【AWS Summit Tokyo 2023】Amazon Redshift クエリパフォーマンスチューニング Deep Dive(AWS-36)

初めまして。マイグレーションチーム所属のDJ.mashiです。
本記事では、AWS Summit Tokyo 2023のセッション「Amazon Redshift クエリパフォーマンスチューニング Deep Dive」のレポート、並びに内容を私なりに整理しました。
セッション概要
タイトル
AWS Summit Tokyo 2023 クエリパフォーマンスチューニング Deep Dive
概要
経験や勘に頼らず、Amazon Redshift のクエリのボトルネックをシステマチックに分析してチューニングする実践的な手法を紹介します。マネジメントコンソールやシステムテーブル・ビューから時間ベースでボトルネックを特定して、チューニングを行う手法を理論と実践の両面から実例を交えて紹介します。
スピーカー
AWS
シニアビッグデータコンサルタント
畔勝 洋平 氏
セッションレポート
本セッションの対象者
- AmazonRedshiftでクエリチューニングをされる方
- RDBMSでのクエリチューニング経験済の方
セッションのゴール
- 職人芸からの脱却
- 経験や勘ではなく、システマチックにボトルネックを特定できるようになる
- 最小限の時間で効率的にチューニング
- ボトルネックを特定できているため、最小限の試行錯誤でチューニングができるようになる
ボトルネック分析にあたって前提知識
- Redshiftの進化の歴史
- 2012年の発表以来継続して進化を続け、2022年 RedshiftServerlessの発表
- Redshiftのアーキテクチャ
- リーダーノードとコンピュートノードの分離
各ノードの役割は下記の通り説明がありました。- リーダーノード:
- クエリのエンドポイント
- クエリオプティマイザがSQL処理コードを生成、コンピュートノードへ展開
- コンピュートノード
- ローカル列指向ストレージ
- クエリの並列実行エンジン
- シェアードナッシング + MPPの組み合わせ
- シェアードナッシング
ストレージをノード間で共有しない
ノードとストレージがセット - MPP(Massively Parallel Processing)
1つのクエリを複数ノードで並列分散実行
ノードを増やすこと(=スケールアウト)によりパフォーマンスが向上
- シェアードナッシング
- スライス
- ノード内でCPU、メモリ、ストレージを論理的に分割した処理単位
- 各スライスに割り当てられたリソースが配下に分散されたデータに対して並列処理
- リーダーノード:
- リーダーノードとコンピュートノードの分離
- Redshiftにおける分析クエリを早くする仕組み
まず、クエリ実行時に動作するクエリ処理の流れについて下記の通り説明がありました。
下記記載のオブジェクトコードは、セグメント単位で作成されます。- クエリのコンパイルの流れ
- パーサによるクエリの解析
- クエリから初期クエリツリーの作成、オプティマイザへの引き渡し
- 最適化を目的としたクエリ書換
- 実行計画作成
- 実行エンジンによる、実行計画をステップ、セグメント、ストリームへの変換、オブジェクトコードにコンパイル
- コンピュートノードにコンパイル済コードの引き渡し、並列実行
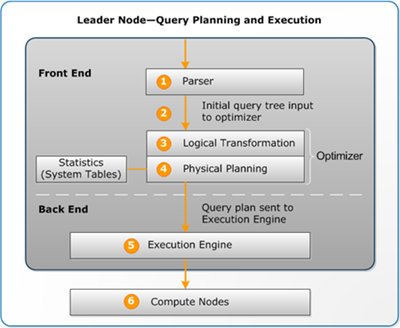
出典:クエリプランと実行ワークフロー
- ステップ、セグメント、ストリームについて
クエリが実行される単位をまとめたものとなります- ステップ
- scan
- join
- aggregation
- projection
- etc…
- セグメント
- ステップを束ねる。オブジェクトコード作成、コンパイルキャッシュの単位
- 複数のセグメントはストリームの中で並列実行されることも
- ストリーム
- セグメントを束ねる
- 複数のストリームはシリアル実行される
- 分析クエリの特性
- OLTPと比較し、OLAPは仕事量が多い
- OLTPはオーダー記法で表現するとO(log n) O(1)などのケースが多い
- OLAPはオーダー記法で表現するとO(n) O(n²)などのケースが多い
- ステップ
分析クエリを早くするためのアプローチ
- I/O量削減
下記を用いて実現- 列指向ストレージ 1ブロック(1MB)
- 圧縮エンコード
- ゾーンマップ
- ソートキー
- 並列化
MPP +シェアードナッシングによる並列分散処理 - 高速化
- SIMD Vectorized Scans
- Advanced Query Accelerator
- Compilation-As-A-Service
テーブル設計の重要性
- 適切なテーブル設計があってこそのクエリ、ANALYZEとなる
- 圧縮エンコード、ソートキー、分散スタイル(シェアードナッシング)に影響する
テーブル設計の指針として次のリンクが参考として紹介頂きました。
Amazon Redshift テーブル設計詳細ガイド
