ニューラルネットワークモデルの容量と汎化性能について-「Understanding deep learning requires rethinking generalization」を読む-

こんにちは。データサイエンスチームのtmtkです。
この記事では、Chiyuan Zhangらによる論文「Understanding deep learning requires rethinking generalization」の一部を解説・追試します。
はじめに
今回紹介する論文「Understanding deep learning requires rethinking generalization」はディープラーニングの汎化誤差(=訓練誤差とテスト誤差の差)についての論文です。論文中では、
- Randomization tests
- The role of explicit regularization
- Finite-sample expressivity
- The role of implicit regularization
の4つの貢献が挙げられています。この記事では、このうち「Randomization tests」と「Finite-sample expressivity」の部分について解説します。
この論文はICLR 2017でBest Paper Awardに選出されています。
Randomization tests
「Randomization tests」の項目は、「ディープラーニングモデルの訓練データのラベルをランダムなものに入れ替えても、モデルは学習ができる」というものです。
論文中では、著者らはCIFAR-10とImageNetのラベルをランダムに入れ替えたものをInception V3やAlexnetなどで学習させています。
実際に追試してみましょう。今回はGoogle Colabのノートブックで、ランタイムをPython 3 + GPUにしたもので実験しています。ライブラリはKerasを使います。
著者らはInceptionやAlexnetなどで実験していますが、今回は時間の節約のためにより小さいネットワークで実験することにします。ネットワーク構造はKerasのMNIST用CNNの例を参考にした小さなCNNです。論文と設定を似せるためにDropoutなどの正則化は除いています。
まず必要なライブラリをimportし、定数を定義します。
import numpy as np import keras from keras.datasets import cifar10 from keras.models import Model from keras.layers import Dense, Flatten from keras.layers import Conv2D, MaxPooling2D, Input batch_size = 128 num_classes = 10 epochs = 100
次に、データセットとモデルを用意する関数を定義します。データとモデルを準備して返すだけです。
def prepare():
img_rows, img_cols = 32, 32
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.reshape(len(x_train), img_rows, img_cols, 3)
x_test = x_test.reshape(len(x_test), img_rows, img_cols, 3)
x_train = x_train.astype("float32")
x_test = x_test.astype("float32")
x_train /= 255
x_test /= 255
ipt = Input(shape=(img_rows, img_cols, 3))
x = Conv2D(32, (3, 3), activation="relu")(ipt)
x = Conv2D(64, (3, 3), activation="relu")(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
x = Dense(128, activation="relu")(x)
out = Dense(num_classes, activation="softmax")(x)
model = Model(inputs=[ipt], outputs=[out])
model.compile(
loss=keras.losses.sparse_categorical_crossentropy,
optimizer=keras.optimizers.SGD(0.01, momentum=0.9),
metrics=["accuracy"],
)
return x_train, x_test, y_train, y_test, model
まずは通常通りに学習をしてみます。
x_train, x_test, y_train, y_test, model = prepare()
true_labels_history = model.fit(
x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[
keras.callbacks.LearningRateScheduler(
lambda _, lr: lr * 0.95
)
],
)
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
すると、23 epoch目で訓練データに対する正確度(accuracy)が1.0000になりました。また、学習完了後、テストデータセットに対して正確度が0.6759となりました。CIFAR-10は10クラス分類なので、正確度がランダムな1/10=0.1より大きいこのモデルはランダムよりも有意に正しく分類ができていることがわかります。
次に、ラベルを完全にランダムに振りなおして学習をします。
x_train, x_test, y_train, y_test, model = prepare()
# ランダムなラベルを振りなおす
y_train = np.random.randint(num_classes, size=len(x_train))
random_labels_history = model.fit(
x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[
keras.callbacks.LearningRateScheduler(
lambda _, lr: lr * 0.95
)
],
)
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
今度は63 epoch目で訓練データに対する正確度が1.0000になりました。なお、学習完了後のテストデータセットに対する正確度は0.0979でした。ランダムなラベルを学習しているので、テストデータについている正常なラベルについては当然何も学習ができていません。
これら2つの場合について、学習の推移を可視化すると以下のようになります。
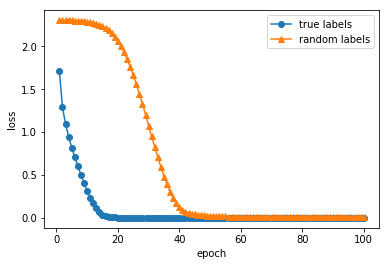
収束までのエポック数に差はありますが、ラベルや画素をランダム化した場合でも損失関数がほぼ0に収束しています。実際、どちらの場合でも訓練データに対する正確度が100%に達していました。
つまり、この畳み込みニューラルネットワークは、ラベルがランダムな場合であっても学習データのサンプルすべてのラベルを記憶することができるということになります。
この研究は、Mikhail Belkinらによる従来のU字型のbias-variance trade-offの「先」の現象があると主張する「Reconciling modern machine learning practice and the bias-variance trade-off」などに発展しているようです。
なお、元の論文中では、サンプルの一部に対してラベルをランダム化する実験や、画像中の画素の位置をランダムに入れ替える実験なども行われています。また、VC次元などとの関連も議論されています。より詳しくは、元の論文をご覧ください。
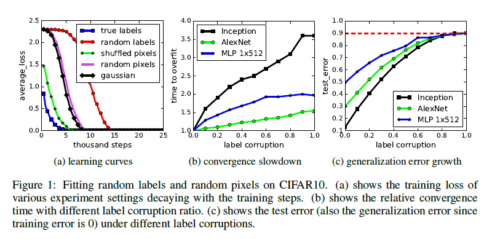 (元論文の図1)
(元論文の図1)
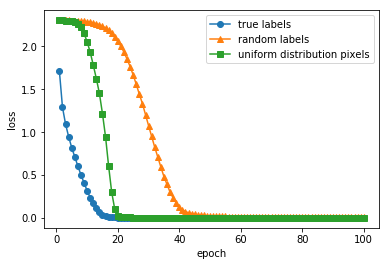
元論文では行われていませんが、画素をランダムな一様分布から生成した場合( x_train = np.random.random(x_train.shape) )にも、同様に訓練誤差が0近くに収束し訓練データに対する正確度が100%に達しました。収束の様子は真のラベルの場合とランダムなラベルの場合の中間くらいでした。元の論文中の「Gaussian」(正規分布から生成した画素で学習)や「Random pixels」(画像ごとに画像内でランダムに画素を並び替えたもので学習)と同じような結果だと思います。
Finite-sample expressivity
「Finite-sample expressivity」は、普遍近似定理(Universal approximation theorem)のサンプルサイズ有限の場合といった内容です。
普遍近似定理はGeorge Cybenko「Approximations by superpositions of sigmoidal functions」のものが有名です。これは「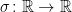
![I^n = [0, 1]^n](https://s0.wp.com/latex.php?latex=I%5En+%3D+%5B0%2C+1%5D%5En&bg=ffffff&fg=000&s=0&c=20201002)

