SageMaker Clarify を用いた機械学習モデルのバイアス検出と説明可能性

こんにちは。データサイエンスチームの t2sy です。
近年、機械学習の活用の広がりや法規制などの社会環境の変化を背景として、公平性配慮型機械学習 (fairness-aware machine learning) と呼ばれる公平性・中立性などを考慮に入れた機械学習の手法や、機械学習モデルの説明可能性 (explainability) のための手法が注目を集めています。昨年の AWS re:Invent 2020 では、データと機械学習モデルのバイアス検出と説明可能性のための Amazon SageMaker の機能としてAmazon SageMaker Clarify が発表されました。
公平性配慮型機械学習では、与信や採用などを決定する分析において、社会的公平性や法規制の観点で考慮すべき性別や年齢などの属性情報をセンシティブな特徴、データや異なるグループに対するモデルの予測の振る舞いにおける不均衡性をバイアスと言います。
この記事では、Amazon SageMaker Clarify の使用例として Loan Payments Data からロジスティック回帰モデルを構築し、Amazon SageMaker Clarify を用いてデータとモデルのバイアス指標を計算、モデルの説明可能性のために予測結果に対する特徴量の寄与を SHapley Additive exPlanations (SHAP) で調べてみます。
今回は、Amazon SageMaker Studio の Notebook から Amazon SageMaker の各種機能を利用します。Amazon SageMaker Studio は、モデルの構築、トレーニング、デプロイなど機械学習のワークロードに必要な Amazon SageMaker の機能を1箇所から実行・管理することができる統合開発環境 (IDE) です。
データセットの準備
今回は、データセットに Loan Payments Data を使用します。リンク先から csv ファイルをダウンロードします。ダウンロードには Kaggle アカウントが必要になります。
AWS マネジメントコンソールから Amazon S3 コンソールにアクセスしバケットを作成します。ダウンロードした csv ファイルを作成したバケットにアップロードします。
次に、AWS マネジメントコンソールから Amazon SageMaker コンソールにアクセスし SageMaker Studio を起動します。
SageMaker Studio の Launcher から Notebook を選択します。Kernel は Data Science (Python3) を選択します。この Kernel には Amazon SageMaker Python SDK が組み込まれています。
分析に必要なパッケージをインポートします。bucket、prefix 変数の値は適宜変更して下さい。
from sagemaker import Session session = Session() bucket = "sagemaker-clarify-example" prefix = 'sagemaker/sagemaker-clarify-techblog' region = session.boto_region_name # Define IAM role from sagemaker import get_execution_role import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn import preprocessing from sklearn.model_selection import train_test_split import urllib import os role = get_execution_role()
S3 からデータセットを読み込みます。
df = pd.read_csv(f"s3://{bucket}/{prefix}/loan_payments_data.csv")
df.head()
Loan_ID loan_status Principal terms effective_date due_date paid_off_time past_due_days age education Gender
0 xqd20166231 PAIDOFF 1000 30 9/8/2016 10/7/2016 9/14/2016 19:31 NaN 45 High School or Below male
1 xqd20168902 PAIDOFF 1000 30 9/8/2016 10/7/2016 10/7/2016 9:00 NaN 50 Bechalor female
2 xqd20160003 PAIDOFF 1000 30 9/8/2016 10/7/2016 9/25/2016 16:58 NaN 33 Bechalor female
3 xqd20160004 PAIDOFF 1000 15 9/8/2016 9/22/2016 9/22/2016 20:00 NaN 27 college male
4 xqd20160005 PAIDOFF 1000 30 9/9/2016 10/8/2016 9/23/2016 21:36 NaN 28 college female
読み込んだデータセットは500行11列で構成されています。
df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 500 entries, 0 to 499 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Loan_ID 500 non-null object 1 loan_status 500 non-null object 2 Principal 500 non-null int64 3 terms 500 non-null int64 4 effective_date 500 non-null object 5 due_date 500 non-null object 6 paid_off_time 400 non-null object 7 past_due_days 200 non-null float64 8 age 500 non-null int64 9 education 500 non-null object 10 Gender 500 non-null object dtypes: float64(1), int64(3), object(7) memory usage: 43.1+ KB
データセットに含まれる各列の意味は以下です。
| Column | Description |
