中央値を線形時間で選択するアルゴリズムについて

こんにちは。データサイエンスチームのtmtkです。
この記事では、中央値を線形時間で選択するアルゴリズムを知って驚いたという話をします。
はじめに
最近、T. コルメン他『アルゴリズムイントロダクション 第3版 第1巻: 基礎・ソート・データ構造・数学』(原著:『Introduction to Algorithms』)を始めのほうだけ読みました。わかりやすく書かれており、とてもいい本だと思います。
この本の9.3節では「線形最悪時間選択アルゴリズム」というものが紹介されています。これはn個の要素をもつ集合のi番目に小さい要素を計算量
プログラミング言語としては、Python 3で説明します。
最大値の線形時間選択アルゴリズム
最大値を計算するアルゴリズムを考えてみましょう。これは、上で述べた問題でi = nの場合に対応します。
Pythonでは組み込み関数 max() がありますが、それを使わないでリストから最大の要素を返す関数 max() を書いてみると、以下のようになると思います。
def max(lst):
"""Handmade max function"""
if not lst:
return None
ret = lst[0]
for elem in lst:
if elem > ret:
ret = elem
return ret
これの計算量は明らかに
中央値の場合は?
中央値は、最大値と同じ方針で計算するのは難しそうです。中央値の計算を実装するとしたら、ソートを使って以下のようにすることを思いつくのではないでしょうか。
def median(lst):
"""Calclate median by sorting"""
if not lst:
return None
lst_sorted = sorted(lst)
return lst_sorted[(len(lst) - 1) // 2]
このコードの計算量は、ソート部分で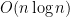
実はで計算できる
中央値を計算するのにソートアルゴリズムを使ってしまうと、計算量が
アルゴリズムそのものは本でよく説明されているのでここで説明することは省略し、本の説明をそのままPythonのコードに落とし込んでみます。ただし、挿入ソートを使うように書いてある場所でPython組み込みの sorted() 関数を使用することにします。ここでソートするのは要素が高々5つ以下のリストなので、大きな問題ではないと思います。
def partition(lst, pivot):
"""Modifired partition algorithm in section 7.1"""
pivot_idx = None
for idx, value in enumerate(lst):
if value == pivot:
pivot_idx = idx
if pivot_idx is None:
raise Exception
lst[pivot_idx], lst[-1] = lst[-1], lst[pivot_idx]
pivot = lst[-1]
i = -1
for j, val in enumerate(lst[:-1]):
if val <= pivot:
i += 1
lst[i], lst[j] = lst[j], lst[i]
lst[i + 1], lst[-1] = lst[-1], lst[i + 1]
return i + 1
def select(lst, i):
"""Selection in linear time"""
if len(lst) == 1:
return lst[0]
split_lists = [lst[i * 5: (i + 1) * 5] for i in range((len(lst) + 4) // 5)]
split_list_medians = [
sorted(split_list)[(len(split_list) - 1) // 2]
for split_list in split_lists
]
x = select(split_list_medians, (len(split_list_medians) - 1) // 2)
k = partition(lst, x)
if i == k:
return x
elif i < k:
return select(lst[:k], i)
else:
return select(lst[k + 1:], i - (k + 1))
def median_linear(lst):
"""Calculate median by selection algorithm"""
return select(lst, (len(lst) - 1) // 2)
関数 partition() はクイックソートにも使われているアルゴリズムです。ピボットとして末尾の要素を使うことが多いと思いますが、ここではピボットを選択できるように修正しています。
関数 select() は「線形最悪時間選択アルゴリズム」で、引数にとったリスト lst の i 番目に小さい要素を線形時間で返す関数です。
関数 median_linear() が線形時間で中央値を選択する関数です。これは select() を利用しており、 select() が線形時間で実行できるため、median_linear() 自身も線形時間で実行できます。
線形時間かどうか実験的に確かめる
それでは、この関数 median_linear() が本当に線形時間になっているのか、実験的に確かめてみます。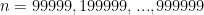
import numpy as np
for i in range(1, 10 + 1):
size = i * 100000 - 1
arr = np.random.rand(size)
%time median_linear(arr)

可視化すると、リストの大きさに対して実行時間がほぼ線形に伸びていることがわかると思います。
まとめ
この記事では、線形最悪時間選択アルゴリズムを紹介しました。これを使うと計算量
参考文献
- T. コルメン他『アルゴリズムイントロダクション 第3版 第1巻: 基礎・ソート・データ構造・数学』
- 中央値の中央値 – Wikipedia
- 選択アルゴリズム – Wikipedia

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

機械学習を学ぶための準備 その1(微分について)
2015.11.24
-

口コミデータを活用したレコメンドシステムの可能性
2017.12.7
-

機械学習を学ぶための準備 その2(級数と積分について)
2015.12.2
-

チュートリアルをやってみよう
2024.3.8


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16