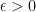
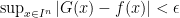

普遍近似定理で考えられている状況は、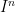
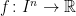
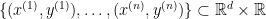

さて、本題に入ります。この論文で述べられている「Finite-sample expressivity」に関する定理は、次のものです。
Theorem 1.
There exists a two-layer neural network with ReLU activations and
weights that can represent any function on a sample of size
in
dimensions.
定理1
サイズ
証明は、条件を満たす2層のニューラルネットワークを具体的に構成する形で書かれています。定理の言明では「ニューラルネットワークのパラメータが
論文中の証明にしたがえば、言明中のニューラルネットワークは、以下の形式で構成されます。パラメータとして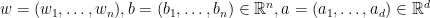
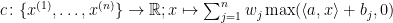
と表されます。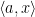


先ほどの式は別の書き方をすると、
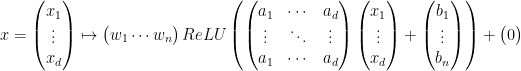
と書くことができます。ただしベクトルに対する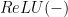
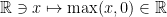
この式を踏まえて改めてこの関数をあらわすニューラルネットワークについて考えてみましょう。層の構成としては、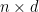





注意すべき点として、階数1の行列


また、隠れ層から出力層にかけての計算ではReLU関数が活性化関数として使われていないことに注意する必要があると思います。もっとも、十分大きい定数
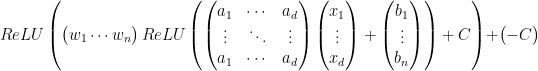
とすれば、すべての層がReLU関数で活性化された
論文中では、2層の場合のみならず一般に深さ
まとめ
この記事では、Chiyuan Zhangらによる論文「Understanding deep learning requires rethinking generalization」の一部を紹介・追試しました。
ニューラルネットワークはラベルをランダムに変更して学習しても、訓練誤差を0に収束させることができます(できることがあります)。
また、サイズ
論文では他にも正則化についてなど述べられています。詳しくは元の論文をご覧ください。

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

高速フーリエ変換で畳み込みを高速化する 2. 高速フーリエ変換(FFT)入門
2018.7.26
-

5分でわかる、1時間でできる、 OSSコントリビューション
2017.10.23
-

画像分類の機械学習モデルを作成する(3)転移学習で精度100%
2018.5.9


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16