|---|---|
| Loan_ID | ローン利用者に割り当てられたID |
| loan_status | ローンの返済状況 |
| Principal | ローン借入額 |
| terms | ローン返済期間 |
| effective_date | ローン発効日 |
| due_date | ローン返済期日 |
| paid_off_time | ローンが返済された日 (返済されていない場合はnull) |
| past_due_days | ローン返済期日からの経過日数 |
| age | ローン利用者の年齢 |
| education | ローン利用者の教育レベル |
| Gender | ローン利用者の性別 |
実際のデータセットを分析する上では、標本選択バイアス (sample selection bias) に気をつける必要があります。Loan Payments Data にはローン申請時の審査に通ったデータのみが含まれており、審査に通らなかったデータは含まれていません。この場合、分析の目的によっては機械学習モデルを適切に学習することはできません。
日付を表す列の型を文字列型から datetime64 型に変換します。
def preprocess(df: pd.DataFrame) -> pd.DataFrame:
"""Convert str to datetime64 and extract weekday"""
df["effective_date"] = pd.to_datetime(df["effective_date"])
df["due_date"] = pd.to_datetime(df["due_date"])
df["paid_off_time"] = pd.to_datetime(df["paid_off_time"])
df["day"] = df["effective_date"].dt.dayofweek
df["weekend"] = df["day"].apply(lambda x: 1 if x > 3 else 0)
return df
df = preprocess(df)
ローンの返済状況を表す loan_status には PAIDOFF、COLLECTION_PAIDOFF、COLLECTION の3つの値が含まれています。PAIDOFF は返済期日までに返済を完了したこと、COLLECTION_PAIDOFF は返済期日の後に返済を完了したこと、COLLECTION は返済が完了していないことを表します。全体に対する割合は、PAIDOFF が60%、COLLECTION_PAIDOFF と COLLECTION が 20% です。
df["loan_status"].value_counts() PAIDOFF 300 COLLECTION_PAIDOFF 100 COLLECTION 100 Name: loan_status, dtype: int64
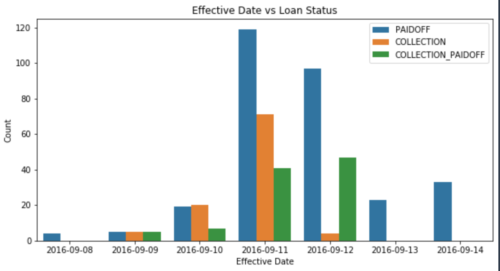
ローン発効日と返済状況の関係を可視化してみます。2016-09-09、2016-09-10、2016-09-11 の週末3日間は、loan_status が COLLECTION である割合が他の曜日に比べ高いことがわかります。
plt.figure(figsize=[10, 5])
sns.countplot(x=df["effective_date"].dt.date, hue=df["loan_status"])
plt.legend(loc="upper right")
plt.title("Effective Date vs Loan Status")
plt.xlabel("Effective Date")
plt.ylabel("Count")
plt.show()
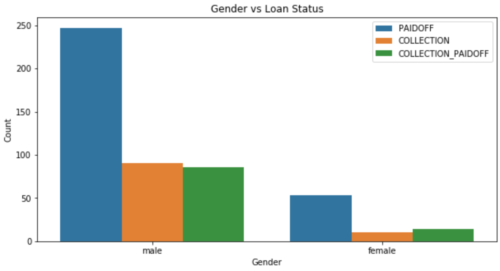
次に、性別と返済状況の関係を可視化してみます。全体の 84.6% が男性であることから性別に対して不均衡なデータであることがわかります。SageMaker Clarify を使用すると、機械学習モデルの訓練を実行する前にデータセットに含まれるバイアスを検出することができます。[1]
plt.figure(figsize=[10, 5])
sns.countplot(df["Gender"], hue=df["loan_status"])
plt.legend(loc="upper right")
plt.title("Gender vs Loan Status")
plt.xlabel("Gender")
plt.ylabel("Count")
plt.show()
データの前処理
今回は、SageMaker Clarify の利用例として、ローンを返済期日内に返済を完了したか否かを予測するロジスティック回帰モデルを構築してみます。
目的変数は loan_status が COLLECTION_PAIDOFF、COLLECTION を 0、PAIDOFF の場合に 1 となるように符号化します。また、この例では、モデルがバイアスを生じさせる可能性があるセンシティブな特徴として性別に注目し、性別 (カテゴリカル特徴) を数値に変換します。
def encode(df: pd.DataFrame) -> pd.DataFrame:
"""Encoding Categorical Values"""
df["Gender"].replace(to_replace=["male", "female"], value=[0, 1], inplace=True)
df["loan_status"].replace(
to_replace=["PAIDOFF", "COLLECTION_PAIDOFF", "COLLECTION"],
value=[1, 0, 0],
inplace=True,
)
df_education_vec = pd.get_dummies(df["education"])
return pd.concat([df, df_education_vec], axis=1)
df = encode(df)
データセットを訓練データとテストデータに分割した後、特徴を sklearn.preprocessing.StandardScaler
で標準化します。
target_column = ["loan_status"]
numeric_columns = ["Principal", "terms", "age"]
categorical_columns = ["Gender", "weekend", "Bechalor", "High School or Below", "college"]
df_train, df_test = train_test_split(
df[target_column + numeric_columns + categorical_columns],