re:Invent 2019 Deep dive and best practice for Amazon Redshift
Amazon Redshift Engineering’s Advanced Table Design Playbook
クエリのボトルネック分析
よくある誤解として
「実行計画を読めばよい」
この考えは主に次の2点の誤解を招くと、説明がありました。
- コストが大きいオペレーションがボトルネックではないか
- 非効率とされるオペレーションがボトルネックではないか
この2点は必ずしもボトルネックではない可能性があります。
- コストは見積(予測)、ボトルネックではないことがある
- 非効率なオペレーションでもボトルネックではないことがある
この点について、次のような説明があります。
クエリチューニングで大切なことは時間ベースでの分析
クエリチューニングにあたっては、ボトルネック分析を実施し
どこに時間がかかっているか、特定したうえでチューニングを実施する必要があります。
コストが大きくても、非効率であっても、時間を要するか要さないかで判断が必要です。
時間を要するクエリの特定方法
システムテーブル、ビューを参照することにより特定します。
システムテーブルとビューのタイプ
ボトルネック分析
上述のシステムテーブル、ビューを用いて各計測を実施することにより
ボトルネックとなるクエリのを行います。
- 計測ポイント:
- SQLクライアントから見た総実行時間の確認
- クライアントから見た実行時間
- レスポンスタイム
- これだけではクエリの遅延が存在するか、判断できない
- クライアントから見た実行時間
- STL_QUERYやマネジメントコンソールによる計測
- AmazonRedshift側で時間がかかっているかの確認
- クライアント等で要した時間+AmazonRedshift側で要した時間
- AmazonRedshiftで要した時間 ≒ クエリーの実行時間
クエリーはAmazonRedshiftにより、最適化されたクエリーへ書き換えられる点に注意
- AmazonRedshift側で時間がかかっているかの確認
- STL_WLM_QUERYによる計測
- 対象クエリーが遅いかの確認
- 待機時間 + 実行時間
- 実行時間 ≒ 各セグメント実行に要した時間の合計
- 対象クエリーが遅いかの確認
- SVL_QUERY_METRICS_SUMMARY
- SVL_QUERY_METRICS
- SVL_QUERY_SUMMARY
- SVL_QUERY_REPORT
- 上記4種はどのセグメントが遅延しているか、さらにはどのスライスで遅延しているかを計測
- 各セグメント、各スライスでの実行時間を知ることができる
- SQLクライアントから見た総実行時間の確認
STL_WLM_QUERYについて
クエリー実行に要した時間について確認することができます。
主に確認できる列は次の通りです
- service_class
- WLMキューを示します
- total_queue_time
- クエリーがキュー内で消費した時間の合計(マイクロ秒)
- total_exec_time
- クエリが実行にかかった時間
これらの情報を利用し
- クエリーが遅延しているのはクエリーの構文(書き方)が悪いのか
- クエリーが遅延しているのは同時実行制御の問題で待機が発生しているのか
上記問題の切り分けが可能となります。
詳細はこちらをご確認ください。
STL_WLM_QUERY
SVL_QUERY_METRICS_SUMMARY
1クエリの実行について、1行で結果(メトリクス)を取得します。
ワークロード特性の把握に利用できます。
主に確認できる列は下記のとおりです。
- query_blocks_read
- クエリーによって読み取られたブロックの数
- query_temp_blocks_to_disk
- クエリーが中間結果書出しをしたディスク上のサイズ
- segment_execution_time
- 単一セグメントで要した実行時間
- cpu_skew
- セグメントにおけるスライス単位の最大CPU使用量とすべてのスライスの平均CPU使用率の比率
- io_skew
- 任意のスライスの最大ブロック読み取り (I/O) とすべてのスライスの平均ブロック読み取りの比率
これらの情報を利用し、ワークロード特定にてボトルネックとなる下記要素を知ることができます。
- ストレージからの読込データ量
- ストレージに書き出した中間結果サイズ
- 単一セグメントで要した最も大きな時間
- スライス間での偏り
詳細はこちらをご確認ください。
SVL_QUERY_METRICS_SUMMARY
SVL_QUERY_METRICSについて
クエリーのメトリクスとして、読み取りしたブロック数、中間結果書出しのサイズ、スライス間の偏り、i/oの偏りを確認することができます。
- query_blocks_read
- クエリーによって読み取られたブロックの数
- query_temp_blocks_to_disk
