GoogleのCloud Vision APIの文字認識を試す

こんにちは。データサイエンスチームのtmtkです。
この記事では、GoogleのCloud Vision APIの文字認識機能をいろいろな画像で試してみます。
Cloud Vision APIとは
Cloud Vision APIは、Googleが出しているサービスです。画像認識機能をクラウド上のAPIとして気軽に使うことができます。
公式ページによると、
光学式文字認識(OCR)
画像内のテキストを検出、抽出できます。数多くの言語に対応しており、言語の種類も自動で判別されます。PDF ファイル、TIFF ファイル、画像(PNG ファイルや GIF ファイルなど)をアップロードできます。サポートされているファイルの詳細については、こちらをご覧ください。
手書き入力認識ベータ版
Vision API を使用すると、印刷テキストだけでなく手書き入力も認識できます。
ということで、画像の中の文字を認識する機能があるようなので、実際に試してみます。
光学式文字認識(OCR)
まずはこの画像で試してみます。

光学式文字認識機能は、Cloud Vision APIのページから試すことができます。「Drag image file here or Browse form your computer」と書いてあるところをクリックし、画像をアップロードします。
画像をアップロードすると、APIによる分析結果が表示されます。
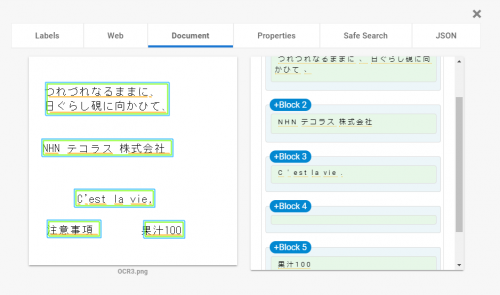
「Document」と書いてあるタブから光学式文字認識の結果をみると、すべての文字の部分がAPIによって発見されていることがわかります。ただし、「注意事項」と書いた部分は枠は正しく表示されているものの、「注意事項」という文字は抽出できていないようです。
次に、さらに難易度を上げて、次の画像で試してみます。

文字にオレンジのブラシでノイズを入れたり、白のブラシで劣化させたり、フォントや字体を変えたり、手書き文字を追加したりしています。
これをAPIに投げると、以下のような結果を得られました。

「日」が「目」、「硯」が「観」、「テ」が「デ」と認識されてしまいました。手書きで「tmtk」と書いた部分は認識できていません。どうやら、ノイズにはある程度強いが、やはりノイズが入ると認識制度が落ちてしまうようです。また、「手書き入力機能」という機能が別途あることから推測すると、手書きの文字はあまり得意でないようです。
手書き入力認識
Cloud Vision APIには、まだベータ版ながら、手書き入力認識機能もあるようです。公式のチュートリアルの”Detecting Handwriting”の部分に手書き入力認識についての記述があります。ただし、11/02(金)現在、日本語版のドキュメントには記載がないので、英語版を見る必要があります(言語切り替えはページの一番左下)。
このチュートリアルにしたがってさきほどの画像から手書き入力認識をさせた結果、
つれづれなるままに、 目ぐらし観に向かひて、 NHN デコラス 株式会社 C'est la vie tmtk
という結果を得ることができました。ノイズの影響は受けてしまっていますが、手書きの「tmtk」の部分もうまく抽出できています。ただし、チュートリアルのサンプルコード中の
image_context = vision.types.ImageContext(
language_hints=['en-t-i0-handwrit'])
は、
image_context = vision.types.ImageContext(
language_hints=["ja-t-i0-handwrit", "en-t-i0-handwrit"])
に変更して実行しました。こうすることによって、日本語と英語のどちらにも対応して文字認識を実行できるようになると思われます。
参考までに、 language_hints を変更せずそのまま実行すると、
Nontatti A5 LAUT NHN 7332 MIA I f'est la vie tmtk
と出力されてしまい、アルファベットの部分はともかく、日本語の部分が正しく抽出できませんでした。
まとめ
GoogleのCloud Vision APIの文字認識機能を試してみました。日本語の文字を入力する場合は、 language_hints を正しく指定するのが重要そうです。
この機能を使えば、紙で保管されている資料の電子化などが効率的にできそうです。

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

画像分類の機械学習モデルを作成する(1)ゼロからCNN
2018.4.17
-

TensorFlowとKerasで画像認識する方法
2017.12.6
-

可分な畳み込みカーネルと計算量の話
2018.7.18
-

畳み込みニューラルネットワークの畳み込み層の重みを可視化する方法
2018.7.10

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16