test_size=0.2,
random_state=42
)
scaler = preprocessing.StandardScaler().fit(df_train[numeric_columns])
scaled_train = scaler.transform(df_train[numeric_columns])
scaled_test = scaler.transform(df_test[numeric_columns])
df_train = pd.concat(
[
df_train["loan_status"].reset_index(drop=True),
pd.DataFrame(scaled_train, columns=numeric_columns),
df_train[categorical_columns].reset_index(drop=True),
],
axis=1,
)
df_test = pd.concat(
[
pd.DataFrame(scaled_test, columns=numeric_columns),
df_test[categorical_columns].reset_index(drop=True),
],
axis=1,
)
訓練データの概観を確認します。
df_train.head() loan_status Principal terms age Gender weekend Bechalor High School or Below college 0 1 0.482146 -0.937928 0.692870 1 0 1 0 0 1 0 0.482146 0.916295 -0.301086 0 1 0 0 1 2 1 -1.232151 0.916295 -0.798063 0 1 0 0 1 3 0 0.482146 0.916295 1.024188 0 1 0 0 1 4 0 0.482146 0.916295 -1.626359 0 1 0 1 0
訓練データとテストデータを S3 にアップロードします。
df_train.to_csv('train.csv', index=False, header=False)
df_test.to_csv('test.csv', index=False, header=False)
# upload to s3
from sagemaker.s3 import S3Uploader
from sagemaker.inputs import TrainingInput
train_uri = S3Uploader.upload('train.csv', f"s3://{bucket}/{prefix}/train")
train_input = TrainingInput(train_uri, content_type='csv')
test_uri = S3Uploader.upload('test.csv', f"s3://{bucket}/{prefix}/test")
トレーニングジョブの実行
次に、scikit-learn でロジスティック回帰モデルを構築します。今回は scikit-learn 用のビルド済み SageMaker Docker イメージを利用してモデルの訓練を行います。
モデルの訓練をコンテナ上で行うための Python スクリプトを準備します。Notebook の %%writefile マジックコマンドを使うことで、以降のセル内容がインスタンス内にファイル保存されます。
%%writefile sklearn_train.py
import joblib
import argparse
import os
import pandas as pd
from sklearn.linear_model import LogisticRegression
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--penalty", type=str, default="l2")
parser.add_argument("--tol", type=float, default=0.0001)
parser.add_argument("--C", type=float, default=1.0)
parser.add_argument("--class_weight", type=float, default=None)
parser.add_argument("--random_state", type=int, default=None)
parser.add_argument("--solver", type=str, default="lbfgs")
parser.add_argument("--max_iter", type=int, default=100)
parser.add_argument("--multi_class", type=str, default="auto")
# Data, model, and output directories
parser.add_argument(
"--output-data-dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR")
)
parser.add_argument("--model-dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
parser.add_argument("--train", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
parser.add_argument("--test", type=str, default=os.environ.get("SM_CHANNEL_TEST"))
args, _ = parser.parse_known_args()
input_files = [os.path.join(args.train, file) for file in os.listdir(args.train)]
if len(input_files) == 0:
raise ValueError(
(
"There are no files in {}.\n"
+ "This usually indicates that the channel ({}) was incorrectly specified,\n"
+ "the data specification in S3 was incorrectly specified or the role specified\n"
+ "does not have permission to access the data."
