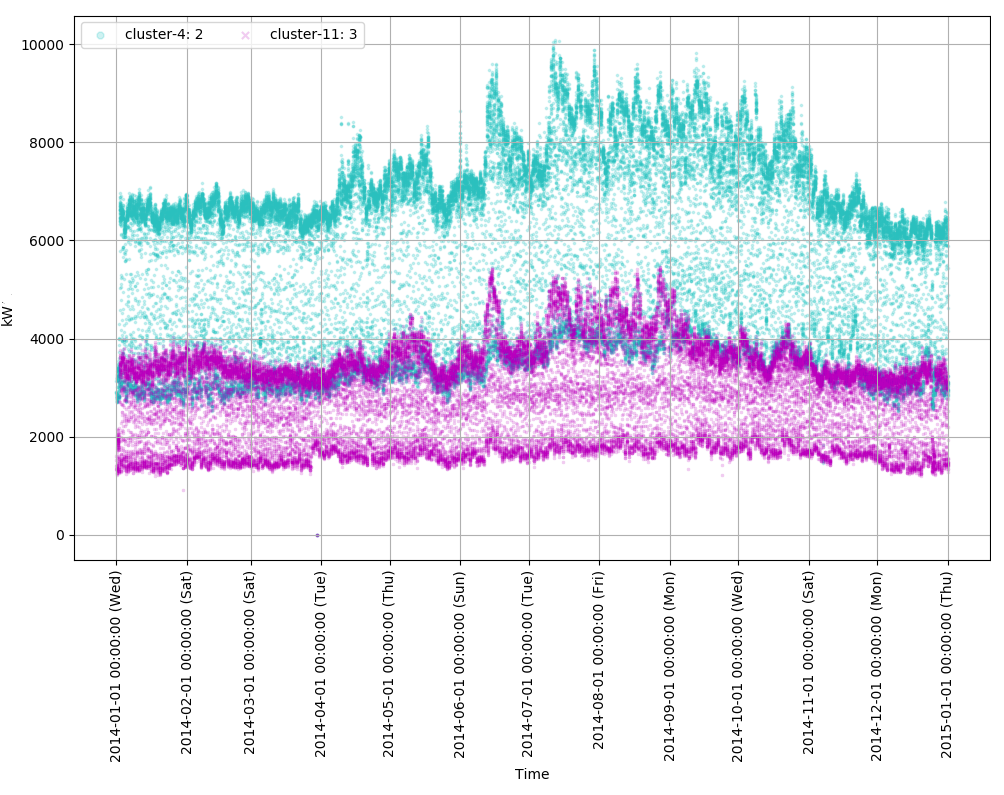
続けて、cluster-4と11を比較してみると、とても綺麗に二分されています。パターンの傾向としてはとても似ていますので、これもまた規模が違う同じ業種のクライアントではないかと考えられます。
5. まとめ
今回のポストでは、代表的な時系列データである消費電力データにクラスタリング手法を適用することで、頻出する時系列パターンを調べてみました。
単位時間の消費電力という一つの特徴量だけで構成されているデータなので最初は簡単に目に見える結果が得られると思ったのですが、実際にはなかなか解析が難しい部分も多くありました。
今後は多変数データやDTWを利用した時間軸のズレを補完する手法などもポストしたいと思うのでお楽しみにしてください。
AWSのビッグデータ活用・機械学習導入支援サービス
これからビッグデータ活用を始める方にオススメ!

AIブームなどにより、先端ビジネスの主要テーマのひとつとなっている「ビッグデータ」。事例を交えながら、ビッグデータの解析や活用方法について解説します。


Recommends
こちらもおすすめ
-

相関係数は外れ値の影響をうけやすい?Pythonで確認してみた。
2018.2.28
-

R からシームレスに Python を呼べる reticulate が便利だった
2018.4.13
-

PythonやR言語で相関係数を計算する方法
2018.2.20
-

Pythonで実装する画像認識アルゴリズム SLIC 入門
2018.2.13
-

TensorFlowとKerasで画像認識する方法
2017.12.6

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16