- クエリーが中間結果書出しをしたディスク上のサイズ
- segment_execution_time
- 単一セグメントで要した実行時間
- cpu_skew
- セグメントにおけるスライス単位の最大CPU使用量とすべてのスライスの平均CPU使用率の比率
- io_skew
- 任意のスライスの最大ブロック読み取り (I/O) とすべてのスライスの平均ブロック読み取りの比率
これらの情報を利用し、SVL_QUERY_METRICS_SUMMRYで確認した特性の中で、
- どのセグメントが遅延しているか
- 遅延しているセグメントで偏りが発生しているか
上記を理解することができます。
詳細はこちらをご確認ください。
SVL_QUERY_METRICS
SVL_QUERY_SUMMARYについて
クエリーステップに含まれるデータ行の数、データバイトの数、ステップ実行に要した最大時間等、クエリーに関する詳細を確認することができます。
主に確認できる列は下記のとおりです。
- maxtime
- ステップを実行する最大時間(マイクロ秒)
- avgtime
- ステップを実行する平均時間(マイクロ秒)
- rows
- クエリステップに含まれるデータ行の数
- rows_pre_filter
- ストレージから読込した行の数
- row_pre_filter-rowsが大きい数値となる場合、不要なブロックを読み込んでいる可能性
- 上記に該当する場合はソートキーの設定で改善の可能性有
- workmem
- ハッシュ、ソート、集計などに使われたクエリステップに割り当てられたメモリ量(バイト単位)
これらの情報を利用し、
- 不要な読み込みが多いか
- 取得結果がメモリで収まらずストレージへ書き出していないか
上記を理解することができます。
詳細はこちらをご確認ください。
SVL_QUERY_SUMMARY
SVL_QUERY_REPORTについて
スライス間でのデータの偏りや、セグメントにおいて並列実行されているかを確認することができます。
主に確認できる列は下記のとおりです。
- slice
- ステップが実行されたデータスライス
- segment
- セグメント番号
- step
- クエリステップ
- elapsed_time
- セグメントの実行に要した時間(マイクロ秒)
- rows
- ステップが生成した行の数
- start_time
- セグメントが開始された時間
- end_time
- セグメントが終了された時間
これらの情報を利用すると
- start_time、end_timeを用いてセグメントが並列実行されているか
- 同じstepにおいてrows,bytesに偏りがある場合はスライスでの処理の偏り
といった内容を理解することができます。
詳細はこちらをご確認ください。
SVL_QUERY_REPORT
まとめ
本レポートでは、AWS Summit Tokyo2023 クエリパフォーマンスチューニング Deep Diveでご説明頂いた内容についてご紹介、並びに私なりに調べ整理致しました。
システムテーブル、ビューの利用によって得られる情報を整理することでボトルネックの特定が可能となります。
そのうえで、特定箇所への適切なアプローチを実施することでボトルネックを解消することが可能となります。
- 前提知識
- アーキテクチャ:ノード、スライス、シェアードナッシング + MPP
- クエリの実行単位:ストリーム、セグメント、ステップ
- etc…
- ボトルネック分析方法
- 時間に基づくボトルネック分析
- システムテーブル、ビューの利用
- STL_WLM_QUERYについて
- クエリーの遅延有無を確認
- SVL_QUERY_METRICS_SUMMARYについて
- ワークロードの特性の確認
- SVL_QUERY_METRICSについて
- セグメントの遅延、偏りの確認
- SVL_QUERY_SUMMARYについて
- 不要な読込の確認
- 取得結果のストレージへの書き込み有無
- SVL_QUERY_REPORT
- セグメントの並列実行状況の確認
- スライス間での処理の偏りの確認
- STL_WLM_QUERYについて
セッションを通しての感想
RDBでのSQLチューニングの経験はありますが、AmazonRedshiftは全くありませんでした。それどころか、AmazonRedshiftは最近学習し始めたサービスなので多くのことを知らない状態で本セッションを受講しました。
本セッションを通じ、AmazonRedshiftのアーキテクチャーとクエリパフォーマンスチューニングに必要な事柄を理解できたと思います。
データ構造はビジネスの変化に追随し、変化を続けます。その中で快適なレスポンスを提供し続けるためにはクエリパフォーマンスチューニング技法の習得は欠かせないものと思います。大変勉強になりました。

2023年4月中途入社 関心の多くはDBにあります


Recommends
こちらもおすすめ





Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16