).format(args.train, "train")
)
raw_data = [pd.read_csv(file, header=None, engine="python") for file in input_files]
train_data = pd.concat(raw_data)
# labels are in the first column
train_y = train_data.iloc[:, 0]
train_X = train_data.iloc[:, 1:]
# Now use scikit-learn's logistic regressor to train the model.
clf = LogisticRegression(
penalty=args.penalty,
tol=args.tol,
C=args.C,
class_weight=args.class_weight,
random_state=args.random_state,
solver=args.solver,
max_iter=args.max_iter,
multi_class=args.multi_class,
)
clf = clf.fit(train_X, train_y)
# Print the coefficients of the trained classifier, and save the coefficients
joblib.dump(clf, os.path.join(args.model_dir, "model.joblib"))
def model_fn(model_dir):
"""Deserialized and return fitted model
Note that this should have the same name as the serialized model in the main method
"""
clf = joblib.load(os.path.join(model_dir, "model.joblib"))
return clf
スクリプトの詳しい記述方法は Using Scikit-learn with the SageMaker Python SDK をご覧ください。
sklearn.linear_model.LogisticRegression のハイパーパラメータを以下のように指定し、SageMaker のトレーニングジョブを開始します。
from sagemaker.sklearn.estimator import SKLearn
sklearn_estimator = SKLearn(
entry_point='sklearn_train.py',
instance_type="ml.c4.xlarge",
framework_version='0.23-1',
role=role,
sagemaker_session=session,
hyperparameters={
'C' : 0.01,
'solver': 'liblinear',
'random_state': 42
},
output_path=f's3://{bucket}/{prefix}/model',
)
sklearn_estimator.fit({'train': f"s3://{bucket}/{prefix}/train",
'test': f"s3://{bucket}/{prefix}/test"})
トレーニングジョブが正常に終了したことを確認し、続いて SageMaker モデルを登録します。
model_name = 'clarify-example-model'
model = sklearn_estimator.create_model(name=model_name)
container_def = model.prepare_container_def()
session.create_model(model_name,
role,
container_def)
SageMaker Clarify の機能を利用する準備が整いました。
Amazon SageMaker Clarify
本題である SageMaker Clarify の各機能を使ってみます。
データとモデルのバイアス検出
最初に、SageMakerClarifyProcessor インスタンスを作成します。パラメータには、バイアス指標の計算を実行するインスタンスの数、インタンスタイプ、現在の Session Session オブジェクト等を設定します。
from sagemaker import clarify
clarify_processor = clarify.SageMakerClarifyProcessor(role=role,
instance_count=1,
instance_type='ml.m5.xlarge',
sagemaker_session=session)
次に、SageMaker Clarify がバイアス指標を計算するために必要な以下の Config を設定します。
- DataConfig
- ModelConfig
- ModelPredictedLabelConfig
- BiasConfig
DataConfig には入力データの S3 パス、バイアスレポートの出力 S3 パス、訓練データのラベル列やヘッダ情報などを設定します。
bias_report_output_path = f's3://{bucket}/{prefix}/clarify-bias'
bias_data_config = clarify.DataConfig(s3_data_input_path=train_uri,
s3_output_path=bias_report_output_path,
label='loan_status',
headers=df_train.columns.to_list(),
dataset_type='text/csv')
SageMaker Clarify はバイアス指標の計算のため SageMaker エンドポイントから推論を取得します。ModelConfig には訓練済みモデルの名前、モデルの推論が実行されるインスタンスの数、インタンスタイプを設定します。SageMaker エンドポイントは SageMakerClarifyProcessor インスタンスの run_bias() 呼び出し時に起動され、終了時に停止されます。
model_config = clarify.ModelConfig(model_name=model_name,
instance_type='ml.m5.xlarge',
instance_count=1,
accept_type='text/csv',
content_type='text/csv')
ModelPredictedLabelConfig にはモデルの予測値の形式を設定します。今回、ロジスティック回帰モデルは 0/1 の予測値を返すため設定は不要ですが、二値分類で確率を出力する場合は必要に応じて probability_threshold を設定、また、多クラス分類では分類ラベルと対応する確率の関係を設定する必要があります。
predictions_config = clarify.ModelPredictedLabelConfig()
BiasConfig には入力データのバイアスに関する情報を設定します。
label_values_or_threshold には目的変数が肯定的な結果を表す場合の値を設定します。今回は、ローンを返済期日内に返済完了した場合、目的変数を 1 としているため label_values_or_threshold に 1 を指定します。
SageMaker Clarify の文脈では、バイアスを調べたいセンシティブな特徴を facet と呼びます。facet_name と facet_values_or_threshold にはセンシティブな特徴を表す列名とその値を設定します。今回の例では、性別に関するバイアス有無に関心があるため、facet_name に Gender を指定、facet_values_or_threshold に性別が男性の場合である 0 を指定します。
group_name には Conditional Demographic Disparity in Labels (CDDL) と Conditional Demographic Disparity in Predicted Labels (CDDPL) を計算する場合に利用されるサブグループを指定します。
bias_config = clarify.BiasConfig(label_values_or_threshold=[1],
facet_name='Gender',
facet_values_or_threshold=[0],
group_name='age')
以上の各 Config を SageMakerClarifyProcessor インスタンスの run_bias() の各パラメータに設定し実行するとプロセッシングジョブが開始されます。
clarify_processor.run_bias(data_config=bias_data_config,
bias_config=bias_config,
model_config=model_config,
model_predicted_label_config=predictions_config,
pre_training_methods='all',
post_training_methods='all')
プロセッシングジョブが正常に終了すると、バイアス指標が Notebook の標準出力と S3 (bias_report_output_path) に出力されます。
{
"version": "1.0",
"post_training_bias_metrics": {
"label": "loan_status",
"facets": {
"Gender": [
{
"value_or_threshold": "0",
"metrics": [
{
"name": "AD",
"description": "Accuracy Difference (AD)",
"value": 0.0194363459669582
},
{
"name": "CDDPL",
"description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)",
"value": 0.1342240101852171
},
{
"name": "DAR",
"description": "Difference in Acceptance Rates (DAR)",
"value": -0.0007208650380456927
},
{
"name": "DCA",
"description": "Difference in Conditional Acceptance (DCA)",
"value": -0.18902683219863836
},
{
"name": "DCR",
"description": "Difference in Conditional Rejection (DCR)",
"value": -7.336206896551724
},
{
"name": "DI",
"description": "Disparate Impact (DI)",
"value": 0.6858733103631063
},
{
"name": "DPPL",
"description": "Difference in Positive Proportions in Predicted Labels (DPPL)",
"value": 0.30310470052682725
},
{
"name": "DRR",
"description": "Difference in Rejection Rates (DRR)",
"value": 0.5603448275862069
},
{
"name": "FT",
"description": "Flip Test (FT)",
"value": -0.33819241982507287
},
{
"name": "RD",
"description": "Recall Difference (RD)",
"value": 0.19519230769230766
},
{
"name": "TE",
"description": "Treatment Equality (TE)",
"value": 0.6109243697478991
}
]
}
]
},
"label_value_or_threshold": "1"
},
"pre_training_bias_metrics": {
"label": "loan_status",
"facets": {
"Gender": [
{
"value_or_threshold": "0",
"metrics": [
{
"name": "CDDL",
"description": "Conditional Demographic Disparity in Labels (CDDL)",
"value": 0.04322418152023414
},
{
"name": "CI",
"description": "Class Imbalance (CI)",
"value": -0.715
},
{
"name": "DPL",
"description": "Difference in Positive Proportions in Labels (DPL)",
"value": 0.09534039179581599
},
{
"name": "JS",
"description": "Jensen-Shannon Divergence (JS)",
"value": 0.005033822226910643
},
{
"name": "KL",
"description": "Kullback-Liebler Divergence (KL)",
"value": 0.01974252305081256
},
{
"name": "KS",
"description": "Kolmogorov-Smirnov Distance (KS)",
"value": 0.0953403917958161
},
{
"name": "LP",
"description": "L-p Norm (LP)",
"value": 0.1348316751196076
},
{
"name": "TVD",
"description": "Total Variation Distance (TVD)",
"value": 0.09534039179581605
}
]
}
]
},
"label_value_or_threshold": "1"
}
}
run_bias() ではデータとモデルのバイアス指標が共に得られますが、分けて取得することもできます。run_pre_training_bias() でデータのバイアス指標、run_post_training_bias() でモデルのバイアス指標を得ることができます。
データのバイアス指標
訓練前のデータのバイアス指標の結果は以下です。データのバイアス指標は facet を表す特徴を基準値によって分割し、2つの目的変数の確率分布の差異を測る方法などで計算するため、モデルに依存しない指標となります。各指標の定義は Measure Pretraining Bias をご覧ください。
| Name | Description | Value |
|---|---|---|
| CDDL | Conditional Demographic Disparity in Labels | 0.0432 |
| CI | Class Imbalance | -0.7150 |
| DPL | Difference in Positive Proportions in Labels | 0.0953 |
| JS | Jensen-Shannon Divergence | 0.0050 |
| KL | Kullback-Liebler Divergence | 0.0197 |
| KS | Kolmogorov-Smirnov Distance | 0.0953 |
| LP | L-p Norm | 0.1348 |
| TVD | Total Variation Distance | 0.0953 |
データのバイアス指標の多くが 0 に近い値であり、facet 間で目的変数に対するバイアスはそれほど大きくないことが示されています。一方で、データの可視化の段階で確認した通り、性別に対して不均衡なデータであることは CI (Class Imbalance) 値が -0.715 であることからわかります。
CI は facet が有利なグループ (advantage group) のサンプルサイズを 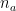


今回の例では、 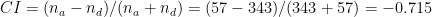
モデルの訓練前にデータのバイアスを検出することで、サンプルのリバランスや、センシティブな特徴をモデリングで使用しないなどの対策を検討することができます。
モデルのバイアス指標
訓練後のモデルのバイアス指標の結果は以下です。モデルのバイアス指標の多くは、facet ごとの混同行列 (Confusion Matrix) から計算されます。各指標の定義は Measure Posttraining Data and Model Bias をご覧ください。
| Name | Description | Value |
|---|---|---|
| AD | Accuracy Difference | 0.01943 |
| CDDPL | Conditional Demographic Disparity in Predicted Labels | 0.13422 |
| DAR | Difference in Acceptance Rates | -0.0007 |
| DCA | Difference in Conditional Acceptance | -0.18902 |
| DCR | Difference in Conditional Rejection | -7.33620 |
| DI | Disparate Impact | 0.68587 |
| DPPL | Difference in Positive Proportions in Predicted Labels | 0.30310 |
| DRR | Difference in Rejection Rates | 0.56034 |
| FT | Flip Test | -0.33819 |
| RD | Recall Difference | 0.19519 |
| TE | Treatment Equality | 0.61092 |
例として、上記の DI (Disparate Impact) について確認してみます。DI は facet のグループ間で予測値 

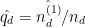
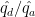
今回の例では、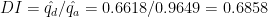
モデルのバイアス指標を解釈する際に、値範囲や解釈のための基準値はバイアス指標ごとに異なる点に気をつける必要があります。例えば、DCR 値の範囲は 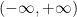
![[-1, +1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+%2B1%5D&bg=ffffff&fg=000&s=0&c=20201002)
モデルのバイアスは、機械学習アルゴリズムの補正や損失関数の工夫で対処することが可能です。
モデルの予測結果の理解
SageMaker Clarifyでは SHAP によってモデルの予測結果に対する特徴量の寄与を出力する機能があります。
最初に、DataConfig に入力データの S3 パス、SHAP レポートの出力 S3 パス、訓練データのラベル列やヘッダ情報などを設定します。
explainability_output_path = f's3://{bucket}/{prefix}/clarify-explainability'
explainability_data_config = clarify.DataConfig(s3_data_input_path=train_uri,
s3_output_path=explainability_output_path,
label='loan_status',
headers=df_train.columns.to_list(),
dataset_type='text/csv')
次に、SHAPConfig を設定します。SHAP の計算にはベースラインのデータが必要となります。今回は、SHAPConfig の baseline にテストデータのサンプルを設定します。また、agg_method に個々の SHAP 値から大域的な SHAP 値に集約するための方法を設定します。
shap_config = clarify.SHAPConfig(baseline=df_test.iloc[0:15].values.tolist(),
num_samples=30,
agg_method='mean_abs',
save_local_shap_values=False)
モデルのバイアス指標の取得時と同様に、SHAP の計算のため SageMaker エンドポイントから推論を取得するための情報を ModelConfig に設定します。今回は、バイアス指標と同じ設定を使用します。各 Config を SageMakerClarifyProcessor インスタンスの run_explainability() の各パラメータに設定し実行するとプロセッシングジョブが開始されます。
clarify_processor.run_explainability(data_config=explainability_data_config,
model_config=model_config,
explainability_config=shap_config)
プロセッシングジョブが正常に終了すると、各特徴に対する大域的な SHAP 値が Notebook の標準出力と S3 (explainability_output_path) に出力されます。
{
"version": "1.0",
"explanations": {
"kernel_shap": {
"label0": {
"global_shap_values": {
"Principal": 0.09829254607723632,
"terms": 0.22159938886940866,
"age": 0.0427517681079289,
"Gender": 0.08525204893106522,
"weekend": 0.18625003219016645,
"Bechalor": 0.04045644514193481,
"High School or Below": 0.08248813298151138,
"college": 0.10636776835233074
},
"expected_value": 0.6666666666666666
}
}
}
}
今回の例では、線形モデルのため偏回帰係数や標準誤差が重要な判断材料となりますが、近年は大規模で複雑なモデルを扱う機会が増えてきており SHAP がモデルの理解に役立つこともあるかと思います。
最後に SageMaker モデルを削除します。
session.delete_model(model_name)
おわりに
この記事では、データや機械学習モデルのバイアス検出やモデルの説明可能性のための Amazon SageMaker の機能である Amazon SageMaker Clarify を紹介しました。また、Amazon SageMaker Clarify の使用例として、Loan Payments Data からロジスティック回帰モデルを構築し、データとモデルのバイアス指標を計算、SHAP でモデルの予測結果に対する特徴量の寄与を調べました。
Amazon SageMaker Clarify を利用することで、データやモデルのバイアスを手軽に検出することができ、公平性・中立性などを考慮に入れた機械学習を行う際に役立ちます。
参考文献
[1] Generate Reports for Bias in Pretraining Data in SageMaker Studio
[2] Fairness-Aware Machine Learning and Data Mining
[3] 機械学習と公平性 (機械学習と公平性に関するシンポジウム 2020)
[4] 機械学習*と公平性に関する声明
[5] Fairness-Aware Machine Learning: Practical Challenges and Lessons Learned (KDD 2019 Tutorial)

2016年11月、データサイエンティストとして中途入社。時系列分析や異常検知、情報推薦に特に興味があります。クロスバイク、映画鑑賞、猫が好き。


Recommends
こちらもおすすめ
-

フォトグラファーのシェアリングサービスとAzure、AIの良い関係
2017.4.24
-

AWSの利用料を見える化!AWS Cost Explorer の基本とコスト管理
2024.3.19


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16